





아래는 **“Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)”**의 핵심 내용을 정리한 설명입니다.
📌 논문의 목적
Transformer 기반 LLM은 뛰어난 성능에도 불구하고 내부 동작이 블랙박스처럼 보입니다.
메커니스틱 인터프리터빌리티 연구는 내부 컴포넌트(Attention Head, MLP 등)가 구체적으로 어떤 알고리즘을 수행하는지 밝히려고 하지만, 현재는 사람이 일일이 수작업으로 분석하는 방식이라 확장성이 떨어집니다.
이 논문은 그 과정을 체계화하고 특히 회로(circuit)를 자동으로 발견하는 알고리즘 ACDC를 제안합니다.
-> 복잡한 모델에서 특정 행동(Task)을 수행하는 **서브그래프(연결 경로)**를 자동으로 찾아내는 방법
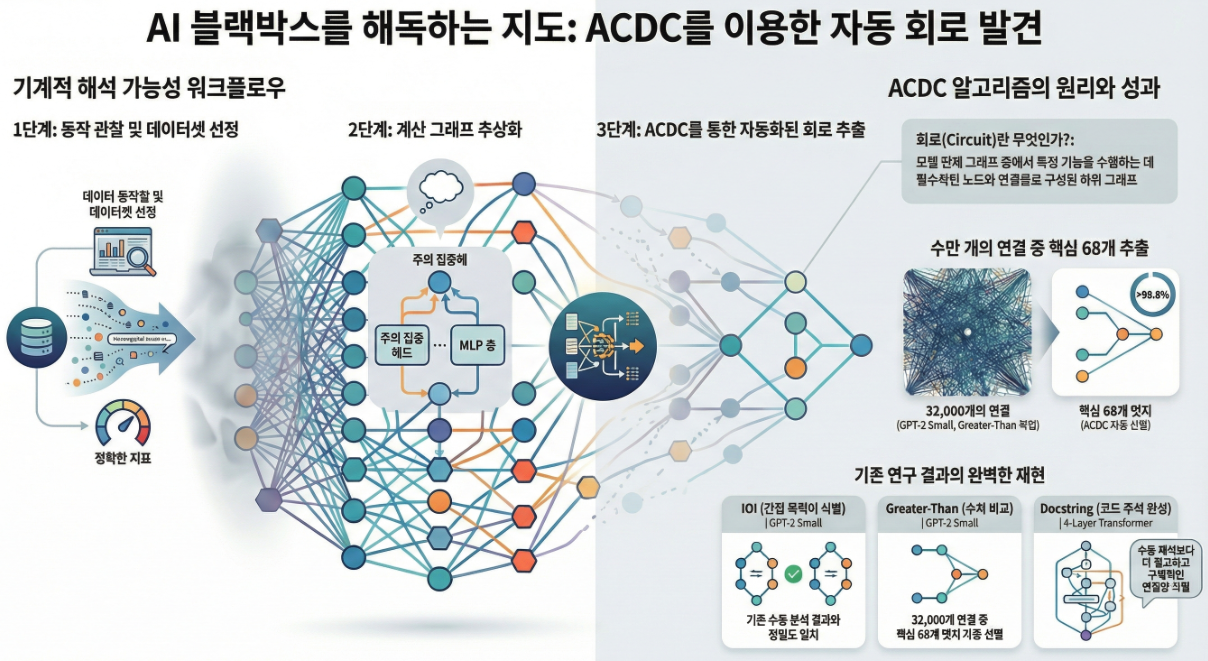
🔁 Mechanistic Interpretability Workflow (3단계)
논문은 지금까지 사람들이 수작업으로 해 오던 회로 분석 과정을 다음 3단계 프로세스로 정리합니다 :
| 단계 | 설명 |
|---|---|
| ① 모델의 특정 행동 선택 | 행동이 잘 드러나는 **데이터셋 및 성능 지표(metric)**를 설정 |
| ② 모델을 컴퓨팅 그래프 단위로 세분화 | (예: Attention Head / MLP / Neuron / Token Position) |
| ③ Activation patching으로 회로 탐색 | 회로 구성 요소가 아닌 Edge를 제거하며 작동에 필수적인 서브그래프만 남기기 |
이 중 가장 시간이 많이 드는 Step ③을 자동화한 것이 ACDC.
🔍 ACDC 알고리즘 개념
ACDC는 다음과 같은 방식으로 모델에서 회로를 찾아냅니다 :
- 모델의 동작이 유지되는 범위에서 Edge들을 하나씩 제거해 본다.
- 제거 시 출력 분포가 얼마나 변하는지 (KL divergence) 측정
- 변화가 작은 Edge는 불필요한 연결 → 영구 제거
- Output → Input 방향으로 재귀적으로 반복
즉, “성능 저하 없이 지워도 되는 부분은 모두 지우자” → 남는 연결이 회로
아래 그림이 논문의 ACDC 과정을 개략적으로 표현합니다:
(Page 5 그림 – 노드 간 Edge pruning & 재귀적 회로 완성)
💡 비교: 기존 회로 추출 방법 vs. ACDC
논문은 ACDC를 아래 두 방법과 비교 실험했습니다:
| 방법 | 특징 | 한계 |
|---|---|---|
| HISP | Gradient 기반 head 중요도 | 비필수 요소 포함 많음 |
| SP | Subnetwork mask 학습 | 학습 비용 큼, 노이즈 민감 |
| ACDC | Activation patching 기반 연결 감소 | Metric/Hyperparameter 민감 |
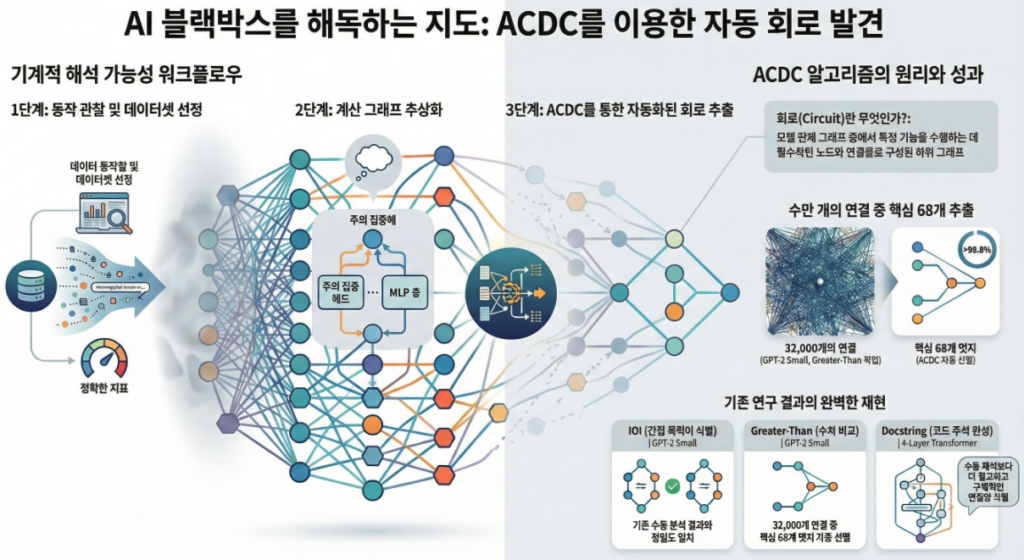
실험 결과
ACDC는 여러 벤치마크(Task)에서 **가장 높은 FPR/TPR 균형(AUC)**을 보임 (Figure 3)
특히 다음 과제에서 기존 회로를 100% 재발견함:
- IOI (Indirect Object Identification)
- Greater-Than (연도 비교)
- tracr-reverse 등
📌 ACDC의 실제 효과 (회로 발견 예시)
논문은 ACDC가 GPT-2 Small에서 다음 회로를 자동 재발견했다고 보고합니다 :
| Task | 발견된 회로 | 특징 |
|---|---|---|
| IOI | Name-Mover Heads | 인칭대명사 추론 |
| Greater-Than | Late MLP → Early year-detector heads | 숫자 의미 비교 |
| Docstring | Program argument extractor heads | 함수 문맥 이해 |
| Induction | Induction heads | in-context pattern 확장 |
→ 사람이 수개월 걸려 찾은 회로를 기계가 자동으로 복원
⚠ 한계 및 논문이 언급한 미래 과제
논문은 ACDC의 장점뿐 아니라 한계도 명확히 언급 :
| 영역 | 현재 한계 |
|---|---|
| 회로 누락 | Negative head(성능을 깎는 요소) 탐지 어려움 |
| Hyperparameter | Threshold τ, metric 선택에 매우 민감 |
| Generalization | 모든 Task에 안정적이지 않음 |
| 효율 | Forward 패치 연산 많아 계산 비용 큼 |
🧠 이 연구가 갖는 의의
ACDC는 해석 가능성을 이론적 수준 → 자동 분석 단계로 초점을 이동시킵니다.
LLM 규모가 커질수록 사람이 회로를 수작업으로 찾는 것은 불가능
→ 자동화된 회로 분석은 대규모 모델의 이해·안전성 연구의 핵심 도구
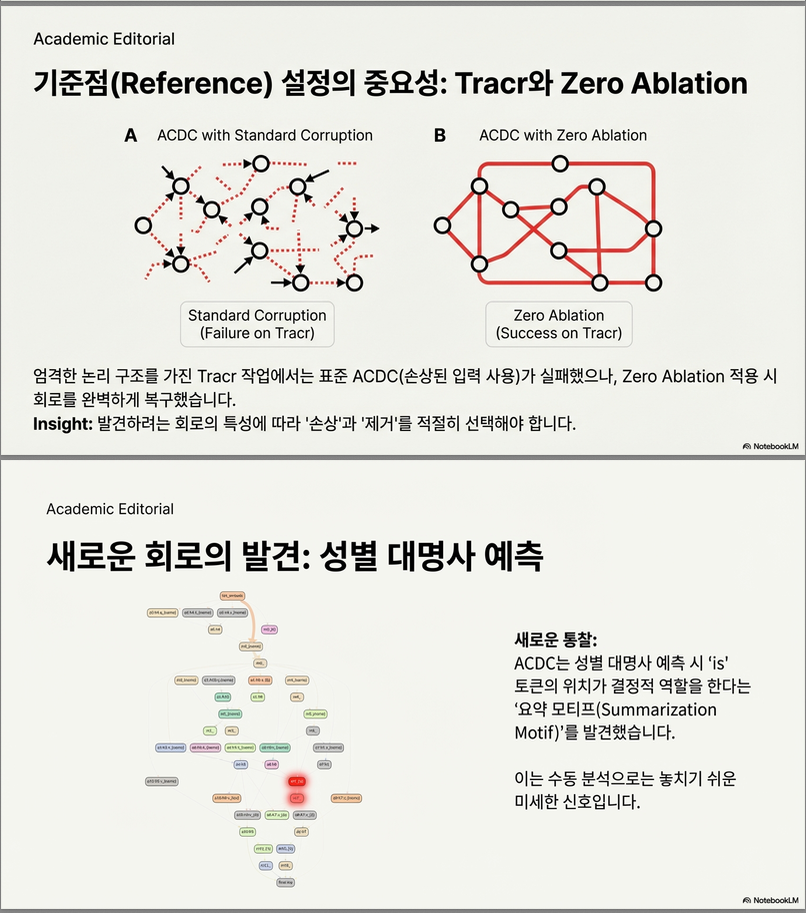
논문은 실제로 젠더 대명사 예측 회로를 ACDC가 새롭게 발견한 사례도 보고하며(부록 K) 해석 연구의 새로운 피드백 루프 가능성을 보여줌
📎 요약
- LLM의 특정 능력은 **연결 경로(회로)**로 구현되어 있음
- 지금까지는 사람이 activation patching으로 수작업으로 추적
- ACDC는 Edge pruning을 통한 회로 자동 추출 알고리즘
- 여러 Task에서 기존 연구 회로를 100% 재발견하며 가능성 입증
- 그러나 metric 민감도, negative circuit 탐지 등 개선 여지 존재
아래는 논문 **“Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)”**의 방법론(Methodology) 섹션을 논문 내용을 기반으로 정리한 설명입니다.
🧩 방법론(Methodology) — ACDC 중심
논문의 방법론 핵심은 Mechanistic Interpretability에서 사람이 수작업으로 수행해온 “회로(circuit) 발견 절차”를 자동화하는 것입니다.
방법론은 크게 (1) 회로 연구 워크플로우의 정식화, (2) ACDC 알고리즘의 설계, (3) 비교 기법(SP, HISP) 일반화로 구성됩니다.
1. Mechanistic Interpretability Workflow 정식화
(논문 Section 2)
논문은 기존 연구자들이 암묵적으로 사용한 회로 탐색 절차를 다음 3단계로 명확히 정리합니다:
Step 1 — Task(행동), Dataset, Metric 정의
모델이 특정 행동을 보이는 상황을 만들기 위해
- 입력 데이터셋 D
- 해당 행동을 측정할 Metric 을 정의합니다.
예:
- IOI task: logit difference
- Greater-Than: “더 큰 숫자에 대한 확률 – 작은 숫자에 대한 확률”
- tracr: Mean Squared Error (표 1에 구체적 예시 제공)
정리:
“어떤 행동을 설명할 것인가?”를 정하고 모델이 그 행동을 명확히 보이는 입력 분포를 구성하는 단계.
Step 2 — 모델을 Computational DAG로 분해
Transformer 내부를 추상 노드(node)들의 Directed Acyclic Graph(DAG) 로 표현합니다.
노드 단위는 연구자 선택:
- Attention Head 단위
- MLP Layer 단위
- Neuron 단위
- Token Position 별로 분리된 Head/MLP (IOI 연구에서 사용됨) (모두 논문에 예시로 나옴)
Edge는 residual stream을 통해 모든 이전 layer로부터의 additive path를 허용할 수도 있고
단순하게 인접 layer 사이 연결만 고려할 수도 있음.
핵심:
“모델을 어떤 resolution으로 바라보고 어떤 노드를 회로 구성 요소로 간주할 것인가?”
Step 3 — Activation Patching으로 회로를 구성하는 Edge 추론
(논문 Section 2.3)
회로는 DAG 내에서 행동(task)을 구현하는 최소한의 subgraph로 정의합니다.
이 subgraph를 찾기 위해
각 노드/엣지를 corrupted activation으로 교체했을 때
행동 metric이 얼마나 떨어지는지 측정합니다.
Corrupted activation 종류:
- 다른 입력 x′의 activation (Interchange Intervention) — 권장 방식
- Zero patch (일부 연구)
- Mean activation patch (IOI 연구) (모두 논문에서 비교됨)
결과적으로 이 단계는 다음 과정을 반복합니다:
- Output node에서 시작
- 각 incoming edge를 하나씩 제거
- 성능이 유지되면 영구적으로 제거
- 남은 edge들의 parent node로 recursion
이 “manual patching-driven circuit discovery”를 자동화한 것이 바로 ACDC.
2. ACDC (Automatic Circuit Discovery) 알고리즘
(논문 Section 3)
ACDC는 위 Step 3 전체를 자동화한 핵심 기여입니다.
✨ 핵심 아이디어
성능을 유지하는 한 불필요한 edge는 모두 제거하자 → 남는 edge가 회로
2.1 정확한 정의
입력:
- 모델의 Computational DAG G
- Behavior dataset {xi}
- Corrupted dataset {x′i}
- Threshold τ
출력:
- Subgraph H (G의 중요한 edge만 포함)
2.2 Subgraph 평가 함수: KL Divergence
(논문은 KL을 기본 metric으로 선택)
H(x, x′): H에서 제거된 edge는 corrupted activation을 사용하여 forward
최종 score:
이 값이 작을수록 H가 원래 모델을 잘 근사함.
2.3 ACDC 절차 (논문 Algorithm 1 요약)
- H ← G 전체 그래프로 초기화
- output → input 방향으로 노드를 topological 정렬
- 각 노드 v의 parent edge (w → v)를 순서대로 검사
- 해당 edge를 제거한 H_new 계산
- 성능 변화를 측정:
- 차이가 τ 보다 작으면 → 제거해도 무해, edge 영구 삭제
- 모든 노드에 대해 반복
결과:
모델 행동을 유지하는 최소 부분 그래프(subcircuit)
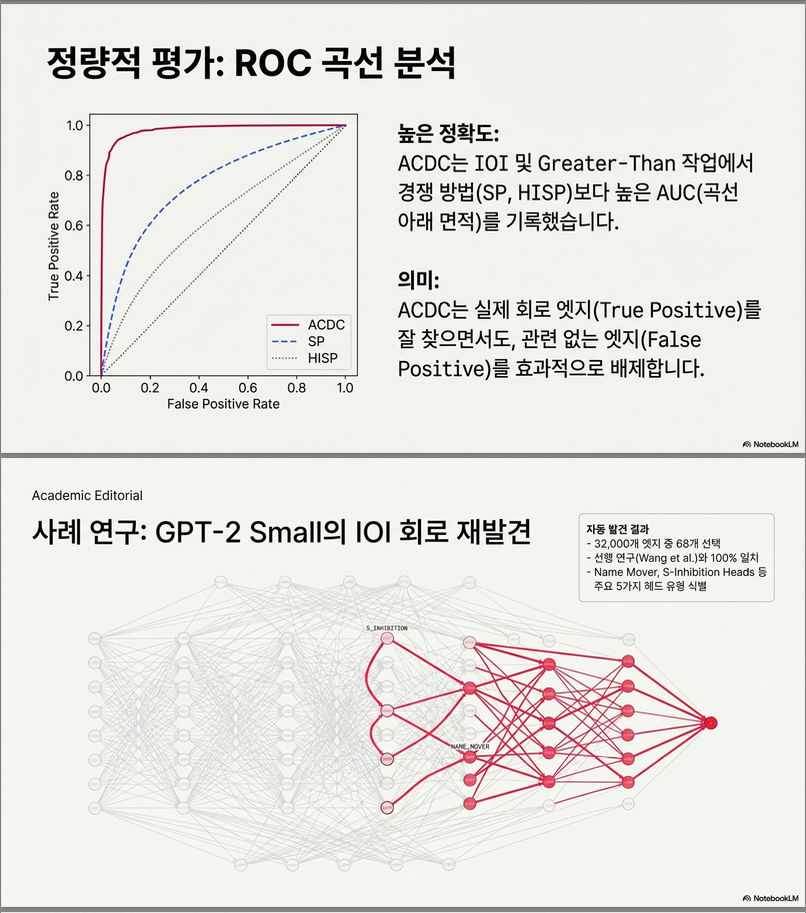
2.4 Corrupted activation의 중요성
ACDC는 interchange patching(다른 입력 x′의 activation) 를 기본 옵션으로 사용.
이는 zero patch보다 안정적이며 interpretability 연구에서 표준화되는 추세.
실험에서도 corrupted activation이 더 좋은 편이지만
일부 tracr task에서는 zero patch가 더 잘 작동하기도 함(논문 Appendix 확인).
3. 비교 방법론: SP & HISP의 ACDC-style 일반화
(논문 Section 3 마지막 부분 & Appendix D)
연구는 ACDC가 실제로 기존 기법보다 회로를 잘 찾는지 비교하기 위해
다음 두 방법을 ACDC 방식으로 수정하여 실험합니다.
3.1 Subnetwork Probing (SP) 확장
원래 SP는 “mask를 학습하여 linear probe 정보 유지”를 목표로 하지만 본 논문에서는:
변형:
- probe 제거
- Loss를 KL(G||H)로 변경
- zero masking 대신 corrupted activation interpolation 사용
즉, SP를 회로 발견 용도로 재구성.
3.2 Head Importance Score for Pruning (HISP) 확장
원래는 gradient-based pruning metric.
논문에서는:
- 중요도 점수 계산
- k개의 head만 남기는 방식
- zero 대신 corrupted activation patch 버전 추가
즉, ACDC와 비교할 수 있도록 공통 평가 방식으로 재해석.
✨ 전체 방법론 요약 도식
(논문 Figure 2 기반 요약)
1️⃣ 모델 내부를 DAG로 표현
2️⃣ Output node부터 시작해 edge를 patching으로 테스트
3️⃣ 영향이 작으면 edge 제거
4️⃣ 재귀적으로 upstream으로 확장
→ 최종적으로 Task를 수행하는 최소 회로가 남음
✔ 메서드의 중요성
ACDC 방법론의 의미:
- 사람이 하던 activation patching trial & error를 완전 자동화
- 회로 발견 효율성 증가
- 기존 연구(IOI, Greater-Than 등)에서 사람이 수개월 걸린 회로를 자동 복원
- 해석(pruning)과는 완전히 다른 목적 (성능 유지가 아니라 “행동을 만들어내는 경로”만 보존)
아래는 ACDC 알고리즘에서 등장하는 **“output → input 방향으로 노드를 topological 정렬(reverse topological sort)”**이 무엇을 의미하는지, 왜 필요한지, Transformer 구조에서 실제로 어떻게 적용되는지를 설명한 내용입니다.
📌 문제의 문장
ACDC Algorithm 1 중:
“H ← H.reverse_topological_sort() // Sort H so output first”
즉,
“output → input 방향으로(출력에서 입력으로) 노드를 topological 정렬한다”
🧠 1. Topological Sort란?
Topological sorting(위상 정렬)은 DAG(Directed Acyclic Graph) 에서
모든 directed edge (u → v)에 대해 u가 v보다 먼저 나오는 순서로 노드를 나열하는 것.
일반적인 topological order:
input → … → middle layers → … → output즉 입력에서 출력 방향으로 정렬됩니다.
🔁 2. 그런데 ACDC는 ‘reverse topological sort’를 사용한다
ACDC에서는 정렬 결과가:
output → … → middle layers → … → input즉, 출력 노드를 가장 앞에 두고 입력으로 갈수록 뒤에 위치합니다.
📌 왜 output→input 순서가 필요한가?
ACDC의 핵심 목표는
출력이 유지되는 한 불필요한 edge를 최대한 제거하는 것
이를 위해 patching을 다음 순서로 진행해야 합니다.
✔ 이유 1: Output node에서 시작해 upstream으로 “회로”를 찾아야 하므로
회로란 결국 **모델이 특정 출력을 만들기 위해 실제로 사용한 경로(edge)**입니다.
- 먼저 출력 노드에 직접 기여한 edge들을 점검 → 불필요한 edge 제거
- 이후, 남은 edge들의 *parent nodes(이전 layer)*로 이동하여 동일 과정 반복
즉 회로 발견은 항상 output → upstream 방향으로 진행됩니다.
따라서 정렬도 output부터 시작해야 재귀적 제거가 잘 작동합니다.
✔ 이유 2: 아직 검증되지 않은 upstream edge를 잘못 제거하지 않기 위해
만약 input → output 정렬을 그대로 사용하면,
- input layer의 edge를 먼저 삭제
- 하지만 그 edge가 output에 실질적 영향이 있었는지 알 수 없음 → 잘못 제거될 위험이 높음
반대로 output부터 시작하면:
- 먼저 output을 유지하는 데 필요한 edge만 남김
- 그 다음 단계에서 upstream node로 이동
- 항상 output 유지 여부를 기준으로 pruning 가능
→ 안전한 순서
✔ 이유 3: Activation patching의 정의상 output이 기준점이기 때문
ACDC는 다음 값을 비교하여 edge 중요성을 판단합니다:
여기서
- G(x) 는 원래 모델의 출력
- H(x,x’) 는 edge 일부가 제거된 subgraph의 출력
이 비교는 항상 “출력”을 기준으로 계산됩니다.
따라서 출력 노드에서 시작해야 metric이 안정적으로 계산됩니다.
🏗 3. Transformer에서 실제 의미는?
Transformer를 computational graph로 보면 대표적인 edge 흐름:
Embedding → Layer 0 → Layer 1 → ... → Layer N → Unembed → LogitsACDC의 reverse topological sort 순서는 다음과 같습니다:
Logits node (output)
↓
Layer N: MLP, Attention heads
↓
Layer N-1
↓
...
↓
Layer 0
↓
Embedding node (input)이 순서대로 edge 삭제 여부를 테스트합니다.
즉,
먼저 마지막 layer에서 어떤 head/MLP가 꼭 필요한지 판정하고,
그 다음 그 구성 요소에 feed하는 이전 layer의 head/MLP를 판정하는 방식
🔍 4. 예시로 보는 절차 (직관적)
Transformer 3-layer라고 가정:
Layer3 → Layer2 → Layer1 → InputReverse topological sort 결과:
[Output(Logits), L3 Heads, L3 MLP, L2 Heads, L2 MLP, L1 Heads, L1 MLP, Input]ACDC는 다음 순으로 edge를 테스트합니다:
- Logits에 들어오는 edge(주로 Layer3 output)
- Layer3 MLP와 head들의 incoming edge
- Layer2에서 Layer3로 가는 edge 테스트
- Layer1에서 Layer2로 가는 edge 테스트 …
결과적으로 output에 기여한 최소한의 경로만 남게 됨
🧩 5. 요약
| 개념 | 설명 |
|---|---|
| Topological sort | 입력 → 출력 방향으로 정렬 |
| Reverse topological sort | 출력 → 입력 방향으로 정렬 |
| ACDC에서 필요한 이유 | 회로는 output을 유지하기 위해 필요한 upstream edge를 찾아야 하기 때문 |
| 효과 | 불필요한 edge를 안전하게 제거하고 최소 회로를 보장 |
아래는 논문 ACDC(Automatic Circuit Discovery) 에서 핵심적으로 사용하는
**“다른 입력 x′의 activation (Interchange Intervention)”**이 무엇인지,
그리고 x′을 어떻게 구성하는지를 논문의 기술과 mechanistic interpretability 문헌 기반으로 설명한 내용입니다.
📌 1. Interchange Intervention이란?
논문에서 activation patching 방식은 크게 3가지가 있습니다:
- Zero patching (활성값을 0으로 대체)
- Mean patching (dataset 평균 activation으로 대체)
- Interchange Intervention (다른 입력의 activation으로 대체) — ACDC가 기본적으로 사용하는 방식
논문에서 이렇게 정의합니다:
“overwrite a node’s activation value on one data point with
its value on another data point.”
즉:
- 원래 입력: x
- corrupted 입력: x′
- 모델 내부 특정 노드의 activation을 x’의 activation으로 교체하여 forward pass 함.
📌 2. 왜 x′(corrupted input)이 필요한가?
ACDC의 목적은
특정 행동(task)을 수행하는 데 필수적인 edge만 유지하고, 불필요한 edge는 삭제하는 것.
그러기 위해선 edge를 삭제했을 때 발생하는 변화가
“자연스러운 activation 변화”인지
“랜덤한 잡음 때문인지”
구별해야 한다.
x′은 가장 자연스러운 ‘비교군’ 역할을 한다.
📌 3. x′은 어떻게 구성되는가? (핵심!)
논문은 x′을 구성하는 원칙을 명확히 제시합니다:
✔ 원칙 1. x′은
원래 task behavior가 나타나지 않는 입력
이어야 한다
(논문 Section 3: “a set of prompts x′ where this task is NOT present”)
즉,
모델이 특정 행동을 수행하지 않아도 되는 “중립적 입력”.
✔ 원칙 2. x′은 반드시 실제 valid input이어야 한다
그래야 activation distribution이 모델의 정상 동작 범위 안에 있음.
✔ 원칙 3. x′은 x와 “비슷한 형태”를 가지되 task trigger는 제거해야 함
왜냐하면:
- x와 너무 다르면 activation 통계가 너무 달라질 수 있음
- x와 너무 비슷하면서 task 정보를 포함하면 corrupted input의 의미가 사라짐
📌 4. 실제 과제들에서 x′을 어떻게 구성하는가? (논문 기반 예시)
논문에서 실험한 6개 task 각각에서 x′ dataset 정의가 명시되어 있습니다.
4.1 IOI Task (Indirect Object Identification)
x (clean inputs)
예:
“When John and Mary went to the store, Mary gave a bottle of milk to John”
x′ (corrupted inputs)
이 문장은 IOI 구조(두 개의 name token, indirect object) 때문에 특정 head가 강하게 활성 됩니다.
따라서 x′은 이 구조가 깨진 문장들로 구성:
- 이름의 grammar 구조를 깨거나
- pronoun resolution이 필요하지 않은 문장들
- 혹은 token order를 교란한 문장들
→ 이렇게 하면 IOI 회로가 작동하지 않음.
Appendix F에서 IOI corrupted dataset 예시가 제시됨.
4.2 Greater-Than Task
x
“The war lasted from 1517 to 15”
모델은 뒤 숫자가 ‘앞 숫자보다 크다’는 패턴을 학습하여 >17을 출력.
x′ 구성 방식 (논문 Appendix G)
- 숫자 위치는 유지
- 하지만 “대소 비교와 무관한 랜덤한 숫자”로 대체 → 즉 모델이 Greater-Than 기능을 발휘하지 않는 문장
4.3 Docstring Task
x
Python 함수 docstring이 있고, 특정 argument name을 predict해야 함.
x′
- docstring을 랜덤하게 섞거나
- 의미와 패턴을 깨는 형태의 문자열
4.4 Induction Task
x
“Vernon Dursley and Petunia Durs” → 모델은 induction head를 통해 다음 token “ley”를 예측.
x′
- 토큰 반복 패턴이 없는 문장 → induction head가 작동하지 않음
4.5 Tracr Tasks (Compiled Transformers)
Tracr는 원래 deterministic algorithm을 transformer로 컴파일한 모델임.
x′
- 알고리즘과 무관한 input sequence
- reverse나 proportion 계산을 촉발하지 않는 입력값들
📌 5. 요약: x′ selection 원칙 (정확한 공식)
ACDC에서 x′은 다음 조건을 만족하도록 선택한다:
- Task behavior가 일어나지 않는 입력
- Activation distribution이 자연스럽고 모델의 정상 범위에 있음
- Clean input x와 어느 정도 구조는 유사 (length, token type 등)
- Clean input과 서로 one-to-one로 매핑되어 patching 시 의미가 유지됨
📌 6. 왜 zero patch보다 x′ patch가 더 좋은가?
논문은 다음 이유로 Interchange Intervention이 더 자연스럽다고 주장합니다:
| Zero patch의 문제 | Interchange patch의 장점 |
|---|---|
| Activation = 0은 실제 activation 분포에 없음 | 실제 activation 분포에서 샘플링됨 |
| 너무 비현실적 → 모델 비정상 동작 | 모델이 본래 동작하는 영역에서만 테스트 |
| 과한 정보 제거 → 오판 가능 | “자연스러운 baseline”으로 비교 가능 |
✔ 최종 요약
Interchange Intervention = “x에서 얻은 activation을 x′의 activation으로 바꿔치기”
x′은 모델이 해당 task behavior를 일으키지 않는 자연스러운 입력 집합으로 구성한다.
ACDC는 이를 사용해 edge를 제거했을 때의 중요도를 안정적으로 측정한다.
답글 남기기