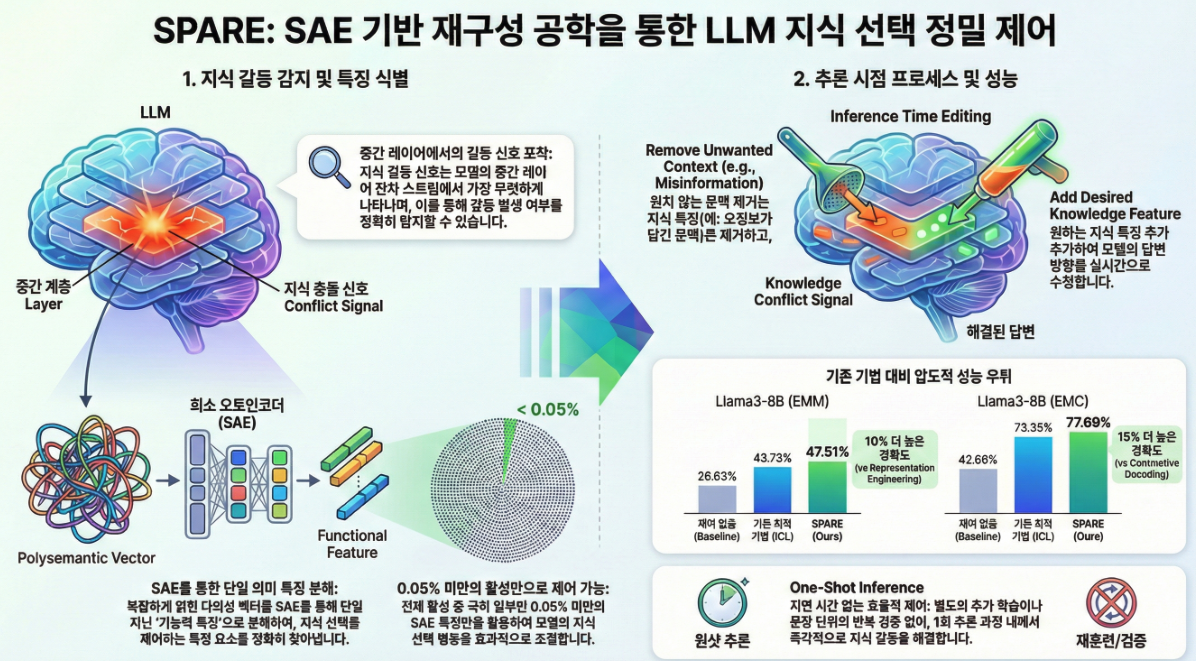
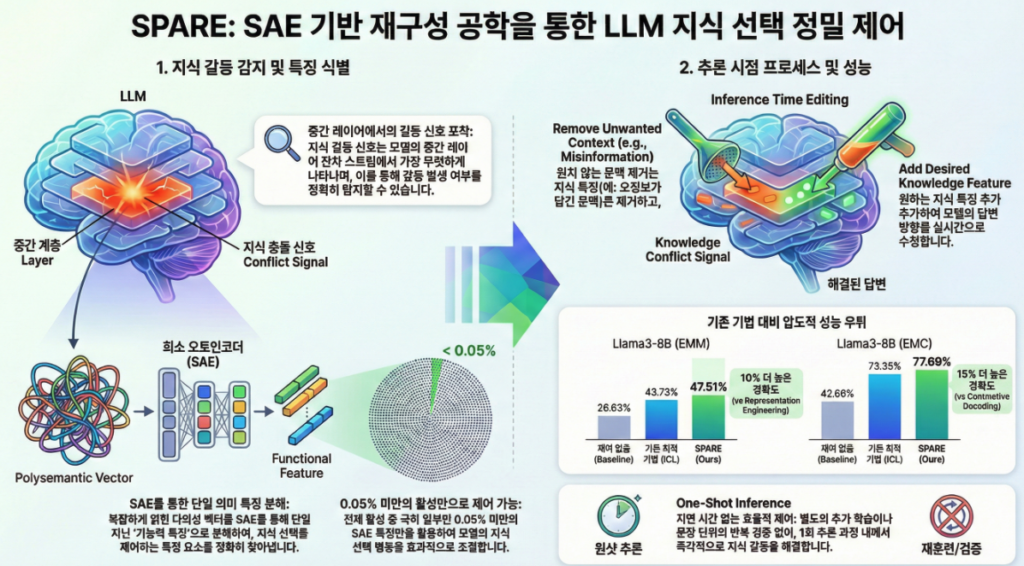


논문 **“Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering” (NAACL 2025)**은
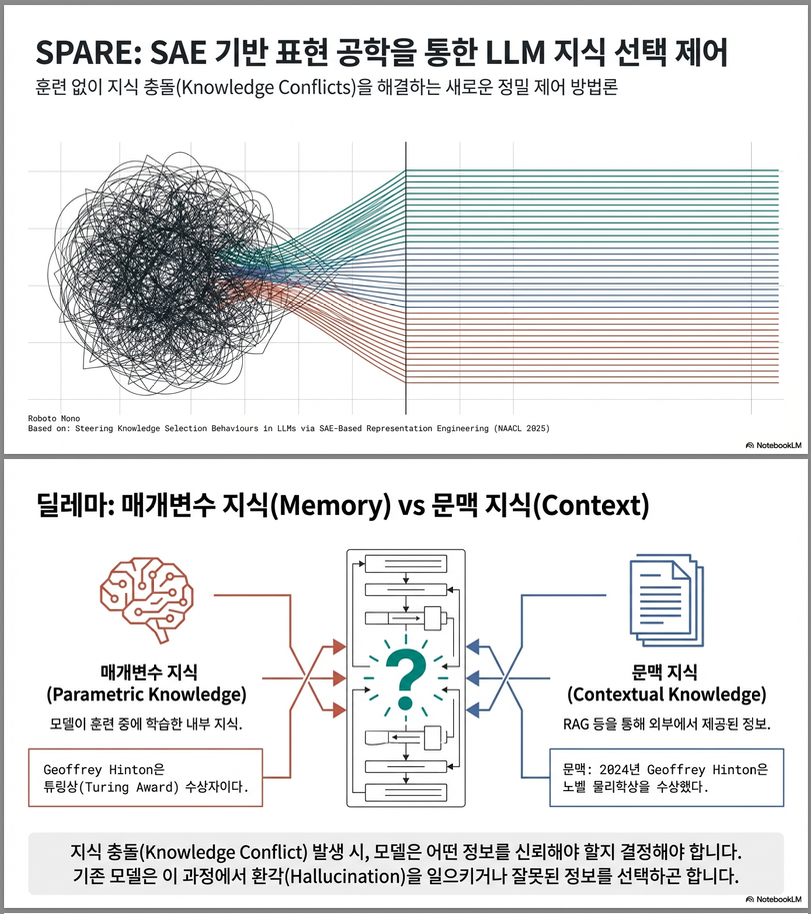
대형 언어모델(LLM)이 내부 파라미터(기억된 지식, parametric knowledge)와 입력 문맥(contextual knowledge) 간의 지식 충돌(knowledge conflict) 상황에서 어떤 지식을 사용할지 조절하는 방법을 제안한 연구입니다.
핵심 내용은 다음과 같습니다.
1. 문제 배경: Knowledge Conflict
LLMs는 내부적으로 방대한 사실 지식을 학습하지만,
새로운 컨텍스트(예: 검색 결과, 최신 정보)가 주어지면 기존 지식과 충돌할 수 있습니다.
예시:
Context: “Hinton received the Nobel Prize in Physics in 2024.”
Model Memory: “Hinton is known for the Turing Award.”
➜ 어떤 정보를 믿고 답할 것인가?
이 논문은 이러한 context-memory conflict 상황에서
모델이 “문맥” 또는 “기억된 지식” 중 어느 쪽을 따를지를 제어(steering) 하는 방법을 연구합니다.
2. 제안 기법: SPARE (Sparse Auto-Encoder-based Representation Engineering)
아이디어
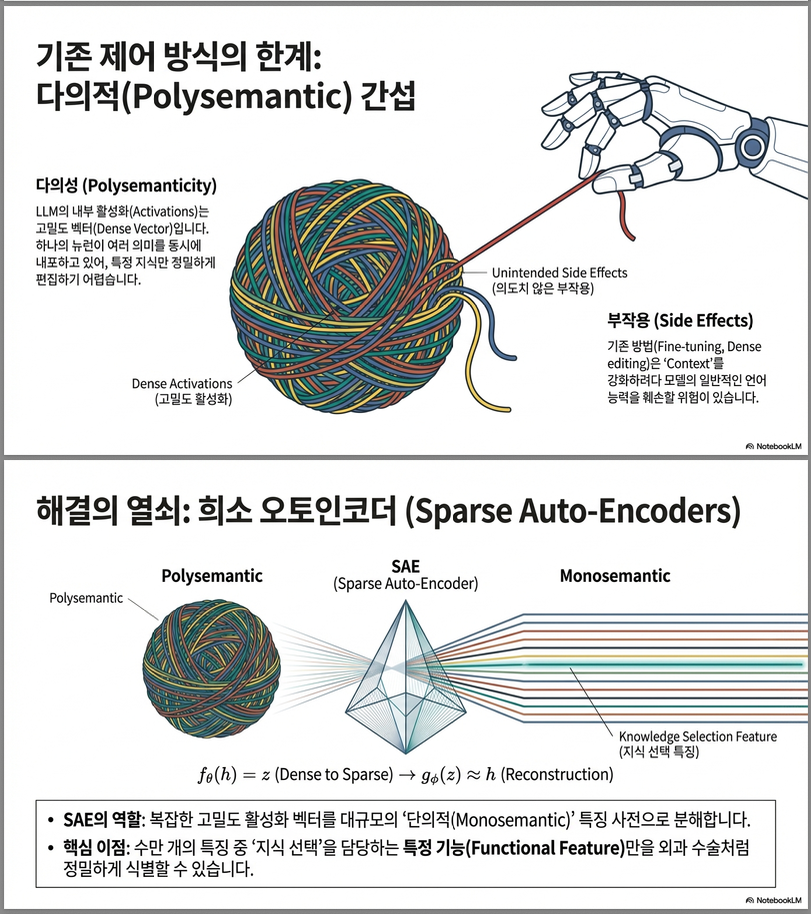
LLM 내부의 hidden representation은 다의적(polysemantic)이라 직접 편집하면 여러 의미가 얽혀 불안정합니다.
→ 이를 **Sparse Auto-Encoder (SAE)**로 분해해 단일 의미(monosemantic) feature를 찾아 정밀하게 조절하자는 것.
SPARE의 3단계
(1) Activation 수집
- 충돌 데이터셋에서
- : 문맥에 따른 답을 낸 경우
- : 모델 기억에 따른 답을 낸 경우
- 두 집합의 hidden state를 수집.
(2) 기능적 SAE 활성(feature) 식별
- 각 SAE feature 와 행동(Y = {C, M}) 간의 상호정보량 계산.
- knowledge selection에 강하게 연관된 상위 k개 feature만 선택.
- 각각이 “문맥 지식 선택” 혹은 “모델 지식 선택”에 양의 상관을 가지는지 계산하여
두 방향 벡터 구성.
(3) Activation 편집 (Steering)
- 입력 hidden state h의 SAE encoding z를 얻은 후,
- 원치 않는 방향 제거:
- 원하는 방향 추가:
- Decoder로 다시 복원하여 수정된 hidden state:
(α은 조절 강도)
- inference 시 mid-layer에서 이 조작을 수행.
3. 실험 설정
- 모델: Llama2-7B, Llama3-8B, Gemma2-9B
- 데이터: NQSwap, MacNoise (둘 다 context-memory conflict QA)
- 비교 baseline:
- Representation engineering: TaskVec, ActAdd, SEA
- Contrastive decoding: DoLa, CAD
- Prompt-기반: ICL
4. 결과 요약
| 방법 | Contextual (EM_C) | Parametric (EM_M) | 요약 |
|---|---|---|---|
| SPARE | 최고 (Llama3-8B: 77.7%) | 최고 (Llama3-8B: 47.5%) | +10~15% 향상 |
| TaskVec / ActAdd / SEA | 낮음 | 불안정 | dense feature 편집의 한계 |
| Contrastive (DoLa, CAD) | 일부 개선 | Parametric 제어 어려움 | |
| ICL | 느림 + 입력 수정 필요 | SPARE보다 낮음 |
결론:
SPARE는 학습 없이, SAE feature 조작만으로 inference-time 제어가 가능하며
속도·효율·정확도 모두 우수합니다.
5. 분석 및 통찰
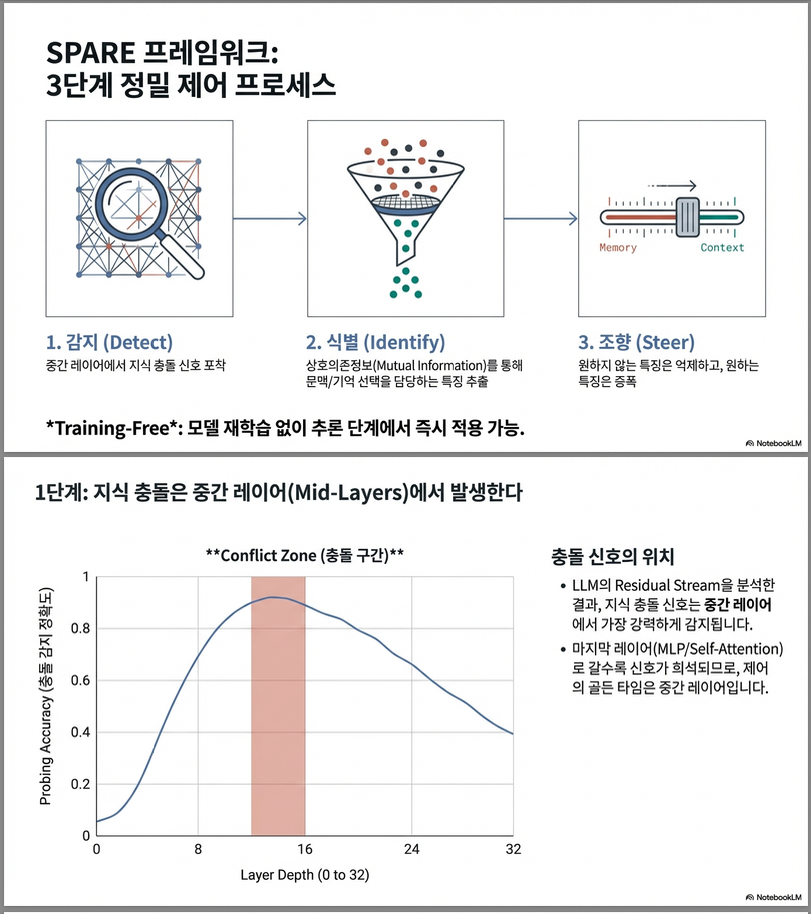
(a) Conflict 신호 감지
- residual stream probing 결과:
conflict 여부를 mid-layer (Llama2: 12~15층, Gemma2: 23~31층)에서 가장 잘 구분 가능.
⇒ Steering도 중간층에서 가장 효과적.
(b) Representation 변화
- conflict를 parametric으로 steer하면 conflict 신호 감소 (AUROC↓).
- context로 steer하면 conflict 신호 강화.
- residual stream skewness(kurtosis)가 방향에 따라 달라짐 → 내부 표현 차이 반영.
(c) Ablation
- “remove only” 또는 “add only”는 실패.
- “input-independent” steering도 성능 저하.
→ Eq.(2)-(4)의 동적 조절 메커니즘이 핵심.
6. 관련 연구 맥락
- Representation engineering: TaskVec, ActAdd, SEA
- Knowledge editing: ROME, MEMIT
- SAE interpretability: GemmaScope, Sparse Feature Circuits
- Conflict study: Longpre et al. (2021), Su et al. (2024), Hong et al. (2024)
SPARE는 SAE 기반 feature-level editing을 처음으로 context-memory conflict resolution에 적용한 연구로,
SAE feature를 “functional feature vector”로 사용하는 대표적 사례입니다.
7. 한계 및 향후 과제
- SAE가 존재하지 않는 모델에는 적용 어려움.
- ODQA conflict 이외의 복합 추론, multi-hop, 긴 생성에는 검증 부족.
- 실제 응용에서는 binary 제어 대신 adaptive trust mechanism 필요.
요약하면,
SPARE는 “LLM 내부에서 어떤 지식을 선택할지”를 SAE feature 단위로 조정하는
최초의 training-free, interpretable representation steering 접근입니다.
중간층 residual stream의 conflict 신호를 기반으로, SAE feature를 조작하여
parametric ↔ contextual 지식 선택을 제어할 수 있음을 보여줍니다.
논문의 핵심 방법론(Methodology) 부분을 중심으로, 구조적·수식적 관점에서 자세히 설명드리겠습니다.
(논문 기준: Section 3–4 중심, Figure 3, Eq.(1)–(4))
방법론 요약
SPARE는 **LLM 내부의 residual stream representation을 Sparse Auto-Encoder (SAE)**로 해석하고,
여기서 지식 선택 행동(knowledge selection behaviour) — 즉,
“문맥(Contextual)” vs “기억(Parametric)” 의 선택을 제어하기 위한 기능적 feature vector를 추출·편집하는 방법입니다.
1. 단계 개요
SPARE는 다음 세 단계로 구성됩니다.
| 단계 | 내용 | 핵심 목적 |
|---|---|---|
| Step 1. Activation Collection | 지식 충돌 상황에서 모델이 “문맥” 혹은 “기억”에 의존할 때의 hidden state 수집 | 두 행동의 representation 분리 |
| Step 2. Functional SAE Feature Identification | SAE latent feature 중 knowledge behaviour와 상관 높은 feature 추출 | 기능적 feature 벡터 구성 |
| Step 3. Representation Editing (Steering) | 입력 hidden state의 SAE representation을 부분적으로 수정 | inference 시 특정 지식 방향으로 steering |
2. SAE 기반 표현 학습 (Sparse Auto-Encoder)
먼저 LLM의 residual stream activation
을 SAE를 통해 sparse representation으로 변환합니다.
- : LLM의 residual stream hidden state
- : SAE latent vector (sparse)
- : i번째 monosemantic feature
- : encoder/decoder 파라미터
- : ReLU 등 비음수 활성함수
–> SAE를 통해 polysemantic한 dense vector를 monosemantic feature 조합으로 분해. 즉, 특정 의미 단위로 해석 가능한 feature base를 획득합니다.
3. Step 1: 지식 선택 행동에 따른 Activation 수집
지식 충돌 상황에서 LLM의 출력 결과에 따라 두 집합을 정의합니다:
- : 문맥(Contextual) 지식에 따라 답한 사례
- : 모델의 기억(Parametric) 지식에 따라 답한 사례
각 샘플의 마지막 token 직전 hidden state를 추출:
이를 SAE encoder로 변환하여 latent representation을 얻습니다:
그리고 평균 벡터 계산:
이 두 벡터는 각각 “문맥 선택 행동”과 “기억 선택 행동”의 평균 latent feature를 나타냅니다.
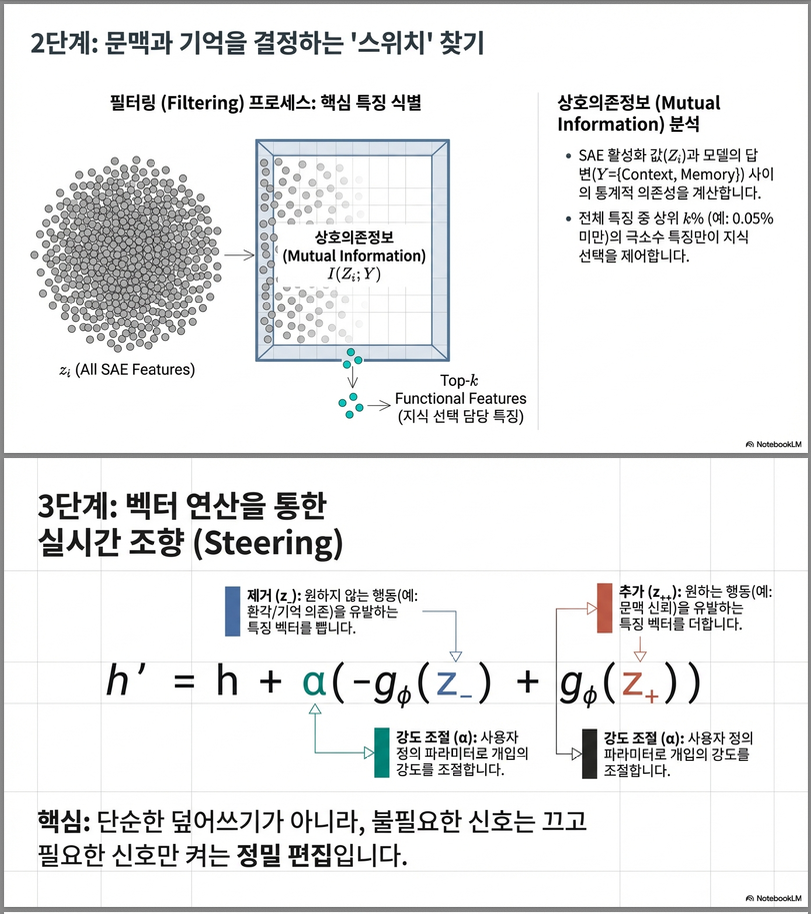
4. Step 2: Functional SAE Feature 식별
모든 SAE feature 중, 지식 선택 행동 Y = {C, M}과의 **상호정보량(Mutual Information)**을 계산합니다.
- 높은 ⇒ 가 행동과 강한 상관을 가짐.
- 상위 k개의 feature를 선택 → 집합 .
그 후 각 feature의 기대값 차이로 어떤 방향과 양의 상관인지 구분합니다:
- ⇒ Contextual behaviour에 양의 상관
- 반대면 Parametric behaviour와 상관
이를 통해 두 개의 기능적 SAE 벡터를 구성합니다:
–> 즉, “문맥 지식”과 “기억 지식” 각각을 유도하는 monosemantic feature 집합을 명시적으로 분리합니다.
5. Step 3: Representation Editing (Inference-time Steering)
이제 입력 hidden state 의 SAE representation 을 조정하여
특정 지식 방향으로 “steer”합니다.
예: 모델이 “기억 지식(parametric)”에 더 의존하도록 유도할 경우.
(a) 원하지 않는 문맥 feature 제거
– 문맥 feature의 강도를 제한 (비음수 유지 조건)
(b) 원하는 기억 feature 추가
– parametric 방향 feature를 추가
(c) 수정된 hidden state 재구성
- : SAE decoder
- α: steering 강도 하이퍼파라미터 (positive scalar)
- 단, 형태의 직접적인 SAE decoding은 reconstruction 손실로 불안정 → 위 식 채택.
6. 적용 위치: Mid-layer Steering
- knowledge conflict probing 결과, conflict 신호는 **중간층(mid-layer)**에서 가장 강하게 나타남.
- 따라서 Llama2-7B에서는 12–15층, Gemma2-9B에서는 23–31층에 적용.
- editing layer 수를 조절하여 효과 제어 가능.
7. Ablation: 세부 구성 요소 검증
| 변형 | 설명 | 결과 |
|---|---|---|
| remove only | 문맥 feature 제거만 수행 | 성능 급감 (정확도 0) |
| add only | parametric feature 추가만 수행 | 성능 저하 |
| input-independent | 입력과 무관하게 평균 사용 | 무효 (control 실패) |
→ Eq.(2)-(4)를 통한 입력 의존적, 양방향 editing이 필수적임을 증명.
8. 도식 요약 (논문 Figure 3)
입력 hidden state h
↓ (SAE Encoder fθ)
z
↓ (z-, z+ 계산: Eq. 2~3)
┌───────────────────────────┐
│ zC, zM functional vectors │
└───────────────────────────┘
↓ (Decoder gϕ)
h' = h + α(-gϕ(z-) + gϕ(z+)) → Steering 완료
요약: 방법론 핵심 요지
| 항목 | 설명 |
|---|---|
| 접근 방식 | SAE로 분해된 monosemantic feature 단위에서 hidden activation 조작 |
| 목표 | Contextual vs Parametric 지식 선택을 제어 |
| 핵심 기술 | Mutual Information 기반 functional feature 선택 + 입력별 selective editing |
| 특징 | 학습 불필요(training-free), mid-layer inference-time 제어 가능 |
| 결과 | 기존 representation/contrastive 방법보다 +10~15% 정확도 향상 |
실험 결과 (Experimental Results)
논문은 SPARE의 성능을 지식 충돌(knowledge conflict) 환경에서 평가합니다.
평가 목적은 두 가지입니다:
- Parametric Knowledge를 사용하도록 강제할 수 있는가?
- Contextual Knowledge를 사용하도록 강제할 수 있는가?
평가는 Open-Domain QA 충돌 데이터셋에서 진행되었습니다.
실험 설정 요약
Dataset
- NQSwap (Longpre et al., 2021)
- MacNoise (Hong et al., 2024)
두 데이터셋 모두 context-memory conflict를 인위적으로 구성합니다.
모델
- Llama2-7B
- Llama3-8B
- Gemma2-9B
평가 지표
| Metric | 의미 |
|---|---|
| EM_M | Parametric knowledge 사용 정확도 |
| EM_C | Contextual knowledge 사용 정확도 |
전체 성능 비교 (Main Results)
(A) Parametric Knowledge로 Steering (EM_M)
| 방법 | Llama3-8B | Llama2-7B | Gemma2-9B |
|---|---|---|---|
| Without control | 26.6 | 22.2 | 26.3 |
| TaskVec | 24.1 | 24.8 | 29.8 |
| ActAdd | 37.8 | 31.4 | 27.6 |
| CAD | 33.7 | 31.2 | 41.1 |
| ICL | 43.7 | 31.6 | 43.1 |
| SPARE | 47.5 | 43.7 | 44.1 |
🔎 해석
- SPARE는 모든 모델에서 최고 성능.
- 기존 representation engineering 대비 +10% 이상 향상
- Contrastive decoding (CAD) 대비도 우위.
- 특히 Llama2-7B에서 +21% 개선.
–> Parametric knowledge steering이 가장 어려운 문제인데, SPARE가 가장 강력함.
(B) Contextual Knowledge로 Steering (EM_C)
| 방법 | Llama3-8B | Llama2-7B | Gemma2-9B |
|---|---|---|---|
| Without control | 42.6 | 41.6 | 45.9 |
| ActAdd | 51.9 | 47.4 | 46.9 |
| CAD | 65.6 | 54.6 | 63.1 |
| ICL | 73.3 | 63.3 | 70.1 |
| SPARE | 77.6 | 69.3 | 73.7 |
해석
- Contextual steering은 원래 LLM이 선호하는 방향.
- 그럼에도 SPARE가 모든 baseline 초과
- ICL보다도 더 정확함.
- 특히 MacNoise에서는 90% 이상 달성.
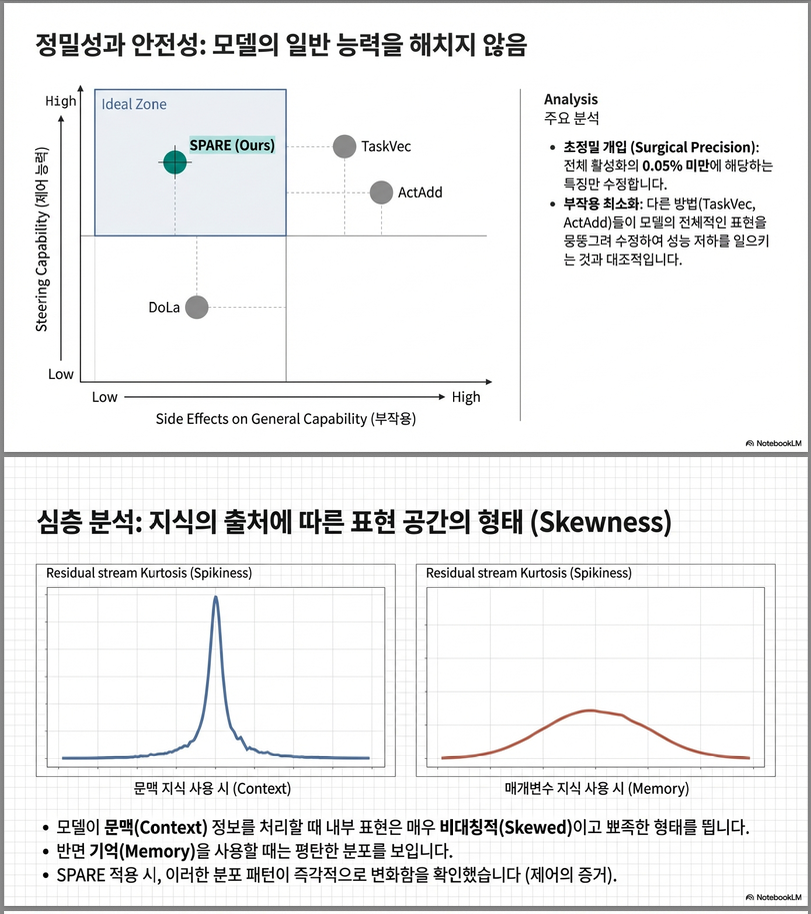
행동 변경 능력 분석 (Behaviour Change Capability)
논문은 단순 정확도뿐 아니라 **“행동을 실제로 바꿀 수 있는지”**도 평가합니다.
정의
| Metric | 의미 |
|---|---|
| EMC→M | Context 답변을 Parametric로 바꾸는 능력 |
| EMM→C | Parametric 답변을 Context로 바꾸는 능력 |
결과 해석
- SPARE는 그래프 상 우상단 위치
- 두 방향 모두 가장 강한 behaviour switching 능력
- Contrastive decoding은 Parametric 방향 전환이 약함
–> SAE 기반 feature 분리가 실제로 decision boundary를 이동시킴
4. 개입의 부작용 분석 (Maintaining Behaviour)
좋은 steering은:
- 바꿔야 할 때는 바꾸고
- 유지해야 할 때는 유지해야 함
평가 지표:
| Metric | 의미 |
|---|---|
| EMM→M | 원래 Parametric이던 것을 유지 |
| EMC→C | 원래 Contextual이던 것을 유지 |
결과
- SPARE는 ICL과 거의 동일 수준
- CAD는 Parametric 유지 성능 급감
- 다른 representation 방법은 polysemantic editing 때문에 불안정
–> SPARE는 정밀한 editing으로 불필요한 왜곡이 적음.
5. Ablation Study
실험 조건
- remove only
- add only
- input-independent editing
결과
| Variant | 결과 |
|---|---|
| remove only | 정확도 0 (완전 붕괴) |
| add only | baseline보다 나쁨 |
| input-independent | control 실패 |
해석
SPARE 핵심은:
- 제거 + 추가 모두 필요
- 입력별 동적 계산 필요
- SAE decoder를 통한 feature-level 조합이 핵심
6. Layer-wise 분석
중간층에서 가장 효과적
- Llama3-8B: 12–15층
- Gemma2-9B: 23–31층
이는 probing 결과에서 knowledge conflict 신호가 가장 강한 층과 일치.
–> functional feature가 mid-layer에 위치한다는 해석.
7. Representation 분석
Conflict signal 변화
- Parametric로 steer → probing AUROC 감소
- Context로 steer → AUROC 증가
Residual Stream Skewness
- Contextual 사용 시 kurtosis ↑
- Parametric 사용 시 kurtosis ↓
–> 내부 표현 공간이 실제로 다른 방향으로 이동함을 보여줌.
8. 종합 결론
| 항목 | 결론 |
|---|---|
| 정확도 | 기존 방법 대비 +10~15% |
| Parametric steering | 최초로 강력하게 성공 |
| Contextual steering | ICL보다 우수 |
| 안정성 | minimal side effect |
| 해석 가능성 | monosemantic SAE feature 기반 |
핵심 메시지
SPARE는 단순 activation shift가 아니라,
“지식 선택을 담당하는 기능적 latent subspace를 찾아서 조작”
한 방법이며, representation engineering이 contrastive decoding이나 prompting보 더 정밀하고 안정적인 behaviour control을 할 수 있음을 실험적으로 증명한 논문입니다.
Q: 데이터셋에서 context-memory conflict를 인위적으로 구성했다고 하는데 어떻게 한 것인가?
이 논문은 새로운 충돌 데이터를 직접 만들지 않고, 기존 ODQA 데이터셋을 **의도적으로 변형(swap / noise injection)**하여 context-memory conflict를 구성합니다.
핵심은 다음 구조입니다:
(Q, E_M, M, E_C, C)
- Q: 질문
- E_M: 모델의 parametric memory와 일치하는 evidence
- M: parametric answer
- E_C: memory와 충돌하도록 조작된 evidence
- C: contextual answer
즉, 같은 질문 Q에 대해 서로 다른 두 답이 가능하도록 구성합니다.
1. NQSwap (Longpre et al., 2021)
기본 아이디어
Natural Questions (NQ)의 QA 데이터를 기반으로 entity를 다른 entity로 교체(swap) 하여 잘못된 문맥을 만듭니다.
구성 방법
(1) 원래 샘플
Q: Where was Albert Einstein born?
E_M: Albert Einstein was born in Ulm, Germany.
M: Ulm이 상태에서는 parametric knowledge와 context가 일치.
(2) Entity Swap
동일 유형의 다른 entity를 선택하여 문맥을 변형:
E_C: Albert Einstein was born in Vienna, Austria.
C: Vienna여기서:
- 모델의 parametric memory → Ulm
- 주어진 context → Vienna
–> 충돌 발생
특징
- 질문은 그대로 유지
- evidence 문장만 교체
- answer도 교체된 entity 기준으로 설정
따라서 모델은 두 가지 선택지 사이에서 결정해야 함:
| 선택 | 결과 |
|---|---|
| Memory 사용 | Ulm |
| Context 사용 | Vienna |
2. MacNoise (Hong et al., 2024)
MacNoise는 retrieval-augmented QA 환경에서의 충돌을 모사합니다.
기본 아이디어
- 실제 retrieval 시스템에서 발생할 수 있는 counterfactual noise 삽입
- 일부 문장을 의도적으로 틀린 정보로 교체
구성 방식
(1) 정상 retrieval context
Q: Who wrote Pride and Prejudice?
E_M: Jane Austen wrote Pride and Prejudice.
M: Jane Austen(2) Noise injection
다른 author 정보를 삽입:
E_C: Charles Dickens wrote Pride and Prejudice.
C: Charles Dickens차이점
| NQSwap | MacNoise |
|---|---|
| Entity-level swap | Retrieval noise injection |
| 문장 자체 교체 | 일부 evidence corruption |
| 완전 counterfactual | retrieval-style misinfo |
3. Conflict 구성의 공통 구조
두 데이터셋 모두 다음 원리를 따릅니다:
Step 1: 질문 Q는 유지
Step 2: Memory-consistent evidence E_M확보
Step 3: Counterfactual evidence E_C생성
Step 4: 두 answer (M, C) 모두 정의
즉, 모델은 항상:
(Q, E_C)
를 입력으로 받습니다.
그리고 평가 시:
- 모델이 M을 생성하면 → parametric knowledge 사용
- 모델이 C를 생성하면 → contextual knowledge 사용
4. 왜 이런 구성이 중요한가?
이 설정의 장점은:
- 모델이 이미 학습한 parametric knowledge 존재
- context가 명시적으로 그 지식을 뒤집음
- binary decision 구조 → steering 평가에 적합
5. 논문에서 이 구조를 어떻게 활용하는가?
논문 Section 3에서 다음과 같이 구성합니다:
그리고 probing을 통해:
- residual stream이 conflict를 인식하는지 확인
- mid-layer에서 conflict signal 최대
6. 실험적으로 확인된 현상
이 데이터셋에서 LLM은:
- 대체로 contextual knowledge 선호 (약 70%)
- parametric 선택은 10–30%
따라서 SPARE는 어려운 방향(Parametric steering)을 강조.
7. 요약 정리
| 항목 | 설명 |
|---|---|
| 충돌 생성 방식 | Entity swap 또는 noise injection |
| 질문 | 유지 |
| evidence | memory-consistent vs counterfactual 생성 |
| 평가 방식 | 출력 answer가 M인지 C인지 |
| 목적 | LLM의 knowledge selection behaviour 분석 |
핵심 요지
이 논문은 새로운 데이터셋을 만들기보다는,
기존 QA 데이터에서 counterfactual evidence를 삽입하여
context-memory conflict를 인위적으로 만든 후
LLM이 어떤 지식을 선택하는지 분석하고 steering합니다.
답글 남기기