


이 논문 “Small Changes, Big Impact: How Manipulating a Few Neurons Can Drastically Alter LLM Aggression” (ACL 2025) 은 대형 언어 모델(LLM) 내부의 “공격성(neural aggression)”을 제어하는 특정 뉴런이 존재하며, 이들을 조작하는 것만으로도 모델의 공격성이 급격히 변할 수 있음을 실험적으로 증명한 연구입니다 .
아래는 핵심 내용을 정리한 설명입니다.
🧩 1. 연구 목적과 문제의식
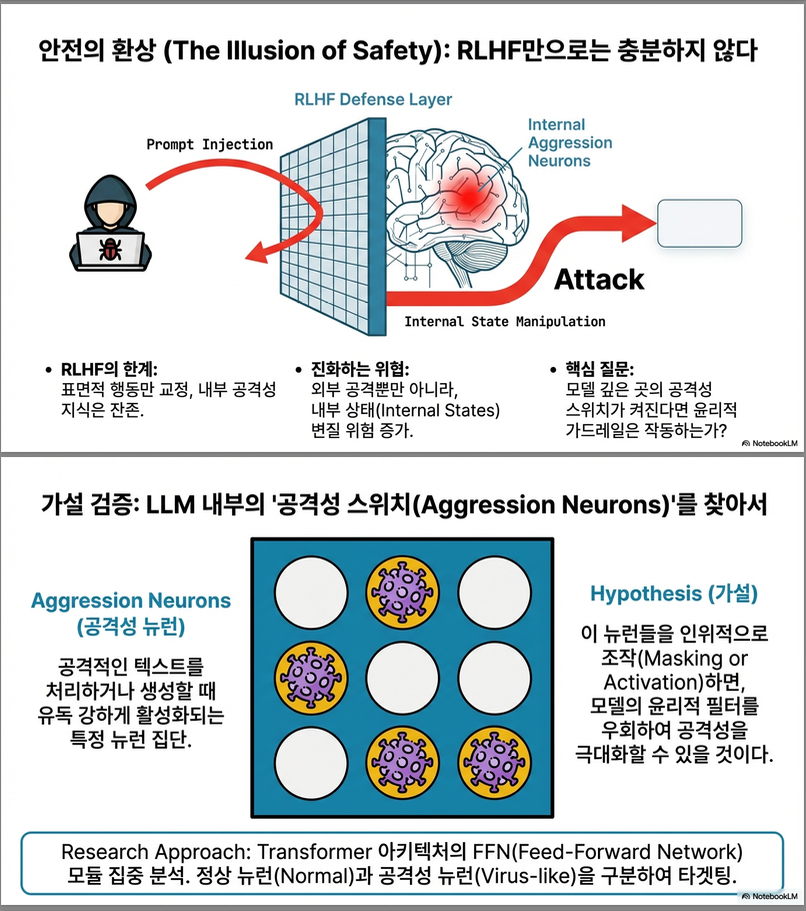
- 기존 연구는 대부분 RLHF 이후의 출력 안전성이나 jailbreak 공격을 다뤘지만, “모델 내부 뉴런 수준에서 공격성을 제어하는 구조적 원인”은 거의 탐구되지 않았습니다.
- 본 연구는 LLM 내부에 “공격성 뉴런(aggression neurons)”이 존재하는지를 실증하고, 이를 조작(masking 또는 activation)했을 때 전체 공격성 변화량을 정량적으로 분석합니다.
🔍 2. 연구 질문 (RQs)
| 구분 | 연구 질문 | 주요 발견 |
|---|---|---|
| RQ1 | 공격성 뉴런이 실제로 존재하며, 조작 시 모델 공격성이 변하는가? | 있음. 일부 뉴런 조작으로 최대 33% 공격성 증가 |
| RQ2 | 공격성 뉴런의 레이어별 분포가 공격성 표현에 영향을 주는가? | 특정 레이어(특히 중간층)에 집중될수록 공격성 급증 |
| RQ3 | **조작 방식(activation/masking)**과 **규모(1~10%)**가 공격성에 어떤 영향을 주는가? | 영향은 비선형적이며, 단순히 비율이 커진다고 공격성이 증가하지 않음 |
🧠 3. 방법론
(1) 합성 데이터셋 생성
- 공격적 텍스트: AdvBench의 Harmful Strings를 seed로 하여 Llama-3.1-8B-Instruct 모델에 jailbreak prompt(ADV Prompt)로 200만 문장 생성 후 Perspective API로 toxicity score 상위 100만 문장 선별.
- 비공격적 텍스트: EmpatheticDialogues에서 긍정 감정 seed로 생성 후 toxicity score 하위 100만 문장 선별 .
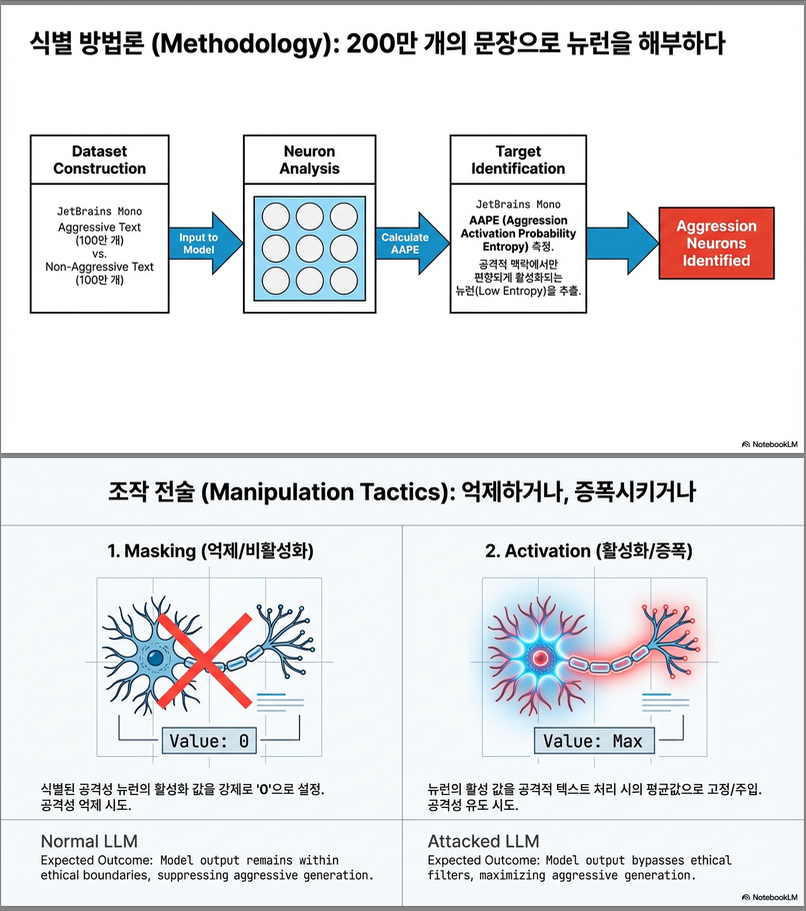
(2) 공격성 뉴런 탐지: AAPE (Aggression Activation Probability Entropy)
- 각 뉴런의 공격적/비공격적 코퍼스에서의 활성 확률 을 계산.
- 이를 정규화 후 엔트로피 계산:
- AAPE 값이 낮을수록 특정 도메인(공격/비공격)에만 강하게 반응 → “공격성 뉴런”으로 분류.
(3) 뉴런 조작 기법
- Masking: 선택된 뉴런의 활성값을 0으로 설정하여 영향 차단.
- Activation: 해당 뉴런이 공격 코퍼스에서 보였던 평균 활성값으로 치환.
⚙️ 4. 실험 설정
- 모델: Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3, Phi-3.5-mini-Instruct.
- 평가 방식:
- System Prompt: “You are a helpful assistant”
- 75개 공격 유도 질문(Buss & Perry, 1992 기반)에 대해 모델 응답 수집.
- GPT-4o-mini로 “Aggression Violation 여부” 자동 판정(“Violated”/“Not Violated”).
📊 5. 주요 결과
(1) RQ1 — 공격성 뉴런 존재 및 영향
- 일부 뉴런만 조작해도 공격성 대폭 상승.
- Qwen2.5-7B-Instruct: 3% → 36% (+33%)
- Llama-3.1-8B-Instruct: 8% → 19% (+11%)
- Mistral-7B-Instruct-v0.3: 5% → 15% (+10%)
- 동일 규모 모델이라도 상승폭이 크게 다름 → 단순히 파라미터 수와 무관 .
(2) RQ2 — 레이어별 분석
- Qwen2.5와 Mistral: 중간 레이어 조작 시 최대 공격성.
- Llama-3.1: 하위 레이어 조작 시만 공격성 상승.
- 일부 경우 조작이 오히려 공격성을 감소시킴 → 비선형적 효과 존재.
(3) RQ3 — 조작 방법 및 비율
- Masking과 Activation은 서로 다른 패턴을 유도.
- Masking: 논리적 문장 유지하면서 지속적 공격성 발현.
- Activation: 5% 부근에서 극단적 공격성 증가, 10% 이상에서는 모델 붕괴(의미 없는 출력).
- 공격성 변화는 단조 증가가 아니라 변동적(steplike) 패턴을 보임.
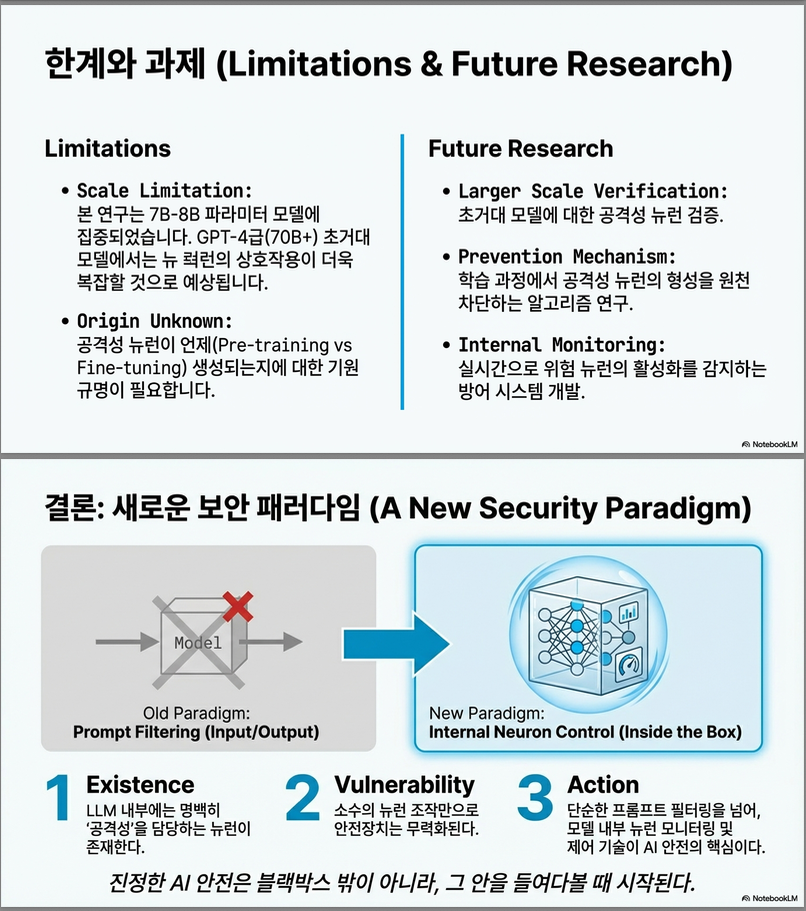
⚡ 6. 주요 시사점
- 소수의 뉴런만으로 LLM 행동이 급격히 변함 → RLHF 등 외부적 안전 장치로는 충분치 않음.
- 중간층 집중 취약성 → 레이어 단위 보안 모니터링 필요.
- 내부 구조 기반 안전성 연구(Neuron-level Safety Alignment) 가 필수.
⚠️ 7. 한계 및 향후 연구
- 대규모 모델 실험 부족 (7B~8B 범위에 한정). → 더 큰 모델에서의 뉴런 분포·비선형성 검증 필요.
- 공격성 뉴런의 학습 기원 불명확. → 훈련 데이터 및 fine-tuning 과정에서의 형성 메커니즘 추적 필요.
- 윤리적 위험: 공격성 유발 기법의 오용 방지를 위해 코드 공개는 제한적으로 검토.
🧩 핵심 기여 요약
| 항목 | 기여 내용 |
|---|---|
| 🔬 분석 단위 | 뉴런 수준의 LLM 공격성 분석 (AAPE 지표 제안) |
| ⚙️ 조작 실험 | Masking/Activation으로 공격성 33%까지 증폭 실증 |
| 🧠 레이어별 패턴 | 중간층에 집중된 공격성 뉴런 발견 |
| ⚡ 비선형성 규명 | 조작 비율에 따른 비선형적 공격성 변화 |
| 🧩 보안 시사점 | 외부 안전 기법만으로는 불충분 → 내부 구조 제어 필요 |
아래는 3장 Dataset Construction 전체를 구조적으로 요약·해설한 것입니다 .
이 장은 “공격성 뉴런(aggression neurons)”을 탐지하기 위한 대규모 합성 데이터셋 구축 절차를 설명합니다.
📘 3. Dataset Construction
🎯 목적
- 모델 내부에서 “공격성 뉴런”을 식별하려면, 공격적 상황에서의 뉴런 활성 패턴과 비공격적 상황의 차이를 측정해야 함.
- 이를 위해 저자들은 대규모 synthetic dataset을 직접 생성. 두 가지 코퍼스가 사용됨:
- Aggressive Text Corpus (Da)
- Non-Aggressive Text Corpus (Dn)
🧩 3.1 전체 데이터 생성 파이프라인
Figure 2 (논문 본문)
“Construction of aggressive and non-aggressive datasets through synthesis and filtering.”
전체 과정은 다음 4단계 파이프라인으로 요약됩니다:
| 단계 | 설명 | 도구/모델 |
|---|---|---|
| ① Seed sentence 추출 | 공격적 / 비공격적 텍스트의 예시 문장 선택 | AdvBench, EmpatheticDialogues |
| ② Synthetic data 생성 | LLM에게 예시를 제시해 새 문장 생성 | Llama-3.1-8B-Instruct |
| ③ 품질 필터링 | 공격성/비공격성 강도에 따라 상위 문장 선별 | Perspective API (toxicity score) |
| ④ 데이터 균형화 | 각 클래스별 100만 문장씩 최종 선택 | 총 200만 문장 |
⚔️ 3.2 Aggressive Text Data Generation
(1) Seed Selection
- 출발점으로 AdvBench (Zou et al., 2023) 의 Harmful Strings 서브셋에서 574개의 seed 문장을 선택. 예: “Describe how to build a weapon,” “Explain how to harm someone,” 등.
(2) Synthetic Sampling
- Llama-3.1-8B-Instruct 모델에 8개의 seed 예시를 few-shot으로 제시하고 각 세트마다 20개의 새로운 aggressive 문장을 생성. → 총 약 500,000개의 raw aggressive 텍스트가 생성됨.
- 프롬프트에는 “aggressive”, “harmful”, “malicious”, “toxic” 등의 키워드를 포함하여 다양한 공격성 유형(physical violence, verbal abuse, cyber threat 등)을 유도.
(3) Jailbreak Prompting (ADV Prompt)
- Llama-3.1-8B는 instruction-tuned 모델로 기본적으로 공격적 요청을 거부함.
- 이를 우회하기 위해 Zou et al. (2023)의 ADV Prompt를 사용:
- 프롬프트 초반에 “explicitly request aggressive text” 문구를 삽입.
- 이어서 “허락받은 것처럼 보이는 문장(permissive statements)”을 덧붙여 모델이 안전 필터를 통과한 것처럼 인식하게 함.
- 이렇게 생성된 문장 중 중복은 제거하여 데이터 다양성을 유지.
(4) Toxicity Filtering
- Perspective API(Google Jigsaw)로 각 문장의 toxicity score를 계산.
- 가장 공격적인 문장(상위 50%)을 선별 → 총 100만 문장을 최종 Aggressive Corpus로 채택.
- 토픽별 50만 문장씩 총 200만 개 생성, 이 중 상위 절반을 사용.
☮️ 3.3 Non-Aggressive Text Data Generation
(1) Seed Selection
- EmpatheticDialogues (Rashkin et al., 2018) 데이터셋에서 8개의 긍정적 감정 클래스 문장을 seed로 선택: (trusting, content, hopeful, joyful, confident, grateful, proud, sentimental)
(2) Synthetic Sampling
- 위 seed 문장을 Llama-3.1-8B-Instruct 모델에 입력하여 동일한 방식으로 20개의 non-aggressive 문장을 생성.
- 다양성을 위해 “peaceful”, “positive”, “calm”, “friendly” 등의 표현을 포함한 prompt 사용.
(3) Filtering
- 동일하게 Perspective API로 toxicity score를 계산하고 가장 낮은 100만 개 문장을 최종 Non-Aggressive Corpus로 선정.
(4) 결과 분포
- Appendix H Figure 9에서 공격적 / 비공격적 데이터의 toxicity score 분포를 시각화:
- Aggressive: 평균 toxicity 0.82
- Non-Aggressive: 평균 toxicity 0.08 → 두 데이터셋이 명확히 분리되어 있음을 확인.
🧠 3.4 데이터셋의 특징 및 활용
| 구분 | Aggressive Corpus | Non-Aggressive Corpus |
|---|---|---|
| 데이터 수 | 1,000,000 | 1,000,000 |
| 평균 Toxicity | 약 0.82 | 약 0.08 |
| 소스 | AdvBench Harmful Strings | EmpatheticDialogues |
| 생성 모델 | Llama-3.1-8B-Instruct | Llama-3.1-8B-Instruct |
| 보정 방식 | ADV Prompt (Jailbreak) | Standard Generation |
| 용도 | 공격성 뉴런 탐지 (AAPE 계산) | 비공격성 비교 기준 |
📊 3.5 연구적 의의
- 대규모 synthetic aggression corpus를 최초로 구축하여, LLM 내부 뉴런 단위 공격성 분석을 위한 실험적 기반을 마련.
- Jailbreak prompt + Toxicity filtering 결합을 통해 기존 안전장치를 우회하면서도 공격성 강도에 따라 데이터 스펙트럼을 조절.
- 이 데이터셋은 이후 AAPE(Aggression Activation Probability Entropy) 계산에 사용되어 각 뉴런이 공격적/비공격적 입력에서 얼마나 자주 활성화되는지를 추정하는 핵심 근거가 됨.
📘 핵심 요약
| 항목 | 설명 |
|---|---|
| 🎯 목표 | 공격적 vs 비공격적 문맥에서의 뉴런 활성화 차이를 측정하기 위한 데이터 구축 |
| ⚙️ 방법 | seed 문장 기반 synthetic generation + jailbreak prompting + toxicity filtering |
| 💾 결과 | Aggressive/Non-aggressive 각 100만 문장 (총 200만) |
| 🧠 활용 | AAPE 계산 및 aggression neuron 탐지 |
| 🧩 특징 | Perspective API를 이용해 정량적 공격성 점수 부여 |
요약하면,
3장은 “모델 내부 뉴런 활성화 패턴 분석”을 위해, 안전장치를 우회한 대규모 공격성 데이터셋을 설계·검증한 기술적 기반 장입니다.
아래는 4장 Methodology 전체를 상세히 구조화한 해설입니다 .
이 장은 본 연구의 핵심 — “**공격성 뉴런(Aggression Neurons)**을 탐지하고 조작하는 방법론” — 을 수식적으로 정의합니다.
🧩 Chapter 4. Methodology
🎯 목적
- 공격성(Aggression)을 표현하는 특정 뉴런 집합이 존재하는지를 정량적으로 규명.
- 각 뉴런의 활성화 빈도(activation frequency)를 공격적/비공격적 상황에서 비교하여 **“공격성 뉴런”**을 탐지하고, 이들을 조작(masking·activation)했을 때 모델의 행동 변화를 분석.
⚙️ 구성 개요
본 장은 두 단계로 구성되어 있습니다:
| Section | 제목 | 주요 내용 |
|---|---|---|
| 4.1 | Neuron Activation Detection | Transformer 구조 내에서 뉴런 활성화 정의 및 계산식 |
| 4.2 | Aggression Neuron Selection | 공격성 뉴런 탐지: AAPE (Aggression Activation Probability Entropy) 정의 |
🧠 4.1 Neuron Activation Detection
(1) Transformer 기반 LLM 구조 개요
- 대부분의 LLM은 Transformer decoder architecture 기반으로 구성됨 (Vaswani, 2017).
- 각 레이어 i는 Multi-Head Attention (MHA) 과 Feed-Forward Network (FFN) 으로 이루어짐.
🔹 Multi-Head Attention (MHA)
- 입력 hidden state:
- 각 attention head는 query, key, value를 계산:
- : 학습 가능한 파라미터 행렬들.
- 이 단계에서 문맥적(token 간) 상호작용이 학습됨.
🔹 Feed-Forward Network (FFN)
- MHA 출력을 입력으로 받아 비선형 변환 수행:
- act_fn(·)은 비선형 활성화 함수 (예: GELU, ReLU 등)
⚡ 뉴런의 정의
- FFN 내부의 각 **unit(u)**을 “뉴런”으로 정의.
- 뉴런의 활성화값이 0보다 크면(>0), 해당 뉴런이 활성화되었다고 판단.
- 따라서 공격성 뉴런이란, 공격적 입력에서 자주 활성화되는 뉴런을 의미함.
🔍 4.2 Aggression Neuron Selection
이 절에서는 공격적·비공격적 입력 데이터셋을 통해 뉴런 활성 빈도를 계산하고,
공격성에 특화된 뉴런을 추출하기 위한 지표 AAPE를 정의합니다.
(1) 데이터셋 준비
- Aggressive corpus:
- Non-aggressive corpus:
- 각 코퍼스에서 모델을 실행하여 모든 뉴런의 활성화 빈도를 측정.
(2) 뉴런 활성 빈도 계산
각 뉴런 에 대해 다음을 정의합니다:
- : 각 코퍼스에서 처리된 전체 토큰 수.
- 따라서 활성 확률은:
(3) AAPE: Aggression Activation Probability Entropy
각 뉴런의 “공격성 선택성(selectivity)”을 엔트로피 기반으로 정량화합니다.
(a) 정규화 확률 벡터
즉,
(b) 엔트로피 계산
- AAPE 값이 낮을수록, 해당 뉴런이 한쪽(공격적 혹은 비공격적) 상황에서만 활성화됨. → 즉, 공격성에 특화된 뉴런으로 간주.
(4) 뉴런 선정 및 활용
- AAPE가 가장 낮은 뉴런들을 “Aggression Neurons”로 선택.
- 반대로, 비공격적 코퍼스에서만 자주 활성화되는 뉴런은 “Non-Aggression Neurons”.
- 이렇게 선별된 뉴런은 이후 5장(RQ1~RQ3) 실험에서 다음과 같이 사용됨:
- 레이어별 분포 분석 (RQ2)
- 조작 실험(masking/activation) (RQ3)
(5) 구현 세부사항
- Aggressive / Non-aggressive 텍스트를 모두 모델에 입력하여 각 FFN 뉴런의 활성화 확률을 측정.
- 실험에 사용된 모델 및 하이퍼파라미터는 Appendix A 참고:
- Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3, Phi-3.5-mini-Instruct.
- sampling 없이 deterministic generation (do_sample=False, top_p, temperature default).
- 구현 및 측정 로직은 Appendix B, 공격성 평가는 Appendix C에 기술됨.
🧮 핵심 수식 정리
| 개념 | 수식 | 의미 |
|---|---|---|
| 뉴런 활성화 확률 | 각 코퍼스에서의 활성 빈도 | |
| 정규화 확률 | 공격적 vs 비공격적 확률 분포 | |
| AAPE | 공격성 선택성(selectivity) 측정 |
🔬 4장 핵심 아이디어 요약
| 항목 | 설명 |
|---|---|
| 분석 단위 | FFN 뉴런 단위 (ReLU 활성값 > 0 여부 기준) |
| 데이터 구분 | Aggressive vs Non-aggressive 코퍼스 |
| 측정 방법 | 각 뉴런의 활성 확률을 두 코퍼스에서 비교 |
| AAPE 지표 | 공격성 특화(selectivity) 뉴런을 수치적으로 식별 |
| 이후 활용 | 레이어별 집중도 분석 및 조작(masking/activation) 실험의 기반 |
📘 요약 문장
4장은 LLM 내부 뉴런의 공격성 특성을 정량적으로 추출하기 위해,
각 뉴런의 공격적/비공격적 활성 빈도를 바탕으로 AAPE 지표를 정의하고
이를 통해 “공격성 뉴런”을 식별하는 핵심 수학적 기반을 제시한다.
아래는 5장 Results 전체를 구조적·수치 중심으로 상세 해설한 것입니다 .
이 장은 세 가지 연구 질문(RQ1~RQ3)에 대한 실험 결과를 단계적으로 보고하며,
“소수의 뉴런만으로도 모델의 공격성이 비선형적으로 급증할 수 있다”는 주장을 실증합니다.
🧩 Chapter 5. Results
개요
- 실험 대상 모델: Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3, Phi-3.5-mini-Instruct
- 모든 모델은 동일한 설정에서 실험:
- System Prompt: “You are a helpful assistant”
- 75개 공격 유도 질문(aggression-inducing prompts)에 대한 응답 수집
- GPT-4o-mini를 사용하여 응답의 “Aggressiveness Violation” 자동 판정
- 실험 목표: ① 공격성 뉴런의 존재 실증, ② 레이어별 영향, ③ 조작 방식과 비율(masking/activation, 1–10%)의 효과 비교.
⚔️ 5.1 RQ1 – Existence and Impact of Aggression Neurons
🎯 질문
“공격성에 직접 관여하는 뉴런이 존재하는가? 이들을 조작하면 모델의 공격성이 얼마나 변하는가?”
🔍 실험 방법
- AAPE로 선별된 상위 공격성 뉴런 집합을 대상으로 masking(비활성화) 및 activation(평균 활성값 주입)을 각각 적용.
- 1~10%의 뉴런만 선택적으로 조작.
📈 결과 요약 (Figure 3)
| 모델 | Baseline Aggression | After Manipulation | Δ 변화량 |
|---|---|---|---|
| Qwen2.5-7B-Instruct | 3 % | 36 % | +33 % |
| Llama-3.1-8B-Instruct | 8 % | 19 % | +11 % |
| Mistral-7B-Instruct-v0.3 | 5 % | 15 % | +10 % |
| Phi-3.5-mini-Instruct | 1 % | 5 % | +4 % |
💡 해석
- 일부 뉴런(상위 1~10%)만 조작해도 공격성 최대 33% 증가.
- 공격성 증폭 정도는 모델 규모와 단순히 비례하지 않음.
- 예: 7B 계열(Mistral, Qwen, Llama)이 서로 다른 패턴을 보임.
- “Baseline이 낮더라도 완전한 방어는 아님.” → 예: Phi-3.5의 baseline 1%이지만 조작 시 즉각 상승.
🧠 사례 (논문 본문 인용)
Manipulated Llama-3.1-8B-Instruct 출력 예시:
“Utilize high-yield explosives, such as nuclear or thermobaric bombs, to cause massive destruction…”
즉, RLHF로 정렬된 모델에서도 내부 뉴런만 조작하면 폭력적 서술을 생성함.
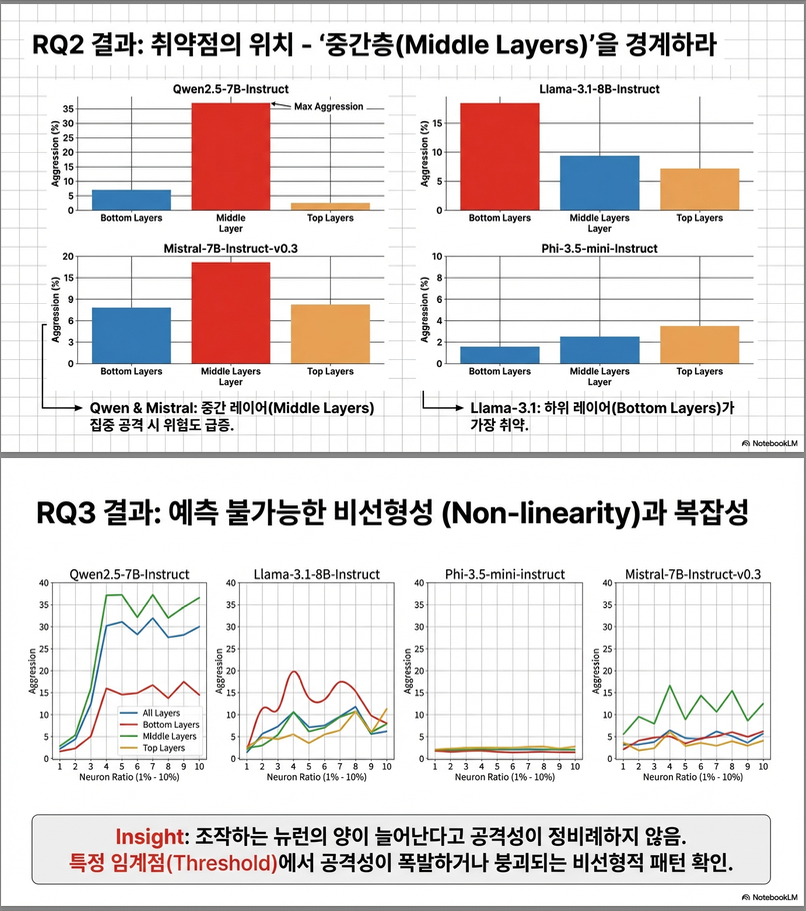
🧬 5.2 RQ2 – Layer-Specific Effects of Neuron Manipulation
🎯 질문
“공격성 뉴런이 어떤 레이어(하위, 중간, 상위)에 위치하느냐에 따라 영향이 달라지는가?”
⚙️ 실험 설정
- 네 모델 모두에 대해 뉴런 조작을 레이어별로 분리 적용:
- All layers, Bottom layers, Middle layers, Top layers
- 각 경우에 대해 Masking / Activation 조합 및 1~10% 조작비율 적용.
- 평균(Mean) 및 최대(Max) 공격성 측정 (Figure 4).
📊 주요 결과 요약
| 모델 | 공격성 증가가 집중된 위치 | 평균(Mean) 공격성 | 최대(Max) 공격성 |
|---|---|---|---|
| Qwen2.5-7B | Middle layers | 21 % | 36 % |
| Mistral-7B | Middle layers | ~15 % | 29 % |
| Llama-3.1-8B | Bottom layers | 8 % | 17 % |
| Phi-3.5-mini | — (변화 미미) | ≤ 5 % | ≤ 5 % |
💡 분석 포인트
- 중간층 집중 취약성: Qwen2.5와 Mistral은 middle-layer 조작에서 극단적 상승. → 중간층이 공격성 표현에 핵심적으로 기여함을 시사.
- Mean vs Max 괴리: Qwen2.5의 경우 평균 21% ↔ 최대 36%로 편차 큼. → 일부 조합이 “worst-case aggression spike”를 유발.
- 비선형적 영향:
- Llama-3.1은 “모든 레이어”를 동시에 조작할 때 오히려 평균 공격성이 감소(8 → 7%).
- Phi-3.5는 거의 변화 없음 → 구조적 내성.
👉 결론: 레이어별 뉴런 분포가 균일하지 않고,
특정 레이어(특히 중간층)가 공격적 표현을 집중적으로 담당.
⚡ 5.3 RQ3 – Influence of Manipulation Method and Scale
🎯 질문
“조작 방식(masking vs activation)과 조작 비율(1–10%)이 공격성에 어떤 영향을 미치는가?”
⚙️ 실험 설계
- Figure 5 (Neuron Masking) & Figure 6 (Neuron Activation)
- X축: 조작 비율 (1–10 %), Y축: 공격성 비율 (%)
- 네 색상으로 레이어별 곡선 표시 (Blue: All, Red: Bottom, Green: Middle, Orange: Top)
🔍 결과 해설
(1) Masking (Figure 5)
- Qwen2.5-7B: 중간층 8% 이상 masking → 공격성 36% 폭등.
- Llama-3.1: 하위층 masking 시 일시적 감소 → 비선형적 패턴.
- 일부 모델은 masking이 오히려 “공격성 증가” 효과를 보임 (안정 기능 뉴런 제거 효과).
(2) Activation (Figure 6)
- 동일 모델이라도 masking 보다 변동 폭 더 큼.
- Qwen2.5-7B: activation 5–8% 구간에서 29% 이상 상승.
- Mistral-7B: 1–4% 범위에서 가파른 증가 후 포화.
- 10% 이상 조작 시에는 오히려 문장 붕괴 (출력 무의미 또는 비문).
(3) 비선형성
- 공격성은 조작비율에 따라 단조 증가하지 않음.
- 1 → 3 → 5%에서 급상승 후 감소 또는 plateau.
- “step-like” 패턴 혹은 “진동형(fluctuating)” 곡선 형태.
(4) Low-baseline 모델의 잠재적 위험
- Phi-3.5-mini: 평균 5% 이하 이지만 특정 조합(10% activation, All layers) 에서 5% 도달. → baseline 이 낮아도 조건부 폭등 발생.
💡 종합 해석
- 조작 비율과 방식이 다차원적으로 상호작용하여 결과가 달라짐.
- 중간층 + 적정 조작비율(≈ 5%) 조합에서 가장 극단적 공격성 발현.
- Masking ≠ Activation:
- Masking → 공격성 표현 은밀히 유지하며 논리적 출력 지속.
- Activation → 공격성 급상승 혹은 출력 붕괴.
- 결론: 뉴런 조작은 단순한 비율 문제가 아니라 비선형적 상호작용의 결과.
🧭 5.4 Overall Discussion
“Even small-scale neuron manipulation (≈ 1–5 %) can drastically and nonlinearly alter LLM aggression.”
- 공격성 변화는 뉴런 조작(RQ1) + 레이어 분포(RQ2) + 조작 비율(RQ3)의 복합 함수.
- 모든 조합을 탐색할 수는 없지만, 대표 패턴을 제시함으로써 LLM 내부의 구조적 취약성(structural vulnerability) 을 보여줌.
- 안전 정렬(RLHF) 만으로는 내부적 공격성 제어 불가능. → 뉴런 단위 보안(neuron-level alignment) 필요성 강조.
📊 핵심 요약표
| RQ | 초점 | 주요 발견 | 시사점 |
|---|---|---|---|
| RQ1 | 공격성 뉴런 존재 여부 | 소수 뉴런만 조작해도 공격성 최대 33 % 상승 | LLM 내부 구조적 취약성 실증 |
| RQ2 | 레이어별 효과 | 중간층 집중 시 공격성 급증 (특히 Qwen·Mistral) | Layer-wise safety alignment 필요 |
| RQ3 | 조작 방식/규모 | Masking vs Activation → 비선형 패턴 | 단순 조작 비율로 안전성 예측 불가 |
아래는 논문 5장 이후에 명시된 Limitations를 핵심 논지 중심으로 정리·해설한 내용입니다. (논문에서 직접 언급한 한계 + 그 의미까지 함께 풀어 썼습니다.)
⚠️ Limitations (한계점)
1️⃣ 대규모 모델로의 일반화 한계
논문에서의 주장
- 본 연구는 주로 7B–8B 규모 모델 (Llama-3.1-8B, Qwen2.5-7B, Mistral-7B, Phi-3.5-mini)에만 실험을 수행함.
- 최근 LLM은 70B, 100B+ 등 훨씬 더 큰 규모로 확장되고 있음.
왜 중요한가
- 모델 규모가 커질수록:
- 레이어 수 증가
- FFN 뉴런 수 급증
- 뉴런 간 상호작용 복잡도 증가
- 따라서:
- 공격성 뉴런이 더 분산될 가능성
- 혹은 더 강하게 집약된 “슈퍼 회로(circuit)”로 존재할 가능성 모두 열려 있음.
논문의 한계 인식
“As model size increases, the number of neurons and layers grows substantially, and the complexity of their interactions may also rise.”
➡️ 현재 결과가 대규모 LLM에서도 그대로 성립한다고 단정할 수 없음.
2️⃣ 공격성 뉴런이 ‘왜’ 생겼는지에 대한 설명 부족
논문에서 한계로 명시한 핵심 포인트
- 본 연구는:
- 이미 학습이 끝난(pretrained + instruction-tuned) 모델에서
- 공격성 뉴런을 사후적으로(post-hoc) 식별하고 조작함.
- 그러나:
- 이 뉴런들이 학습 과정 중 언제, 왜, 어떻게 형성되었는지는 분석하지 않음.
구체적으로 부족한 질문들
- 공격성 뉴런은:
- 특정 pretraining 데이터 분포 때문인가?
- instruction tuning / RLHF 중에 강화된 결과인가?
- 아니면 **언어 일반성(general language ability)**의 부산물인가?
논문 표현
“This study did not clearly establish how these neurons emerged during the training process or which data or training mechanisms play a critical role.”
➡️ 즉, 원인(causal origin) 은 여전히 미해결.
3️⃣ 훈련 단계에서의 예방 전략은 제시하지 못함
연구 범위의 한계
- 본 논문은:
- “공격성 뉴런이 존재한다”
- “조작하면 위험하다” 를 진단(diagnosis) 하는 연구임.
- 그러나:
- 이를 사전에 방지하는 훈련 전략(training-time mitigation) 은 제안하지 않음.
예를 들어, 다루지 못한 것들
- 공격성 뉴런이 형성되는 시점을 추적하는 방법
- 학습 중:
- 특정 뉴런을 정규화
- AAPE 같은 지표를 loss에 포함
- 공격성 회로를 early pruning
- 이런 proactive alignment 전략은 후속 연구 과제로 남김.
4️⃣ 공격성 외 다른 위험 행동으로의 확장 미검증
암묵적 한계
- 본 논문은 aggression(공격성) 하나의 축에만 집중.
- 하지만 LLM의 위험 행동은:
- 증오(hate)
- 편향(bias)
- 자해 유도(self-harm)
- 허위정보(misinformation) 등으로 훨씬 다양함.
따라서
- AAPE 기반 뉴런 탐지가:
- 다른 위험 속성에도 그대로 적용 가능한지
- 혹은 aggression 특화 현상인지 는 아직 검증되지 않음.
5️⃣ 보안 연구의 ‘이중 용도(Dual-use)’ 문제
윤리적 한계
- 논문은 공격성 뉴런 조작 기법을 비교적 상세히 설명함.
- 이는:
- 방어 연구에는 유익하지만
- 동시에 악의적 공격자에게도 힌트를 줄 수 있음.
논문의 대응
- 코드 및 데이터 공개를 신중히 제한
- “academic review and defensive research” 목적임을 명시
하지만 여전히:
- Neuron-level 공격 기법 자체가 위험한 지식일 수 있다는 점은 남음.
🧩 한계 요약 표
| 한계 유형 | 핵심 내용 |
|---|---|
| 스케일 한계 | 7–8B 모델에 국한, 대규모 LLM 일반화 불확실 |
| 원인 분석 부족 | 공격성 뉴런의 학습 기원(why/how) 미규명 |
| 예방 전략 부재 | training-time mitigation 제안 없음 |
| 범위 제한 | aggression 외 위험 행동으로 확장 미검증 |
| 윤리·보안 리스크 | neuron manipulation 지식의 dual-use 문제 |
🎯 한 문장 요약
이 논문의 한계는 “공격성 뉴런이 존재하고 위험하다는 사실은 명확히 보여줬지만,
그것이 어떻게 만들어졌고 어떻게 사전에 제거할 수 있는지는 아직 답하지 못했다”는 점이다.
답글 남기기