

아래는 **arXiv 2025 논문 *“LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models”***에 대한 설명입니다. 설명은 배경 → 방법론 → 시스템 설계 → 시각화 및 결과 → 기여와 한계 순으로 정리했습니다.
1. 연구 배경과 문제의식
Logit Lens는
중간 layer의 hidden state를 최종 LM head로 바로 투사하여, “이 layer에서 이미 어떤 토큰을 예측하고 있는가?”
를 관찰하는 대표적인 mechanistic interpretability 기법입니다.
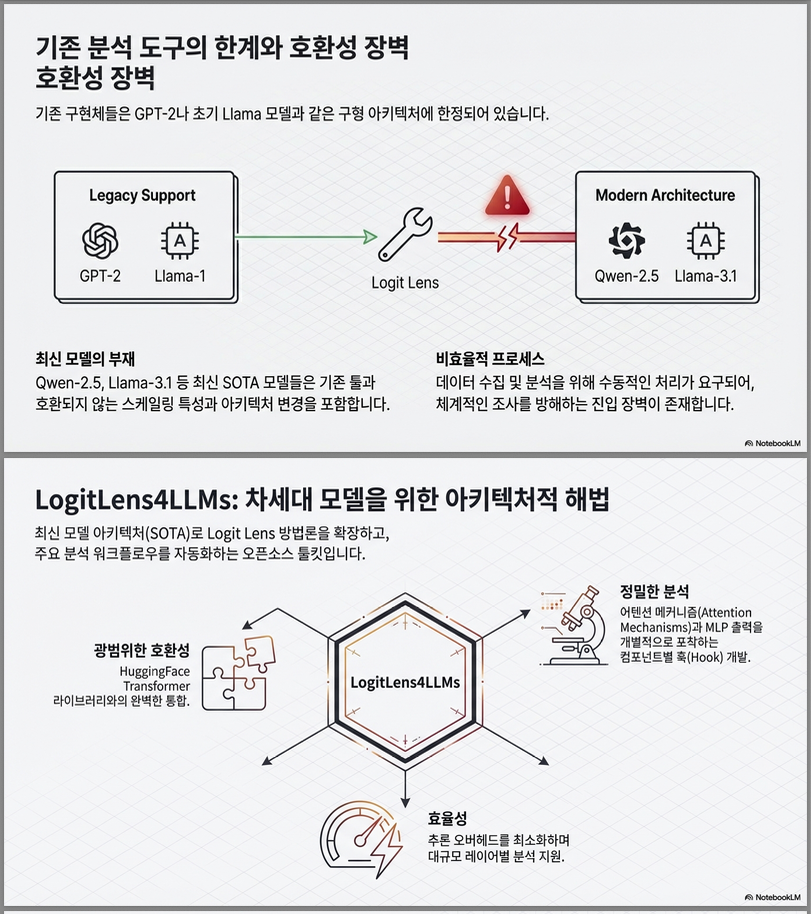
하지만 기존 Logit Lens 구현에는 명확한 한계가 있었습니다.
- 지원 모델 제한: GPT-2, 초기 LLaMA 계열 위주
- 현대 LLM 구조 미지원
- Pre-Norm 구조
- Attention / MLP 분리
- Residual stream의 복잡한 흐름
- 수작업 중심 분석
- layer별 activation 수집
- logits 계산
- 시각화 파이프라인 부재
–> 이 논문의 목표는
“현대 LLM(Qwen-2.5, Llama-3.1 등)에서도 Logit Lens를 그대로 쓰게 만들자” 입니다.
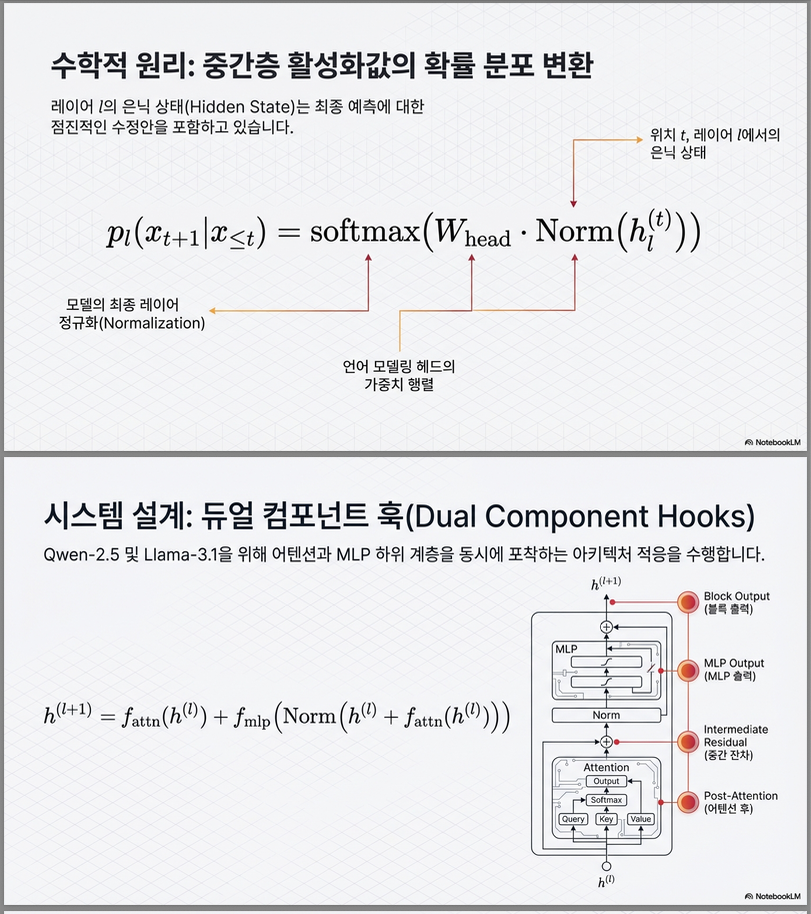
2. 핵심 아이디어 (Logit Lens의 수식적 정의)
논문은 기존 Logit Lens의 정의를 다음처럼 명확히 합니다.
- : layer , position 의 hidden state
Norm: 최종 layer norm (중요!)- : LM head (unembedding matrix)
해석:
*“layer 의 representation이 이미 어떤 다음 토큰 분포를 암묵적으로 담고 있는지”*를 보는 것
3. 방법론 핵심: 현대 LLM 구조 대응
(1) Transformer block 분해 관점
논문은 Transformer block 내부를 명시적으로 분해합니다.
이를 기반으로 4개 지점에서 activation을 포착합니다:
- Post-Attention output
- Intermediate residual
- MLP output
- Block output
– 기존 Logit Lens가 **“block output만 보는 단일 시점 분석”**이었다면,
– LogitLens4LLMs는 **“block 내부 미시적 예측 형성 과정”**까지 볼 수 있음
(2) HuggingFace 완전 호환 Hook 시스템
- gradient-preserving hook
- forward graph 보존
- inference overhead 최소화
즉, “분석 때문에 모델 구조를 망가뜨리지 않는다”는 것이 구현상의 핵심 기여입니다.
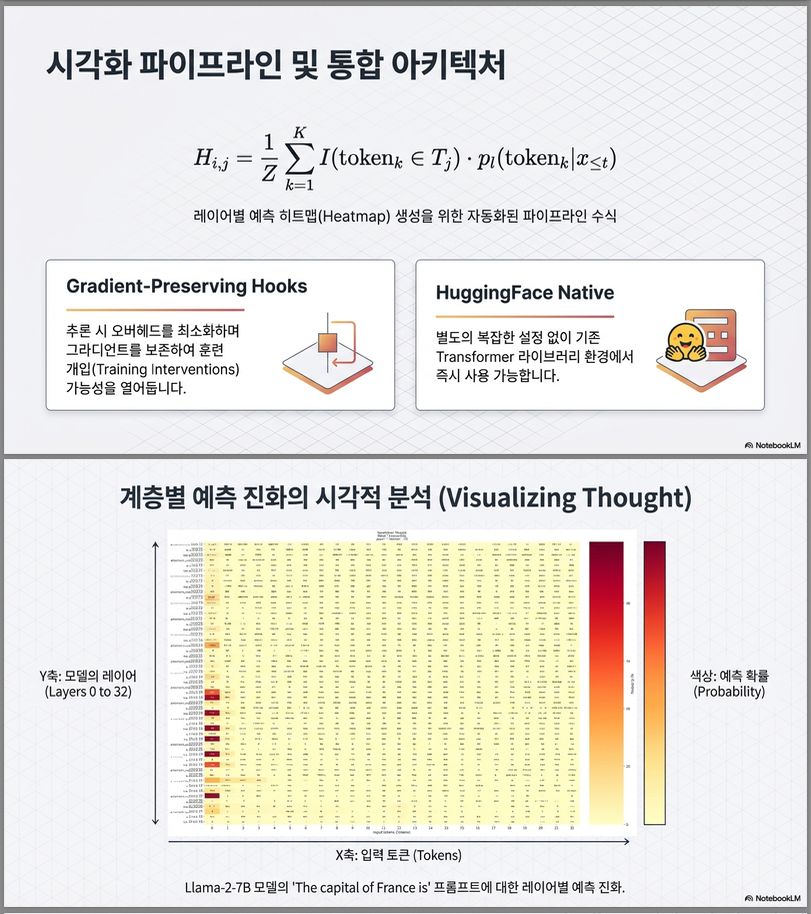
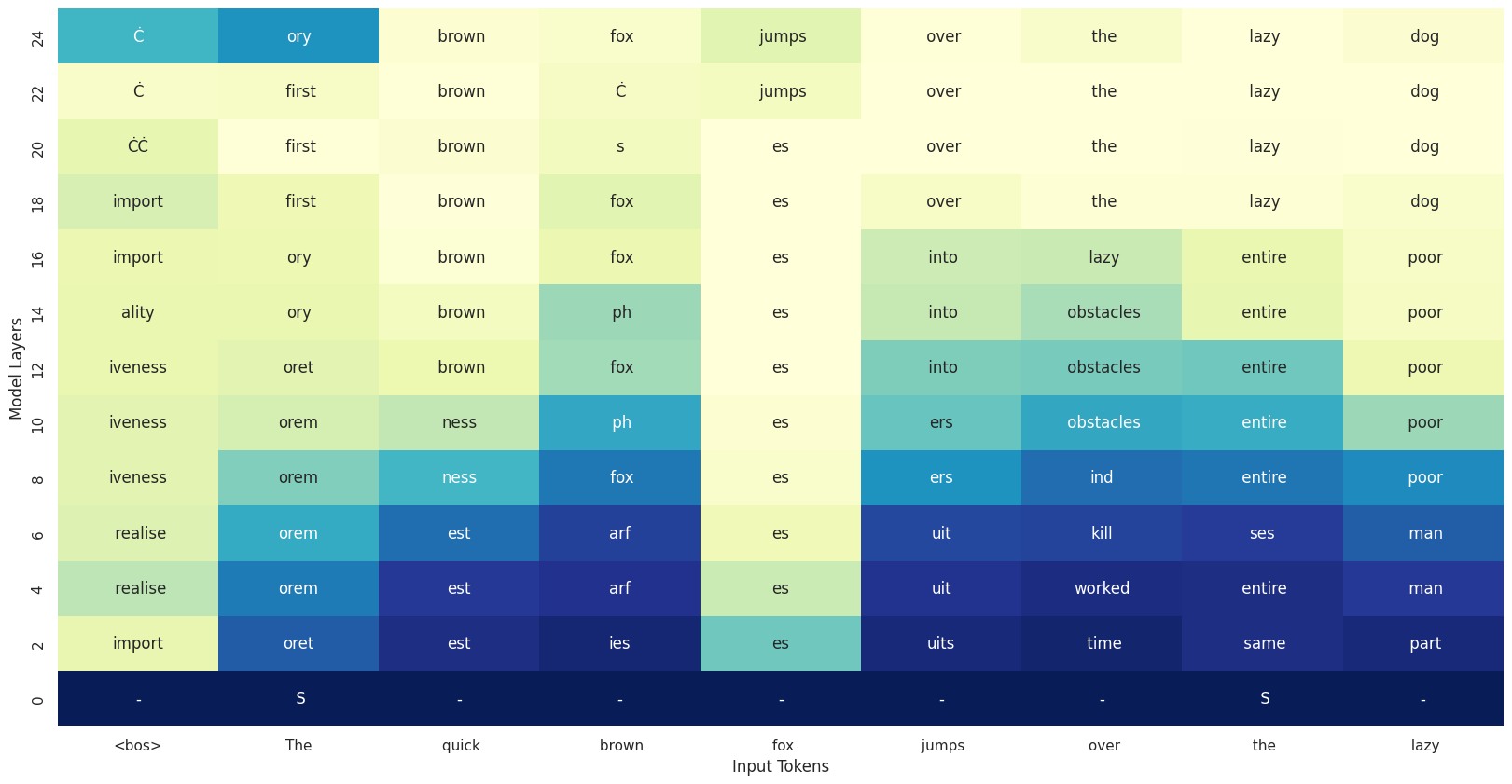
4. 자동화된 시각화 방법 (Heatmap)
논문은 layer-wise prediction을 heatmap으로 시각화합니다.
- : layer index
- : 특정 토큰
- : top-K 예측 토큰 집합
의미:
- 각 layer에서 특정 토큰이 얼마나 강하게 예측되고 있는지
- token-level probability evolution 추적 가능
5. 실험 결과 해석 (Figure 1)
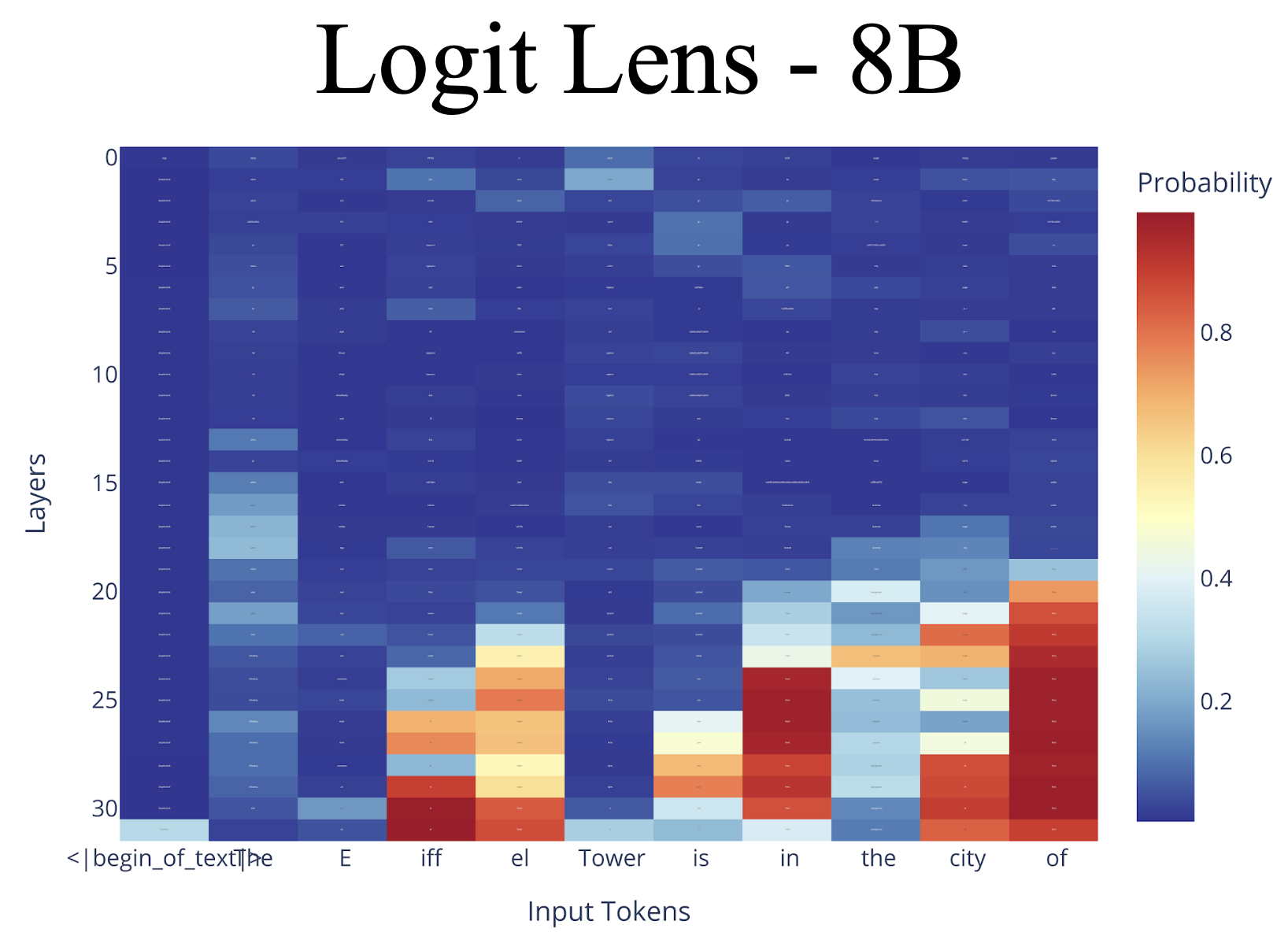
**Figure 1 (논문 p.4)**는
“The capital of France is”
라는 프롬프트에 대해 layer별 예측 분포 변화를 보여줍니다.
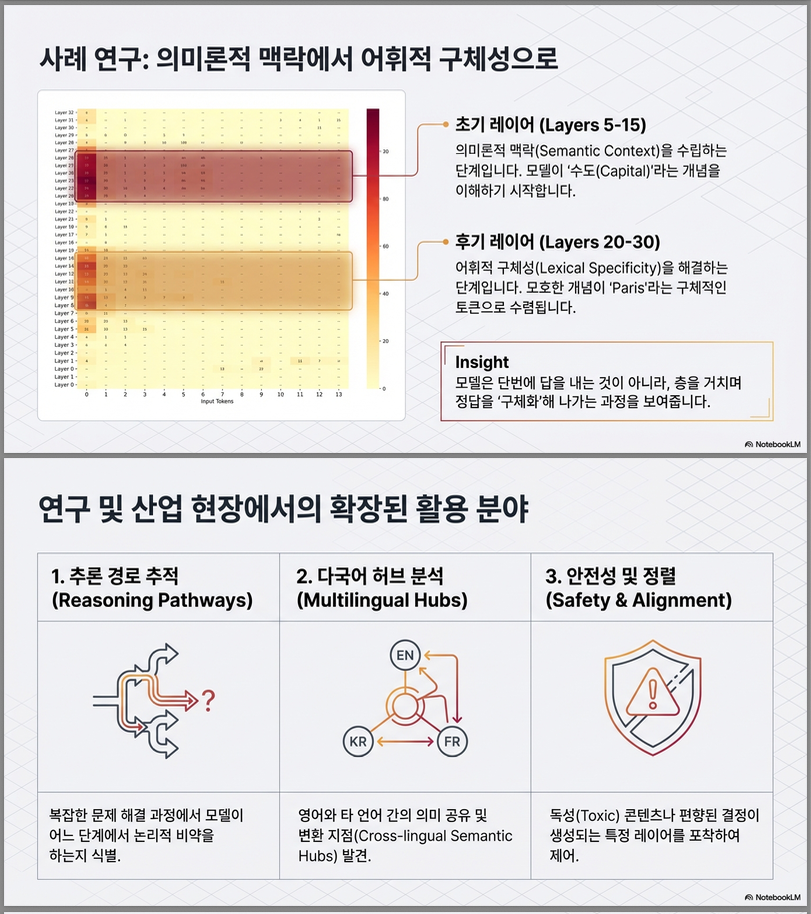
관찰 결과:
- 초기 layer (5–15)
- France, capital, Europe 등 semantic field 형성
- 중간 layer
- 후보 도시들 (Paris, Lyon 등) 등장
- 후반 layer (20–30)
- Paris로 강하게 수렴
–> 이는 다음을 시사합니다:
- 의미적 추론은 비교적 이른 layer에서 시작
- lexical disambiguation은 후반 layer에서 완료
(이는 최근 semantic hub, prediction refinement 계열 논문들과 일관됨)
6. 이 논문의 기여 요약
실질적 기여 (Engineering + Research Tool)
- 현대 LLM 완전 지원
- Qwen-2.5
- Llama-3.1
- Attention / MLP 분리 분석
- 자동화된 대규모 분석 파이프라인
- HuggingFace native 호환
- 오픈소스 제공
7. 한계와 연구적 포지션
한계
- 새로운 해석 이론 제시 X
- Tuned Lens처럼 보정 학습은 없음
- 실험은 mostly qualitative
하지만…
이 논문의 진짜 가치는:
“Logit Lens를 다시 연구 최전선으로 끌어올린 인프라 논문”
8. 한 줄 요약
LogitLens4LLMs는 Logit Lens를 현대 LLM 구조에 맞게 재설계한 실용적·연구 친화적 분석 툴킷으로, activation-level interpretability 연구의 기반 인프라를 제공한다.
다음은 LessWrong에 올라온 “Interpreting GPT: the Logit Lens” 글의 핵심 내용을 쉽게 정리한 설명입니다. (lesswrong.com)
1) 주제: GPT 내부를 들여다보는 간단한 해석 도구
이 글은 GPT 계열 언어 모델(GPT-2/3 등)의 내부 동작을 해석하려는 관찰을 소개합니다. 전통적인 해석 방법들이 주로 attention이나 hidden state를 분석하는 데 집중한 반면, Logit Lens는 *각 층(layer)에서 모델이 “무엇을 믿고 있는가?”*를 직접 보여주는 방법입니다. (lesswrong.com)
2) Logit Lens란?
Transformer 계열 LLM은 다음과 같은 구조를 가집니다:
- 입력 토큰은 embedding 공간으로 투사됨
- 여러 층을 거쳐 최종 hidden state가 생성됨
- 최종 hidden state는 unembedding(출력 projection) 행렬을 통해 어휘(토큰) 공간의 확률 분포로 변환됨
Logit Lens는 이 아이디어를 확장합니다:
–> 중간 층의 hidden state도 같은 출력 projection을 적용해 보면, 그 층에서 모델이 “예상하는” 다음 토큰 분포를 알 수 있다. (lesswrong.com)
즉, 최종 출력 뿐 아니라 층별로 예측 분포가 어떻게 만들어지는지를 관찰합니다.
3) 어떻게 동작하나?
수식으로 보면 간단합니다:
- : layer 의 hidden state
- : 어휘 공간으로 매핑하는 unembedding 행렬
이렇게 계산된 logits에 softmax를 적용하면 그 층에서의 추정 확률 분포가 됩니다. (lesswrong.com)
4) Logit Lens로 본 GPT 내부 행동
글에서 여러 가지 흥미로운 관찰이 나옵니다:
(1) 층이 올라갈수록 예측이 점점 나아진다
- 초반 층에서는 분포가 무작위이거나 엉뚱한 결과
- 중간 층에서는 그럴듯하지만 부정확한 후보
- 후반 층에서는 최종 예측에 가까운 분포
즉, 모델은 단순히 “정보를 저장 → 최종 판단”을 하는 것이 아니라 점진적으로 그럴듯한 예측으로 정제해 나간다는 것이 보입니다. (lesswrong.com)
5) 입력은 중간에 대부분 사라진다
Logit Lens 분석 결과에 따르면,
– 입력 토큰의 정보(input embedding)는 매우 초기에 사라지고,
– 모델은 곧바로 *예측 공간(prediction space)*으로 전환된 뒤
– 그 예측을 반복적으로 정제한다.
즉 GPT는 입력 문장을 그대로 보존하면서 처리하는 것이 아니라,
초반부터 “다음 토큰 예측”에 집중하는 방향으로 연산을 진행한다는 관찰이 있습니다. (lesswrong.com)
6) 어떤 인사이트를 주나?
Logit Lens는 다음과 같은 관점을 제공합니다:
– 모델이 어떻게 단계적으로 정답에 수렴하는지를 관찰
– 각 층의 예측 분포가 단순한 추측 → 정제된 언어적 이해로 바뀌는 과정 시각화
– 단지 attention 패턴이나 neuron activation만 보는 것이 아니라
–> 언어 모델의 실제 “믿음(belief)”이 어떻게 형성되는가 를 보여줌 (lesswrong.com)
7) 한계
논문/블로그 글에서도 언급하는 한계점은 다음과 같습니다:
Logit Lens는 부분적 해석 방법이며,
- 모든 정보가 드러나는 것은 아님
- 단순히 output heads를 중간 state에 적용한 것이기 때문에
- representation drift(내부 표현과 출력 표현 간의 mismatch)가 있을 수 있음 (Artificial Intelligence in Plain English)
8) 해석의 의의 (Intuition)
이 글은 mechanistic interpretability의 한 사례로,
LLM이 정보를 어떻게 내부에서 처리해나가는지
– 특히 어떤 토큰을 얼마나 빨리 자기 예측에 반영하는가를 보여주는 *직관적인 창(렌즈)*을 제공합니다. (lesswrong.com)
즉, Logit Lens는 단순히 결과를 보는 것이 아니라
**“모델이 중간 과정에서 무엇을 믿고 있는지”**를 층별로 보는 도구입니다. (lesswrong.com)
요약
- Logit Lens는 GPT 내부의 hidden state에 최종 출력 projection을 적용해서 층별 예측 분포를 살펴보는 방법입니다 (lesswrong.com)
- 층이 올라갈수록 예측이 점진적으로 정제되는 과정이 보이며,
- GPT는 입력 자체를 오래 보존하는 것이 아니라 예측 신념을 점진적으로 강화하는 방식으로 작동하는 것으로 관찰됩니다 (lesswrong.com)
- 이는 언어 모델의 내부 추론 과정에 대한 직관적 해석을 제공하는 간단하지만 강력한 시각화 도구입니다 (lesswrong.com)
답글 남기기