





아래에서는 **EMNLP 2025 논문 “Latent Inter-User Difference Modeling for LLM Personalization”**을 중심으로 관련 연구, 방법론, 실험 결과를 연구 흐름 관점에서 정리해 설명합니다. (설명은 논문 전체 내용을 종합한 요약입니다)
1. 관련 연구 (Related Work)
(1) LLM 개인화의 주류: Memory-Retrieval Paradigm
- RAG / PAG 계열
- RAG: 사용자의 과거 기록을 그대로 프롬프트에 삽입
- PAG: 과거 기록을 요약(profile)해 프롬프트에 삽입
- 장점: LLM 파라미터를 고정한 채 확장 가능
- 한계:
- 사용자 자신의 과거만 활용
- “다른 사용자와 어떻게 다른가”라는 **상대적 차이(inter-user difference)**는 충분히 모델링하지 못함
(2) Inter-User Difference를 명시적으로 다룬 연구
- DPL (Qiu et al., 2025)
- 사용자 vs 타 사용자 행동을 자연어 비교로 요약
- 심리학적 “uniqueness” 이론에 근거
- 한계 (본 논문의 문제의식):
- LLM이 자연어로 “차이”를 요약 → 통제 불가 / 누락 가능
- 타 사용자 데이터를 포함한 프롬프트가 길어져 context window 부담
(3) Latent-Space Personalization
- 최근 연구(PPlug, User-LLM 등):
- 사용자 이력을 임베딩으로 변환 후 soft prompt로 주입
- 한계:
- 대부분 절대적 사용자 표현만 사용
- “다른 사용자 대비 차이”를 구조적으로 표현하지 않음
–> 이 논문의 핵심 포지션
“Inter-user difference는 자연어가 아니라 latent embedding 공간에서 벡터 연산으로 모델링하는 것이 구조적으로 더 적합하다.”
2. 방법론 (Methodology)
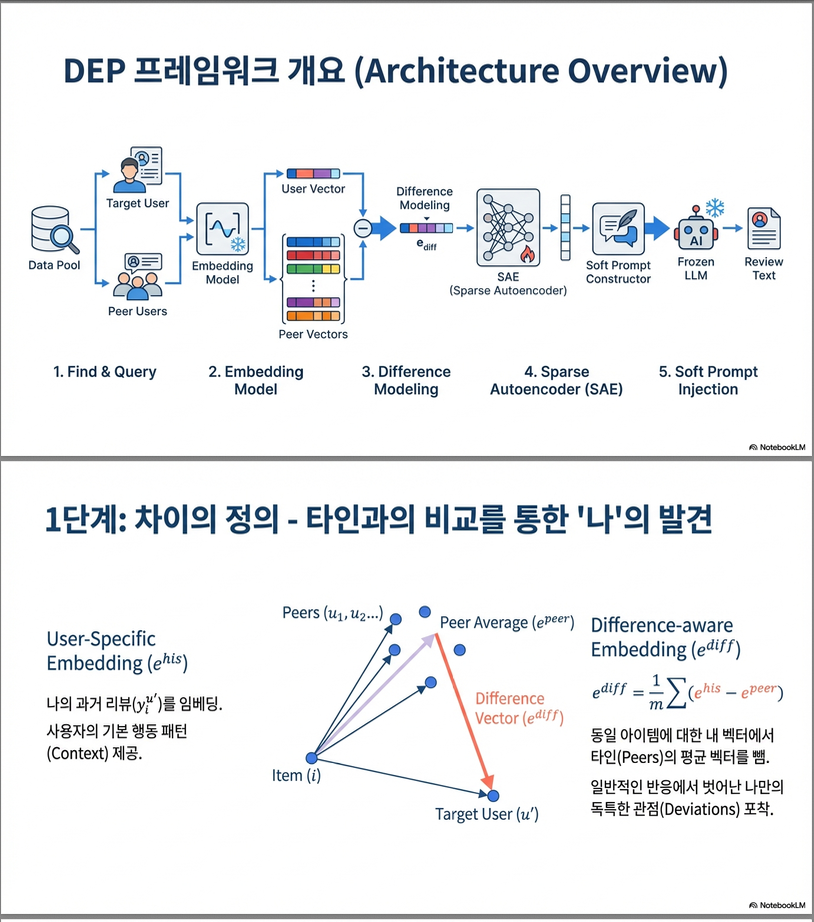
논문은 DEP (Difference-aware Embedding-based Personalization) 프레임워크를 제안합니다.
전체 구조 개요
- User-specific embedding: 사용자의 절대적 선호
- Difference-aware embedding: 타 사용자 대비 상대적 차이
- **Sparse Autoencoder(SAE)**로 task-relevant feature만 추출
- 결과를 soft prompt 형태로 LLM에 주입 (LLM은 frozen)
2.1 Latent Inter-User Difference Modeling
(1) User-specific embedding
- 사용자 u’가 아이템 i에 남긴 리뷰
- 임베딩 모델로 변환:
→ “이 사용자는 이 아이템을 어떻게 보는가”
(2) Difference-aware embedding
- 같은 아이템 i를 본 다른 사용자
- 각 리뷰 임베딩 계산
- 차이 벡터 평균:
→ “이 사용자는 다른 사용자들과 무엇이 다른가”
✔ 핵심 포인트
- 자연어 비교 ❌
- 벡터 차이 연산으로 inter-user difference를 직접 모델링
2.2 Sparse Autoencoder (Representation Distillation)
문제:
- 임베딩에는 task-irrelevant / redundant 정보가 많음
해결:
- SAE (ℓ1 sparsity) 적용
- 중요한 latent feature만 활성화
- 사용자 고유 선호 + 차이 신호를 압축
- Reconstruction loss + sparsity KL loss로 학습
–> SAE는 단순 차원 축소가 아니라
“개인화에 필요한 latent factor 선택기” 역할
2.3 Soft Prompt Injection
- SAE 출력 → projection layer → LLM embedding space
- user-specific + difference-aware prompt를 함께 삽입
- LLM 파라미터는 고정, SAE와 projection만 학습
최종 목적함수:
3. 실험 결과 (Experiments)
3.1 실험 설정
- Task: Personalized Review Generation
- Dataset: Amazon Reviews 2023 (Books / Movies & TV / CDs & Vinyl)
- Backbone LLM: Qwen2.5-Instruct (7B, 32B)
- Metrics: ROUGE-1, METEOR, BLEU, BERTScore
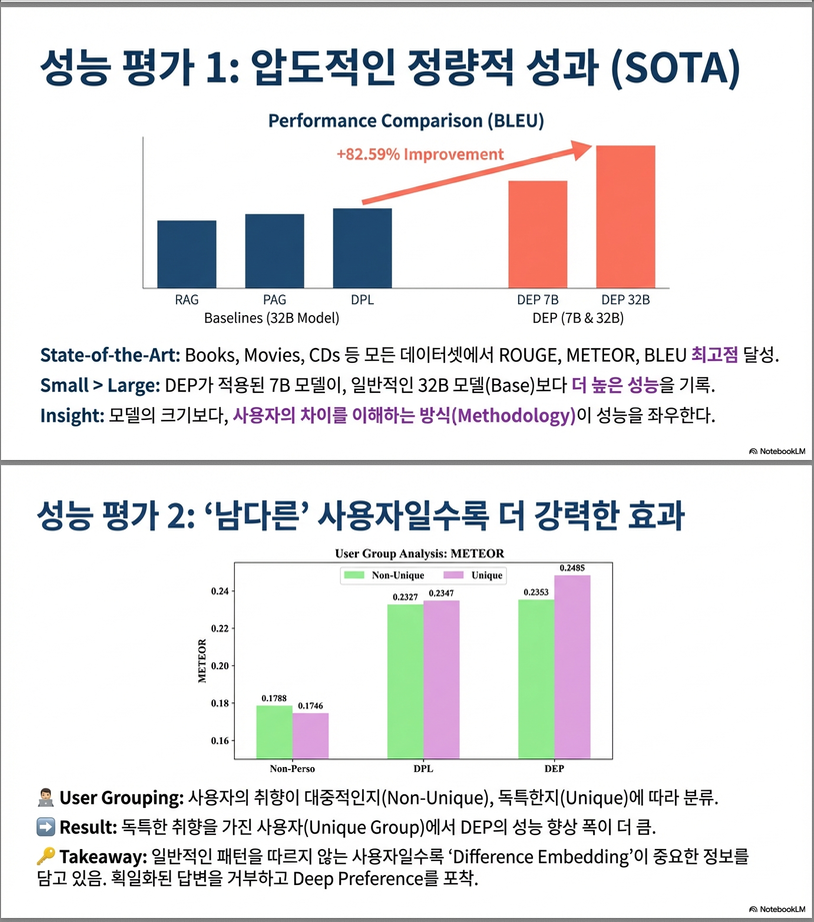
3.2 Main Results (Table 1)
핵심 결과
- DEP가 모든 데이터셋 & 모든 지표에서 SOTA
- 7B 모델임에도 32B 기반 기존 방법들보다 성능 우수
예시 (상대 개선):
- BLEU: +82%
- METEOR: +4%
- BERTScore: +6%
–> 해석:
- 단순 user embedding (PPlug) <
- 자연어 inter-user 비교 (DPL) <
- latent difference modeling + SAE (DEP)
3.3 Ablation Study
(1) User embedding 구성 (Table 2)
- his_emb 단독 ✔
- diff_emb 단독 ✔
- his_emb + diff_emb (best)
→ 절대적 선호 + 상대적 차이는 보완적
(2) Representation Refinement (Table 3)
- raw embedding ❌
- standard AE △
- SAE ✔ (항상 최고)
→ sparsity가 personalization에 핵심
3.4 Additional Analysis
(1) Retrieved history 수 (RQ3)
- K=1만 있어도 큰 성능 점프
- 이후는 diminishing return
(2) User Uniqueness (RQ4)
- “독특한 사용자(Unique)”일수록 성능 향상 큼
- DEP는 DPL보다 더 안정적이고 일관된 개선
4. 핵심 기여 요약
- 자연어 기반 inter-user comparison → latent vector difference
- difference-aware embedding이라는 명확한 구조적 정의
- SAE를 personalization-oriented feature selector로 활용
- Prompt engineering 없이도 compact & robust personalization
답글 남기기