
이 논문 **「Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models」 (ACL 2024)**은 대형 언어 모델(LLM)의 다국어 능력이 **특정한 언어 전용 뉴런(language-specific neurons)**에 의해 어떻게 형성되는지를 정량적으로 규명한 연구입니다 .
🧩 연구 배경 및 문제의식
대형 언어 모델(GPT-4, PaLM-2 등)은 주로 영어 데이터로 학습되었음에도 불구하고 여러 언어로 높은 수준의 이해 및 생성 능력을 보입니다.
그러나 이러한 다국어 능력이 내부적으로 어떻게 실현되는지는 명확히 알려지지 않았습니다.
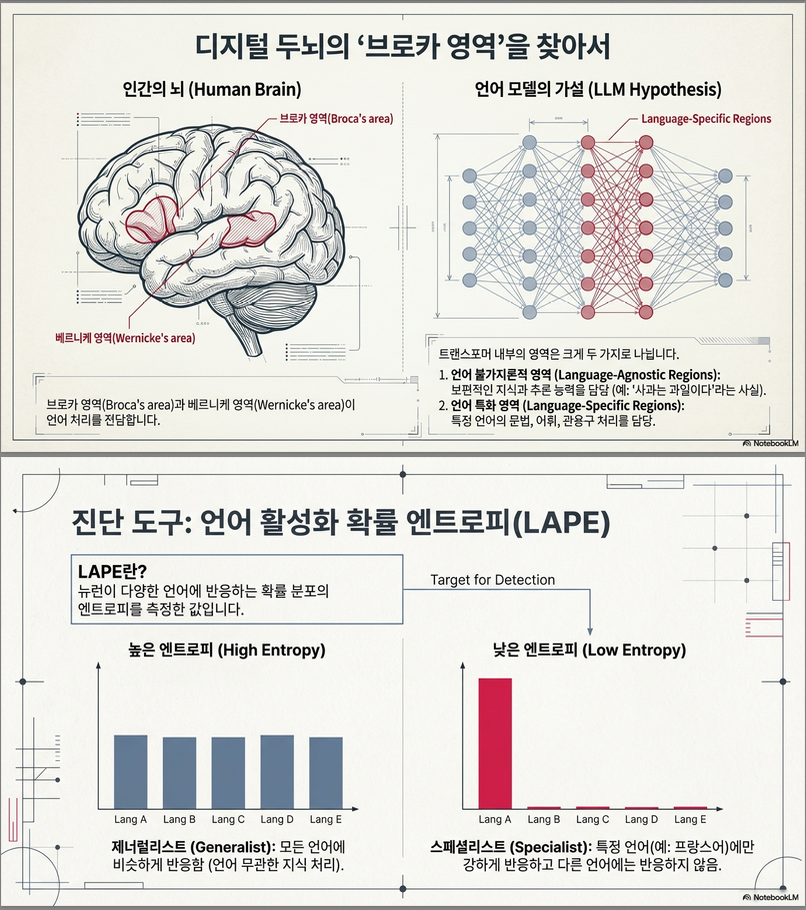
저자들은 인간의 뇌에서 **언어 처리 기능이 특정 영역(예: Broca’s area, Wernicke’s area)**에 국소화되어 있는 점에서 영감을 받아,
LLM 내부에도 언어별로 특화된 뉴런 영역이 존재할 것이라고 가정합니다.
🧠 제안 방법: LAPE (Language Activation Probability Entropy)
핵심 제안은 언어별 뉴런을 탐지하기 위한 지표인
언어 활성 확률 엔트로피 (LAPE) 입니다 .
개념적 절차
- 다국어 코퍼스 입력 여러 언어(영어, 중국어, 프랑스어 등)별 Wikipedia 문서를 모델에 입력합니다.
- 각 뉴런의 활성 확률 계산 특정 뉴런 이 언어 k의 입력에 대해 활성화되는 확률:
- 언어별 확률 분포를 정규화하고 엔트로피 계산
- 낮은 엔트로피(즉, 특정 언어에만 강하게 반응) → 언어 특화 뉴런으로 정의.
- 1% 최하위 LAPE 뉴런을 언어 전용으로 간주.
🔬 실험 설정
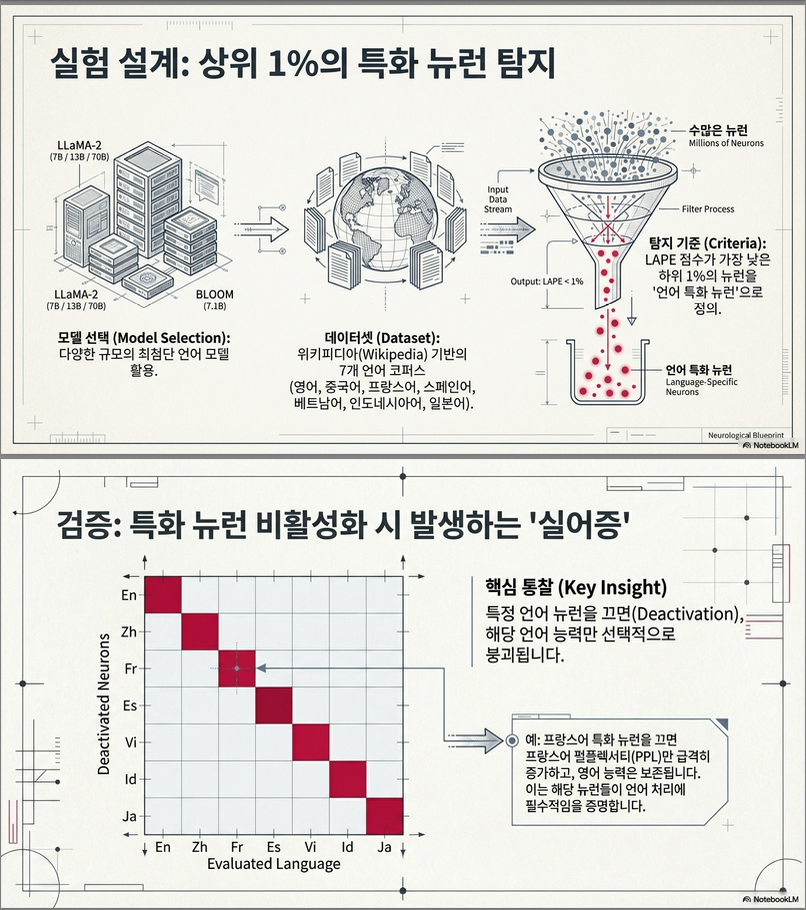
- 모델: LLaMA-2 (7B, 13B, 70B), BLOOM (7B), OPT, Mistral, Phi-2 등
- 언어: 영어(en), 중국어(zh), 프랑스어(fr), 스페인어(es), 베트남어(vi), 인도네시아어(id), 일본어(ja)
- 데이터: Wikipedia 1억 토큰/언어 + Vicuna QA dataset 번역 버전 (GPT-4 평가)
🧪 주요 실험 결과
1️⃣ 언어 능력은 일부 뉴런에 집중되어 있음
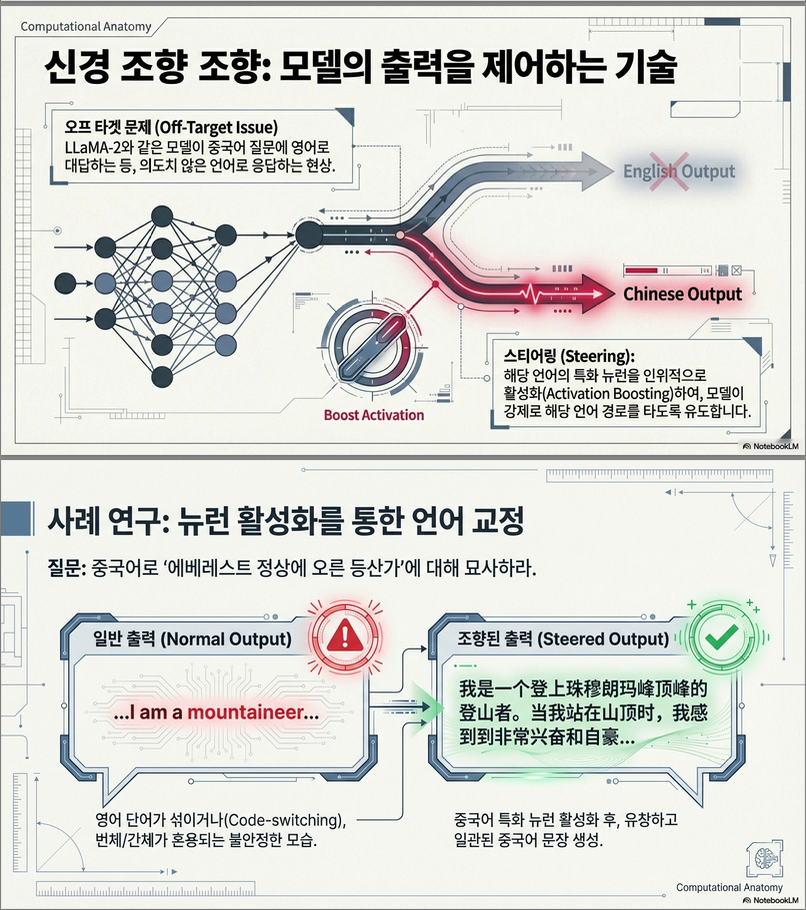
- 특정 언어 뉴런을 비활성화하면 해당 언어의 PPL이 급상승, 즉 그 언어 이해 및 생성 능력이 급격히 저하됨 .
- 반면, 다른 언어에는 거의 영향을 주지 않음 → 언어별 뉴런의 분리성 존재.
2️⃣ 뉴런의 위치 분포
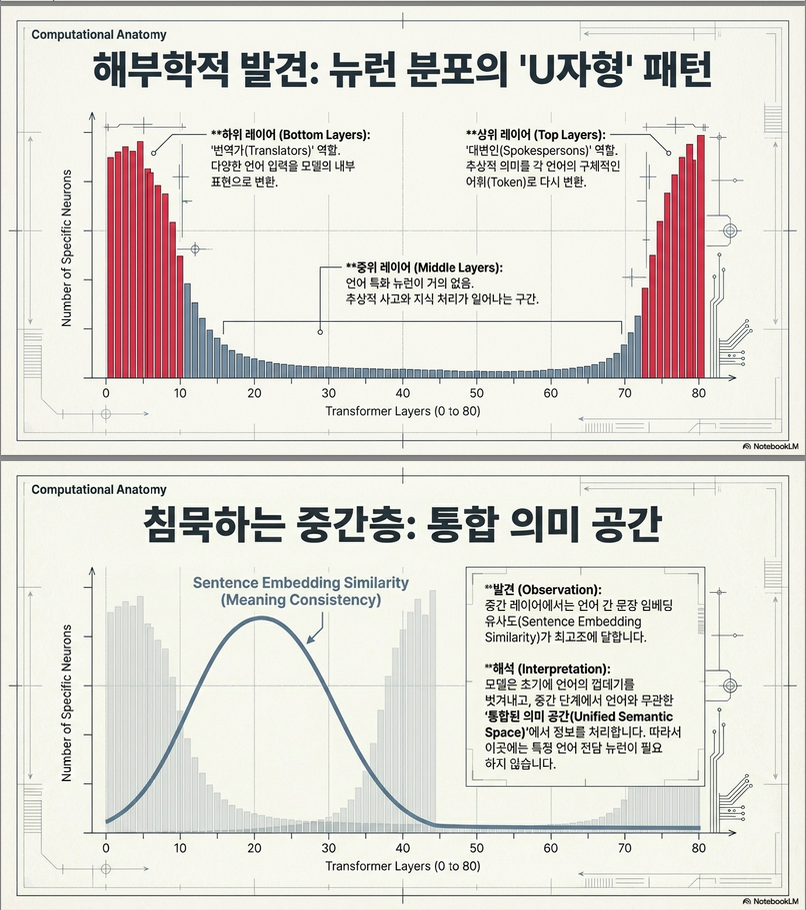
- 언어별 뉴런은 하단(bottom)과 상단(top) 계층에 집중되어 있음 .
- 하단: 입력 언어를 공통 의미 공간으로 매핑 (semantic alignment)
- 상단: 언어별 토큰으로 투사 (vocabulary mapping)
- 중간 계층은 언어 비특정(agnostic) 기능이 많음.
3️⃣ 대형 모델일수록 언어 전문화 강화
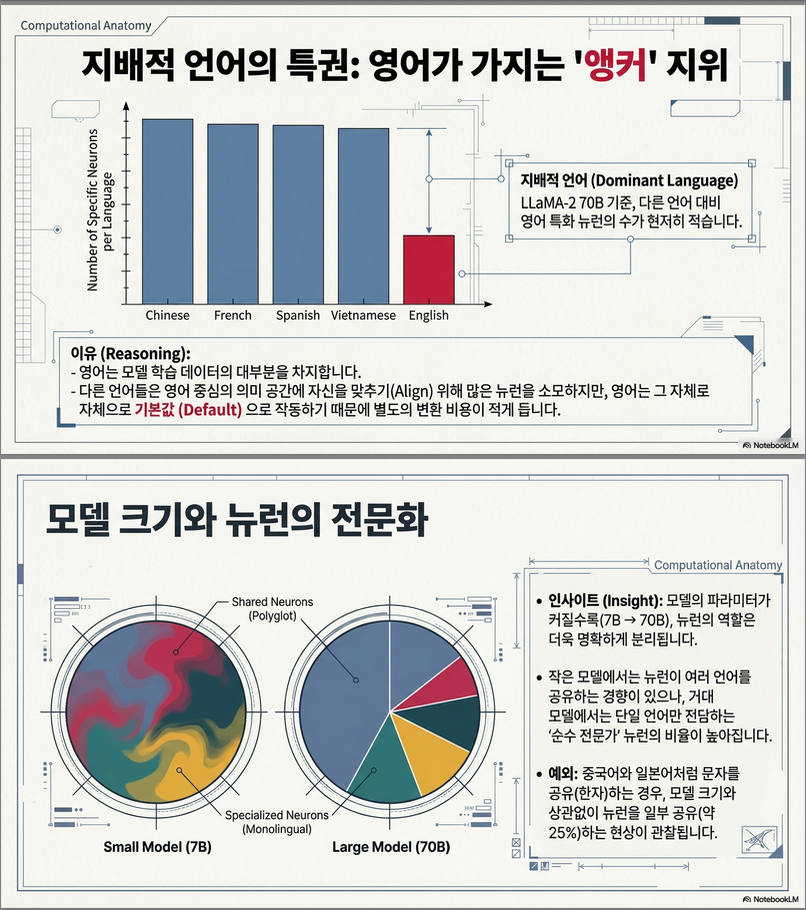
- 모델 크기가 클수록 언어별 뉴런이 명확히 분리됨.
- 중국어와 일본어는 약 25%의 뉴런이 중첩, 공통 한자 표기 때문으로 분석됨.
4️⃣ 언어 지배 관계 (Language Dominance)
- LLaMA-2에서는 영어가 중심 언어로 작용 (고자원 언어). 다른 언어의 표현이 영어 의미 공간을 중심으로 정렬됨.
- BLOOM은 다언어 학습으로 인해 중국어·영어가 동등한 중심 역할을 함.
5️⃣ 언어 제어(steering) 가능성
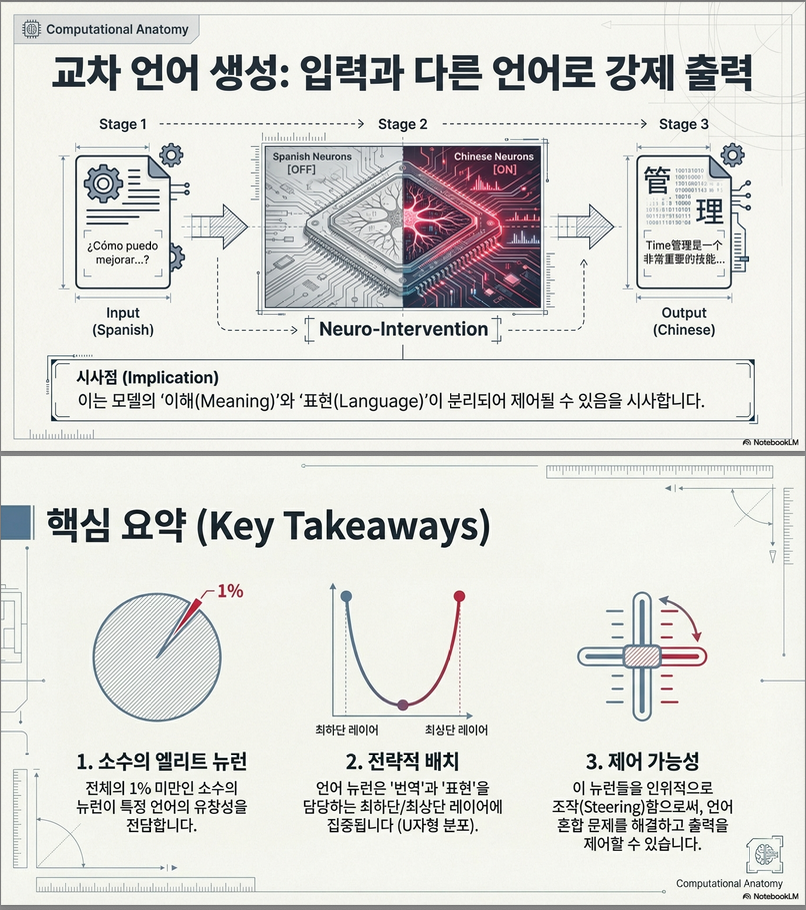
- 특정 언어 뉴런을 인위적으로 활성화/비활성화하여 모델의 출력 언어를 제어할 수 있음 .
- 예: 스페인어 질문 → 스페인어 뉴런 off + 중국어 뉴런 on → 중국어로 답변 생성
- Off-target 현상(중국어 질문에 영어 답변)을 완화하는 방법으로 활용 가능.
📚 관련 연구
- 언어 공유(neuron sharing): Knowledge neurons (Dai et al., 2022), Skill neurons (Wang et al., 2022)
- 언어 중립적 뉴런(Language-agnostic neurons): Stanczak et al. (2022), Chen et al. (2023)
- 본 연구는 **언어 특화 뉴런(language-specific neurons)**에 초점을 맞춘 최초의 LLM 분석 연구로 평가됨.
🚀 결론 및 시사점
- LLM의 다국어 능력은 전체 파라미터의 극히 일부 (<1%)의 뉴런에 의해 주도된다.
- 이러한 뉴런은 언어별로 상이하게 분포하며, 모델의 크기와 학습 데이터 구성에 따라 다르게 형성된다.
- 뉴런 조작을 통해 **LLM의 언어 출력 방향을 제어(steering)**하거나, 저자원 언어의 성능 향상에 활용할 수 있는 가능성을 제시한다.
⚠️ 한계 및 향후 과제
- 단일 언어 환경에서는 절대적인 뉴런 기준치를 정하기 어려움.
- 고자원/저자원 언어 간 경계 정의가 명확하지 않음.
- 언어별 뉴런을 **지속적 학습(continual pretraining)**이나 **지식 이전(knowledge transfer)**에 활용하는 연구가 필요함.
요약하면,
이 논문은 **“LAPE 지표를 통해 언어별 뉴런을 탐지하고, 이를 조작함으로써 LLM의 다국어 능력 구조를 해석하고 제어할 수 있다”**는 점을 실증적으로 보여준 연구입니다.
이 논문의 관련 연구(Related Work) 챕터에서는 LLM의 다국어 능력과 언어별 뉴런 분석에 대한 기존 연구들을 다룹니다. 주요 내용은 다음과 같습니다:
1. 다국어 능력(Multilingual Ability)
- 다국어 능력에 관한 연구는 다국어 모델(mBERT, XLM-R) 등의 등장과 함께 활발히 진행되었습니다 .
- 기존 연구에서는 모델이 다국어를 어떻게 처리하는지, 특히 다국어 간의 공유된 의미적 구조(cross-lingual semantic alignment)에 대한 논의가 많습니다.
- 언어 유사성(linguistic similarity) 및 훈련 설정(training settings) 등 다양한 요인이 다국어 전이 학습에 영향을 미친다고 밝혀졌습니다 .
2. 언어 공유 뉴런(Language-Agnostic Neurons)
- 언어 공유 뉴런(language-agnostic neurons)은 다국어 모델에서 특정 언어에 의존하지 않고 공통의 의미적 정보를 처리하는 뉴런을 의미합니다.
- 이전 연구들은 언어 독립적 지식(knowledge)과 작업 처리(task handling)를 위한 공유 뉴런의 역할을 다룬 바 있습니다 .
- 예를 들어, **Dai et al. (2022)**는 **지식 뉴런(knowledge neurons)**을 제시했으며, **Wang et al. (2022)**는 기술적 작업을 해결하는 **기술 뉴런(skill neurons)**에 대해 설명했습니다 .
3. 언어 특화 뉴런(Language-Specific Neurons)
- 이 연구의 핵심은 언어 특화 뉴런에 대한 분석입니다. 기존 연구들에서 다국어 모델의 언어 처리 기능은 대부분 언어-공유 뉴런에 초점을 맞추었지만, 언어별 뉴런에 대한 연구는 상대적으로 적었습니다.
- **Gurnee et al. (2023)**은 언어 모델에서 특정 뉴런의 역할을 분석한 연구를 진행했으며, 특히 음성 모델과 이미지 모델에서 뉴런이 어떻게 특정 기능을 처리하는지에 대한 연구가 있었습니다 .
4. 신경망 분석(Neuron Analysis)
- 신경망 분석은 최근 인간 뇌의 신경 과학 연구와 함께 활발히 진행되고 있습니다. **Bau et al. (2020)**는 단일 뉴런이 지식 회상을 담당한다고 분석했으며, **Sajjad et al. (2022)**은 언어 모델에서의 신경망 분석을 다뤘습니다 .
- 이러한 분석은 Transformer 모델의 특정 능력이나 기술을 이해하는 데 중요한 역할을 하고 있습니다.
5. 언어 모델에서의 뉴런 활성화(Neuron Activation)
- 본 연구와는 다르게, **Gurnee et al. (2024)**은 GPT-2 모델의 뉴런 활성화를 분석하며, 특정 뉴런이 특정 기능을 담당하는지에 대한 연구를 진행했습니다.
- **Dalvi et al. (2019)**과 **Xin et al. (2019)**은 언어 모델의 문법적 성질이나 구조적 트리거에 대응하는 뉴런의 특성을 분석한 연구를 진행했습니다 .
연구의 차별점
- 기존의 연구들이 언어 공유 뉴런에 초점을 맞추었다면, 본 연구는 언어별 특화된 뉴런에 대해 구체적으로 다루고, 이를 LAPE 방법을 통해 식별하는 새로운 방법을 제시합니다.
- 또한, 언어 특화 뉴런의 활성화가 다국어 처리에 미치는 영향과 이를 조작하여 출력 언어를 제어할 수 있는 가능성을 제시한 점에서 기존 연구들과 차별화됩니다 .
이 논문은 언어 특화 뉴런의 존재를 규명하고 이를 제어함으로써, LLM의 다국어 처리 능력을 보다 정밀하게 이해하고 활용할 수 있는 방법을 제시합니다.
이 논문의 방법론(Methodology) 챕터에서는 **언어별 뉴런(Language-Specific Neurons)**을 탐지하고 분석하는 방법을 제시합니다. 핵심적으로 **Language Activation Probability Entropy (LAPE)**라는 새로운 지표를 도입하여, LLM 내부에서 언어별로 특화된 뉴런을 식별하고, 이를 통해 다국어 모델의 능력을 설명합니다.
1. 모델 아키텍처
- 이 연구에서는 Transformer 아키텍처를 기반으로 한 대형 언어 모델(LLMs)을 대상으로 실험을 진행했습니다.
- LLaMA-2(7B, 13B, 70B), BLOOM(7B), OPT, Mistral, Phi-2 모델을 사용하여 실험을 수행하였습니다 .
2. 언어별 뉴런 탐지 (Language-Specific Neurons Detection)
이 연구에서 핵심적으로 제안된 방법은 **LAPE (Language Activation Probability Entropy)**입니다. 이 방법은 각 뉴런이 특정 언어에 대해 얼마나 강하게 반응하는지 평가하여 언어별 뉴런을 식별합니다.
2.1 언어 활성화 확률 (Language Activation Probability)
- 먼저, 각 뉴런이 특정 언어 입력에 대해 활성화될 확률을 계산합니다.
- 구체적으로, 뉴런 에 대해, 언어 k에서 그 뉴런이 활성화될 확률 는 다음과 같이 정의됩니다: 여기서, 는 활성화 여부를 판별하는 지표 함수입니다 .
2.2 LAPE 계산
- 각 뉴런에 대해 여러 언어에 대한 활성화 확률 분포 를 계산하고, 이를 L1 정규화하여 확률 분포를 유효하게 만듭니다.
- LAPE는 이 확률 분포의 엔트로피를 사용하여 계산됩니다: 여기서 는 언어별 확률 분포의 정규화된 값입니다 .
2.3 언어별 뉴런 선택
- 각 뉴런에 대해 LAPE 값을 계산한 후, 최소 엔트로피 값을 가진 뉴런을 **언어 특화 뉴런(language-specific neurons)**으로 간주합니다.
- LAPE 값이 낮을수록, 해당 뉴런은 특정 언어에 강하게 반응하고 다른 언어에는 약하게 반응하는 특성을 보입니다 .
- 본 연구에서는 LAPE 값이 **하위 1%**에 해당하는 뉴런을 선택하여, 언어별 뉴런으로 정의합니다.
3. 실험 설계 및 모델 설정
3.1 데이터셋
- 실험에는 Wikipedia 코퍼스를 사용하여 각 언어별로 1억 개의 토큰을 선택하여 모델에 입력합니다.
- 추가로 Vicuna 데이터셋을 사용하여 오픈 엔디드 생성(Open-ended generation) 능력을 평가했습니다.
3.2 모델과 실험
- 언어 모델링(Language Modeling):
- 모델의 다국어 언어 모델링 능력을 Perplexity (PPL) 점수로 평가합니다.
- 오픈 엔디드 생성(Open-ended Generation):
- 모델의 다국어 생성 능력을 GPT-4에 의해 평가합니다. 이 실험에서는 여러 언어로 된 질문에 대한 답변을 평가하고 언어 정확도(language accuracy)와 생성 품질(content quality)을 점수화합니다.
4. 언어별 뉴런 분석 (Analysis of Language-Specific Neurons)
4.1 언어 뉴런의 위치 분포
- 언어별 뉴런은 하단(bottom) 및 상단(top) 계층에 집중되어 있다는 결과를 도출했습니다 .
- 하단 계층: 다양한 언어의 입력을 공통된 의미 공간으로 매핑하는 역할을 합니다.
- 상단 계층: 의미적 처리 후 해당 언어의 어휘로 출력하는 역할을 합니다.
4.2 언어 지배 관계 (Language Dominance)
- 영어는 **고자원 언어(high-resource language)**로, 다른 언어들이 영어를 중심으로 정렬되는 경향을 보였습니다.
- **저자원 언어(low-resource languages)**는 고자원 언어에 의존하여 성능을 향상시키는 경향이 있음을 발견했습니다 .
4.3 출력 언어 조정(steering)
- 언어별 뉴런을 활성화하거나 비활성화함으로써 모델의 출력 언어를 제어하는 실험을 진행했습니다.
- 예를 들어, 스페인어 질문에 대해 중국어로 답변을 유도할 수 있었습니다 .
5. 결과 분석 및 시사점
- 실험 결과, 언어별 뉴런은 LLM의 다국어 처리 능력에 중요한 역할을 하며, 특정 언어 뉴런을 조작하여 모델의 출력 언어를 제어할 수 있는 가능성을 보여주었습니다.
- 특히, 하위 계층과 상위 계층의 뉴런들은 언어 처리에 중요한 기여를 하며, 이들 뉴런을 통해 다국어 전이(cross-lingual transfer)를 향상시킬 수 있는 가능성이 제시되었습니다 .
이 방법론은 LLM 내부의 언어별 뉴런을 체계적으로 분석하고, 이들 뉴런을 활용하여 모델의 다국어 능력을 정확하게 조작할 수 있는 새로운 방법을 제시합니다.
2. 언어별 뉴런 탐지 (Language-Specific Neurons Detection) 절은 이 연구의 핵심 방법론으로, **LAPE(Language Activation Probability Entropy)**를 이용해 **언어별로 특화된 뉴런(language-specific neurons)**을 정량적으로 찾아내는 과정을 기술하고 있습니다.
아래는 원문을 기반으로 한 세부 구조적 설명입니다 .
🔹 2. 언어별 뉴런 탐지 (Language-Specific Neurons Detection)
2.1 배경 (Background)
- LLM은 Transformer 구조를 기반으로 하며, 각 층(layer)은 **Multi-Head Self-Attention (MHA)**와 **Feed-Forward Network (FFN)**으로 구성되어 있습니다.
- 특히 FFN은 언어 표현 및 의미적 정보를 처리하는 데 핵심적인 부분으로, **언어별 반응성(neuron activation)**을 관찰하기에 적합한 영역입니다.
(1) Transformer FFN의 기본 구조
Transformer의 각 층에서 FFN은 다음과 같이 정의됩니다:
여기서,
- 은 활성화 함수 (예: GELU)
- FFN의 각 열(column)은 하나의 뉴런을 형성합니다.
최근의 LLM (예: LLaMA)은 Gated Linear Unit (GLU) 변형을 사용하며:
이때,
뉴런 은 일 때 **활성화(activated)**된다고 간주합니다 .
2.2 언어 활성 확률(Language Activation Probability)
각 뉴런이 특정 언어 입력에 대해 얼마나 자주 활성화되는지를 확률적으로 측정합니다.
(정의)
뉴런 가 언어 k의 입력에 대해 활성화될 확률 는 다음과 같습니다:
여기서:
- 는 indicator function (뉴런이 활성화되면 1, 아니면 0)
- 는 입력 샘플 전반에 대한 평균 (경험적 확률)
즉, 는 언어 k의 입력을 처리할 때 j번째 뉴런이 활성화될 확률을 나타냅니다.
2.3 언어 활성 확률 분포 및 정규화
- 하나의 뉴런 에 대해, 여러 언어(예: 영어, 중국어, 프랑스어, 스페인어 등)에 대한 확률값들을 모으면 다음과 같은 분포를 얻습니다: 여기서 L은 전체 언어 수입니다.
- 이 확률벡터는 L1 정규화를 통해 확률 분포로 변환됩니다:
2.4 언어 활성 확률 엔트로피 (Language Activation Probability Entropy, LAPE)
(정의)
정규화된 확률분포 를 사용해 엔트로피를 계산함으로써, 특정 뉴런이 언어별로 얼마나 편향되어 활성화되는가를 수치화합니다:
- LAPE 값이 낮을수록, 그 뉴런은 특정 언어에만 강하게 반응하는 경향이 있습니다.
- 반대로, 높은 LAPE는 여러 언어에 고르게 반응하는 **언어-공유 뉴런(language-agnostic neuron)**을 의미합니다 .
2.5 언어별 뉴런 선정 절차 (Selection Criteria)
- LAPE 계산: 모든 뉴런에 대해 LAPE 점수를 계산합니다.
- 하위 백분위수 선택: LAPE 값이 **가장 낮은 하위 1%**의 뉴런을 선택합니다. → 이들은 특정 언어에 강하게 반응하는 후보로 간주됩니다.
- 활성화 임계값(activation threshold): 너무 약하게 활성화되는 뉴런을 제거하기 위해, (논문에서는 예시로 사용) 인 뉴런만을 언어 k 전용으로 최종 선정합니다.
- 결과: 이렇게 선택된 뉴런들이 곧 **언어별 뉴런(language-specific neurons)**이며, 전체 모델 뉴런 수의 약 1% 미만에 해당합니다.
2.6 데이터셋 및 구현 세부사항
- 데이터 소스: Wikipedia의 다국어 버전 사용. 각 언어당 **1억 토큰(100M)**을 샘플링.
- 언어 구성: English, Chinese, French, Spanish, Vietnamese, Indonesian, Japanese.
- 평가 대상 모델: LLaMA-2 (7B/13B/70B), BLOOM (7B), OPT (6.7B), Mistral (7B), Phi-2 (2.7B).
- 활성화 계산: FFN의 모든 뉴런에 대해 언어별 확률 분포와 LAPE 스코어를 계산.
2.7 요약: LAPE의 직관적 의미
| 구분 | 엔트로피 높음 | 엔트로피 낮음 |
|---|---|---|
| 활성화 분포 | 여러 언어에 고르게 반응 | 특정 언어에만 강하게 반응 |
| 뉴런 성격 | 언어-공유(agnostic) 뉴런 | 언어-특화(specific) 뉴런 |
| 역할 예시 | 공통 문법, 의미 구조 | 어순, 문법, 어휘 차이 |
🔍 핵심 요약
- LAPE는 “뉴런의 언어 선택성(language selectivity)”을 측정하는 척도입니다.
- LAPE가 낮은 뉴런은 특정 언어의 처리에 결정적인 역할을 하며, 이들 뉴런을 조작함으로써 LLM의 언어 출력 방향을 제어할 수 있습니다.
- 이러한 접근은 기존의 Language-Agnostic 분석(예: Cross-lingual alignment)과 달리, 뉴런 단위로 언어별 특화 구조를 해석하는 데 초점을 둔다는 점에서 차별화됩니다.
정리하면, 2장에서는
“언어 입력에 따른 뉴런 활성 확률의 엔트로피(LAPE)”를 계산하여
“언어별로 특화된 뉴런을 자동 식별”하는 방법을 제안했습니다.
이 방법은 이후 실험(§3)에서 다국어 성능 저하·출력 제어 등의 형태로 그 타당성이 검증됩니다.
아주 정확한 질문입니다 — 이 논문에서 등장하는 i와 j 인덱스는 **뉴런의 위치를 식별하기 위한 계층(layer)과 뉴런(neuron)**의 인덱스이며, **활성 확률 **는 **토큰 단위(token-level)**로 계산된 후 언어별 평균값으로 집계됩니다.
아래는 논문 원문(2.2절) 수식과 저자들의 서술을 기반으로 한 상세한 해석입니다 .
🔹 인덱스 i와 j의 의미
논문에서는 각 LLM이 Transformer 블록으로 구성되어 있으며, 각 블록 안의 **Feed-Forward Network (FFN)**에는 수십만 개의 뉴런이 존재합니다.
이때 인덱스는 다음과 같이 정의됩니다:
| 기호 | 의미 |
|---|---|
| i | 레이어 인덱스 (layer index) — Transformer의 i번째 층 (예: LLaMA-2-70B는 약 80층) |
| j | 뉴런 인덱스 (neuron index) — 해당 레이어의 FFN 내부에서 j번째 뉴런 (보통 4d개의 뉴런 존재) |
| k | 언어 인덱스 (language index) — 실험 대상 언어 (예: en, zh, fr, es 등) |
즉,
는 “i번째 레이어의 j번째 뉴런”을 의미하며,
이 뉴런이 **언어 k**의 입력에 대해 얼마나 자주 활성화되는지를 측정하는 것이 입니다.
🔹 확률 계산 방식
논문에서 정의된 언어별 활성 확률 식은 다음과 같습니다:
이 수식의 의미를 단계별로 풀면 다음과 같습니다.
① 입력 단위 (token-level) 측정
- LLM은 입력 문서를 토큰 단위로 처리하므로, 각 토큰 t에 대해 FFN에서 생성된 활성화값(activation value) 을 계산합니다.
- 이 값이 0보다 크면 해당 뉴런이 **“활성화됨(activated)”**으로 간주합니다.
② 언어별 평균 (expectation over tokens)
- 한 언어 k에 대해 모든 토큰 에 대해 위 indicator를 평균합니다: 여기서 는 언어 k 코퍼스의 전체 토큰 수 (논문에서는 약 1억 토큰)입니다.
즉,
는 “언어 k의 입력 토큰들 중에서, i번째 레이어의 j번째 뉴런이 활성화된 비율(확률)”을 의미합니다.
③ 확률 분포 및 정규화
- 모든 언어에 대해 확률을 계산하면, 뉴런별로 다음과 같은 벡터를 얻게 됩니다:
- 이를 L1-normalization으로 정규화하여 각 뉴런의 언어별 확률분포로 변환합니다:
- 그 후 엔트로피를 계산해 LAPE 스코어를 얻습니다.
🔹 핵심 요약
| 항목 | 의미 |
|---|---|
| i | Transformer의 레이어 인덱스 |
| j | 해당 레이어의 뉴런 인덱스 |
| k | 실험 대상 언어 인덱스 |
| 언어 k 입력 토큰 중 뉴런 (i,j)이 활성화된 비율 | |
| 계산 단위 | **토큰 단위 (token-level)**로 indicator 값을 측정한 후, 언어별 평균 |
| 결과 의미 | “이 뉴런이 언어 k를 처리할 때 얼마나 자주 활성화되는가”를 확률적으로 표현 |
🔍 직관적 예시
예를 들어 LLaMA-2-70B의 layer 10, neuron 5423을 생각해봅시다.
| 언어 | 활성화 확률 p_{k,i,j} |
|---|---|
| 영어(en) | 0.02 |
| 중국어(zh) | 0.83 |
| 프랑스어(fr) | 0.05 |
| 스페인어(es) | 0.07 |
→ 정규화 후 = (0.02, 0.83, 0.05, 0.07)
→ LAPE = 0.42 (낮음)
⇒ “이 뉴런은 중국어에 특화되어 있다(language-specific to Chinese)”로 분류됩니다.
✅ 정리
- i: 층(layer)
- j: 뉴런(neuron)
- : 언어 k의 토큰 단위 활성화 비율
- 계산은 토큰 단위, 통계는 언어 단위 평균
- 따라서 LAPE는 “뉴런이 언어별로 얼마나 선택적으로 활성화되는지”를 수치화한 지표입니다.
**실험 결과(Section 3: Experiments)**는 제안한 LAPE(Language Activation Probability Entropy) 방법이 실제로 언어별 뉴런을 정확히 식별하고, 이 뉴런들이 LLM의 다국어 처리 능력에 핵심적인 역할을 함을 체계적으로 검증하는 부분입니다.
아래는 논문 본문의 주요 결과를 수치, 그림, 테이블 중심으로 정리한 심층 요약입니다 .
🧪 3. 실험 (Experiments)
3.1 실험 환경 (Experimental Setup)
🔹 모델
- LLaMA-2 (7B / 13B / 70B)
- BLOOM-7B1
- OPT-6.7B, Mistral-7B, Phi-2 (2.7B)
- 추가로 LLaMA-2-Chat 버전 실험도 수행.
🔹 언어
영어 (en), 중국어 (zh), 프랑스어 (fr), 스페인어 (es), 베트남어 (vi), 인도네시아어 (id), 일본어 (ja)
(BLOOM에는 ja 제외, 학습 데이터에 없음)
🔹 데이터
- Wikipedia 각 언어당 1 백만 토큰 (언어 모델링용)
- Vicuna Dataset (오픈엔디드 생성 평가용) – GPT-4로 번역 및 채점
🔹 평가지표
- 언어 모델링: Perplexity (PPL) 변화량
- 생성 품질: GPT-4 평가 점수 (1 ~ 10 점)
- 언어 정확도: langdetect 패키지로 출력 언어 판별
🔸 3.2 주요 결과 1 – LAPE 가 가장 정확한 언어별 뉴런 탐지 법
비교 대상 방법
- LAPE (ours) – 언어별 활성 확률 엔트로피
- LAP – 언어별 활성 확률 임계값 > 0.95 일 때 선택
- LAVE – 활성 값 평균의 엔트로피 사용 (확률 대신 값)
- PV – 언어별 파라미터 변동량 (Parameter Variation)
- RS – 무작위 선택 (랜덤 기준선)
🧭 Figure 2 결과 – PPL 증가 행렬
- 각 행(row)은 비활성화한 언어의 뉴런을, 각 열(column)은 평가한 언어의 PPL 증가량을 표시.
- 즉, 대각선 값이 크면 “그 언어 뉴런을 꺼면 그 언어 성능이 심각하게 저하된다” 는 의미.
✅ 결과 해석
- LAPE 행렬에서만 뚜렷한 대각선 패턴 (zh-zh, fr-fr, es-es 등) → 언어별 뉴런을 정확히 찾아냄.
- 다른 방법들 (LAVE, LAP, PV) 은 언어 간 교차 간섭(cross-lingual interference)이 발생.
- 랜덤 선택 (RS)은 변화 미미.
📈 결론: LAPE 가 유일하게 명확한 언어별 지역성을 보여줌.
🔸 3.3 결과 2 – 모델 크기와 유형에 따른 일관성 (Figure 3)
- LAPE 를 LLaMA-2 (7B, 13B, 70B), BLOOM, OPT, Mistral, Phi-2 등에 적용.
- 모든 모델에서 대각선 패턴 유지, 즉 언어별 뉴런 존재 확인.
- 모델 크기가 클수록 뉴런의 언어 선택성이 강화됨.
- 중국어 ↔ 일본어 뉴런 약 25 % 중첩 → 공통 한자 표기 영향.
🔸 3.4 결과 3 – 생성 품질 평가 (Table 1 & 2)
(1) Table 1 – LLaMA-2 (70B) Vicuna 생성 평가
| 비활성화 상태 | zh | fr | es | vi | id | ja |
|---|---|---|---|---|---|---|
| 정상 (Normal) | 4.30 | 4.19 | 3.51 | 3.70 | 4.16 | 2.86 |
| 무작위 (Random) | 4.18 | 4.22 | 3.35 | 3.53 | 4.42 | 2.99 |
| 중국어 뉴런 비활성 | 2.46 | 3.56 | 2.96 | 3.64 | 3.56 | 2.31 |
| 프랑스어 뉴런 비활성 | 3.69 | 2.50 | 2.29 | 3.01 | 3.59 | 2.76 |
| 스페인어 뉴런 비활성 | 3.51 | 2.57 | 2.01 | 3.14 | 3.34 | 2.56 |
👉 특정 언어의 뉴런을 꺼면 그 언어의 생성 품질이 급격히 저하됨.
다른 언어에는 영향 적음 → 뉴런 의미 분리 (Language Locality) 확인.
(2) Table 2 – 중국어 출력 예시
- 정상 출력: 간체 중국어로 자연스러운 응답.
- 중국어 뉴런 비활성: 혼합 출력(繁體字 + 영문) 발생. → “當我站在珠my朗ma峰頂峰…” 등 비정상적 코드스위칭.
💡 언어 특화 뉴런이 실제 출력 언어 구성에 직접 영향을 미침.
🔸 3.5 결과 4 – 언어별 뉴런 분포 및 비율 (Table 3, Figure 4 ~ 6)
(1) Table 3 – LLaMA-2-70B 언어별 뉴런 수
| 언어 | 뉴런 수 |
|---|---|
| en | 836 |
| zh | 5 153 |
| fr | 6 082 |
| es | 6 154 |
| vi | 4 980 |
| id | 6 106 |
| ja | 5 216 |
→ 영어 뉴런 수 가 가장 적음.
즉 고자원 언어는 상대적으로 적은 전용 뉴런만으로 처리 가능,
저자원 언어는 보다 많은 전용 뉴런이 필요함.
(2) Figure 4 – 뉴런 비율 에 따른 PPL 변화
- 프랑스어 뉴런 비활성화 비율 1%→10%로 늘릴수록, 프랑스어 PPL 폭등 (성능 급락).
- 스페인어 처럼 유사 언어에서도 약간의 성능 감소 발생 (linguistic proximity 효과).
(3) Figure 5 – 계층별 뉴런 분포
- U-shape 패턴: 하단 (bottom) 및 상단 (top) 층에 언어 특화 뉴런 집중.
- 하단층: 다국어 입력을 공통 의미 공간으로 정규화.
- 상단층: 의미를 언어별 어휘로 투사.
- 중간층은 언어 비특정적(agnostic).
(4) Figure 6 – SES (Mean Sentence Embedding Similarity)
- 다국어 문장쌍의 층별 의미 유사도 곡선 → 뉴런 분포와 역상관. 즉, SES가 높은 층(의미 공유 높음)에서는 언어별 뉴런 적음.
🔸 3.6 결과 5 – 언어 지배(Dominance) 관계 (Figure 7)
- LLaMA-2에서는 영어가 모든 언어의 의미 공간의 중심. → 다른 언어의 문장 표현이 영어 공간에 정렬됨.
- BLOOM에서는 영어와 중국어 공동 지배 구조 (다언어 학습 효과).
- 이는 고자원 언어 → 저자원 언어 지식 전이 의 가능성 을 시사.
🔸 3.7 결과 6 – 언어 제어 (Steering) 실험 (Table 4 & 5)
(1) Table 4 – 언어 정확도 및 콘텐츠 품질
| 언어 | Language Accuracy (Normal → Steered) | Content Score (Normal → Steered) |
|---|---|---|
| zh | 0.87 → 0.99 | 4.30 → 4.57 |
| fr | 0.73 → 0.90 | 4.19 → 4.35 |
| id | 0.40 → 0.99 | 4.16 → 4.28 |
→ 언어별 뉴런을 인위적으로 활성화하면 모델이 그 언어로 정확히 응답하며, 콘텐츠 품질도 향상됨.
→ “오프타겟 언어 출력”(예: 중국어 질문에 영어 답변)을 효과적으로 억제.
(2) Table 5 – 크로스 언어 생성 예시
- 질문: 스페인어 입력
- 조작: 스페인어 뉴런 off + 중국어 뉴런 on
- 결과: 유창한 중국어 응답 생성 → 뉴런 조작을 통해 출력 언어를 자유롭게 전환 가능.
🧩 핵심 요약
| 결과 항목 | 핵심 발견 |
|---|---|
| 언어별 뉴런 탐지 | LAPE 만이 명확히 언어별 로컬 뉴런 식별 가능 (Figure 2) |
| 모델 일관성 | 모델 크기 ↑ → 언어 분리성 ↑ (Figure 3) |
| 출력 품질 | 특정 언어 뉴런 off → 그 언어 생성 품질 심각 저하 (Table 1) |
| 뉴런 분포 | Top/Bottom 층에 집중, U-shape (Figure 5) |
| 언어 지배 | 고자원 언어 (영어) 가 중심 공간 형성 (Figure 7) |
| 언어 조작 | 뉴런 활성화로 출력 언어 제어 가능 (Table 4 & 5) |
🧠 요약 결론
LLM의 다국어 능력은 전체 뉴런의 극히 일부(약 1 %)에 의해 좌우되며,
이 언어 특화 뉴런들은 모델의 하단과 상단 층에 집중되어 있고,
이들을 조작함으로써 출력 언어를 의도적으로 제어할 수 있다.
답글 남기기