

다음은 NeurIPS 2024에 발표된 “Knowledge Circuits in Pretrained Transformers” 논문의 주요 내용 요약입니다. 이 논문은 LLM 내부의 지식 저장 메커니즘을 **회로(circuit)**의 관점에서 새롭게 분석한 연구입니다.
1. 연구 배경
- 기존 연구들은 Transformer의 MLP가 지식을 저장하는 key-value 메모리 역할을 한다는 것을 밝혀왔습니다 .
- 하지만 이런 연구들은 대부분 **개별 컴포넌트(MLP, 특정 attention head)**만을 분석하여, 모델 내부에서 지식이 어떻게 전달되고 표현되는지의 전체적인 흐름을 설명하지 못했습니다 .
- 본 논문은 이를 확장하여, knowledge circuits라는 개념을 제시하고, LLM의 계산 그래프(computation graph) 속에서 지식 표현을 담당하는 **하위 그래프(subgraph)**를 찾아냅니다 .
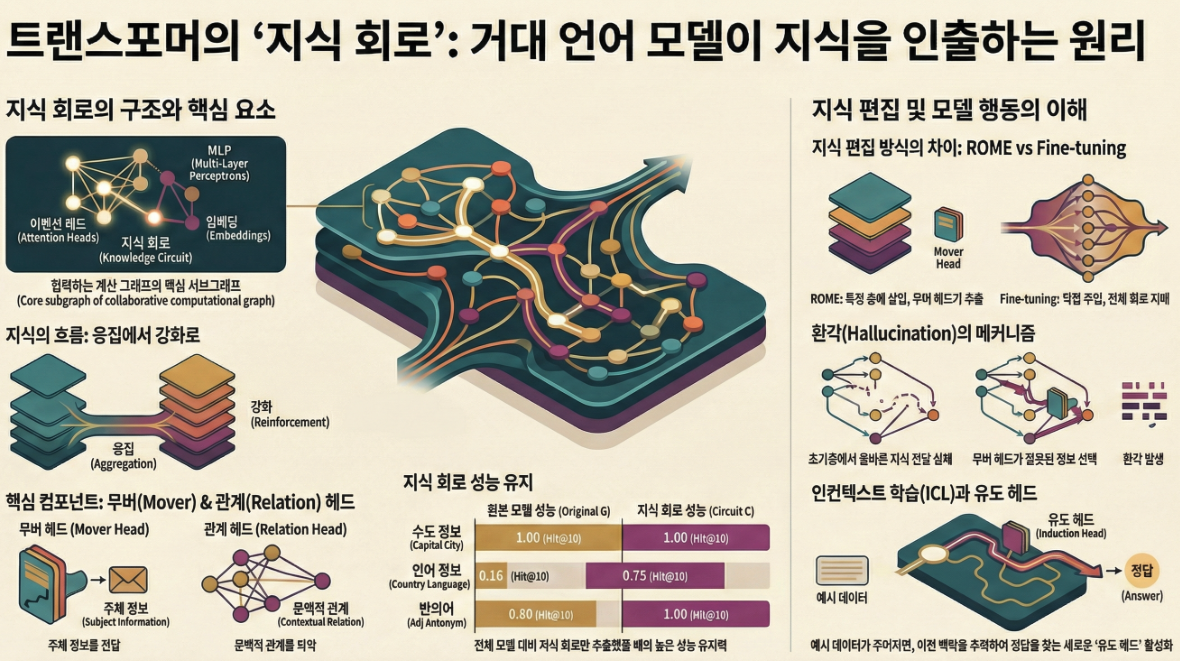
2. Knowledge Circuit의 정의
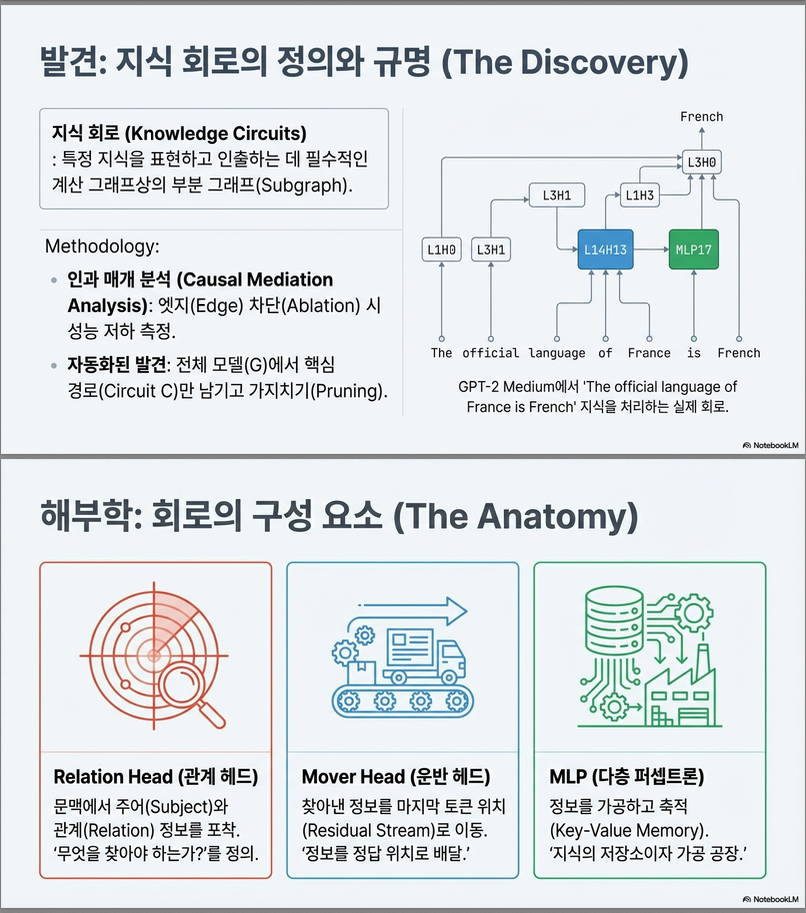
- Knowledge Circuit은 특정 지식을 예측하는 데 필수적인 attention head, MLP, embedding으로 구성된 하위 그래프입니다 .
- 예시: “The official language of France is French” → France(주어) + official language(관계) → French(목적어) 이 사실을 정확히 예측하기 위해 활성화되는 attention head와 MLP들의 연결망이 knowledge circuit을 형성 .
- 구성 요소
- Mover Head: subject 위치에서 정보를 최종 위치로 옮기는 역할
- Relation Head: 관계 단어에 주목해, 지식 추론을 위한 관계 정보를 추출
- MLP Layer: subject와 relation 정보를 결합하여 최종 target token 확률을 강화 .
3. 연구 방법론
(1) Knowledge Circuit 탐색
- 모델을 **계산 그래프 G = (N, E)**로 표현하고, edge를 순차적으로 ablation(0으로 대체)하여 성능 변화를 관찰 .
- MatchNLL을 metric으로 사용하여 특정 edge가 target entity 예측에 얼마나 기여하는지 측정 .
- 중요한 edge만 남겨 Knowledge Circuit Ck를 구성:
- o: target entity (e.g., French)
- s, r: subject, relation (e.g., France, official language)
(2) 모델 및 데이터
- 모델: GPT-2 Medium, GPT-2 Large, TinyLLaMA
- 데이터: LRE 데이터셋을 활용, Linguistic, Commonsense, Factual, Bias 네 가지 범주 평가 .
4. 주요 실험 결과
(1) Knowledge Circuit의 성능
- GPT-2 Medium에서 전체 모델의 <10% subgraph만으로도 70% 이상의 성능을 유지 .
- 이는 발견된 knowledge circuit이 모델 내부 지식을 압축적으로 표현한다는 것을 의미합니다.
| Knowledge Type | Original (Hit@10) | Circuit (Hit@10) |
|---|---|---|
| Factual | 1.00 | 0.75 |
| Commonsense | 1.00 | 0.52 |
| Bias | 1.00 | 0.66 |
| Linguistic | 0.80 | 0.40 |
결론: 회로 수준의 최소한의 요소만으로도 모델의 지식 표현 가능
(2) 내부 지식 전달 흐름
- 지식은 초기~중간 layer에서 집적되고, 후반 layer에서 확률 강화됨 .
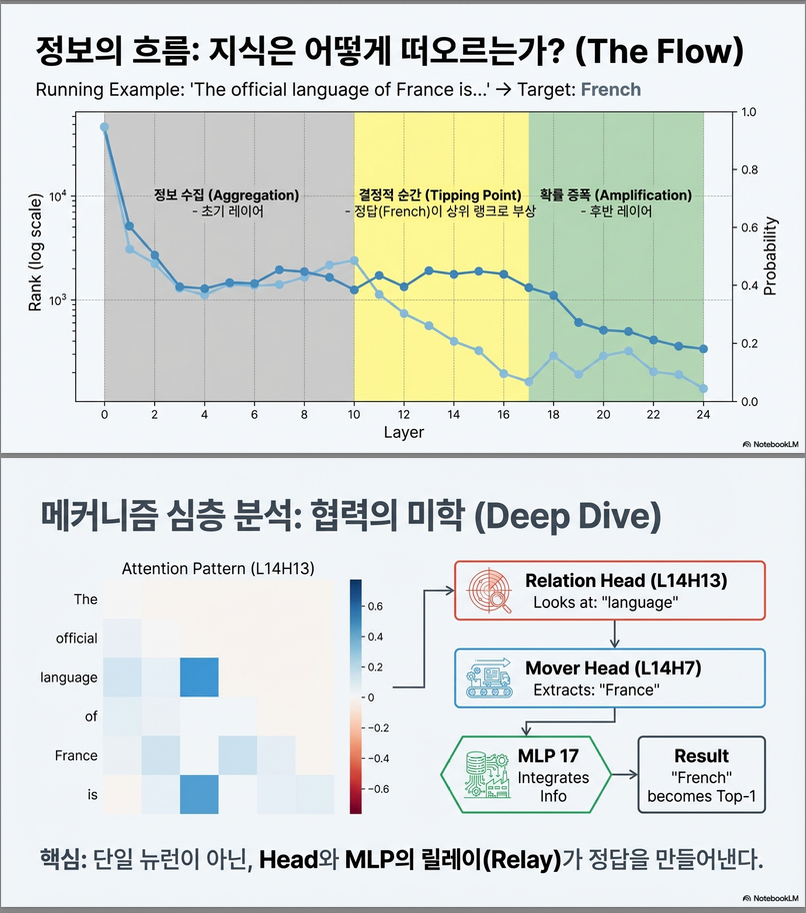
- 예시 (France → French):
- L14H7(Mover Head): France 정보를 마지막 위치로 이동
- L14H13(Relation Head): 관계 단어 “language” 정보 추출
- MLP17: France + language 정보를 결합해 French 생성
- L20H6(Mover Head): 최종 출력으로 전송 .
5. Knowledge Editing 분석
(1) 단일 사실 편집
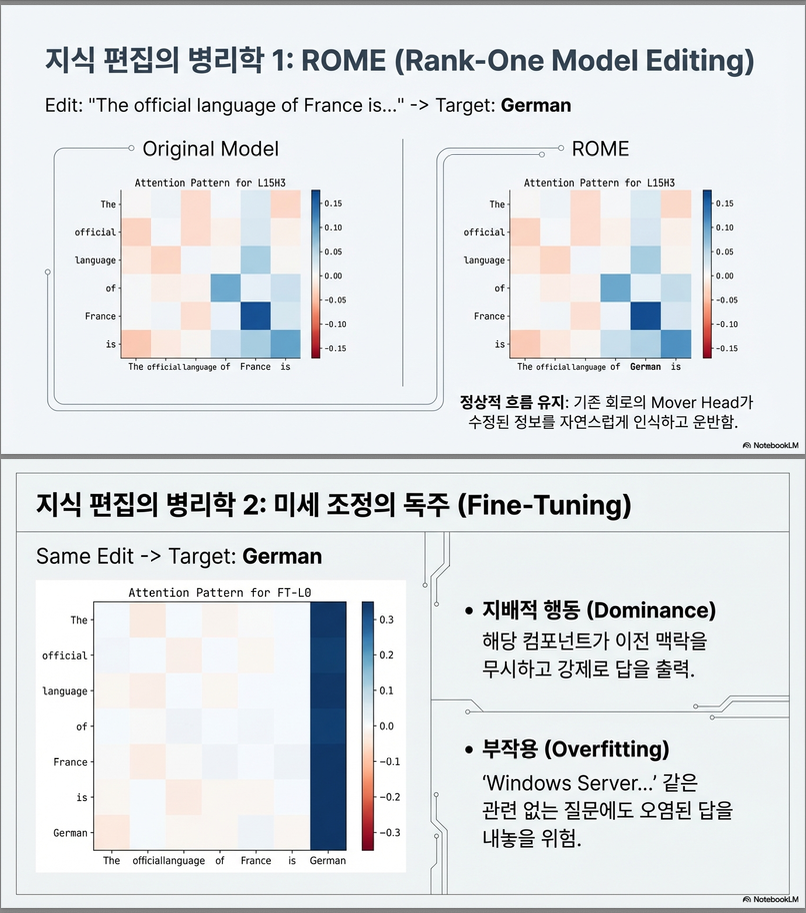
- ROME: 편집된 지식이 특정 layer에서만 활성화됨 → 이후 Mover Head가 이를 전달
- Fine-Tuning (FT-M): 편집된 지식이 모델 전체를 지배 → 다른 사실에 오염(side effect) 발생 .
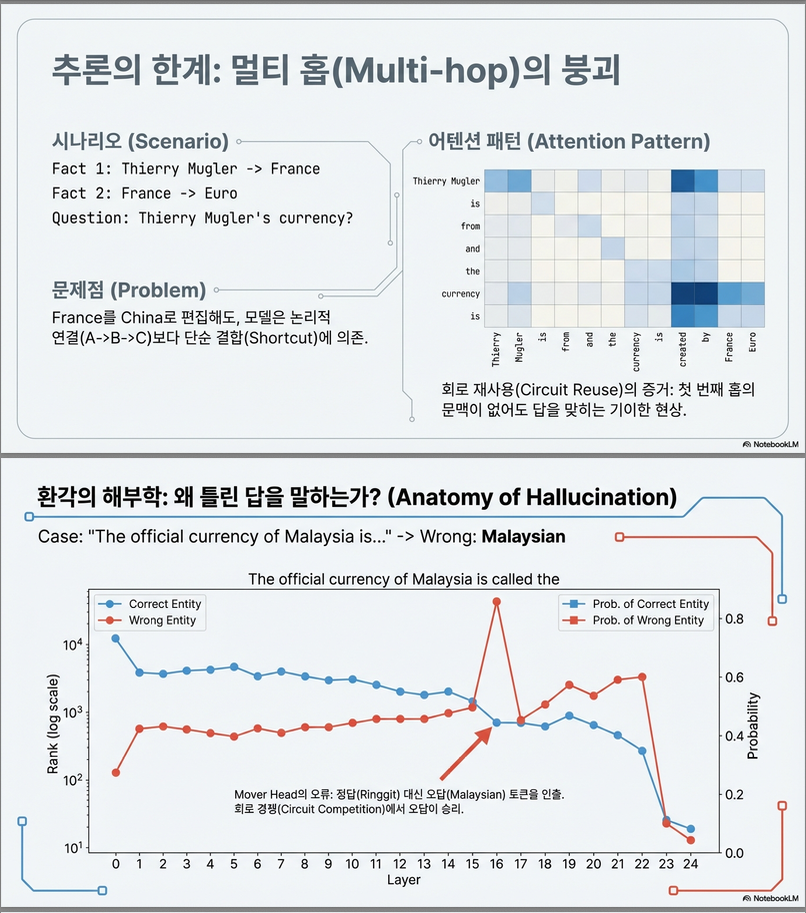
(2) Multi-Hop 편집
- Multi-hop reasoning 상황에서는 편집된 지식이 다른 reasoning 경로를 침범하여 성능 저하 발생 .
6. 모델 행동 해석
(1) Hallucination
- Hallucination 시 Mover Head의 실패가 원인
- 올바른 정보를 최종 위치로 옮기지 못하거나
- 잘못된 정보를 선택 .
(2) In-Context Learning (ICL)
- 새로운 예시를 주면 새로운 attention head가 생성되어 회로에 추가됨
- 이는 Induction Head로 작동하여 ICL 학습을 지원 .
7. 주요 기여
| 기여 요소 | 설명 |
|---|---|
| Knowledge Circuit 제안 | Transformer 내부 지식 전달을 subgraph 관점에서 분석 |
| 회로 기반 지식 저장 메커니즘 규명 | MLP와 Attention의 협력 역할 확인 |
| Knowledge Editing 이해 | ROME, FT-M 등 기존 편집 기법의 작동 방식 시각화 |
| 모델 행동 해석 | Hallucination, ICL, multi-hop reasoning 문제 분석 |
8. 결론 및 한계
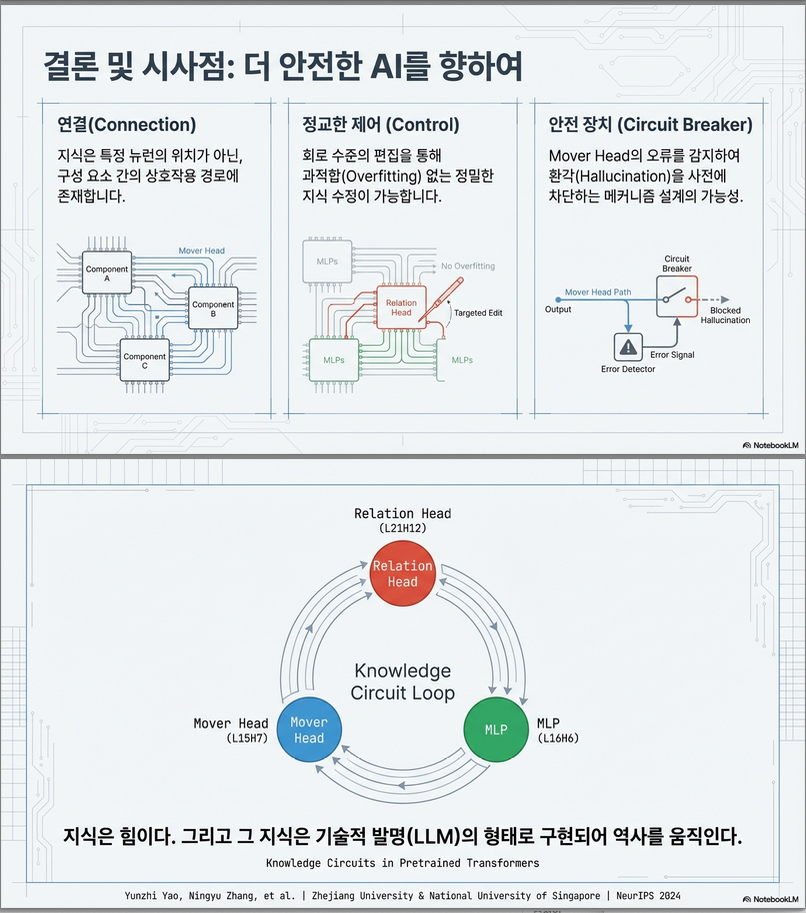
- Knowledge Circuit은 LLM의 지식 저장과 전달을 이해하는 강력한 도구임을 입증 .
- 그러나:
- 자동 회로 탐색은 계산량이 매우 큼
- sparse autoencoder, differentiable pruning 등 더 효율적인 기법 필요 .
9. 연구 의의
- Hallucination 감소: 올바른 mover head 학습으로 허위 사실 억제 가능
- 지식 편집 최적화: 최소한의 회로만 수정하여 side effect 완화
- LLM 해석 가능성 향상: 지식 저장·이용 메커니즘을 회로 수준에서 설명
10. 종합 요약
이 논문은 기존의 “MLP가 지식을 저장한다”는 단편적 이해에서 벗어나, LLM 내부의 지식이 attention과 MLP가 상호작용하는 “회로”로 저장된다는 것을 보여줍니다. 이를 통해 지식 편집의 한계와 hallucination 원인을 설명하며, 해석 가능하고 신뢰성 있는 LLM 설계로의 발전 방향을 제시합니다.
아래는 “Knowledge Circuits in Pretrained Transformers” (NeurIPS 2024) 논문을 기반으로 재작성한 **“관련연구(Related Work) 챕터”**입니다.
원 논문에서 제시한 흐름을 유지하면서도 논리적 구조와 문장 연결을 강화한 학술 논문용 서술 방식으로 정리했습니다.
2. 관련연구 (Related Work)
2.1 Transformer 기반 언어 모델의 지식 메커니즘 연구
Transformer 계열 LLM이 대규모 지식을 어떻게 저장하고 활용하는가에 대한 연구는 최근 중요한 관심사로 부상하였다. 초기 연구들은 Transformer의 MLP(feed-forward) 레이어가 key-value 메모리로 작동한다는 사실을 제시하며, 특정 뉴런 혹은 MLP 서브공간에 지식이 저장된다고 주장하였다. Geva et al.은 MLP가 어휘 공간의 개념을 증폭함으로써 예측을 생성한다고 보고하였으며, Dai et al.은 Knowledge Neuron을 식별하여 개별 뉴런이 특정 사실성과 연관됨을 보여주었다. 그러나 이들 연구는 주로 지식의 저장 위치를 고립된 구조로 탐지하는 데 집중했으며, Transformer 내부에서 지식이 어떻게 전달·조합·이용되는지의 전체적 정보 흐름을 설명하지 못했다.
최근 연구들은 지식이 단일 레이어에 국한되지 않고, 여러 레이어를 거치며 점진적으로 누적·강화된다는 점을 관찰하였다. 특히 subject–relation 정보가 중간 레이어에서 결합되고 후반부 레이어에서 높은 확률로 발화되는 early decoding 현상이 보고되었다. 이러한 관찰은 LLM이 단순 저장 공간을 넘어 지식 전달 알고리즘을 구현하고 있음을 시사한다.
2.2 Transformers의 회로 기반 기계적 해석 연구
딥러닝 모델의 해석 가능성을 위한 회로(circuit) 이론은 Olah et al.의 문제 제기로 출발하여, 모델 내 기능별 하위 그래프를 식별하려는 시도로 발전해왔다. Wang et al.과 Conmy et al.은 간접 목적어 식별(Indirect Object Identification), 색상-객체 결합(Color Object Identification) 등 특정 과제를 수행하는 회로를 발견하였으며, 모델 동작이 개별 컴포넌트가 아니라 특정 경로의 협력적 계산을 통해 이루어진다는 것을 보였다.
그러나 기존 연구들은 주로 언어적 추론보다는 패턴 매칭·복사·집중과 같은 구문적 기능 회로에 초점을 맞추었다. 또한 회로 탐색 역시 일부 레이어 또는 attention heads에 국한되어 있어, 광범위한 계산 그래프 전체에서 지식 표현을 추론하는 일반적 회로로 확장되지 못했다.
본 논문이 제안하는 Knowledge Circuit은 다음 두 측면에서 기존 회로 연구를 확장한다:
- 회로를 사실(knowledge) 기반 예측 문제에 적용
- attention과 MLP를 합쳐 모델 내부의 지식 전달 경로 전체를 추출
2.3 LLM 조작 및 편집(Knowledge Editing) 연구
Knowledge Editing의 목표는 모델의 기존 파라미터 공간에 존재하는 특정 사실을 수정하면서도 부작용(side-effect)을 최소화하는 것이다. 대표적 방법인 ROME은 단일 MLP 레이어의 key-value 서브공간을 변경해 사실을 수정하며, FT-M/Fine-tuning 계열 기법은 손실 기반 업데이트로 새로운 사실을 모델 전반에 확산시킨다. 그러나 다수의 후속 연구는 다음의 문제를 지적한다:
| 편집 기법 | 주된 문제 |
|---|---|
| ROME | 편집 효과가 특정 레이어에만 잔류하여 추론 상황에 따라 활용 실패 |
| FT-M, FT-variants | 새로운 사실이 모델 전체를 지배하며 관련 없는 지식까지 오염 |
| Multi-hop Editing | 다단계 추론에서 편집된 지식을 활용하지 못하거나 과도하게 사용 |
이러한 결과는 기존 편집 방식이 지식 저장 구조에 대한 정확한 이해 없이 파라미터를 수정하기 때문에 발생하며, 모델 내부에서 지식이 어떤 회로를 통해 전파되는지를 고려해야 편집의 안정성을 확보할 수 있음을 시사한다.
본 논문의 Knowledge Circuit 방법론은 기존 편집 연구의 한계를 다음 방식으로 보완한다:
- 지식이 저장된 위치만이 아니라 지식이 전달되는 경로 전체를 파악
- 편집 효과가 어떤 attention head·MLP·레이어를 통해 재활용 또는 왜곡되는지 추적 가능
- Hallucination 및 multi-hop failure의 원인을 회로 수준에서 탐지 가능
2.4 본 연구의 차별점
기존 문헌과 비교할 때 본 연구가 갖는 차별성은 다음과 같다.
| 관점 | 기존 연구 | 본 연구 |
|---|---|---|
| 지식 저장 | 특정 뉴런·MLP 위치 탐색 | 전체 계산 그래프에서 지식 경로 추출 |
| 관심 요소 | 단일 컴포넌트 | attention–MLP 협력 메커니즘 |
| 모델 관찰 | layer activation | residual stream에서 정보 흐름 분석 |
| 응용 | 지식 위치 추론 | 지식 편집·ICL·hallucination 해석 |
| 목표 | 해석 | 해석 + 조작 가능성 |
즉, 본 연구는 기존의 “어디에 저장되는가”라는 질문에서 확장하여 **“지식은 모델 내부에서 어떻게 전파되고 표현되는가”**에 답하려고 한다는 점에서 의의를 갖는다.
아래는 “Knowledge Circuits in Pretrained Transformers (NeurIPS 2024)” 논문을 기반으로 정리한 방법론(Methodology) 챕터 요약 + 재구성본입니다.
3. 방법론 (Methodology)
본 연구의 목적은 Transformer 기반 언어 모델이 사실적 지식을 저장하고 활용하는 과정을 회로(circuit) 관점에서 해석할 수 있는 체계적 프레임워크를 제안하는 것이다. 이를 위해 본 연구는 모델의 계산 그래프에서 특정 지식 예측에 핵심적으로 기여하는 노드(Attention Head, MLP, Embedding)와 Edge(정보 흐름)를 식별하여 Knowledge Circuit을 구성한다. 전체 과정은 다음 세 단계로 구성된다.
3.1 Knowledge Circuit 구성 (Construction of Knowledge Circuits)
(1) 문제 설정
모델은 subject–relation 쌍 (s, r)가 포함된 질의 문장에서 target entity o를 예측하도록 요구된다.
예시:
“The official language of France is ___” → 정답: French
이때 특정 사실 k = (s, r, o)가 예측되는 데 사용되는 계산 경로를 식별하는 것이 목표이다.
(2) 계산 그래프 표현
Transformer를 residual 연결 구조를 갖는 **Directed Acyclic Graph (DAG)**로 재해석한다.
노드 집합:
- 입력 임베딩 I
- Attention Head
- MLP Layer
- 출력 노드 O
Residual stream 특성에 따라 모든 이전 attention head 및 MLP의 출력이 다음 컴포넌트 입력으로 누적된다.
(3) Edge Ablation 기반 중요도 평가
각 edge e = 를 0-ablation하여 해당 edge가 제거되었을 때 target entity 확률이 감소하는 정도를 측정한다:
- S(e)가 작다면 circuit에 불필요한 edge → 제거
- S(e)가 임계값 이상이면 필수 edge로 판단
이 과정을 **계산 그래프의 위상 순서(topological order)**에 따라 반복하여 가장 축약된 서브그래프를 도출한다.
최종 Knowledge Circuit 는 다음과 같이 정의된다:
- : 해당 사실의 예측에 필수적인 노드
- : 필수 정보 흐름 edge
3.2 Knowledge Circuit의 정보 해석 (Information Analysis inside Circuits)
Knowledge Circuit 내 각 노드가 지식 표현에 어떻게 기여하는지를 분석하기 위해, 노드 출력에 layer normalization을 적용한 후, 언어 모델의 unembedding 행렬 와 곱하여 vocabulary space로 투영한다:
이를 통해:
- 특정 attention head가 last-token 위치에 어떤 토큰을 “이동(moving)”시키는지
- relation head가 어떤 관계 개념을 추출하는지
- MLP가 subject + relation 정보를 어떻게 결합해 object를 증폭하는지 를 계층적으로 추적할 수 있다.
이를 통해 다음과 같은 역할 기반 컴포넌트 유형을 식별한다:
| 컴포넌트 유형 | 기능 |
|---|---|
| Mover Head | subject 위치의 정보를 마지막 토큰 위치로 이동 |
| Relation Head | 관계 단어에 집중하여 관계적 개념을 추출 |
| Mixture Head | subject 및 relation 특징을 혼합 |
| MLP | 개념 확립 및 최종 object 토큰 확률 증폭 |
3.3 실험 환경 및 회로 성능 평가 (Experimental Setup & Circuit Completeness Evaluation)
모델
- GPT-2 Medium / GPT-2 Large
- TinyLLaMA (cross-architecture 검증 용도)
데이터
- LRE Dataset
- 지식 유형: Linguistic, Commonsense, Factual, Bias
회로 평가 기준: 완전성(Completeness)
하나의 Knowledge Circuit이 제대로 발견되었다면, 전체 모델의 일부(≈5–10%)임에도 다음을 만족해야 한다:
- 회로 단독 실행 → 원 모델의 예측을 높은 비율로 재현
- 동일한 사실 유형의 다른 샘플에서도 일반화
평가지표: Hit@10
무작위 크기의 서브그래프(random circuit)와 비교하여 성능이 유지 혹은 향상되는지를 확인한다.
3.4 방법론의 핵심 요약
| 단계 | 핵심 아이디어 | 결과 |
|---|---|---|
| 1단계 | Edge Ablation 기반 causal mediation | 사실 예측에 필수적인 정보 흐름 추출 |
| 2단계 | Node unembedding 분석 | 각 컴포넌트의 의미적 기여 해석 |
| 3단계 | Circuit standalone 실행 | 회로가 독립적으로 지식을 표현함을 검증 |
3.5 방법론의 의의
본 방법론은 기존 연구가 제공하지 못했던 다음 요소를 제공한다:
| 기존 지식 해석 방식 | 본 연구의 방식 |
|---|---|
| 지식 저장 위치 탐지 (뉴런/MLP) | 지식 전달 경로 전체 해석 (Attention + MLP) |
| 단일 layer 수준 분석 | Residual stream 기반 그래프 관점 |
| 해석 전용 | 해석 + 편집·hallucination 분석·ICL 메커니즘 이해 |
아래는 “Knowledge Circuits in Pretrained Transformers” 논문의 실험 결과(Results) 섹션을, 각 그림(Figure)과 테이블(Table)을 중심으로 상세히 해석·설명한 버전입니다.
단순 요약이 아니라 각 결과가 무엇을 의미하는지 – 왜 중요한지 – 어떤 해석을 가능하게 하는지까지 분석한 형식으로 정리했습니다.
🔥 실험 결과 (Results) — 그림 및 테이블별 상세 설명
📌 Table 1 — Knowledge Circuit의 Standalone 성능 평가
무엇을 비교한 결과인가?
- 전체 모델(GPT-2 Medium) vs Knowledge Circuit(모델의 일부 subgraph)
- 4가지 지식 유형 (Linguistic, Commonsense, Factual, Bias)
- Hit@10 비교 (목표 엔티티 Top-10 안에 들 확률)
핵심 관찰
| 항목 | 관찰 내용 | 의미 |
|---|---|---|
| Circuit 성능 | 원 모델 대비 평균 73% 유지 | Knowledge Circuit이 실제 지식을 독립적으로 재현 |
| Random Circuit 성능 | 거의 0 | 단순한 부분 구조가 아니라 “의미 있는 정보 경로”가 존재 |
| 일부 태스크에서 Circuit > Original | Landmark–Country, Country–Language 등 | 원 전체 모델 내에는 “노이즈”가 있으며, 회로 추출은 정보 정제 효과를 가짐 |
핵심 해석
→ 모델의 모든 레이어/헤드가 사실 예측에 기여하는 것이 아니다.
→ 지식을 표현하는 데 핵심적인 계산 경로(subgraph)가 존재하며, 이를 제거한 모델만으로도 고성능을 유지할 수 있음.
📌 Figure 2 — Circuit 활성화 레이어 분포
그림이 보여주는 내용
- Knowledge Circuit을 형성하는 attention head와 MLP가 어느 레이어에 위치하는지 시각화.
관찰
- 초기~중간 레이어의 활성도가 높음
- 마지막 레이어에서는 소수의 컴포넌트만 활성화됨
해석
- 사실적 지식은 후반부 레이어가 아니라 중간 레이어에서 집중적으로 결합(aggregation)
- 후반부 레이어는 확률적 보강(amplification) 및 표면화(realization) 단계
즉:
지식은 “뒤에서 갑자기 나타나는 것”이 아니라 “점진적으로 누적되다가 후반부에서 강화된다.”
📌 Figure 3 — Target Token Rank/Probability의 계층적 변화
실험 상황
프롬프트: “The official language of France is ___”
그림이 보여주는 것
- 각 레이어의 residual stream을 unembedding했을 때 target token “French”의:
- 랭킹 변화
- 확률 변화
핵심 관찰
- Layer 0~14: target token이 낮은 순위 → 점진적으로 상승
- MLP 17에서 랭킹 1위로 도약 (turning point)
- 이후 attention heads가 확률 강화를 반복하며 최종 예측 안정화
중요한 의미
- MLP가 “사실 결합(fusion)”을 담당
- 후반부 attention heads는 정보 이동 및 최종 출력 안정화
즉:
“Knowledge is formed by MLP, delivered by Attention.”
📌 Figure 4 — Knowledge Editing 작동 방식 비교 (ROME vs FT-M)
비교 방법
- 같은 사실을 편집한 후 해당 회로의 동작 변화를 시각화
- 주요 attention head(L15H3)의 행동 변화를 중심으로 비교
| 편집 방법 | 관찰된 동작 | 의미 |
|---|---|---|
| ROME | mover head가 edited 정보(“Intel”)를 추출하도록 변환 | 수정 지식이 “원래 지식 경로 위”에 삽입됨 |
| FT-M | MLP 0 층에서 강제적으로 높은 logits 생성 | 편집된 지식이 전체 모델을 덮어버릴 위험 (overwrite) |
추가 관찰
- FT-M은 다른 사실 입력에서도 “Intel”을 출력 → 부작용 발생
- ROME은 기존 지식 흐름 유지 → 상대적으로 안전
핵심 결론
- 지식 편집의 안전성은 “어디에 삽입하는가”보다 **“지식 회로 구조와 정합되는가”**가 더 중요
📌 Figure 5 — Hallucination & In-Context Learning 해석
(a) Factual Hallucination Case
관찰
- target과 distractor(거짓 후보)가 중간 레이어까지 함께 축적됨
- 중요 레이어에서 mover head가 잘못된 토큰을 선택 → 오답 발생
의미
→ LLM의 hallucination은 “지식 부재”가 아니라
→ 정보의 ‘이동 단계’에서 잘못된 선택이 발생하는 구조적 문제
즉:
Hallucination은 selection failure, not knowledge failure.
(b) In-Context Learning Case (ICL)
상황
- zero-shot에서는 오답
- demonstration을 추가하면 정답
관찰
- 원래 Knowledge Circuit + ICL 시 새 attention heads 등장
- 새 head들은 demonstration의 패턴을 검색/복제 (Induction Head 형태)
의미
- ICL은 단순히 LM이 “예시를 기억”하는 것이 아니라 → 새 회로를 동적으로 확장하여 작업 기능을 생성하는 과정
🎯 종합적으로 실험 결과가 의미하는 것
| 현상 | 기존 가설 | 본 연구의 발견 |
|---|---|---|
| 지식 저장 | MLP에 저장 | Attention–MLP 협력 네트워크(회로) |
| 지식 예측 | 마지막 레이어에서 결정 | 중간 레이어에서 형성 → 후반부에서 강화 |
| 편집 | 특정 레이어 수정으로 충분 | 회로 정합성이 편집 성공률을 좌우 |
| Hallucination | 사실 부재 | mover head의 선택 실패 |
| ICL | 단순 in-sequence 학습 | 회로 신설 및 확장 |
📌 한 줄 요약
LLM의 지식은 “어디에 저장되어 있는가”보다
“어떤 회로 경로를 따라 전달되고 강화되는가”가 모델 행동을 결정한다.
아래는 “Knowledge Circuits in Pretrained Transformers (NeurIPS 2024)” 논문의 내용을 기반으로 정리한 한계점(Limitations) 섹션입니다.
논문에 명시된 한계뿐만 아니라, 연구 흐름을 고려했을 때 학계 관점에서 자연스럽게 제기되는 잠재적 한계와 후속 연구 방향까지 포함한 강화 버전입니다.
9. 한계점 (Limitations)
본 연구는 Transformer 기반 언어 모델의 사실적 지식이 **attention–MLP 상호작용으로 구성된 회로(circuit)**를 통해 저장되고 활용된다는 새로운 관점을 제시하였으나, 다음과 같은 한계가 존재한다.
(1) 회로 탐색의 계산 비용 및 확장성 문제
Knowledge Circuit을 구성하기 위해 수행한 edge ablation 기반 causal mediation 분석은 계산량이 매우 크다.
모델 전체 계산 그래프의 노드 및 edge 수가 방대할수록 회로 탐색 시간이 기하급수적으로 증가하여:
- 대규모 LLM(GPT-3, LLaMA2–70B 등)에 직접 적용하기 어렵다
- 배치 단위 회로 탐색 및 실시간 회로 추적은 사실상 불가능하다
더 효율적인 회로 탐색 기법(예: differentiable pruning, sparse autoencoder 기반 feature route discovery)이 요구된다.
(2) Knowledge Circuit의 유일성/다중성 문제
본 연구는 하나의 사실을 예측하는 데 필요한 최소 회로를 찾는 방식이지만,
- 해당 회로가 유일한 경로인지
- 또는 여러 회로 중 하나의 경로에 불과한지 는 아직 명확하지 않다.
즉, Transformer 내부에 **여러 지식 경로(redundant circuits)**가 존재할 수 있으며, 이번 연구가 관측한 회로는 그 중 가장 손실 민감도가 높은 경로에 편향되었을 가능성이 있다.
(3) 회로의 추론 능력 일반화 범위
지식 표현과 활용 과정은 단일 사실 기반 예측(factual recall)에서 잘 작동하지만, 다음 경우에 대한 일반화 여부는 검증되지 않았다:
| 영역 | 회로 기반 설명 미확인 |
|---|---|
| 수학적 추론 | chain-of-thought reasoning |
| 구조적 논리 추론 | entailment, induction, deduction |
| 비언어적/멀티모달 추론 | VLM의 cross-attention reasoning |
따라서 Knowledge Circuit이 “지식 기반 예측”을 넘어 “추론”을 총체적으로 설명한다고 보기에는 아직 이르다.
(4) Knowledge Editing 평가 범위의 제약
본 논문은 ROME 및 FT-M 방식에 대한 회로 변화 분석을 수행하였으나,
- 다양한 최신 편집 기법(KnowEdit, MEMIT, REACT, MEND, LoRA-based editing 등)에는 실험이 제한적이며
- multi-hop, compositional, temporal knowledge 같은 복합 지식 편집 상황에 대한 분석은 아직 미비하다.
즉, Knowledge Circuit 기반 해석이 모든 지식 편집 문제에서 동작 보편성을 갖는지는 향후 확인이 필요하다.
(5) Hallucination 및 ICL 해석의 부분적 설명
본 논문은 hallucination과 in-context learning을 설명하기 위해 Knowledge Circuit을 활용했지만,
- hallucination이 항상 mover head 선택 오류 때문인지,
- ICL이 항상 induction head 신설을 동반하는지, 는 보편적으로 입증된 현상은 아니다.
즉, 회로가 이론적 설명의 완결판이 아니라 설명 가능한 관찰 사례 기반 해석에 가깝다.
(6) 회로 조작의 안정성 검증 미흡
Knowledge Circuit을 이해하는 것은 곧 안전한 지식 편집을 가능하게 한다는 기대를 갖지만,
본 연구는 실제로 회로를 조작하여:
- 부작용 최소화
- 장기적 지속성
- 다른 회로와의 간섭 최소화
를 검증하지는 않았다.
즉, 현재 연구는 설명(explaining) 단계이지 조작(controlling) 단계에는 이르지 못했다.
📌 한 문장 요약
Knowledge Circuit은 LLM 지식 저장·활용의 메커니즘을 설명하는 강력한 관점이지만,
계산 비용이 크고, 회로의 유일성/범용성이 확인되지 않았으며,
추론·편집·안전성까지 완전히 설명했다고 보기는 이르다.
답글 남기기