

아래는 논문 **“Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)”**의 핵심 내용을 직관적으로, 기존 ACDC/EAP과의 차이를 중심으로, 수식·개념까지 포함해 정리한 설명입니다.
🔍 1. 연구 배경: 왜 Edge Pruning인가?
Transformer의 동작을 해석하려면 모델 내부에서 특정 기능을 수행하는 회로(circuit) 를 찾아야 한다.
기존 자동 회로 추출 방식에는 두 가지 대표적 접근이 있다:
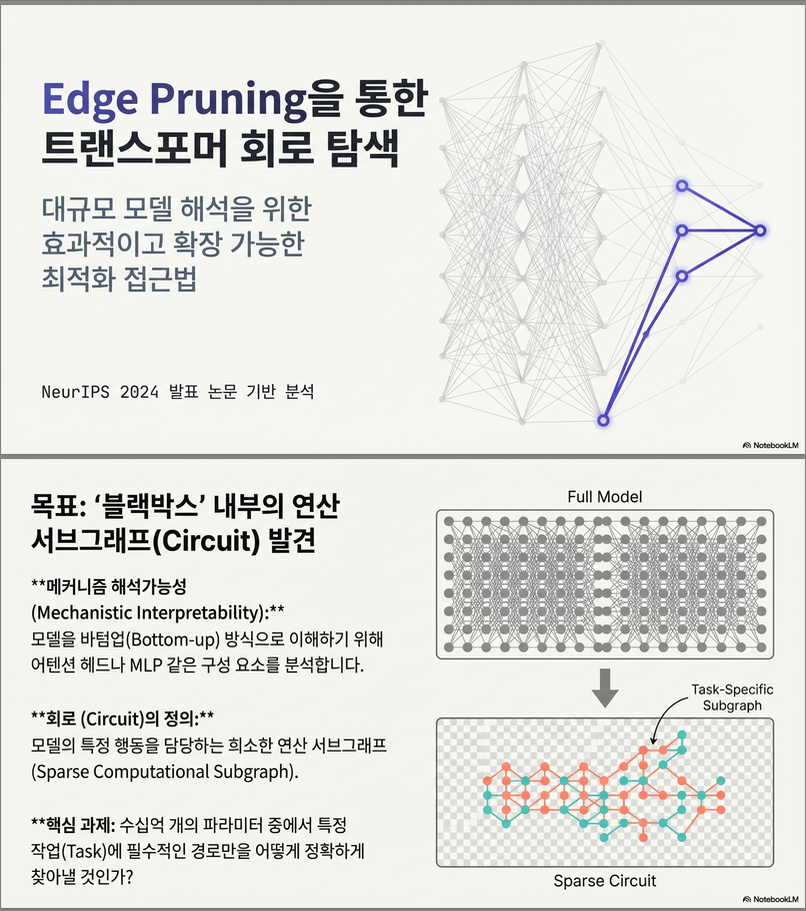
(1) ACDC (2023)
- 각 edge를 하나씩 ablate 해보며 greedy search
- 정확하지만 느리고, 데이터셋이 커지면 불가능
- 대규모 모델(GPT-2 Small 이상)에 확장 어려움
(2) EAP (Edge Attribution Patching, 2023)
- 모든 edge에 대해 1st-order gradient (linear approx) 로 중요도 스코어를 계산
- 빠르지만 근사 오차가 커서 신뢰도가 떨어질 수 있음
- edge 간 상호작용을 고려하지 못함
📌 문제점
- ACDC: 정확하지만 너무 비싸다
- EAP: 빠르지만 정확도가 떨어진다
- 둘 다 대규모 모델(13B 등) 에 적용하기 매우 어렵다
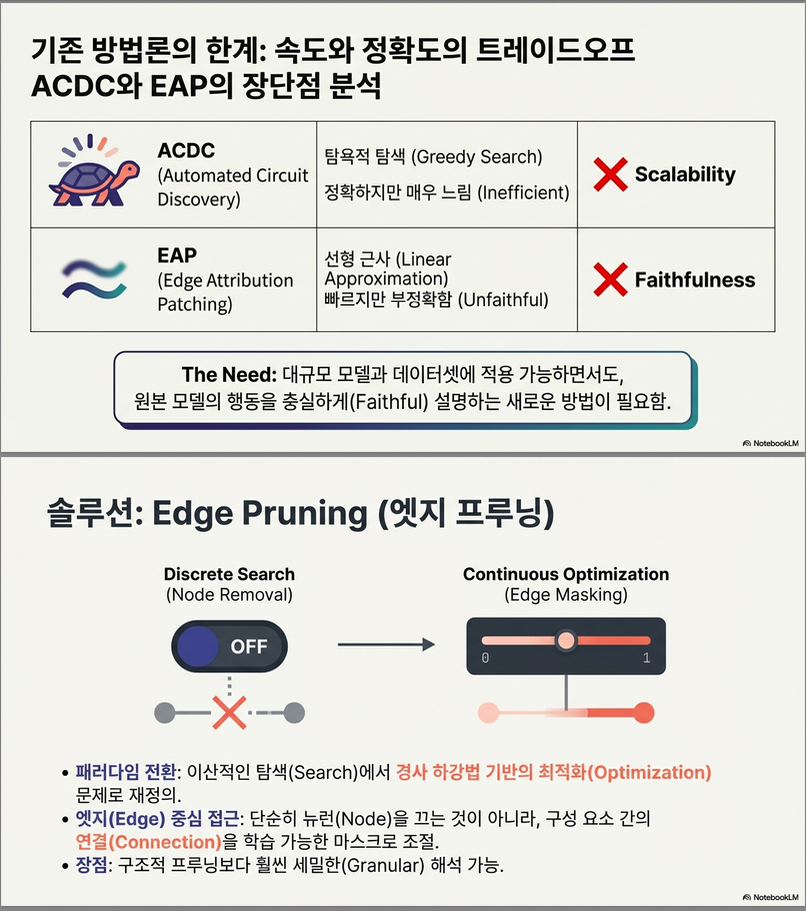
🌟 2. Edge Pruning의 핵심 아이디어
논문의 새로운 접근:
🧠 회로 찾기 문제를 ‘edge-level pruning + continuous optimization’ 문제로 재정의한다.
즉,
edge를 binary mask로 두고, 이를 gradient descent로 최적화하여 회로를 찾는다.
✔ (A) Edge mask 도입
각 edge 에 대해
- 포함하면 1
- 제외하면 0
이 아니라
0~1 사이의 continuous 값으로 relaxation 하여 gradient로 학습
이 mask는 다음과 같이 clean activation과 corrupted activation 사이를 interpolation 한다:
(수식 3)
여기서
- : 원래 activation
- : corrupted example의 activation (interchange intervention)
- : 학습되는 mask 값
즉,
edge가 사라지면 activation을 0으로 없애는 것이 아니라, corrupted activation으로 대체함
→ Out-of-distribution 문제가 사라지고 신뢰도 높은 회로 분석 가능.
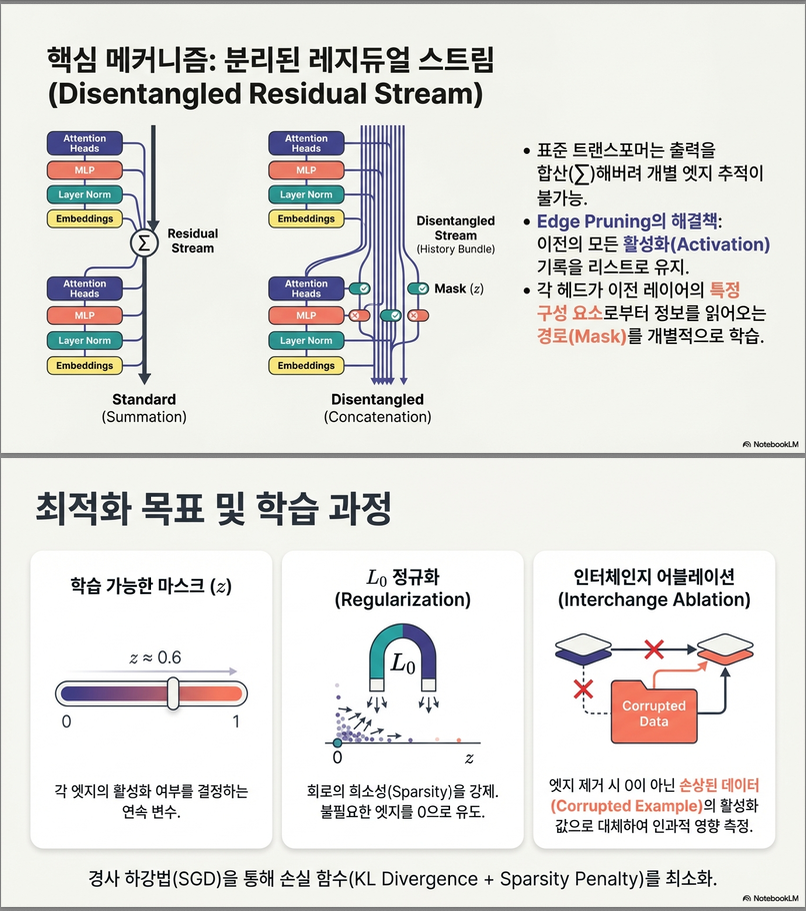
✔ (B) Disentangled Residual Stream 필요성
Transformer의 residual stream은 단일 벡터지만,
edge pruning에서는 노드마다 서로 다른 upstream activation 조합을 보게 된다.
그래서 논문은:
모든 layer의 activation을 리스트로 저장하는 disentangled residual stream
을 사용한다. (그림 1(b))
이를 통해
어떤 node에서든 “과거 모든 activation”의 조합을 mask로 선택할 수 있게 된다.
✔ (C) L0 Regularization을 통한 sparsity 제어
목표는:
subject to sparsity constraint
(식 2)
이를 위해 Hard Concrete distribution (Louizos et al., 2018) 를 사용하여
edge mask를 L0 regularization으로 sparsify 한다.
🧪 3. 실험 결과 요약
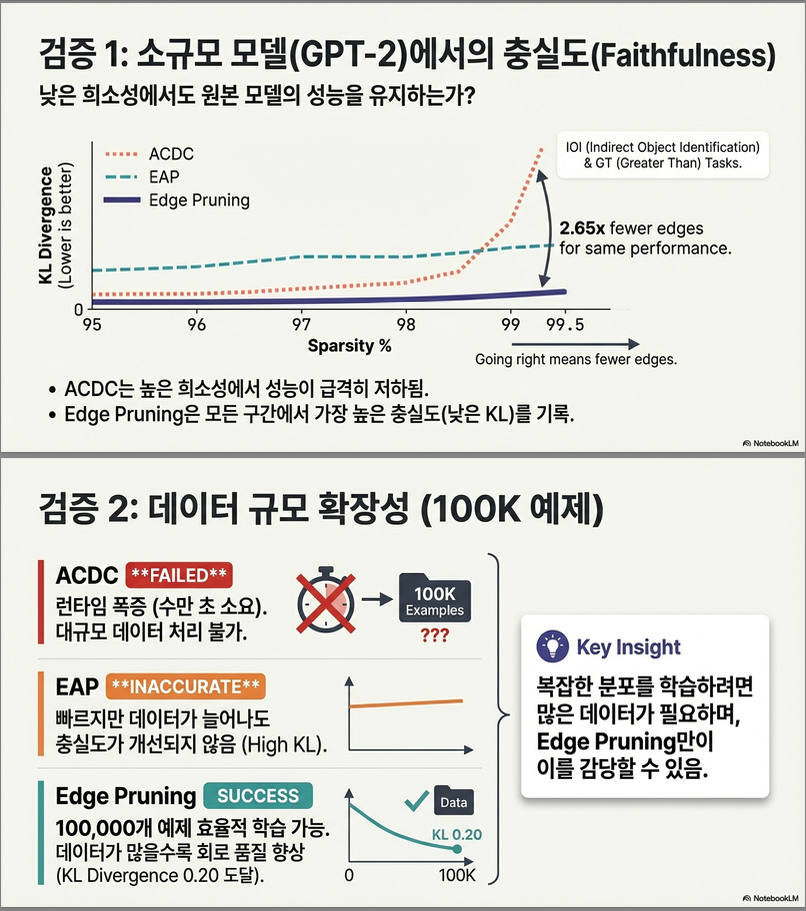
✔ GPT-2 Small 실험: Faithfulness & Performance
📌 핵심 결과
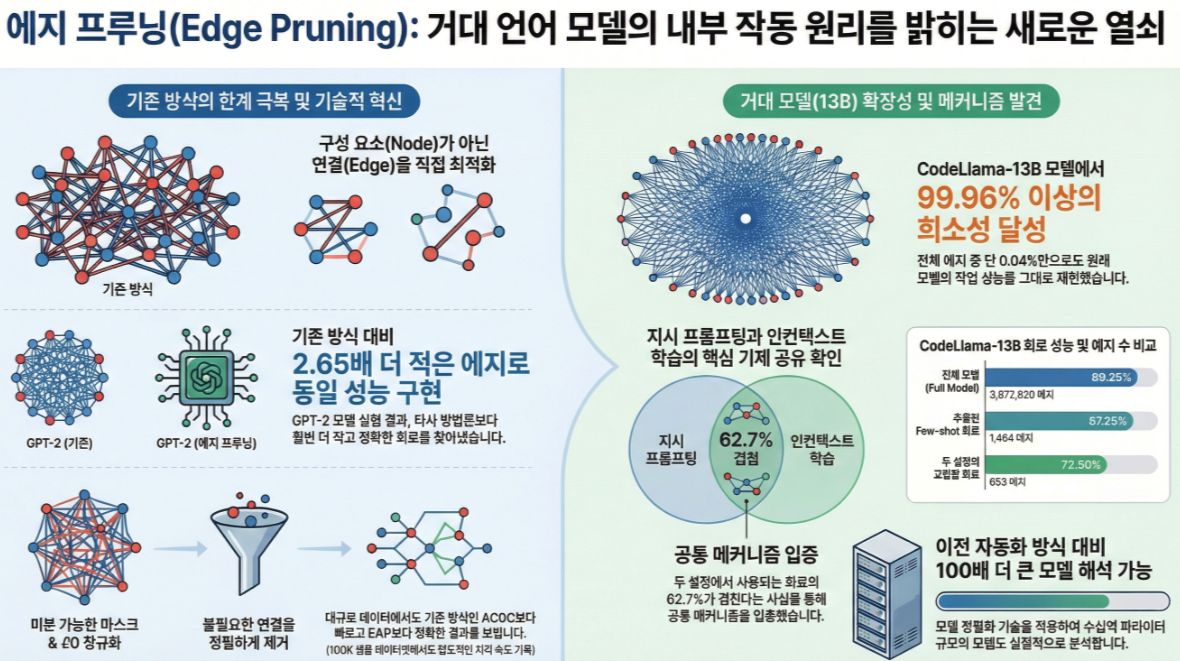
- Edge Pruning은 IOI, Greater Than 같은 복잡한 task에서 ACDC/EAP보다 훨씬 높은 faithfulness(KL) 과 성능을 보임
- 같은 성능을 유지하면서 2.65× 더 적은 edge로 회로를 구성 (그림 2, 3)
✔ 100K 데이터셋 규모 실험
Table 1 (page 7)에서:
- ACDC: 너무 느려서 100K에서는 작동 불가
- EAP: 매우 빠르지만 faithfulness가 떨어짐
- Edge Pruning: 가장 빠르고 가장 faithful
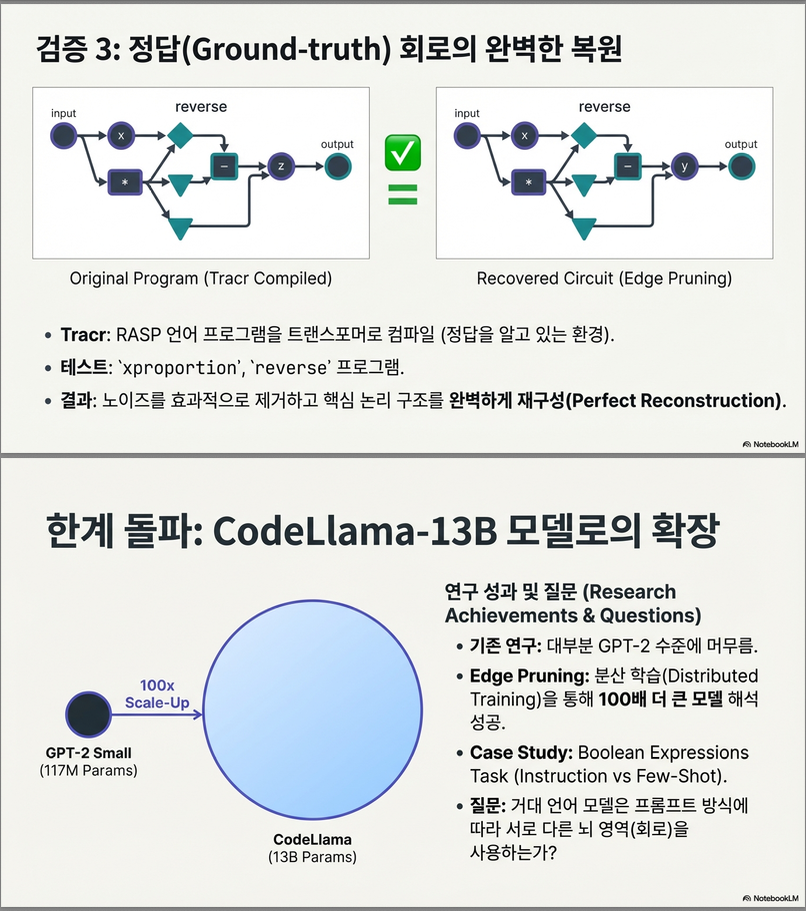
✔ Tracr 프로그램 회로 완전 복원
Tracr로 만든 ground-truth circuit을
Edge Pruning이 100% 완벽하게 재현
(그림 4)
🏋️ 4. 13B 모델(CodeLlama-13B)까지 확장
Edge Pruning은 모델 병렬화(FSDP)까지 활용하여:
CodeLlama-13B에 대해 99.96–99.97% sparsity 회로 를 찾아냄
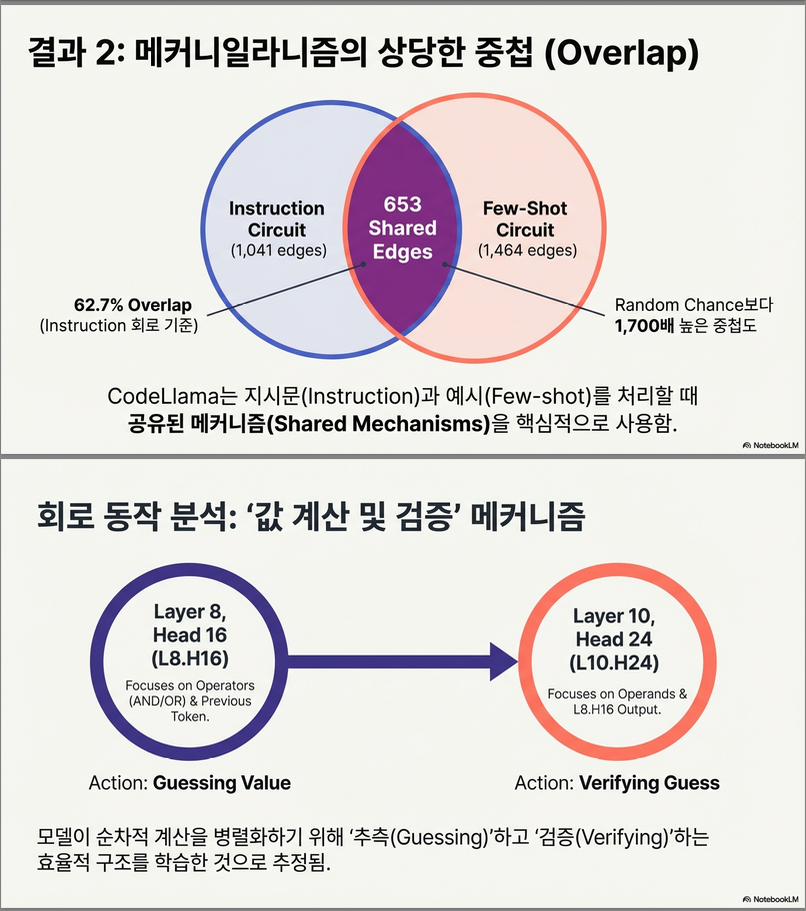
→ 한 회로는 단 1,041 edges, 다른 회로는 1,464 edges
Table 2 (page 9):
- Instruction-prompt 회로: full model 대비 accuracy –2.75%
- Few-shot 회로: –2%
- 두 회로의 교집합만으로도 높은 성능
이는 LLM의 다른 prompting setting이 동일한 기저 메커니즘을 공유함을 시사.
🧠 5. 기존 방법과의 비교 정리
| 방법 | 방식 | 장점 | 한계 |
|---|---|---|---|
| ACDC | per-edge greedy ablation | faithful | 계산량 폭발, 대규모 불가 |
| EAP | 1st-order gradient approx | 매우 빠름 | 근사오차 → 회로 불완전 |
| Edge Pruning | continuous edge mask + gradient + L0 | 정확 + 빠름 + scalable | 메모리 요구량 큼 (disentangled stream 필요) |
🎯 6. 이 논문의 핵심 기여
- Edge-level optimization이라는 새로운 회로 탐색 프레임워크 제안
- ACDC보다 faithful, EAP보다 정확, 그리고 더 scalable
- 대규모 모델(13B)에서도 미세한 회로 추출 가능
- Prompting 방식의 기저 메커니즘 비교 같은 해석 연구 가능성을 염증
📌 결론
Edge Pruning은
대규모 Transformer 모델에서 신뢰성 높은 회로를 자동으로 찾고,
기존 방식보다 더 sparse하고 faithful한 subgraph를 얻을 수 있는
새로운 interpretability 도구
로 자리매김한다.
아래는 NeurIPS 2024, Finding Transformer Circuits with Edge Pruning 논문의 방법론(Methodology) 을 수식–구현–개념 흐름으로 정리한 설명입니다. (ACDC/EAP과의 차별점이 어디서 생기는지도 함께 짚습니다.)
1) 문제 정식화: “회로 찾기 = edge 선택 최적화”
Transformer의 계산 그래프를 노드(헤드/MLP 등) 와 에지(상류→하류 연결) 로 보고,
회로(circuit) 는 전체 그래프의 부분 에지 집합 .
목표는 다음을 만족하는 희소한 에지 집합을 찾는 것:
- : 전체 모델 출력
- : 회로만 남기고 나머지는 interchange ablation으로 대체한 출력
- D: KL(토큰 분포 간)
- : 의미만 살짝 바꾼 corrupted 입력 (in-distribution 유지)
핵심: 에지를 “없애면 0”이 아니라, corrupted activation으로 대체 → 분포 붕괴 방지.
2) 에지 마스킹: 이산을 연속으로 풀어 gradient 최적화
각 에지 에 연속 마스크 를 둡니다.
노드 i의 입력은 clean/ corrupted activation의 선형 보간:
- : clean 경로 사용
- : corrupted 경로 사용
ACDC(에지 하나씩 제거)·EAP(1차 근사)와 달리, 모든 에지를 동시에 최적화.
3) Disentangled Residual Stream (필수 구조 변경)
일반 Transformer는 residual을 누적해 단일 벡터로 전달 →
에지별 선택이 생기면 “각 노드가 보는 residual”이 달라짐.
해결:
- 모든 이전 컴포넌트의 출력 을 리스트로 보관
- 각 노드 입력에서 마스크로 필요한 것만 집계
비용(메모리)은 늘지만, 원거리 에지까지 정확히 제어 가능.
4) 희소성 강제: L0 정규화 (Hard Concrete)
에지 마스크를 Hard Concrete 분포로 파라미터화:
- 학습 변수:
- 샘플 → sigmoid → stretch → clamp → 에 가깝게
목표 sparsity는 라그랑지안으로 제어:
- s: 현재 sparsity
- t: 타깃 sparsity(훈련 중 선형 증가)
훈련 후 threshold로 이진화 → 최종 회로 결정.
5) 노드 마스크(가속 장치)
실무적으로:
- 노드 마스크 를 추가
- 실제 에지 활성은
효과:
- 중요 없는 컴포넌트 묶음을 빠르게 제거
- 최종 sparsity 수렴 안정화 (라그랑지안은 에지에만 적용)
6) 학습 절차 요약 (Algorithmic View)
- clean/ corrupted 입력으로 모든 activation 계산
- disentangled residual에 저장
- 각 에지 마스크 z로 clean/ corrupted 보간
- KL 손실 + L0 라그랑지안 최소화 (SGD/Adam)
- 타깃 sparsity 스케줄링
- threshold로 이진화 → 회로 출력
7) 왜 이게 잘 되나? (직관)
- 동시 최적화: 에지 상호작용을 직접 반영
- in-distribution 대체: 제거 부작용 최소화
- 연속→이산: 대규모 그래프에서도 효율적
- 구조 변경: 에지 단위 제어가 정확해짐
8) 기존 방법과의 방법론적 차이
| 방법 | 핵심 가정 | 한계 |
|---|---|---|
| ACDC | 에지 하나씩 영향 평가 | 조합 상호작용 무시, 비확장 |
| EAP | 1차 테일러 근사 | 비선형/상호작용 손실 |
| Edge Pruning | 연속 마스크로 전역 최적화 | 메모리 요구 ↑ |
한 줄 요약
Edge Pruning은 “에지 선택”을 L0-정규화된 연속 최적화로 바꾸고, residual을 분해해 정확한 counterfactual 보간을 가능하게 함으로써, 대규모 모델에서도 faithful한 회로를 찾는다.
아래는 논문 방법론 중 3) Disentangled Residual Stream (필수 구조 변경) 을 왜 필요한지 → 무엇을 바꾸는지 → 수식 수준에서 어떻게 달라지는지 → 기존 residual과의 본질적 차이 순서로 정리한 설명입니다.
왜 필요한가? (핵심 동기)
Edge Pruning은 “에지 단위”로 clean / corrupted activation을 선택합니다.
그런데 표준 Transformer residual stream은 다음처럼 동작합니다:
즉,
- 각 레이어는 단일 벡터 만 봄
- 과거 정보는 이미 모두 섞여(add) 있음
👉 이 상태에서
“에지 는 clean, 에지 는 corrupted”
같은 에지별 선택을 하려면 불가능합니다.
왜냐하면 안에는 이미 가 구분 없이 합쳐져 있기 때문입니다.
무엇을 바꾸는가? (아이디어)
논문은 residual을 누적 벡터 하나로 들고 가는 대신,
모든 과거 컴포넌트의 출력들을 분리된 상태로 보관하고,
각 노드 입력에서 “어떤 출력들을 읽을지”를 에지 마스크로 결정합니다.
이를 Disentangled Residual Stream이라 부릅니다.
구조적 차이 (표준 vs Disentangled)
1️⃣ 표준 Transformer
- 상태:
- 레이어 i는 혼합된 하나의 벡터만 입력으로 받음
- 에지 단위 제어 ❌
2️⃣ Disentangled Residual Stream
- 상태:
- 레이어 i는:
- 이 리스트 전체를 보고
- 에지 마스크 z_ 로 필요한 activation만 선택
즉, residual이
“합(sum)” → “activation 리스트”
로 바뀜.
수식으로 보면 정확히 뭐가 달라지나
논문 식 (3):
여기서 중요한 점:
- 모두 개별적으로 존재
- 가 “이 에지를 통해 무엇을 읽을지” 결정
- residual stream 자체는 더 이상 고정된 값이 아님 → 노드마다 다른 residual을 본다
📌 이게 표준 Transformer에서는 구조적으로 불가능.
직관적 해석 (아주 중요)
Disentangled residual은 다음 질문을 가능하게 합니다:
“레이어 i가 판단할 때,
어떤 이전 컴포넌트의 출력이 정말로 필요했는가?”
즉,
- attention head / MLP를 정보 생산자
- residual stream을 정보 저장소
- edge를 정보 접근 권한
으로 분리해 버린 구조입니다.
→ 회로(circuit) 를
“누가 누구의 정보를 읽는가”의 그래프로 직접 다룰 수 있음
Interchange Ablation과의 결합이 왜 자연스러운가
에지를 끊으면 단순히 0을 넣는 것이 아니라:
- clean activation 대신
- corrupted activation 를 넣음
이때 Disentangled 구조 덕분에:
- “이 에지 하나만” counterfactual로 바꾸는 것이 정확히 가능
- 다른 에지들의 activation은 그대로 유지
👉 edge-level counterfactual intervention 이 정확해짐
(기존 residual 구조에서는 불가능)
비용과 트레이드오프
| 장점 | 비용 |
|---|---|
| 에지 단위 제어 가능 | GPU 메모리 ↑ |
| edge interaction 정확히 반영 | 구현 복잡 |
| 대규모 모델에서도 faithful | 병렬화 필요 |
그래서 논문은:
- gradient checkpointing
- FSDP
- multi-GPU 로 CodeLlama-13B까지 확장함
기존 방법들과의 연결 고리
- ACDC / EAP → 개념적으로 “disentangled graph”를 가정하지만 → 실제 forward는 표준 residual 위에서 근사
- Edge Pruning → 구조 자체를 바꿔서 가정과 구현을 일치시킴 → 그래서 faithfulness가 크게 개선됨
한 줄 요약
Disentangled Residual Stream은 residual을 ‘합’이 아닌 ‘activation 목록’으로 바꿔,
각 노드가 어떤 이전 컴포넌트의 출력을 읽는지를
에지 단위로 정확히 제어·최적화할 수 있게 만든 구조적 핵심이다.
아래는 4) 희소성 강제: L0 정규화 (Hard Concrete) 를
(왜 L0인가) → (Hard Concrete가 뭔가) → (수식/학습 메커니즘) → (라그랑지안으로 목표 sparsity 맞추기) → (실무 디테일/함정) 순서로 정리한 설명입니다.
4.1 왜 L0 정규화인가?
회로 찾기의 목표는 본질적으로:
“가능한 한 적은 edge만 남기되, 모델 행동은 그대로 유지”
입니다. 이는 곧
- L1: 값이 작아지지만 정확히 0은 잘 안 됨
- L2: 희소성 유도 불가
- L0: 정확히 몇 개의 edge를 켤지를 직접 제어
👉 회로(circuit)는 이산 구조이므로, 이상적인 목적함수는 L0.
문제는:
- L0는 미분 불가능
- edge 수가 수백만 → 조합 최적화 불가
그래서 등장하는 게 Hard Concrete relaxation.
4.2 Hard Concrete: “미분 가능한 Bernoulli”
Hard Concrete(Louizos et al., 2018)는
Bernoulli(0/1) 를 다음처럼 연속 확률변수로 근사합니다:
“학습 중에는 연속,
추론/해석 단계에서는 거의 0 또는 1”
즉,
- forward: 거의 이진 mask
- backward: gradient 흐름 가능
4.3 Hard Concrete 수식 (논문 그대로)
각 edge mask z는 다음 과정으로 샘플링됨:
1️⃣ Uniform noise
2️⃣ Logit + temperature
- : 학습 파라미터
- : temperature (논문에서는 )
3️⃣ Stretch
4️⃣ Hard clamp
📌 결과:
- 대부분의 z는 정확히 0 또는 1
- 일부만 (0,1) 내부 → gradient 전달
4.4 L0 항은 어떻게 계산되나?
Hard Concrete의 핵심 장점:
“이 mask가 0이 아닐 확률”을 닫힌형태로 계산 가능
즉,
이 확률은 의 함수로 계산됨
→ L0 penalty를 미분 가능하게 근사
4.5 목표 sparsity를 맞추는 방식: 라그랑지안
논문은 “그냥 L0를 줄이자”가 아니라:
“정확히 이 정도 sparsity를 달성하자”
를 원함.
그래서 아래 constraint-style 라그랑지안을 사용:
- s: 현재 sparsity (edge 기준)
- t: 목표 sparsity
- : 학습 중 업데이트
📌 중요한 디테일:
- t는 훈련 초반엔 0 → 점점 증가
- 즉, 처음엔 dense → 점진적으로 prune
이게 없으면:
- 초반에 너무 많이 죽어서 학습 붕괴
- 혹은 local minimum에 고정
4.6 전체 손실 함수
최종적으로 최적화하는 목적함수:
- 모델 파라미터는 freeze
- 오직 만 학습
4.7 왜 “edge + node mask”를 같이 쓰나?
논문 구현상 중요한 포인트:
- edge mask만 쓰면:
- sparsity가 잘 안 올라감
- 수렴이 느림
그래서 추가:
- node mask
- 실제 edge 활성:
효과:
- 중요 없는 노드가 꺼지면 그 노드의 모든 outgoing edge 즉시 제거
- 대규모 모델에서 수렴 안정성 ↑
📌 단,
- sparsity 라그랑지안은 edge에만 적용
- node mask는 가속용 보조 장치
4.8 왜 thresholding이 필요한가?
훈련 후에도 z는 정확히 0/1이 아님.
논문은:
- 모든 mask 평균값으로 실제 sparsity 추정
- binary search로 threshold 탐색
- 가 원하는 sparsity가 되도록 설정
→ 정확히 원하는 sparsity의 회로를 얻음
4.9 직관 요약 (중요)
Hard Concrete + L0는 다음 질문에 답하게 해줍니다:
“이 edge는 있어야 하나, 없어도 되나?”
- 값 크기(X)
- gradient 크기(X)
- 실제로 모델 행동에 기여하는가(O)
즉,
EAP처럼 중요도 점수로 정렬하는 게 아니라
회로 전체를 한 번에 ‘선택 최적화’ 하는 방식.
4.10 EAP / ACDC와의 본질적 차이 (희소성 관점)
| 방법 | 희소성 처리 |
|---|---|
| ACDC | greedy edge 제거 |
| EAP | 중요도 정렬 후 top-k |
| Edge Pruning | L0 제약 하의 전역 최적화 |
👉 “top-k가 왜 최적인지”를 묻지 않아도 됨
👉 최적화가 직접 답을 줌
한 줄 요약
Hard Concrete L0 정규화는
‘회로는 이산 구조’라는 사실을 존중하면서도
gradient 기반으로 수백만 개 edge 중
필요한 것만 정확히 선택하게 만드는 핵심 장치다.
아래는 4.3 Hard Concrete 수식을 한 줄 한 줄 의미·역할 중심으로 해부한 설명입니다.
(“왜 이런 수식이 필요한가 / 각 항이 sparsity에 어떻게 작동하는가”에 초점을 둡니다.)
전체 목표 요약 (맥락)
- 각 edge mask z 를 0/1에 가까운 값으로 만들되
- gradient 기반 학습이 가능해야 함 → Hard Concrete = 미분 가능한 Bernoulli 근사
Hard Concrete 생성 과정 (Step-by-step)
논문에서 edge mask z는 다음 절차로 생성됩니다.
(1) Uniform noise
의미
- Bernoulli 샘플링을 reparameterization 하기 위한 noise
- 는 수치적 안정성 (보통 )
왜 필요한가
- 샘플링이 있어야 “확률적 on/off”가 가능
- gradient는 \log\alpha로만 흐르게 설계
(2) Logistic noise + logit shift
이게 핵심 수식입니다.
각 항의 역할
- → Logistic noise → Bernoulli를 연속 확률변수로 만드는 핵심
- → 학습되는 파라미터 → “이 edge가 살아남고 싶은 정도”
- (temperature) → 작을수록 더 sharp (0/1에 가까움)
직관
즉,
edge 생존 확률을 하나로 제어
(3) Stretch (범위 확장)
왜 [0,1]이 아니라 [-0.1, 1.1]?
- 일부 값이 0 아래 / 1 위로 넘어가도록 허용
- 다음 단계의 hard clamp에서
- 확률 질량이 정확히 0 또는 1에 쌓이게 함
👉 이 단계가 “Hard” 의 핵심
(4) Hard clamp (이산화)
결과:
- z = 0 (완전히 꺼짐)
- z = 1 (완전히 켜짐)
- 극소수만 0<z<1 (gradient 전달용)
중요
- forward에서는 거의 이진 mask
- backward에서는 여전히 미분 가능
전체 흐름 요약 그림 (개념)
Uniform noise
↓
Logistic noise + log α
↓
Sigmoid (temperature)
↓
Stretch [-0.1,1.1]
↓
Hard clamp → z ∈ {0,1} (mostly)L0와의 연결: “이 edge가 살아 있을 확률”
Hard Concrete의 강력한 점:
이 확률은 닫힌형태로 계산 가능하고
의 함수입니다.
👉 그래서
- L0 penalty를 직접 미분
- sparsity를 확률적으로 제어
Edge Pruning에서의 의미 (중요)
Hard Concrete 덕분에:
- ❌ “gradient 크니까 중요”
- ❌ “top-k만 남기자”
가 아니라,
“이 edge를 남긴 채로 다른 edge들과 함께 최적화했을 때
모델 행동을 유지하는가?”
를 전역 최적화로 판단할 수 있음
→ EAP / ACDC와 결정적 차이
자주 헷갈리는 포인트 정리
Q1. 왜 Gumbel-Softmax 안 쓰나?
- Gumbel은 categorical
- 여기선 independent Bernoulli mask가 필요
- L0 기대값 계산이 Hard Concrete가 훨씬 깔끔
Q2. 왜 temperature 고정?
- 목적은 sampling 다양성 ❌
- 목적은 안정적인 pruning
- 논문에서는 고정
한 줄 핵심 정리
Hard Concrete 수식은
“edge의 생존 여부”를
하나의 스칼라 로 표현하고,
거의 이산적인 선택을 하면서도
gradient 기반 L0 최적화를 가능하게 만드는 장치다.
아래에서는 정확히 왜 가 닫힌형태로 계산되는지를 수식 전개를 한 단계씩 보여드리겠습니다.
목표
Hard Concrete mask z에 대해
를 의 함수로 정확히 계산하고 싶다.
1️⃣ Hard Concrete에서 z>0의 의미
정의 복습:
따라서
논문 설정:
- l=-0.1,\; r=1.1
- r-l=1.2
즉,
edge가 “켜져 있다” ≡ sigmoid 출력 s가 임계값 를 넘는다
2️⃣ s의 정의 다시 쓰기
여기서
- u
3️⃣ 확률 계산:
Sigmoid의 단조성(monotonicity)을 이용해 양변에 logit 적용:
4️⃣ u에 대해 정리
지수 취하면:
정리:
5️⃣ Uniform 분포이므로 확률은 바로 계산됨
이므로
따라서
🎉 닫힌형태(closed-form) 완성
6️⃣ 최종 L0 기대값 공식
각 edge e에 대해:
(위 식은 를 대입한 형태)
👉 L0 penalty는 단순히 sigmoid 함수 하나
7️⃣ 왜 이게 혁명적인가?
🔹 (1) L0가 “진짜로” 미분 가능
- 근사 아님
- 기대값 정확 계산
🔹 (2) gradient가 매우 직관적
→ pruning 압력이 자연스럽게 작동
🔹 (3) top-k 같은 휴리스틱 불필요
- “몇 개를 남길지”를 제약 조건으로 직접 제어
8️⃣ Edge Pruning에서의 해석 (중요)
이 의미는 다음과 같습니다:
각 edge는 “살아 있을 확률”이라는
단 하나의 스칼라 로 표현된다.
그리고 학습은:
- faithfulness loss → ↑
- sparsity constraint → ↓
의 줄다리기
→ 최종적으로
- 반드시 필요한 edge만
- 불필요한 edge는
한 줄 요약
Hard Concrete의 L0 기대값은
“mask가 0보다 클 확률”로 정확히 계산되며,
이는 에 대한 sigmoid 닫힌형태를 가져
대규모 edge 선택을 안정적인 gradient 최적화 문제로 바꾼다.
답글 남기기