



논문 “Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis” (ACL 2025) 은 데이터 오염(data contamination) 문제로 인해 LLM 평가의 신뢰성이 손상되는 문제를 해결하기 위해, 모델 내부의 “지름길 뉴런(shortcut neurons)”을 분석하고 억제함으로써 공정하고 신뢰할 수 있는 평가를 수행하는 방법을 제안한 연구입니다.
아래는 주요 내용 요약입니다.
연구 배경 및 문제의식
- 데이터 오염(data contamination): 공개 벤치마크의 일부가 LLM의 학습 데이터에 포함되어, 모델이 단순히 정답을 ‘암기’한 상태로 높은 점수를 받는 문제. → 이는 모델의 진짜 능력(capability) 이 아니라 기억/패턴 지름길(shortcut) 에 의해 평가 점수가 부풀려지는 현상.
- 기존 연구들은 오염을 줄이기 위해 새로운 벤치마크를 계속 만드는(dynamically updating) 방식을 사용했지만,
- 유지비용이 높고,
- 근본적인 해결책이 아님.
따라서 이 논문은 모델 내부의 원인, 즉 오염된 모델이 “지름길 뉴런(shortcut neurons)” 을 통해 인위적으로 높은 점수를 얻는 메커니즘을 분석하고, 이를 억제함으로써 신뢰할 수 있는 평가를 가능하게 하려 함.
방법론 개요
1. Shortcut Neuron 가설
- 오염된 모델(contaminated model)은 특정 뉴런들이 문제 형식(input format) 이나 정답 패턴(reasoning shortcut) 을 암기함으로써 비정상적으로 높은 점수를 낸다.
- 이러한 뉴런을 찾아 억제하면, 모델의 진짜 능력만 평가할 수 있다.
2. Shortcut Neuron 탐지 단계 (Locate)
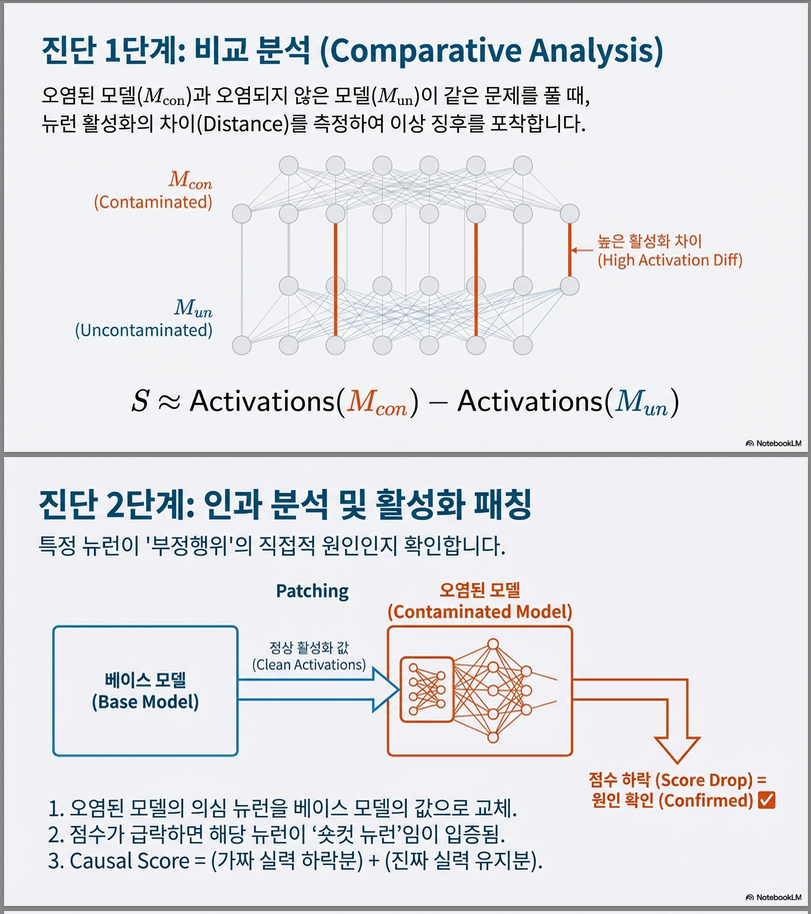
(1) 비교 분석 (Comparative Analysis)
- 동일한 벤치마크 샘플 x 에 대해,
- 오염된 모델 과 비오염 모델 의 뉴런 활성값을 비교.
- 뉴런 i의 비교 점수: → 활성화 차이가 큰 뉴런일수록 오염 관련 가능성이 높음.
(2) 인과 분석 (Causal Analysis)
- Activation Patching (활성화 패칭): 오염 모델의 뉴런 활성값을 기준(base) 모델의 활성값으로 교체한 뒤 정확도 변화를 측정.
- 뉴런 집합 N의 인과 점수: → 오염 모델의 성능이 크게 떨어지면서 비오염 모델의 성능은 유지될수록, 그 뉴런이 shortcut neuron일 가능성이 높음.
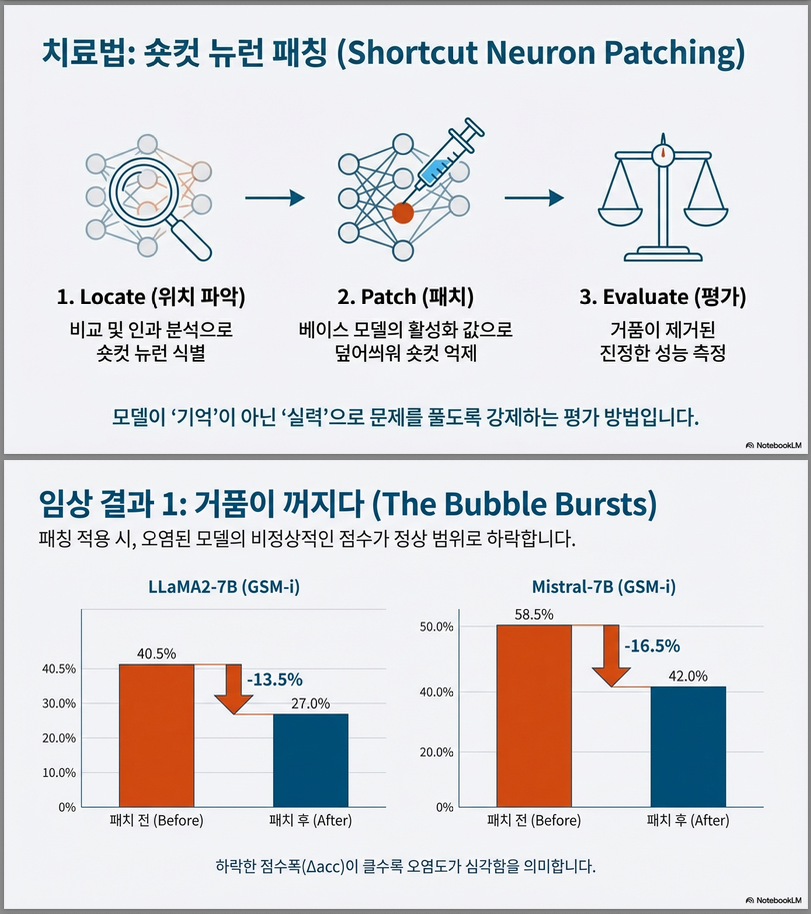
3. Shortcut Neuron Patching (평가 단계)
- 평가 대상 모델 의 지름길 뉴런을 기준 모델 의 활성값으로 패치하여 오염된 영향을 제거.
- 이를 통해:
- 지름길 추론 억제 (behavior shortcut)
- 입력 포맷 편향 제거 (input shortcut)
- 진짜 성능 평가 (trustworthy evaluation) 가능.
실험 결과
설정
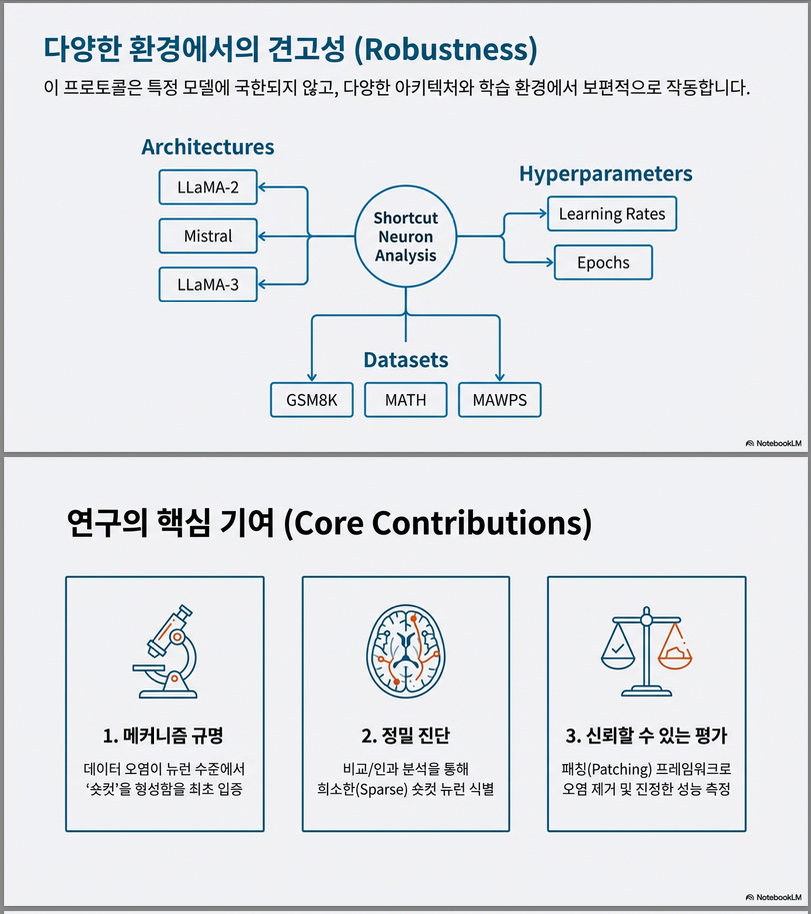
- 모델: LLaMA2-7B, Mistral-7B-v0.2
- 데이터셋: GSM8K, MATH, MAWPS, SVAMP, ASDiv 등 수학 추론 벤치마크
- 오염 모델 vs 비오염 모델을 각각 fine-tuning하여 비교.
주요 발견
1. Shortcut Neuron은 희소(sparse)
- 약 5,000개 뉴런(전체의 1% 수준) 만 억제해도 오염 효과가 사라짐.
- 20,000개 이상 패치하면 오히려 정상 성능 저하 → 따라서 지름길 뉴런은 국소적임.
2. 신뢰할 수 있는 평가 점수
- 오염 모델의 성능은 평균 37% 감소, 비오염 모델은 3% 이내 변화 → 정확히 지름길만 억제됨.
3. 참조 벤치마크와 높은 상관관계
- OpenMathInstruct-2 및 MixEval 점수와의 Spearman 상관계수 ρ > 0.95 → 제안된 평가 점수가 “진짜 능력”을 정확히 반영.
4. 일반화
- 다른 벤치마크(MA WPS, MATH)나 학습률·오염정도 변화에도 동일하게 동작.
- 다른 아키텍처(LLaMA3-8B)에도 적용 가능.
대표 실험 예시 (Table 2 요약)
| Model | Original Acc | Trustworthy Eval (TE) | ΔAcc | Interpretation |
|---|---|---|---|---|
| LLaMA2-7B + GSM-i | 40.5 | 27.0 | −13.5 | 데이터 오염 억제 성공 |
| LLaMA2-7B + GSM8K Train | 35.0 | 28.5 | −6.5 | 입력 포맷 오염 억제 |
| LLaMA2-7B + MATH | 19.5 | 19.0 | −0.5 | 영향 없음 (비오염) |
논문의 의의
| 측면 | 내용 |
|---|---|
| 분석 단위 | 뉴런 수준의 활성화 분석 (activation-level inspection) |
| 주요 개념 | Shortcut Neuron — 오염으로 인해 형성된 비정상적 활성화 패턴 |
| 목표 | 벤치마크 교체 없이, 모델 내부 분석으로 신뢰 가능한 평가 수행 |
| 확장성 | 수학, 추론, 코드 생성 등 다양한 task에서 contamination 탐지 가능 |
| 지표 | Spearman ρ ≈ 0.97, RMSE ≈ 3.7 — MixEval과 거의 일치 |
결론 및 한계
- 기여: 1. 최초로 “오염 → shortcut neuron → 과대평가”의 인과경로를 규명. 2. Comparative + Causal 분석으로 shortcut 뉴런 탐지. 3. Shortcut Neuron Patching으로 신뢰 가능한 LLM 평가 실현.
- 한계:
- 현재는 LLaMA2-7B / Mistral-7B 중심 실험.
- 수학 reasoning task 중심 → 다른 도메인 확장은 과제.
- base 모델도 완전히 ‘비오염’이라 가정하지만 실제로는 불확실.
요약하자면,
이 논문은 “데이터 오염 문제를 벤치마크 수준이 아니라 뉴런 수준에서 해결하려는 시도”로, 신뢰 가능한 LLM 평가(trustworthy evaluation) 를 위한 새로운 프레임워크를 제시한 연구입니다.
Methodology
이 논문의 방법론은 다음 두 단계로 구성됩니다:
- Shortcut Neuron 탐지 (Locate)
- Shortcut Neuron Patching을 통한 신뢰 가능한 평가 (Evaluate)
핵심 아이디어는 다음과 같습니다:
데이터 오염으로 인해 모델 내부에 “지름길(shortcut)”을 담당하는 특정 뉴런 집합이 형성되며,
이 뉴런들을 억제하면 모델의 진짜 능력을 복원할 수 있다.
1. Shortcut Neuron 탐지 (Locate Phase)
1.1 사전 준비: 세 가지 모델
같은 아키텍처 (base model)에서 다음을 fine-tuning하여 생성:
- : contaminated model
- : uncontaminated model
- : vanilla base model
이때 벤치마크 D (예: GSM8K 일부)를 오염 데이터로 사용.
2. Comparative Analysis (비교 분석)
목적
오염 모델과 비오염 모델 간 뉴런 활성화 차이를 측정하여 shortcut 후보 뉴런을 찾는다.
뉴런 정의
Transformer의 FFN에서 뉴런은 down-projection 이전 activation:
- : layer l의 token representation
- : MLP weight row
- : activation function
논문에서는 마지막 토큰의 activation 사용:
비교 점수 정의
뉴런 i (layer l)의 비교 점수:
해석
- 활성화 차이가 클수록:
- contaminated 모델에서만 특별히 활성화됨
- → memorization / shortcut 가능성 높음
즉, 통계적 divergence 기반 후보 추출
3. Causal Analysis (인과 분석)
비교 분석은 상관(correlation) 기반.
진짜 shortcut인지 확인하려면 인과성을 측정해야 함.
3.1 Activation Patching
아이디어
특정 뉴런의 activation을 base model 값으로 교체하여
모델 성능이 어떻게 변하는지 관찰.
Dynamic Patching (open-ended task용)
For generation step t:
- 실행 → 뉴런 activation 캐시
- 실행 → 해당 뉴런 activation 교체
- 다음 토큰 생성
- 반복
3.2 Causal Score 정의
뉴런 집합 N에 대해:
해석
좋은 shortcut neuron 조건:
- 성능 크게 감소
- 성능 거의 유지
→ contamination 전용 지름길 뉴런
4. Shortcut Neuron Selection
- Comparative score 상위 뉴런 추출
- Causal score 검증
- 상위 5000개 선택
실험 결과:
- 전체 뉴런의 약 1% 수준
- sparse
- contaminated model만 성능 감소
5. Trustworthy Evaluation Phase
Shortcut Neuron Patching
평가 대상 모델 에 대해:
즉:
shortcut 뉴런 activation을 base model 값으로 대체
기대 효과
| 상황 | 결과 |
|---|---|
| 오염 모델 | 점수 감소 (진짜 능력으로 복원) |
| 비오염 모델 | 거의 변화 없음 |
| 일반 reasoning 능력 | 유지 |
6. 전체 파이프라인 정리
1. Fine-tune base model → M_con / M_un
2. Compute comparative score (activation divergence)
3. Compute causal score (dynamic activation patching)
4. Select top shortcut neurons (~5000)
5. During evaluation:
Patch shortcut neurons
→ Measure trustworthy score7. 수학적 구조 관점에서 정리
본 방법은 다음과 같은 구조적 가정을 기반으로 함:
Shortcut neuron patching은:
을 구현하는 neuron-level intervention.
8. 이 방법의 본질적 의미
기존 접근
- 벤치마크를 바꿈
- 데이터 암호화
- dynamic test construction
본 논문 접근
- 모델 내부의 shortcut 회로를 직접 제거
- 일종의 “mechanistic evaluation correction”
9. 한 줄 요약
이 논문의 방법론은
Comparative + Causal neuron analysis로 contamination-induced shortcut을 찾아내고,
activation patching으로 이를 제거하여 신뢰 가능한 LLM 평가를 수행하는 프레임워크이다.
Experimental Results
논문의 실험은 다음 질문에 답하기 위해 설계되었습니다:
- Shortcut neuron은 실제로 존재하는가?
- Patching이 오염 모델의 “가짜 성능”만 제거하는가?
- 일반 능력에는 부작용이 없는가?
- 실제 신뢰 벤치마크와 상관관계가 높은가?
- 다른 데이터셋·아키텍처·하이퍼파라미터에도 일반화되는가?
1. Shortcut Neuron은 희소한가?
실험: patch할 뉴런 개수를 점진적으로 증가
- 오염 모델과 비오염 모델 각각에 대해
- top-k 뉴런을 패치하면서 정확도 변화 관찰
결과 (Figure 3)
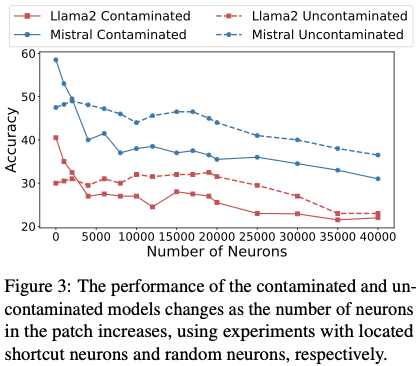
- 약 5,000개 뉴런 패치 시:
- 오염 모델 정확도 → 비오염 모델 수준으로 감소
- 비오염 모델 정확도 → 거의 변화 없음
- 20,000개 이상 패치 시:
- 두 모델 모두 성능 하락
결론
- shortcut neuron은 약 1% 수준 (LLaMA2-7B: 1.4%, Mistral: 1.1%)
- 매우 sparse
- 특정 기능 서브스페이스에 집중되어 있음
2. 오염 모델에서 성능 감소 (핵심 결과)
설정
- 모델: LLaMA2-7B, Mistral-7B
- 벤치마크: GSM8K
- 오염 설정: GSM-i를 1× 또는 5× fine-tuning
대표 결과 (Table 2 요약)
LLaMA2-7B
| 모델 | Original | TE (patched) | ΔAcc |
|---|---|---|---|
| +GSM-i | 40.5 | 27.0 | −13.5 |
| +5×GSM-i | 80.0 | 30.2 | −49.8 |
| +GSM-i-Syn | 33.4 | 20.5 | −12.9 |
→ 오염이 강할수록 패치 후 큰 폭 감소
Mistral-7B
| 모델 | Original | TE | ΔAcc |
|---|---|---|---|
| +GSM-i | 58.5 | 42.0 | −16.5 |
| +5×GSM-i | 88.7 | 45.6 | −43.1 |
평균 결과
- 오염 모델: 평균 −37% 감소
- 비오염 모델: 평균 3% 이내 변화
–> shortcut만 제거되고 정상 능력은 유지됨
3. Input Format Shortcut 억제
GSM8K train set으로 fine-tuning한 경우:
| 모델 | Original | TE | ΔAcc |
|---|---|---|---|
| +GSM8K Train | 35.0 | 28.5 | −6.5 |
→ 문제 포맷에 맞춘 “입력 shortcut”도 제거됨
4. 정상 능력 유지 검증
테스트 벤치마크
- MAWPS (수학 추론)
- MMLU (종합 추론)
결과 (Table 3)
| 모델 | MAWPS Δ | MMLU Δ |
|---|---|---|
| 대부분 모델 | ±1~2% | ±1~2% |
결론:
- shortcut neuron 패치는 일반 reasoning 능력을 손상시키지 않음
5. 참조 벤치마크와의 상관관계
비교 대상
- OpenMathInstruct-2
- MixEval (real-world aligned benchmark)
상관계수 (Figure 4)
| Reference | Spearman ρ | RMSE |
|---|---|---|
| OpenMathInstruct | 0.970 | 2.96 |
| MixEval | 0.957 | 3.74 |
의미:
- 제안된 TE 점수는 “진짜 능력”을 매우 정확히 반영
- 기존 benchmark 점수보다 현실 능력과 더 일치
6. Real-world 모델 적용
HuggingFace에서 다운로드한 실제 모델들 평가 (Table 9)
예시
| 모델 | Original | TE | ΔAcc |
|---|---|---|---|
| llamaRAGdrama | 45.2 | 21.7 | −23.5 |
| Fewshot-MetaMath | 66.4 | 50.1 | −16.3 |
| flux-7b-v0.2 | 71.6 | 73.3 | +1.7 |
해석:
- 일부 모델은 GSM8K 오염 가능성 높음
- 일부 모델은 오염 없음 → 점수 유지 또는 증가
7. 일반화 실험
(1) 다른 벤치마크
- MAWPS
- MATH
→ 동일 shortcut neuron이 효과 유지
(2) 다양한 hyperparameter
- learning rate 변화
- contamination frequency 1~20×
- 72개 모델 생성
→ MixEval과 상관계수 ρ = 0.935 유지
(3) 다른 아키텍처
LLaMA3-8B (Table 6)
| 모델 | Original | TE | ΔAcc |
|---|---|---|---|
| +5×GSM-i | 90.0 | 67.9 | −22.1 |
| +OpenOrca | 58.9 | 61.3 | +2.4 |
→ 동일한 현상 재현
(4) 다른 task domain
ARC-Challenge 적용 (Table 12)
| 모델 | Original | TE | ΔAcc |
|---|---|---|---|
| SFT-Cheater | 69.8 | 53.8 | −16.0 |
| PT-Cheater | 76.8 | 59.3 | −17.5 |
→ pretraining contamination도 억제 가능
실험 결과 종합 정리
| 질문 | 답 |
|---|---|
| Shortcut neuron 존재? | 있음 (sparse, 약 1%) |
| 오염 모델 점수 감소? | 평균 −37% |
| 정상 능력 손상? | 거의 없음 |
| 참조 benchmark와 일치? | ρ > 0.95 |
| 다른 아키텍처? | 재현됨 |
| 다른 데이터셋? | 재현됨 |
| 다른 hyperparameter? | robust |
핵심 메시지
Shortcut neuron patching은 오염 모델의 “가짜 성능”만 제거하고 진짜 능력은 유지한다.
그리고 그 결과는 현실 benchmark (MixEval)와 거의 완벽하게 일치한다.
답글 남기기