아래에서는 「Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (SAE-RSV)」 논문의 관련연구, 방법론, 실험 결과를 핵심만 구조적으로 정리해 설명합니다.
1. 관련연구 (Related Work)
(1) Steering / Difference-in-Means 계열
- CAA (Contrastive Activation Addition), DoM(Difference-in-Means) 계열은 positive/negative 대비 활성 차이의 평균으로 steering vector를 구성하여, 파라미터 수정 없이 행동 제어를 수행.
- 장점: 단순, 해석 가능
- 한계: 소량 데이터에서는 activation 차이가 잡음(feature noise) 과 표본 편향을 강하게 포함 → 성능 불안정.
(2) Sparse Autoencoder(SAE) 기반 Steering
- SAE는 residual stream을 고차원 sparse feature 공간으로 분해하여 단일 의미(monosemantic) feature를 제공.
- 기존 SAE-steering 연구:
- activation 통계(positive > negative)로 top-k feature 선택
- 문제: 구두점, 빈도 토큰, 형식적 패턴 등 과제 무관 feature가 쉽게 섞임.
(3) 본 논문의 포지션
- 기존 연구들이 **“통계적 활성 크기”**에 의존한 반면, → 본 논문은 **“feature의 의미(semantic explanation)”**를 직접 사용.
- 핵심 기여: (i) 의미 기반 denoising, (ii) 의미 유사도 기반 feature 보강(augmentation)
2. 방법론 (Methodology)
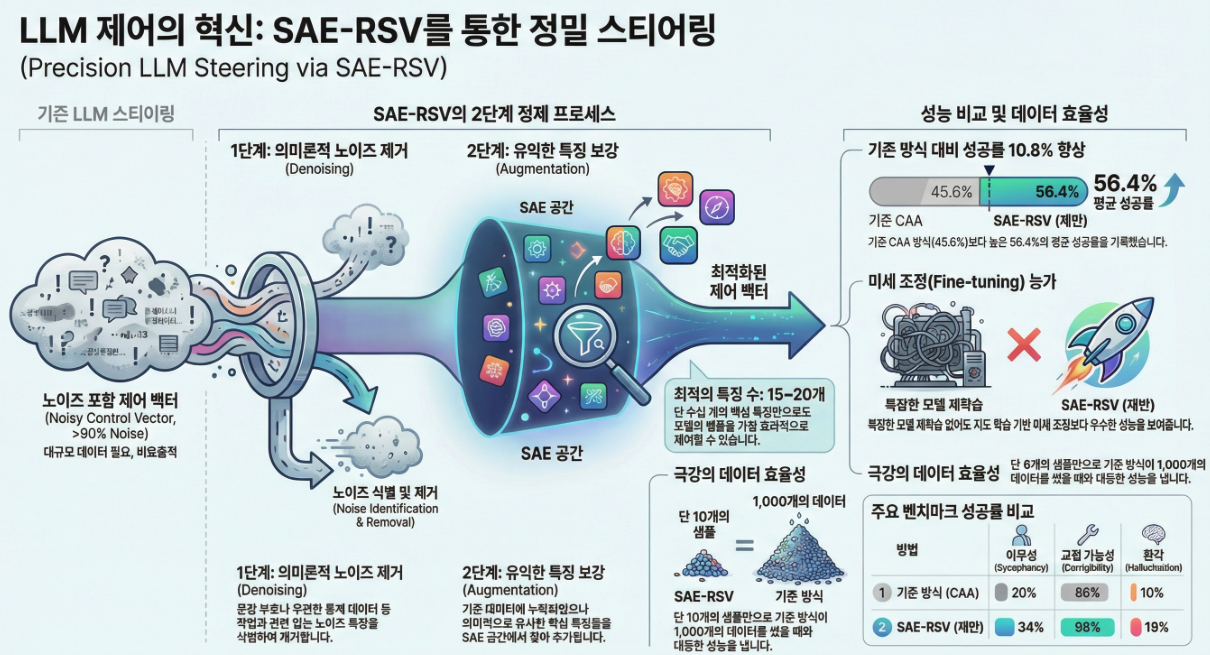
논문은 **SAE-RSV (Sparse Autoencoder-based Refinement of Steering Vector)**라는 2-단계 정제 프레임워크를 제안합니다.
(1) 기본 Steering Vector (CAA 기반)
- contrastive pair , 에 대해
- 문제: 소량 데이터 → 노이즈 다수 포함, 유용 feature 누락
(2) Denoising: 의미 기반 Noise 제거
- SAE feature 공간으로 projection
- positive−negative activation 차이가 양수인 feature를 seed set으로 수집
- 각 feature의 자연어 설명 + top activating token을 LLM(GPT-4o-mini)에 제공
- LLM이 해당 feature가 과제와 의미적으로 관련 있는지 판단 → I_relevant vs I_noise
- noise feature들의 decoder vector를 가중합하여 noise vector 구성:
–> 기존 activation-기반 SAE 선택보다 훨씬 강한 노이즈 제거
(3) Augmentation: 누락된 유용 feature 보강
- 소량 데이터 → 의미적으로 중요한 feature가 아예 활성화되지 않을 수 있음
- 해결 전략:
- 모든 SAE feature의 자연어 설명을 임베딩
- 각 feature c에 대해:
- 점수가 높은 top-K feature를 I_useful로 선택
- decoder weight 평균으로 useful vector 구성:
(4) 최종 Refined Steering Vector
- v_steer: 원래 행동 방향 유지
- − v_noise: 의미적으로 무관한 축 제거
- + v_useful: 데이터 부족으로 누락된 의미 축 보강
–> 저자들은 “denoising + augmentation”이 동시에 필요함을 실험적으로 입증
3. 실험 결과 (Experiments)
(1) 설정
- 모델: LLaMA-3-8B-Instruct
- SAE: 25번째 layer, 65K feature
- 데이터:
- 5개 행동 개념 (Sycophancy, Corrigibility, Hallucination, Myopic Reward, Survival Instinct)
- 훈련: 각 50쌍 contrastive, 테스트: open-ended 50문항
- 평가 지표:
- Success Rate (SR): 목표 행동 충족 비율 (LLM 평가)
- Entropy: 생성 품질/유창성
(2) Baseline 대비 성능
- SAE-RSV는 모든 task에서 최고 SR
- 특히:
- CAA 대비 평균 +10% 이상
- LoRA-SFT(미세조정)보다도 전반적으로 우수
- Fine-tuning은 entropy가 낮아 출력이 지나치게 경직
핵심 메시지
“소량 데이터 환경에서는 SAE-RSV가 fine-tuning보다도 더 강력하고 안정적인 steering을 제공”
(3) Denoising vs Augmentation 기여도
- Augmentation 단독: +7.2% SR
- Denoising 단독: +3.6% SR
- 둘 다 사용 시 최대 성능
- 관찰:
- Denoising만 쓰면 feature 다양성 감소 → entropy 하락
- Augmentation은 의미적으로 다양한 방향 추가 → fluency 개선
(4) Feature 개수 분석
- 평균적으로:
- noise feature ≈ 100+
- 실제 유용 feature ≈ 15–20
- 성능 곡선: Inverted-U
- 너무 적으면 steering 약함
- 너무 많으면 다시 노이즈 유입
(5) 데이터 크기 민감도
- 훈련 샘플 10개만 사용해도:
- SAE-RSV(10) ≈ CAA(1000)
- 데이터가 커져도 항상 baseline 상회
4. 핵심 요약 (한 줄)
SAE-RSV는 “activation 통계”가 아니라 “feature 의미”를 중심으로 steering vector를 정제하여, 소량 데이터 환경에서도 fine-tuning을 능가하는 안정적·해석적 LLM 행동 제어를 달성한다.
아래에서는 (2) Denoising: 의미 기반 Noise 제거와 (3) Augmentation: 누락된 유용 feature 보강을 수식–절차–핵심 직관 중심으로 정리합니다.
(2) Denoising:
의미(semantic) 기반 Noise 제거
문제 인식
- 소량 데이터로 만든 기존 steering vector 에는 과제와 무관한 SAE feature(구두점, 형식, 빈도 토큰 등)가 다수 섞임.
- 기존 방식(activation 통계 기반 top-k)은 통계적 우연에 취약.
핵심 아이디어
“활성 크기”가 아니라 “feature의 의미”로 노이즈를 판별한다.
절차
- Seed feature 집합 구성
- positive/negative 대비에서 양의 기여를 보인 SAE feature들을 모아
- 의미 판별 (LLM 판정)
- 각 feature c의 자연어 설명 (+ top activating tokens)을 LLM에 제공
- “이 feature가 목표 행동과 의미적으로 관련 있는가?”를 yes/no로 판정 → 두 집합으로 분리:
- Noise vector 구성
- 노이즈 feature들의 decoder 방향을 활성 가중합으로 묶어
- (스케일 폭주 방지 위해 정규화)
효과
- 과제 무관 축을 명시적으로 제거 → steering 방향의 정밀도 상승
- 단, 제거만 하면 feature 다양성이 줄어 표현 붕괴/entropy 하락 위험
(3) Augmentation:
누락된 유용 feature 보강
문제 인식
- 소량 데이터에서는 의미적으로 중요한 feature가 아예 활성화되지 않을 수 있음 (즉, 에 포함조차 안 됨)
핵심 아이디어
의미적으로 “가까운” feature를 SAE 전 공간에서 검색해 보강한다.
절차
- Feature 의미 임베딩
- 모든 SAE feature의 설명 를 LLM 임베딩으로 변환:
- 유용도 점수 계산 (Relevant vs Noise 대비)
- 관련 집합에 가깝고, 노이즈 집합과는 먼 feature일수록 점수↑
- Top-K 선택 & 검증
- 점수 상위 K개를 로 선택
- 필요 시 LLM/휴먼으로 의미 검증
- Useful vector 구성
효과
- 훈련에 나타나지 않았던 의미 축을 복원
- feature 다양성 증가 → 유창성(entropy) 회복 및 OOD 일반화 개선
결합 요약 (왜 둘 다 필요한가)
최종 steering은
- Denoising: 잘못된 축 제거(정밀도↑)
- Augmentation: 빠진 축 보강(표현력·유창성↑) → 소량 데이터에서도 안정적·강력한 steering 달성
아래에서는 ② 의미 판별(LLM 판정) 단계를 왜 필요한지 → 무엇을 입력으로 주는지 → LLM이 무엇을 판단하는지 → 출력이 어떻게 쓰이는지 순서로 아주 구체적으로 설명합니다.
② 의미 판별 (LLM 판정): 무엇을 어떻게 묻는가?
1. 왜 LLM 판정이 필요한가?
- SAE feature는 통계적으로 활성되었다고 해서 과제 의미와 관련되었다고 보장되지 않음
- 예:
- 구두점, 숫자, 대화 상투어 → contrastive pair에서 우연히 많이 등장
- 따라서 저자들은 **“이 feature가 실제로 이 행동 개념을 나타내는가?”**를 👉 의미 수준에서 직접 판별하기로 함
2. LLM에 제공하는 입력 정보
각 SAE feature c에 대해 아래 두 가지 정보를 함께 제공:
(a) 자연어 의미 설명
- SAE 연구에서 이미 널리 쓰이는 방식
- 예: “expressions of urgency and limited time” “numeric values or statistical quantities”
–> 이 설명은
- 해당 feature가 언제 활성되는지,
- 어떤 개념을 포착하는지를 요약한 문장
(b) Top activating tokens
- 해당 feature를 가장 강하게 활성화시키는 토큰 목록
- 예:
now, immediately, urgent, right away, quick- 의미 설명이 모호하거나 과도하게 추상적일 때 보조 증거 역할
3. LLM에게 묻는 질문의 형태 (핵심)
LLM은 **이진 판별기(binary semantic filter)**로 사용됨.
기본 프롬프트 구조 (개념별로 다름)
예: Myopic Reward의 경우
Myopic reward refers to responses that demonstrate a focus on short-term gains or
rewards, disregarding long-term consequences.
I will provide you with:
(1) a semantic description of a feature extracted from a sparse autoencoder
(2) a list of top activating tokens
Based on this information, determine whether the feature is related to the
concept of myopic reward.
Semantic description: {T_c}
Top activating tokens: {tokens}
Respond with 'yes' or 'no'.–> 중요한 점
- 점수, 확률, ranking ❌
- 오직 yes / no
- LLM의 역할은: “이 feature는 이 행동 개념을 표현한다고 볼 수 있는가?”
4. LLM이 실제로 판단하는 기준 (암묵적)
논문 전반과 사례 분석을 종합하면, LLM은 사실상 다음을 평가:
| 판단 요소 | 설명 |
|---|---|
| 개념 정합성 | feature 의미가 target behavior 정의와 직접 연결되는가 |
| 일반성 vs 우연성 | 특정 문장/형식/데이터셋 패턴이 아닌가 |
| 행동 수준 추상도 | 단어/형식이 아니라 의사결정 성향·태도를 나타내는가 |
| 반례 가능성 | 다른 task에서도 흔히 등장하는 보편 feature인가 |
예:
- Relevant
- “urgency and quick action” → Myopic Reward
- Noise
- “numeric quantities”, “expressions of gratitude”
5. 판정 결과의 사용 방식
LLM 판정 결과로 seed feature 집합이 명확히 분리됨:
이후:
- → noise vector 구성 후 제거
- →
- 그대로 유지
- Augmentation 단계에서 “의미 anchor”로 사용
6. 왜 이게 중요한가? (기존 방법과의 결정적 차이)
| 기존 SAE-steering | SAE-RSV |
|---|---|
| activation 크기 | 의미 판별 |
| 통계적 top-k | semantic filtering |
| 데이터 의존적 | 데이터-독립적 판단 |
| punctuation/format 오염 | 의미적으로 차단 |
논문에서 밝힌 정량 결과:
- original steering vector의 93.6%가 noise
- 의미 판별 후 남는 feature는 평균 7–15개
- 하지만 성능은 대폭 상승
한 줄 요약
SAE-RSV에서 LLM은 ‘steering을 학습하는 모델’이 아니라,
‘이 feature가 정말 그 행동을 의미하는가’를 판별하는
의미 기반 필터(semantic judge)로 사용된다.
아래는 SAE-RSV 논문의 실험 결과를 핵심 질문별(RQ)로 정리한 요약입니다. 수치·관찰·해석을 함께 담았습니다.
전체 성능 한눈에 보기
설정 요약
- 모델: LLaMA-3-8B-Instruct
- 데이터: 5개 행동(Sycophancy, Corrigibility, Hallucination, Myopic Reward, Survival Instinct)
- 훈련: 각 50쌍 contrastive / 평가: open-ended 50문항
- 지표: Success Rate(SR), Entropy(유창성)
RQ1. 베이스라인 대비 성능은?
결론: SAE-RSV가 모든 과제에서 최고 SR.
- CAA 대비: 4/5 과제에서 +10%p 이상 SR 향상
- LoRA-SFT 대비: 전반적으로 더 높은 SR + 유창성 유지
- LoRA-SFT는 다지선형 훈련 영향으로 entropy 급락(출력 경직)
해석: 소량 데이터에서는 파라미터 업데이트보다 의미 정제된 steering이 더 강력.
RQ2. Denoising vs Augmentation의 기여도는?
(단독/결합 비교)
- CAA → +Denoising: 평균 +3.6%p SR
- CAA → +Augmentation: 평균 +7.2%p SR
- 둘 다 사용(SAE-RSV): 최대 성능
품질(Entropy)
- Denoising만: entropy 감소(축 과도 축소)
- Augmentation 포함: entropy 회복/유지(의미 다양성 보강)
해석: 제거만으로는 부족—보강이 필수.
RQ3. 몇 개의 feature가 최적인가?
- Noise feature: 평균 ~100개 이상
- 실제 유용 feature: 15–20개가 최적
- 성능 곡선: Inverted-U
- 너무 적음 → 효과 미약
- 너무 많음 → 노이즈 재유입
해석: “많이 쓰는 것”이 아니라 정확히 고르는 것이 관건.
RQ4. 하이퍼파라미터 민감도는?
- (noise 제거), (보강) 증가 시 성능 상승
- 과도한 값에서는 성능 하락(과잉 보정)
- 전반적으로 넓은 안정 구간 존재
해석: 실전 적용 시 튜닝 난이도 낮음.
RQ5. 훈련 데이터 크기에 얼마나 강건한가?
- 훈련 10개 샘플에서도 → SAE-RSV(10) ≈ CAA(1000)
- 데이터가 커져도 항상 베이스라인 상회
해석: 저자원 환경에 특히 강함.
정성적 사례(출력 비교)
- CAA 실패 / SAE-RSV 성공 사례 다수
- Myopic Reward: 즉시 보상 선택 유도 성공
- Survival Instinct: 종료/수정 수용 태도 명확
- 문장 유창성 유지하면서 행동 방향만 전환
핵심 요약 (Takeaways)
- 의미 기반 Denoising + 의미 유사도 Augmentation이 함께 작동해야 최고 성능
- 15–20개의 의미 feature만으로도 강력한 steering 가능
- 소량 데이터에서 fine-tuning보다 우수
- 품질 저하 없이 행동 제어 정확도 대폭 향상
SAE feature c의 자연어 의미 설명 는 보통 (A) 자동 해석(auto-interpretability) 파이프라인으로 “설명 생성”을 하거나, (B) 이미 공개된 대시보드/데이터셋에서 가져오거나, (C) 직접 LLM으로 요약 생성하는 방식으로 얻습니다. 아래에 실제로 많이 쓰이는 도구/라이브러리들을 중심으로 정리할게요.
1) 가장 표준: LLM 기반 자동 설명 생성 라이브러리 (추천)
EleutherAI
Delphi
- SAE/Transcoder feature에 대해 **설명 텍스트를 생성 + 점수화(scoring)**까지 지원하는 라이브러리입니다.
- 입력으로 보통 top-activating examples / tokens를 넣고, LLM이 이를 요약해 “이 feature가 무엇을 의미하는지” 설명을 뽑아줍니다.
언제 좋나?
- 본인 SAE를 학습했는데 feature 설명이 없다
- 대량(수만~수십만) feature를 자동으로 설명해야 한다
2) 이미 설명이 달린 feature를 “가져오기”: 대시보드/플랫폼
Neuronpedia
- 여러 공개 SAE에 대해 feature별로 대시보드를 제공하고, feature의 설명(explanation) / top activations / 통계 등을 볼 수 있습니다.
- 연구 커뮤니티에서 auto-interp explanations를 올리고 공유하는 허브 성격이 강해요(모델/레이어/SAE ID로 탐색).
언제 좋나?
- 내가 쓰는 SAE가 Neuronpedia에 이미 올라가 있다면 “설명 생성” 과정을 생략 가능
- 논문 재현/분석(예: feature semantics를 바로 사용)할 때 매우 편함
3) SAE 학습/분석 “인프라”: SAELens (+ 시각화)
decoderesearch
SAELens
- SAELens 자체가 “설명 생성”을 직접 표준화해 제공한다고 단정하긴 어렵지만,
- 사전학습 SAE 다운로드/분석/대시보드 생성(연동) 흐름을 제공하고
- feature별 top activating tokens / examples를 뽑아 (Delphi 같은) auto-interpretability에 태우는 기반으로 많이 씁니다.
- 튜토리얼/코스 자료에서도 SAELens를 SAE 분석 도구로 소개합니다.
언제 좋나?
- SAE 학습부터 실험까지 일관된 파이프라인(TransformerLens 스타일)을 원할 때
- feature 설명은 Delphi/Neuronpedia를 붙여서 해결하는 경우가 많음
4) “직접 만들기”: 가장 흔한 실무 파이프라인(간단 버전)
논문 SAE-RSV에서 말하는 는 보통 아래 중 하나로 얻습니다:
- top-activating tokens / examples 수집
- LLM에게 “이 tokens/examples의 공통 패턴을 1–2문장으로 요약해라” 프롬프트
- 출력 문장을 로 저장
- (선택) Delphi 같은 scorer로 품질 점검
이 방식은 “라이브러리 없이도” 만들 수 있지만, 대규모에선 Delphi가 편합니다.
5) 참고: “왜 설명이 필요한가”에 대한 배경
- SAE를 통해 monosemantic features를 뽑고, 이를 사람이 이해 가능한 “설명”으로 붙이는 흐름은 Transformer Circuits/monosemanticity 계열 연구에서 대중화됐습니다.
결론: 어떤 걸 쓰면 되나?
- 내 SAE feature에 설명이 없다 → Delphi로 자동 생성 (가장 실용적)
- 공개 SAE를 쓰고 있고 설명이 이미 있다 → Neuronpedia에서 가져오기
- SAE 학습/분석 파이프라인이 필요 → SAELens로 tokens/examples 뽑고, Delphi/Neuronpedia와 결합
답글 남기기