



이 논문은 ICL(In-Context Learning) 예제 선택(example selection) 문제를 다루며, 기존 DPP 기반 방법의 한계를 극복하기 위해 NDPP (Nonsymmetric Determinantal Point Process) 를 도입한 연구이다.
Compositional Exemplars (CEIL, ICML 2023) 의 후속 발전으로 볼 수 있다.
1. 문제의식
ICL에서는 어떤 demonstration(example)을 넣느냐에 따라 성능 차이가 매우 크다.
기존 방법들은 크게:
(1) Query Similarity 기반
- BM25
- SBERT retrieval
- EPR
즉,
만 보고 예제를 선택한다.
(2) DPP 기반
CEIL 등이 대표적.
DPP는
로 정의되며,
서로 비슷한 예제를 억제한다.
즉,
“다양한(diverse) 예제 집합” 선택에 특화되어 있다.
논문의 핵심 주장:
좋은 ICL example set은 단순히 diverse 하기만 해서는 안 된다.
예를 들어 감정 분석에서
- 예제1: 긍정
- 예제2: 긍정
- 예제3: 긍정
처럼 일관성(consistency) 이 있는 경우도 중요하다.
즉,
ICL에는
- Negative correlation (다양성)
- Positive correlation (일관성)
둘 다 필요하다.
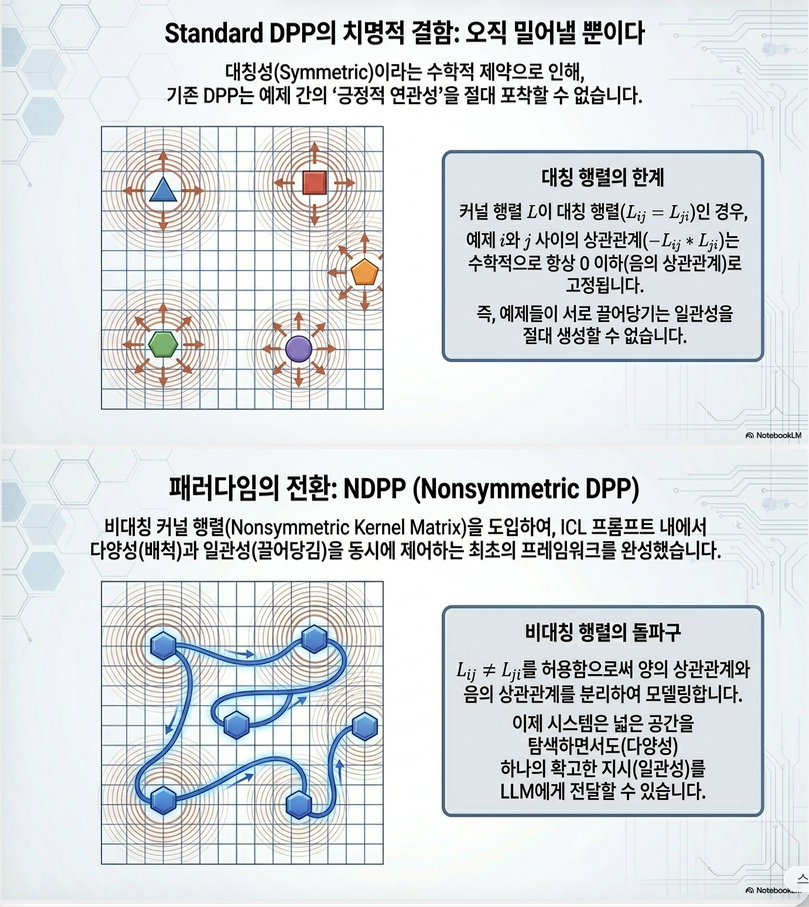
2. DPP의 한계
DPP kernel:
L은 PSD symmetric matrix이다.
즉
DPP에서 두 item의 correlation은
이다.
대칭행렬이면
이므로
항상
이다.
즉, DPP는 음의 상관관계만 표현 가능하다.
3. NDPP
Gartrell et al. (NeurIPS 2019)의 NDPP를 사용한다.
NDPP는 kernel이 비대칭이다.
따라서
가 양수도 가능하고 음수도 가능하다.
결과적으로
NDPP는
- Positive correlation
- Negative correlation
을 모두 모델링할 수 있다.
즉
| 관계 | 의미 |
|---|---|
| Positive | 일관성 |
| Negative | 다양성 |
동시 고려 가능하다.
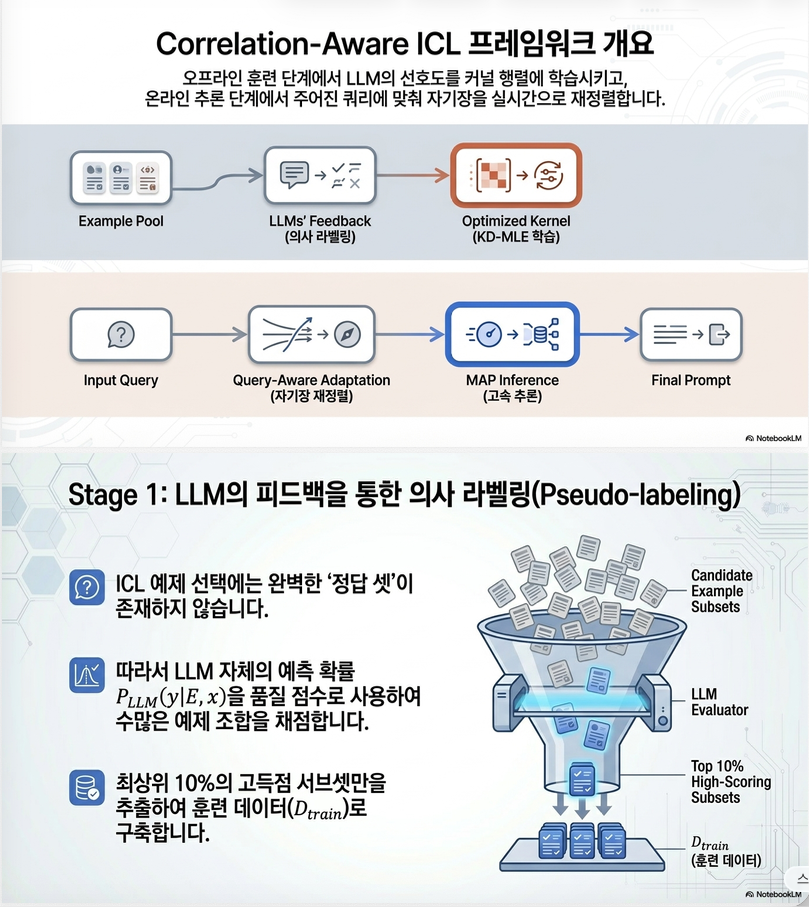
4. 전체 프레임워크
논문 전체 구조는 4단계이다. (Figure 1)

Training
Step 1
Pseudo-labeled subset 생성
↓
Step 2
NDPP 학습
↓
Inference
Step 3
Query-aware kernel adaptation
↓
Step 4
MAP inference
5. Step 1: Pseudo-labeled Dataset 생성
이 부분이 상당히 중요하다.
NDPP를 학습하려면 좋은 example subset이 필요하다.
하지만 GT가 없다.
5.1 Candidate Retrieval
학습 샘플 에 대해
KNN retrieval 수행
획득.
5.2 Subset Sampling
retrieved examples에서
N개의 subset
생성.
5.3 LLM Scoring
각 subset 품질 측정
Prompt:
LLM 입력
정답
의 생성 확률을 계산
즉, “이 subset을 사용했을 때 정답이 얼마나 잘 나오는가?”를 측정한다.
5.4 Top-10% 선택
score가 높은 subset만 선택
구성.
6. Step 2: NDPP 학습
논문의 핵심.
목표
고품질 subset이 높은 확률을 갖도록 NDPP 학습
NDPP:
MLE 수행:
즉, pseudo-labeled subset들이 NDPP에서 높은 확률을 갖도록 학습한다.
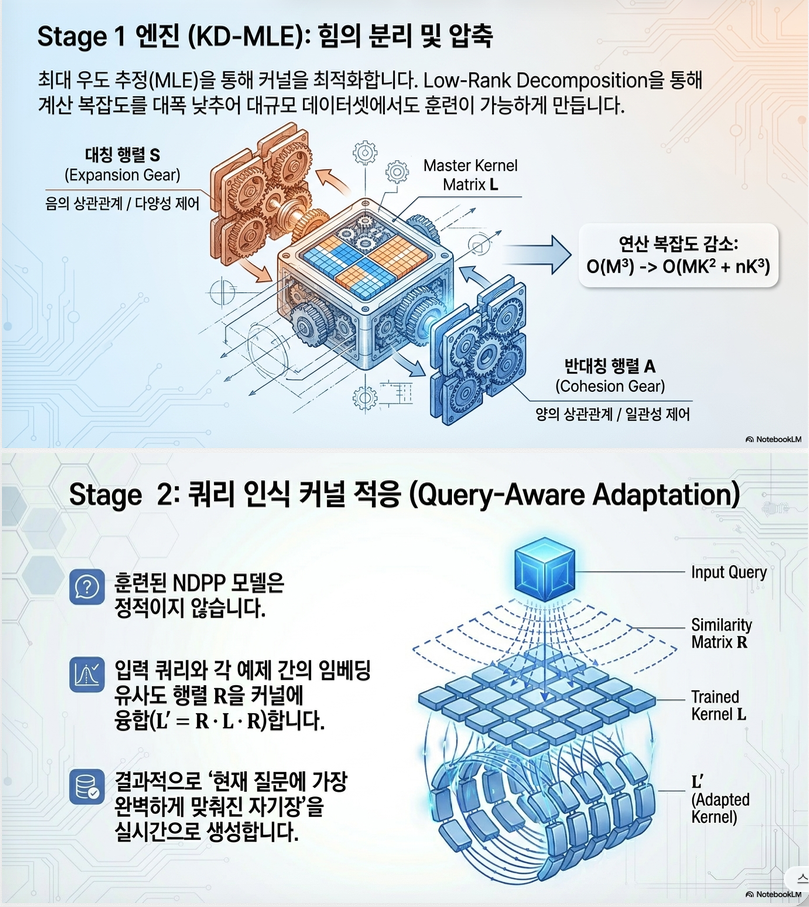
7. Kernel Decomposition
이 논문의 가장 중요한 수식.
저자들은
L=S+A
로 분해한다.
7.1 Symmetric Part
대칭행렬
논문 해석:
S는
negative correlation
을 담당한다.
즉 diversity.
7.2 Skew-Symmetric Part
A는 positive correlation을 담당.
즉 consistency.
결과적으로
L=S+A
는
- 다양성
- 일관성
동시 모델링 가능.
8. Low-rank NDPP
원래 kernel 크기:
(M = example pool size)
저자들은
로 low-rank 표현.
복잡도 감소:
원래
↓
대규모 example pool에서도 학습 가능.
9. Regularized Likelihood
과적합 방지:
최종 objective:
최적화.
10. Query-Aware Kernel Adaptation
지금까지 학습된 NDPP는
query-independent.
그러나 실제 ICL은
query별 다른 example 필요.
Similarity 계산
Diagonal Matrix
Kernel Adaptation
핵심:
즉, query와 비슷한 example은 kernel에서 중요도가 커진다.
11. MAP Inference
최종 example set 선택.
목표:
의미:
- query relevance
- diversity
- consistency
모두 고려한 subset 선택.
하지만 NP-hard.
그래서
Fast Greedy MAP
(Chen et al., NeurIPS 2018 계열)
사용.
반복적으로
가 가장 큰 example 추가.
12. CEIL과의 차이
CEIL(ICML 2023)과 비교하면:
| 항목 | CEIL | NDPP |
|---|---|---|
| Query relevance | O | O |
| Diversity | O | O |
| Example consistency | X | O |
| Positive correlation | X | O |
| Negative correlation | O | O |
| 모델 | DPP | NDPP |
CEIL:
NDPP:
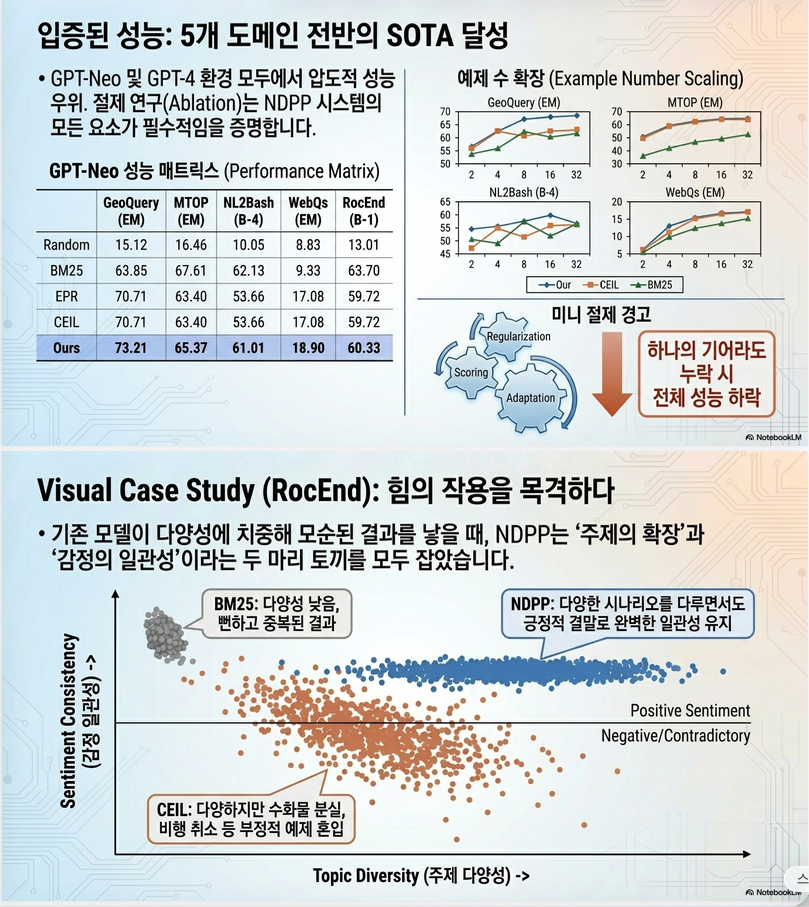
13. 실험 결과
GPT-Neo(2.7B), GPT-4, Gemini-2.0-flash에서 평가.
주요 결과:
- 모든 데이터셋에서 CEIL보다 우수
- GPT-4에서도 개선
- Ablation에서
- LLM scoring 제거 → 성능 감소
- Regularization 제거 → 감소
- Query adaptation 제거 → 감소
연구 관점에서의 평가
이 논문의 핵심 아이디어는 매우 명확합니다.
기존 DPP 계열(ICL-DPP, CEIL)의 가정은
“좋은 demonstration set = diverse set”
이었는데,
이 논문은
“좋은 demonstration set = diverse + consistent”
라고 주장합니다.
이를 위해 DPP를 NDPP로 확장하여 positive correlation을 직접 모델링했다는 점이 가장 큰 기여입니다. DPP 기반 example selection 연구 흐름에서 보면,
- CEIL (ICML 2023)
- Effective Demonstration Annotation via LM-based DPP (EMNLP 2024)
- NDPP (EMNLP 2025)
로 이어지는 자연스러운 발전 방향으로 볼 수 있습니다.
답글 남기기