
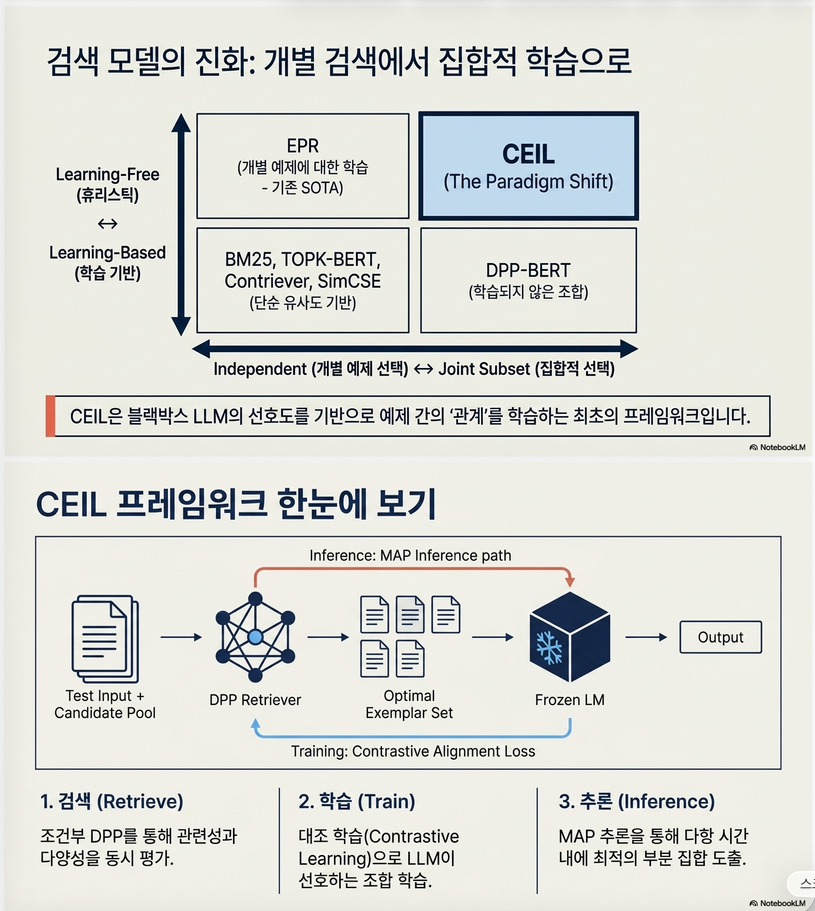


이 논문은 **ICL(In-Context Learning)에서 어떤 예제(demonstration)를 선택할 것인가?**라는 문제를 다룹니다.
핵심 아이디어는 매우 간단합니다.
기존 방법은 “좋은 예제를 하나씩” 찾는다.
CEIL은 “좋은 예제 집합(set)“을 찾는다.
이를 위해 Determinantal Point Process (DPP) 를 활용하여
예제들 간의 다양성(diversity) 과 입력과의 관련성(relevance) 을 동시에 고려합니다.
1. 연구 배경
ICL에서는 다음과 같은 형태로 추론합니다.
Example 1
Input -> Output
Example 2
Input -> Output
...
Test Input
Output ?GPT-3 이후 알려진 사실은
- 어떤 demonstration을 넣느냐에 따라
- 성능이 랜덤 수준에서 SOTA 수준까지 변한다
는 것입니다.
따라서 많은 연구들이
형태로
“현재 입력 x와 가장 유사한 예제 를 찾자”
라는 접근을 사용했습니다.
대표적으로
- BM25
- SBERT
- Contriever
- EPR
등이 있습니다.
하지만 문제는
예제 간 상호작용을 무시
예를 들어
Example A : positive movie review
Example B : another positive movie review처럼 거의 같은 예제 2개를 선택하면
실제로는 정보량이 증가하지 않습니다.
즉
입니다.
CEIL은 바로 이 문제를 해결하려고 합니다.
2. 핵심 아이디어
기존:
↓
CEIL: P(S|x)
여기서 는 예제 집합입니다.
즉, “좋은 예제를 찾는 문제”가 아니라, “좋은 예제 조합을 찾는 문제”로 재정의합니다.
3. 왜 DPP인가?
DPP는 원래
- 추천 시스템
- 문서 요약
- 비디오 요약
에서 사용된 다양성 기반 subset selection 모델입니다.
DPP의 확률은
입니다.
여기서 입니다.
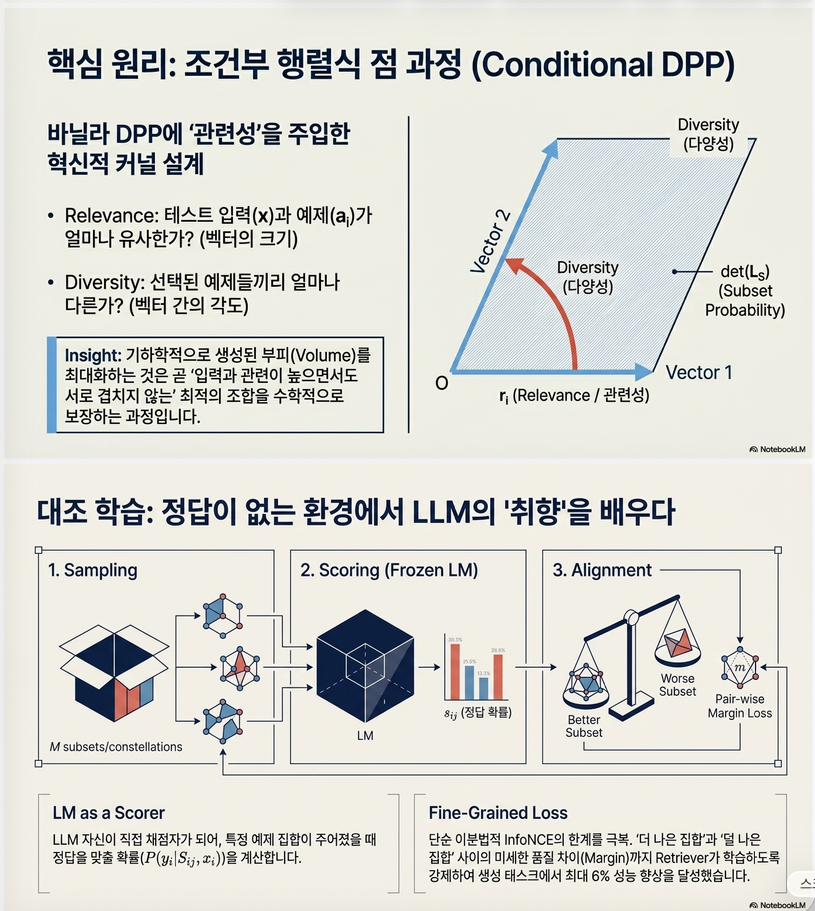
DPP의 직관
Quality
벡터 길이가 크면
→ 선택될 확률 증가
Diversity
벡터가 서로 비슷하면
가 작아짐
→ 같이 선택될 확률 감소
즉, DPP는 자동으로
좋은 예제 + 서로 다른 예제를 선호합니다.
4. CEIL의 Conditional DPP
기존 DPP는
예제들끼리의 관계만 고려합니다.
하지만 ICL에서는
현재 테스트 입력과의 관련성도 중요합니다.
그래서 논문은
를 제안합니다.
여기서
- : input과 example의 relevance
- : example 간 similarity
입니다.
결과적으로
로 분해됩니다.
첫 번째 항 → Relevance
두 번째 항 → Diversity
입니다.
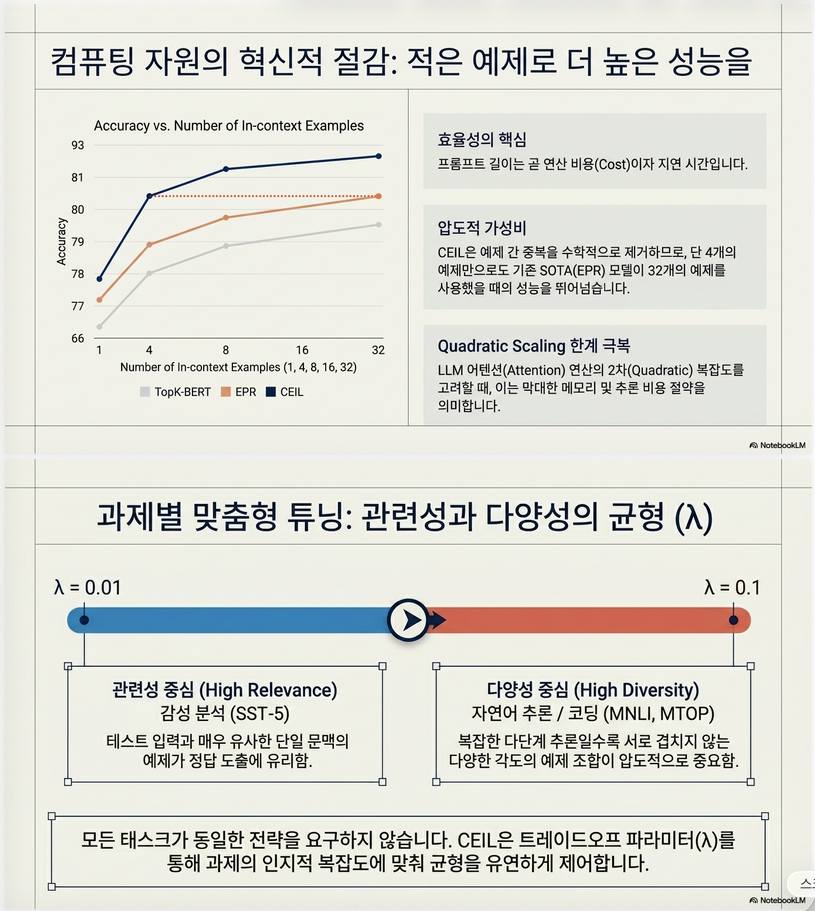
5. Diversity-Relevance Tradeoff
논문은 추가로 를 도입합니다.
λ가 작을 때
relevance 강조
query와 비슷한 예제λ가 클 때
diversity 강조
서로 다른 예제 조합논문 실험에서는
- Sentiment → relevance 중요
- NLI → diversity 중요
라는 결과가 나옵니다.
6. 학습 방법
문제: 정답 exemplar set이 존재하지 않습니다.
Training data 생성
각 training sample에 대해
- Top-100 유사 예제 검색
- 여러 subset 생성
- LM으로 평가
즉, “이 subset이 정답 생성에 얼마나 도움이 되는가”를 LM 자체로 측정합니다.
Contrastive Learning
좋은 subset
나쁜 subset 를 만들고
좋은 subset의 DPP score가 더 높도록 학습합니다.
논문은 InfoNCE 대신 Pairwise Margin Loss를 사용합니다.
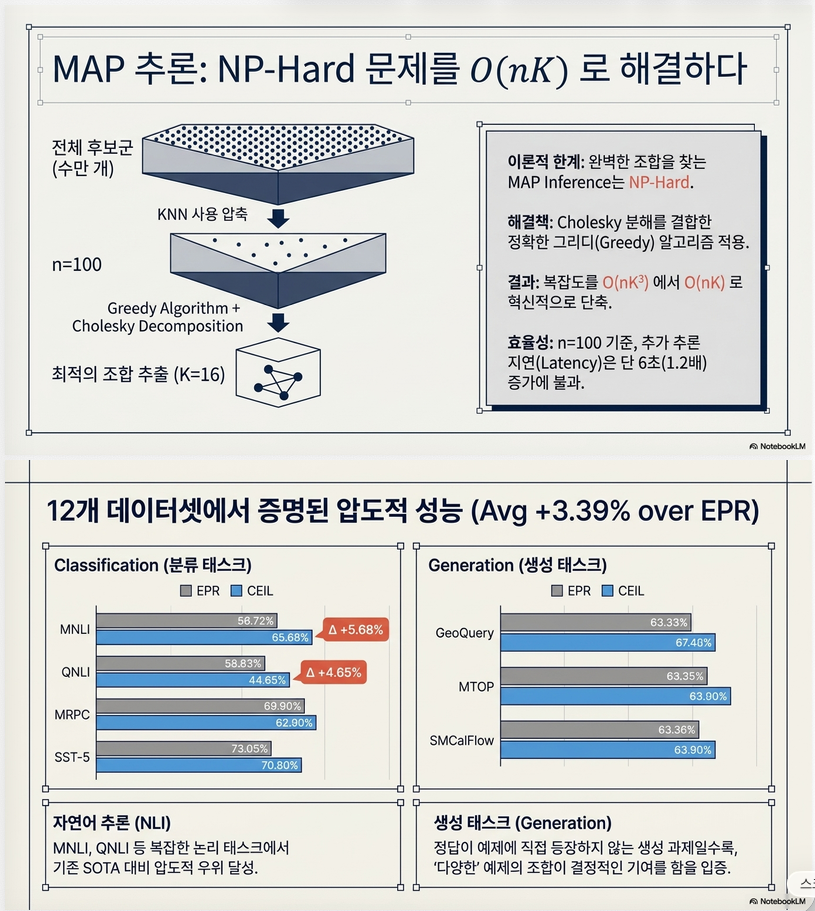
7. Inference
추론 시에는 Top-K retrieval 대신
DPP MAP inference 수행
실제로는
- Top-100 후보 검색
- DPP greedy MAP
을 수행합니다.
사용된 알고리즘은
Lianjie Chen의 Fast Greedy MAP 알고리즘입니다.
8. 주요 실험 결과
12개 데이터셋
7개 NLP task 평가
결과:
| Method | Avg |
|---|---|
| EPR | 53.37 |
| CEIL | 56.76 |
평균 +3.39%p 향상
특히 NLI에서 매우 큼
| Dataset | EPR | CEIL |
|---|---|---|
| QNLI | 80.76 | 85.41 |
| MNLI | 66.06 | 71.74 |
약 5%p 향상
9. 왜 NLI에서 잘 될까?
NLI는
Premise
Hypothesis사이의 관계를 추론해야 합니다.
단순히 유사한 예제를 반복적으로 보여주는 것보다
Entailment 예시
Neutral 예시
Contradiction 예시등 다양한 reasoning pattern을 제공하는 것이 중요합니다.
DPP가 이러한 다양성을 자연스럽게 확보해줍니다.
논문도 NLI에서 가장 큰 성능 향상을 보고합니다.
10. Transferability
흥미로운 결과입니다.
GPT-Neo로 학습한 retriever를
- GPT2-XL
- Codex
에 그대로 적용해도 성능 향상이 유지됩니다.
즉, CEIL이 특정 LM이 아니라
“좋은 demonstration 구성 원리”
를 학습한 것으로 해석할 수 있습니다.
11. 논문의 의의
이 논문의 가장 큰 기여는
ICL example selection을 에서
문제로 바꾼 것입니다.
MMR, mRMR, DPP 관점에서 보면
사용자께서 앞서 질문하신 DPP 관점에서 보면
| 방법 | 목적 |
|---|---|
| Similarity Search | relevance만 고려 |
| MMR | relevance + redundancy penalty |
| mRMR | relevance + redundancy penalty |
| CEIL | relevance + diversity를 확률적으로 전역 최적화 |
입니다.
실제로 CEIL의 objective는
형태이므로
MMR/mRMR의 집합 최적화 버전으로 볼 수 있습니다.
RAG/ICL 연구 관점에서의 영향
이 논문은 이후 다음 계열 연구들의 직접적인 출발점이 되었습니다.
- DPP 기반 ICL Example Selection
- Diversity-aware ICL
- Coverage-aware ICL
- Retrieval-Augmented ICL
- Context Compression에서 DPP 활용
- RAG reranking 및 subset selection
특히 사용자가 관심 있는
- In-Context Learning Example Selection
- Context Compression
- RAG Context Selection
분야에서 DPP를 본격적으로 적용한 대표 논문 중 하나로 평가됩니다.
CEIL 방법론 상세 설명
CEIL의 핵심은 다음 세 단계입니다.
- Conditional DPP로 exemplar set 모델링
- LM 점수를 이용한 Contrastive Learning
- DPP-MAP으로 최적 exemplar subset 추론
전체 흐름은 다음과 같습니다. (논문 Figure 1)
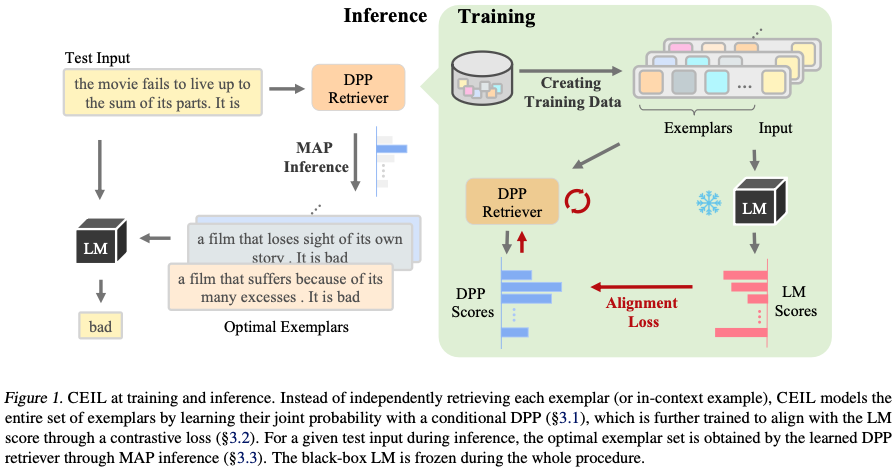
Training
Input x
↓
후보 exemplar subset 생성
↓
LM으로 subset 품질 평가
↓
Conditional DPP 학습
↓
Contrastive Loss
Inference
Test Input
↓
Conditional DPP
↓
MAP Inference
↓
Optimal Exemplar Set
↓
LLM Inference1. 문제 정의
기존 ICL Retrieval:
즉, “입력 x와 가장 비슷한 exemplar 하나” 를 찾음
CEIL: P(S|x)
여기서
즉, “좋은 exemplar 집합” 전체를 선택함.
2. Conditional DPP
Step 1. Example Embedding
각 exemplar 를 encoder로 embedding 로 변환
테스트 입력 x 도 encoder로 embedding 로 변환
논문에서는 BERT encoder 사용
- input encoder
- exemplar encoder
2개를 사용함.
Step 2. Similarity 정의
예제간 similarity:
논문에서는 단순 dot product 사용
입력-예제 relevance:
역시 dot product 사용
Step 3. Conditional Kernel
일반 DPP
CEIL
행렬 형태
여기서
의미
relevance × diversity × relevance3. DPP Score
subset S 의 점수는
여기서
첫 번째 항 → relevance
두 번째 항 → diversity
즉, CEIL은 자동으로 “입력과 관련 있으면서 서로 다른 예제들”을 선호함
4. Trade-off λ
논문은 relevance/diversity 비율을 조절하기 위해 도입
λ가 작으면
Relevance ↑
Diversity ↓λ가 크면
Relevance ↓
Diversity ↑실험 결과
- SST5 → 작은 λ
- NLI, Semantic Parsing → 큰 λ
가 좋았음.
5. Training Data 생성
가장 중요한 부분
문제:
정답 exemplar subset이 없음
그래서 논문은 LM 자체를 teacher로 사용
후보 생성
훈련 샘플 에 대해
Stage 1
Top-100 retrieval
Input
↓
Top-100 nearest examplesStage 2
random subset 생성
예를 들어
S1 = {e3,e7,e9,...}
S2 = {e1,e8,e21,...}
...
S5050개 생성
각 subset 크기: |S|=16
6. LM Scoring
각 subset을 GPT-Neo에 넣음
점수:
의미:
이 subset이 정답 생성에 얼마나 도움되는가?예시
Subset A
LM score = 0.8
Subset B
LM score = 0.4그러면 A가 B보다 좋은 subset
7. Contrastive Learning
이제
좋은 subset
나쁜 subset
을 구할 수 있음
목표:
되도록 학습
논문은 Pairwise Margin Loss 사용
즉, 좋은 subset의 DPP score가 나쁜 subset보다 충분히 크도록 encoder를 학습
8. 왜 EPR Initialization을 쓰나?
논문의 중요한 trick
처음부터 BERT로 학습
↓
성능 안 좋음
EPR retriever로 초기화
↓
성능 크게 향상
(Table 5)
이유
EPR은 이미 좋은 exemplar 하나를 찾는 방법을 배웠음
CEIL은 그 위에서 좋은 exemplar 집합을 배우는 형태
9. Inference
실제 추론
Step 1
Top-100 후보 검색
축소
논문 n=100 사용
Step 2
MAP Inference
목표
10. Fast Greedy MAP
DPP MAP는 원래 NP-hard
논문은 Chen et al. (NeurIPS 2018) Fast Greedy MAP 사용
매 단계
선택
여기서
직관:
현재 subset에 추가했을 때, 가장 정보량이 증가하는 exemplar 선택복잡도:
(Cholesky update 사용 시 더 감소)
연구 관점에서 중요한 해석
사용자께서 관심 있는
- DPP
- MMR
- mRMR
- ICL Example Selection
관점에서 보면
CEIL은 사실상
를
학습 가능한 형태로 만든 DPP-based Set Retrieval Framework
입니다.
특히 이후의
- Diverse Demonstration Selection
- Coverage-aware ICL
- Retrieval-Augmented ICL
- DPP-based RAG Context Selection
연구들의 기반이 되었고,
사용자 연구 분야인 ICL Example Selection에서는 CEIL이 사실상 최초의 본격적인 Learning-based DPP Retriever로 볼 수 있습니다.
이 논문에서 DPP가 사용되는 곳은?
이 논문에서 DPP는 학습(training) 과 추론(inference) 두 곳 모두에서 사용되지만, 역할이 약간 다릅니다.
한 줄 요약
DPP는 단순히 diversity 측정을 위한 regularizer가 아니라,
“Exemplar Set 자체의 확률 모델”
로 사용됩니다.
전체 구조에서 DPP 위치
Training
Input
↓
BERT Encoder
↓
DPP Score 계산
↓
LM Score와 비교
↓
Contrastive Learning
Inference
Input
↓
BERT Encoder
↓
DPP MAP Inference
↓
최적 Exemplar Set즉 DPP는
- 학습 시: subset scoring model
- 추론 시: subset selection algorithm
으로 사용됩니다.
1. Training에서 DPP
논문은 먼저 여러 exemplar subset을 생성합니다.
예를 들어
S1 = {e1,e3,e7,e9}
S2 = {e2,e5,e8,e10}
S3 = {e4,e6,e11,e13}각 subset에 대해
LM score 계산
동시에 DPP score 계산
좋은 subset은
LM score 높음나쁜 subset은
LM score 낮음DPP가 LM의 선호도를 따라가도록 학습
만족시키게 됨.
즉 여기서 DPP 역할은
Subset Scoring Function입니다.
DPP가 계산하는 점수
논문에서는
를 정의하고
subset score를
로 계산합니다.
실제로는
여기서
첫 번째 항
relevance
두 번째 항
diversity
즉 DPP가
Relevant + Diversesubset에 높은 점수를 부여합니다.
2. Inference에서 DPP
이 부분이 사실 CEIL의 핵심입니다.
기존 EPR
Top-K retrievalCEIL
DPP-MAP목표는
즉, 후보 100개 중 가장 좋은 조합을 찾는 것입니다.
예를 들어
Query:
Premise: dog running
Hypothesis: animal moving후보
A dog example
B dog example
C animal example
D motion exampleTop-K
A
B
C선택
(중복)
DPP
A
C
D선택
(coverage 확보)
그래서 DPP는 inference 단계에서
Subset Search Engine역할을 합니다.
DPP가 실제 사용하는 정보
Kernel
Relevance
DPP Score
determinant의 의미는
선택된 exemplar embedding들이 만드는
평행다면체(parallelepiped)의 부피입니다.
예를 들어
e1=(1,0)
e2=(0,1)이면
반면
e1=(1,0)
e2=(0.99,0.01)이면
즉, 거의 같은 예제는 자동으로 배제됩니다.
MMR와 비교
사실 DPP 관점에서는
CEIL의 DPP가 하는 일은
MMR의 전역 최적화 버전이라고 볼 수 있습니다.
MMR
CEIL
차이점은
MMR
하나씩 greedy 선택DPP
subset 전체를 평가입니다.
답글 남기기