



논문 개요
이 논문은 ICL(In-Context Learning)에서 exemplar 선택 문제를 단순히 “정확도를 높이는 문제”가 아니라, 정확도와 calibration을 동시에 최적화하는 multi-objective combinatorial optimization 문제로 재정의합니다. 제안 방법은 COM-BOM으로, 전체 이름은 Combinatorial Bayesian Optimization of Multiple ICL Metrics입니다.
핵심 아이디어는 다음과 같습니다.
좋은 exemplar set은 단순히 정답률이 높은 것만으로는 부족하고,
모델이 자신의 정답 가능성에 대해 얼마나 잘 calibrated되어 있는지도 함께 고려해야 한다.
즉, 목표는 다음 두 가지입니다.
- Accuracy 최대화
- ECE(Expected Calibration Error) 최소화
이를 위해 Pareto frontier를 탐색합니다.
1. 문제 정의: Exemplar Selection을 Multi-objective Optimization으로 formulatation
후보 exemplar pool을 다음과 같이 둡니다.
각 exemplar를 prompt에 포함할지 여부를 binary vector로 표현합니다.
여기서 이면 exemplar 를 포함하고, 이면 제외합니다.
논문의 최적화 문제는 다음과 같습니다.
즉, accuracy는 maximize하고, ECE는 minimize해야 하므로 를 maximize하는 형태로 바꿉니다.
2. Accuracy와 Calibration 평가 방법
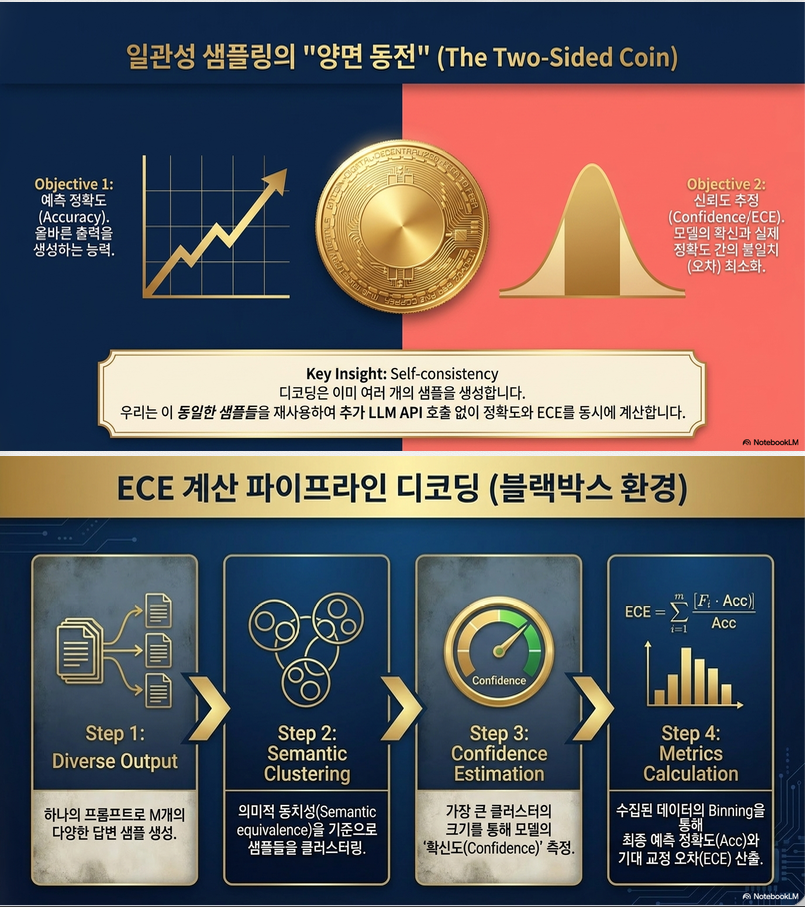
논문의 중요한 특징은 black-box LLM API 환경에서도 accuracy와 calibration을 평가할 수 있도록 설계했다는 점입니다.
2.1 하나의 query에 대해 multiple samples 생성
validation set의 각 입력 x에 대해 exemplar set z를 포함한 prompt를 만들고, LLM으로부터 M개의 답변을 샘플링합니다.
논문 실험에서는 M=16을 사용합니다.
2.2 Semantic clustering
생성된 답변들을 의미적으로 같은 답변끼리 clustering합니다.
예를 들어 lexical form은 달라도 의미가 같으면 같은 cluster로 묶습니다.
가장 큰 cluster를 모델의 최종 예측으로 사용합니다.
즉, self-consistency decoding과 유사하게 가장 많이 나온 의미적 답변을 final answer로 사용합니다.
2.3 Confidence estimation
모델의 confidence는 가장 큰 semantic cluster의 비율로 정의합니다.
예를 들어 16개 샘플 중 12개가 같은 의미의 답변이면 confidence는 0.75입니다.
이 방식의 장점은 별도의 logit access 없이도 black-box LLM에서 confidence를 추정할 수 있다는 점입니다.
2.4 Accuracy 계산
각 validation instance에 대해 예측 답변이 gold label과 일치하면 1, 아니면 0입니다.
전체 accuracy는 validation set 평균입니다.
2.5 ECE 계산
ECE는 confidence와 실제 accuracy의 차이를 bin 단위로 측정합니다.
confidence 구간 [0,1]을 K개 bin으로 나누고, 각 bin 에 대해 평균 confidence와 평균 accuracy를 계산합니다.
ECE가 낮을수록 모델의 confidence가 실제 정답률과 잘 맞는다는 뜻입니다.
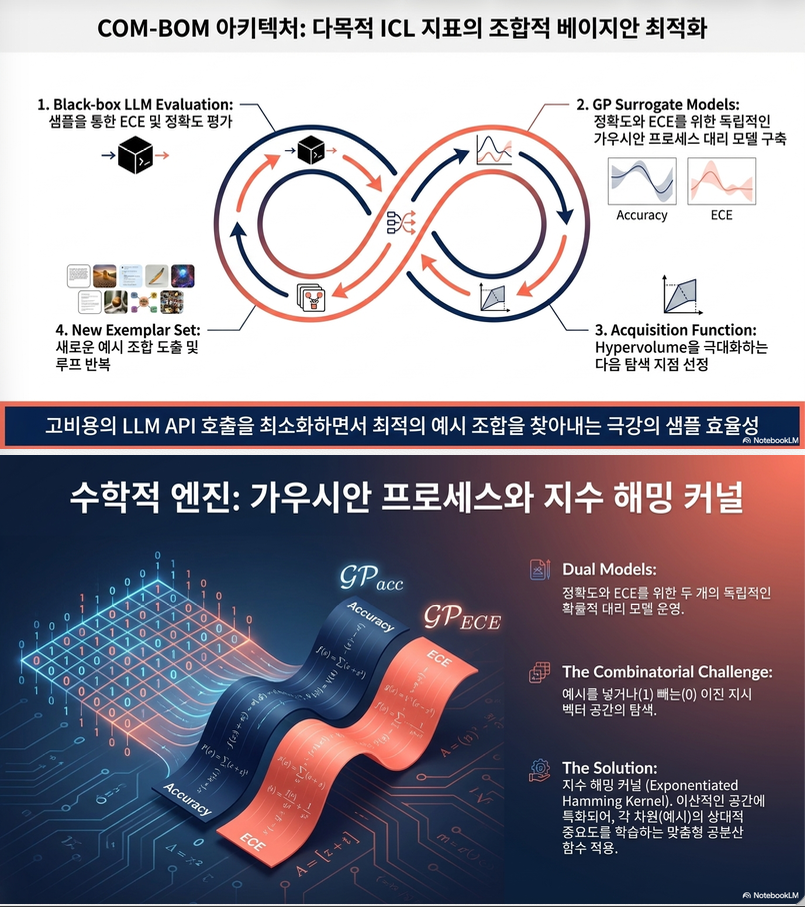
3. COM-BOM 방법론
COM-BOM은 exemplar 선택을 위한 multi-objective Bayesian optimization입니다.
전체 loop는 다음과 같습니다.
- 초기 exemplar subset z들을 random sampling
- 각 subset에 대해 LLM evaluation 수행
- Accuracy와 ECE 계산
- 두 objective에 대해 Gaussian Process surrogate model 학습
- acquisition function으로 다음 평가할 exemplar subset 선택
- Pareto frontier 업데이트
- budget이 끝날 때까지 반복
4. Gaussian Process Surrogate Model
COM-BOM은 두 개의 독립적인 GP를 사용합니다.
여기서 z는 binary vector이므로 일반적인 RBF kernel 대신 Exponentiated Hamming Kernel을 사용합니다.
즉, 두 exemplar subset이 얼마나 다른지를 Hamming distance로 측정합니다.
는 exemplar dimension별 lengthscale이며, 어떤 exemplar가 objective에 더 중요한지 GP가 학습할 수 있게 합니다.
5. Acquisition Function: NEHVI
COM-BOM은 multi-objective acquisition function으로 Noisy Expected Hypervolume Improvement, NEHVI를 사용합니다.
기본 아이디어는 다음과 같습니다.
다음에 평가할 exemplar set은 현재 Pareto frontier의 hypervolume을 가장 많이 확장할 것으로 기대되는 점이어야 한다.
Pareto frontier의 hypervolume은 accuracy-ECE objective space에서 좋은 solution들이 지배하는 영역의 크기입니다.
EHVI는 다음 candidate z를 평가했을 때 기대되는 hypervolume 증가량입니다.
논문에서는 실제 LLM evaluation이 noisy하므로 EHVI 대신 NEHVI를 사용합니다.
6. Acquisition Optimization: Greedy Hill-Climbing
Exemplar subset search space는 이므로 조합공간입니다.
논문은 acquisition function을 최적화하기 위해 trust-region 기반 greedy hill-climbing을 사용합니다.
절차는 다음과 같습니다.
- 현재 Pareto set 중 hypervolume contribution이 큰 point를 center로 선택
- 그 주변의 Hamming ball을 trust region으로 정의
- bit flip을 통해 local search 수행
- acquisition value가 좋아지는 방향으로 이동
- multiple random restarts 사용
즉, 전체 조합공간을 무작정 탐색하지 않고, 현재 좋은 solution 주변을 효율적으로 탐색합니다.
7. 실험 설정
논문은 MMLU-Pro의 여러 domain에서 실험합니다.
사용 모델:
- Qwen3-8B
- LLaMA-3.3-70B-Instruct
주요 설정:
| 항목 | 값 |
|---|---|
| 후보 exemplar 수 | 32 |
| 샘플 수 | 16 |
| temperature | 0.7 |
| top-p | 0.8 |
| top-k | 20 |
| BO initial points | 20 |
| evaluation budget | 200 iterations |
| acquisition | qNEHVI |
비교 방법:
- No exemplars
- All exemplars
- Nearest retrieval
- Diversity retrieval
- Random Search
- Genetic Algorithm
- Simulated Annealing
- Hill Climbing
- COM-BOM
8. 주요 결과
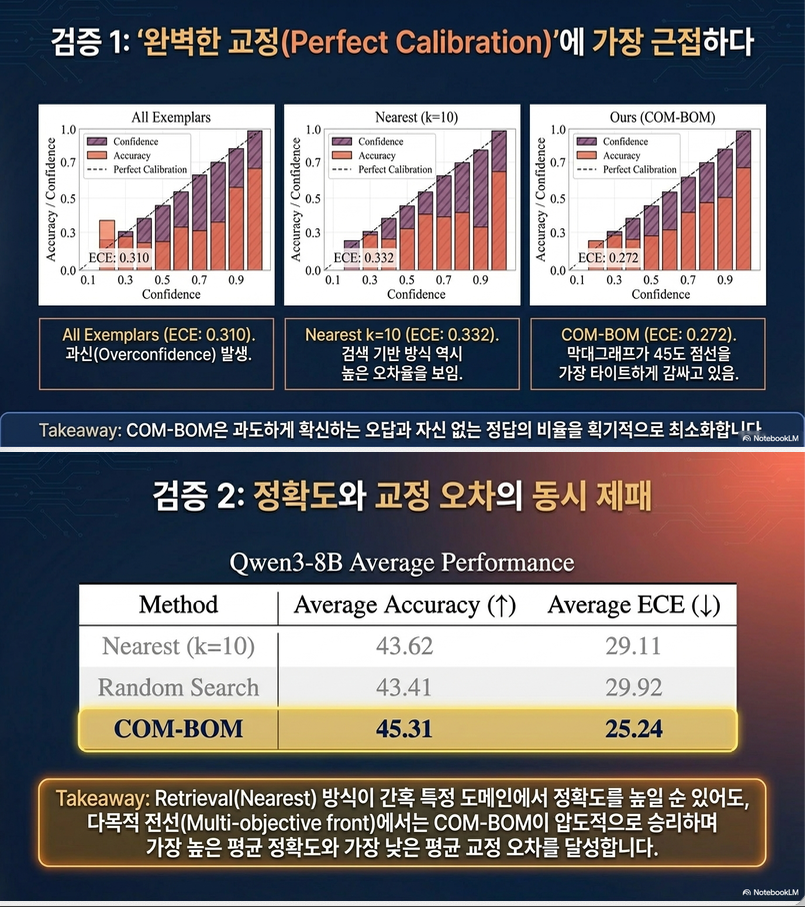
Qwen3-8B 기준 평균 결과는 다음과 같습니다.
| 방법 | Accuracy | ECE |
|---|---|---|
| No Exemplars | 43.48 | 31.73 |
| All Exemplars | 44.55 | 28.06 |
| Nearest | 43.62 | 29.11 |
| Diversity | 43.32 | 30.87 |
| COM-BOM | 45.31 | 25.24 |
즉, COM-BOM은 평균적으로 accuracy도 가장 높고, ECE도 가장 낮습니다.
Optimization-based baseline과 비교해도 COM-BOM이 가장 좋은 평균 성능을 보입니다.
| 방법 | Accuracy | ECE |
|---|---|---|
| Genetic Algorithm | 43.36 | 27.98 |
| Simulated Annealing | 43.26 | 28.02 |
| Random Search | 43.41 | 29.92 |
| Hill Climbing | 44.24 | 27.73 |
| COM-BOM | 45.31 | 25.24 |
9. 논문의 핵심 주장
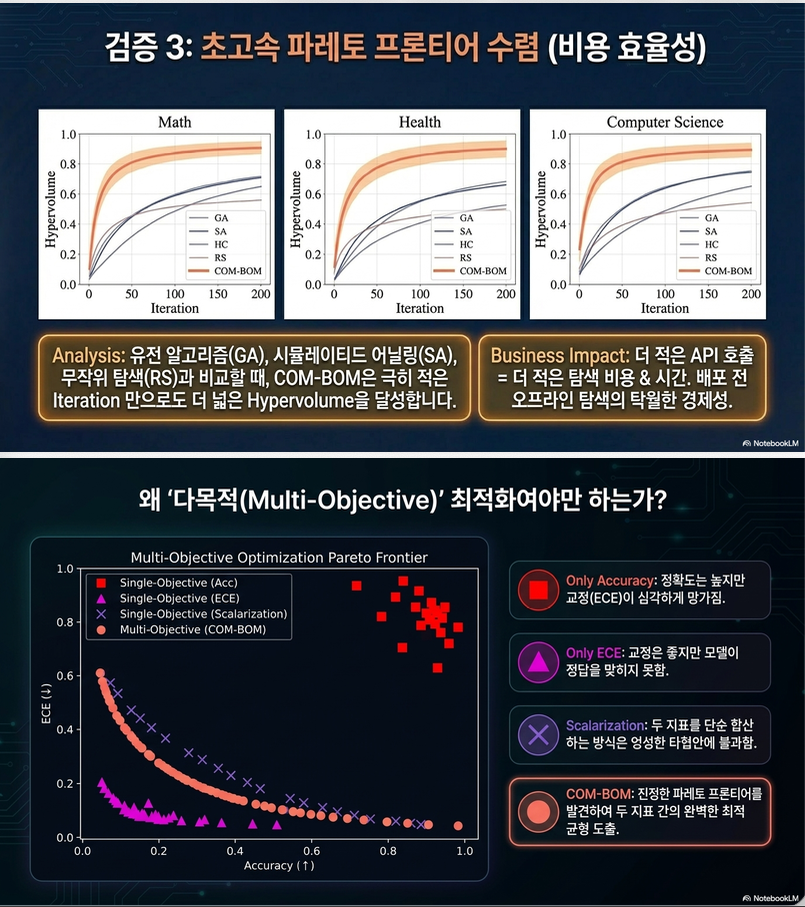
이 논문의 핵심 주장은 세 가지입니다.
- Exemplar selection은 accuracy-only 문제가 아니다.
Calibration을 함께 고려해야 trustworthy ICL이 가능하다. - Accuracy와 ECE는 trade-off 관계에 있을 수 있다.
Accuracy만 최적화하면 calibration이 나빠질 수 있다. - COM-BOM은 Pareto frontier를 직접 탐색하기 때문에 scalarization baseline보다 효율적이다.
특히 hypervolume 기반 acquisition을 사용해 accuracy-calibration trade-off를 더 잘 탐색한다.
10. 한계점
논문이 인정한 한계는 다음과 같습니다.
- 후보 exemplar pool이 32개로 비교적 작음
- BO는 차원이 커질수록 scalability 문제가 있음
- 실험이 영어 multiple-choice QA 중심
- open-ended generation, code generation 등에는 별도 accuracy/confidence metric이 필요함
- exemplar 순서 최적화는 다루지 않음
정리
이 논문은 ICL exemplar selection을 accuracy-calibration Pareto optimization 문제로 재정의하고, 이를 해결하기 위해 combinatorial multi-objective Bayesian optimization 방법인 COM-BOM을 제안합니다.
방법론적으로는 다음 조합이 핵심입니다.
결과적으로 COM-BOM은 기존 retrieval, random search, GA, SA, hill climbing보다 더 좋은 accuracy-ECE trade-off를 찾으며, 특히 calibration 측면에서 강한 성능을 보입니다.
이 논문의 방법론에서 가장 중요한 부분은 사실상
(1) NEHVI(Noisy Expected Hypervolume Improvement)
(2) Acquisition Optimization with Greedy Hill-Climbing
입니다.
BO(Bayesian Optimization)를 잘 모르면 이 부분이 상당히 어렵게 느껴질 수 있는데, ICL exemplar selection 관점에서 설명하면 훨씬 이해하기 쉽습니다.
1. 왜 Hypervolume이 필요한가?
논문의 목표는
를 동시에 최적화하는 것입니다.
예를 들어 현재까지 발견한 exemplar set들이 아래와 같다고 가정합시다.
| Exemplar Set | Accuracy | ECE |
|---|---|---|
| A | 0.80 | 0.20 |
| B | 0.85 | 0.25 |
| C | 0.75 | 0.10 |
어느 것이 최고일까요?
정답은 없습니다.
- A는 calibration 좋음
- B는 accuracy 좋음
- C는 calibration 매우 좋음
따라서 단일 최적해가 아니라, 를 찾아야 합니다.
2. Pareto Front
Pareto optimal solution은
다른 모든 objective에서 동시에 더 좋은 해가 존재하지 않는 해입니다.
예를 들어
| Accuracy | ECE |
|---|---|
| 0.85 | 0.25 |
| 0.82 | 0.18 |
| 0.75 | 0.10 |
세 점 모두 Pareto front에 있을 수 있습니다.
논문의 목표는
를 찾는 것입니다.
3. Hypervolume이란?
Pareto front의 품질을 평가하기 위해 Hypervolume(HV)을 사용합니다.
논문에서는 reference point를 근처로 둡니다.
직관
Accuracy ↑
ECE ↓
방향이 좋습니다.
Pareto front가 차지하는 면적을 계산합니다.
ECE
↑
|
|
| *
| *
| *
+------------------> AccuracyPareto front가 오른쪽 아래로 갈수록
- accuracy 증가
- ECE 감소
따라서 hypervolume 증가
즉, HV(P)가 크면 좋은 Pareto frontier입니다.
4. Expected Hypervolume Improvement (EHVI)
BO에서는 항상 질문이 같습니다.
다음 evaluation을 어디서 할까?
exemplar subset 후보 z가 있다고 합시다.
GP가 예측하는 값은
입니다.
만약 z를 실제 평가하면,
현재 Pareto front가 커질 수도 있고
안 커질 수도 있습니다.
따라서 의 기대값을 계산합니다.
논문 식 (6)
의미는
“z를 평가했을 때 Pareto front가 얼마나 확장될 것으로 기대되는가?”
입니다.
5. 왜 EHVI가 좋은가?
기존 scalarization은
예를 들어, Score = 0.7Acc - 0.3ECE 같이 합칩니다.
그러면 Pareto frontier 전체를 찾지 못합니다.
예시
A:
(0.9,0.3)
B:
(0.8,0.1)
둘 다 좋은 해인데, scalarization은 하나만 선호합니다.
EHVI는
Pareto frontier 전체를 고려합니다.
따라서, 조합이 현재 Multi-objective BO의 표준입니다.
6. Noisy EHVI (NEHVI)
문제는 논문의 objective가 noisy하다는 것입니다.
Accuracy 계산: 16개의 sample 생성
ECE 계산: semantic clustering 수행
temperature=0.7
sampling 존재
따라서 같은 exemplar set을 평가해도 f(z) 값이 조금씩 달라집니다.
EHVI는 원래 f(z)를 deterministic하다고 가정합니다.
하지만 LLM은 noisy합니다.
그래서 논문은 NEHVI(Noisy EHVI)를 사용합니다.
개념적으로 p(f(z)|D) 전체에 대해 적분합니다.
즉, “평균적으로 얼마나 Pareto front가 좋아질까?”를 계산합니다.
7. Acquisition Optimization 문제
이제 acquisition function이 생겼습니다.
하지만 새로운 문제가 있습니다.
z는 입니다.
논문 설정:
m=32
exemplar 후보 32개
탐색 공간
개
모든 후보의 acquisition을 계산하는 것은 불가능합니다.
그래서 Acquisition Optimization이 필요합니다.
8. Greedy Hill-Climbing
논문은 Trust-region + Greedy Hill-Climbing을 사용합니다.
Step 1
현재 Pareto front에서
hypervolume contribution이 가장 큰 점 선택
즉, “현재 가장 좋은 exemplar subset” 근처를 탐색
Step 2
Trust Region 생성
Hamming distance 기준
예:
101101100...가 center면1~2 bit 정도 바꾼 이웃만 탐색
9. Hill Climbing
이웃 exemplar set 생성
예:
101101100↓
101001100(한 exemplar 제거)
각 이웃의 acquisition 계산
가장 큰 acquisition을 선택
반복:
더 이상 개선이 없으면 종료
10. 왜 Trust Region이 필요한가?
BO에서 GP surrogate는 관측된 영역 근처에서 신뢰도가 높습니다.
멀리 가면 uncertainty만 커집니다.
따라서, 근처에서 탐색하는 것이 더 안정적입니다.
논문 ablation에서도 Trust Region 제거 시 성능이 떨어집니다.
11. COM-BOM 전체 흐름
최종적으로는
Random exemplar subsets
↓
LLM evaluation
↓
Accuracy
ECE 계산
↓
GP_acc
GP_ECE 학습
↓
NEHVI 계산
↓
Greedy Hill-Climbing
↓
다음 exemplar subset 선택
↓
LLM 평가
↓
Pareto frontier 업데이트
↓
반복기존 NLP 연구자 관점에서의 의미
이 논문은 본질적으로
DPP 기반 exemplar selection
(EMNLP 2024, 2025)
↓
BO 기반 exemplar selection
(BRIDGE, ICLR 2025)
↓
Multi-objective BO exemplar selection
으로 발전한 연구라고 볼 수 있습니다.
특히 차별점은
- Accuracy만 최적화하지 않음
- Calibration(ECE)을 함께 최적화
- Scalarization 대신 NEHVI 사용
- Pareto frontier 전체를 탐색
이라는 점입니다.
따라서 방법론적으로는 최근 AutoPrompt/Exemplar Optimization 계열에서 사용되는 **Combinatorial Bayesian Optimization + Multi-objective BO(qNEHVI)**를 ICL exemplar selection에 적용한 논문으로 이해하면 됩니다.
답글 남기기