[카테고리:] Prompt Selection
-

** Searching for Optimal Solutions with LLMs via Bayesian Optimization (ICLR 2025)
1. 문제의식: LLM 기반 “탐색”의 한계 최근 LLM을 테스트 타임에서 여러 번 샘플링하여 더 나은 해를 찾는 방식(test-time compute scaling)이 주목받고 있습니다. 하지만 기존 방식들은 다음 한계를 가집니다: 접근 한계 Repeated Sampling 탐색 공간 구조를 고려하지 않음 Greedy OPRO exploitation 위주 → local optima에 갇힘 진화 알고리즘 비용 큼 / 정적 전략 난이도 예측 기반…
-
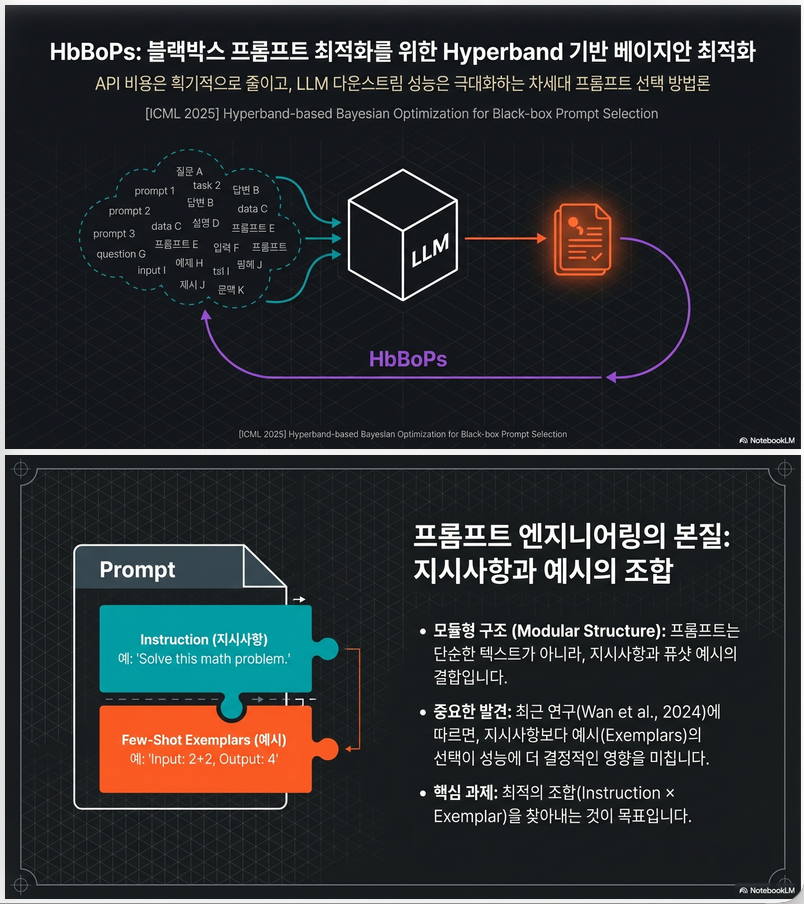
** Hyperband-based Bayesian Optimization for Black-box Prompt Selection (ICML 2025)
1. 문제 설정: Static Black-box Prompt Selection 목표 수식적으로는: argminp∈P𝔼(x,y)[l(y,hp(x))]\arg\min_{p \in P} \mathbb{E}_{(x,y)}[l(y, h_p(x))] 하지만 실제로는 validation set 평균으로 근사: f(p)=1nvalid∑i=1nvalidl(yi,hp(xi))f(p) = \frac{1}{n_{valid}} \sum_{i=1}^{n_{valid}} l(y_i, h_p(x_i)) 여기서 핵심 제약은: 즉, 샘플 효율(sample-efficient) + 쿼리 효율(query-efficient) 이 동시에 필요함. 2. 기존 방법들의 한계 논문에서 지적한 문제점: 방법 한계 EASE exemplar selection 위주, 구조 정보 활용 X…
-

** INSTRUCTZERO: Efficient Instruction Optimization for Black-Box Large Language Models (ICML 2024)
1. 문제 정의: 왜 Instruction 최적화가 어려운가? LLM은 instruction-following 능력이 있지만, instruction phrasing에 매우 민감합니다. 동일한 의미라도 표현이 조금만 달라지면 성능이 크게 변합니다. 논문은 다음 문제를 다룹니다: maxv∈𝒱𝔼(X,Y)∼Dth(f([v;X]),Y)\max_{v \in \mathcal{V}} \mathbb{E}_{(X,Y)\sim D_t} h(f([v;X]), Y) 핵심 난점 2. 핵심 아이디어 직접 instruction을 최적화하지 않는다. 대신, Soft prompt를 최적화해서, open-source LLM이 좋은 instruction을 생성하도록 유도한다. 전체 구조…
-
* Bayesian Optimization for Instruction Generation (BOInG) (Applied Sciences, 2024)
다음 논문은 BO를 이용해 instruction(프롬프트)를 자동 생성하는 방법을 제안한 연구입니다: Sabbatella et al., “Bayesian Optimization for Instruction Generation (BOInG)”, Applied Sciences, 2024 1. 문제 설정: 왜 Instruction을 BO로 최적화하는가? LLM의 성능은 **instruction(=프롬프트)**에 매우 민감합니다. 특히 **black-box LLM (예: GPT-3.5, GPT-4o)**에서는 gradient 접근이 불가능하므로, instruction 최적화는 black-box combinatorial optimization 문제가 됩니다. 논문은 이를 다음과 같이 정식화합니다…