[카테고리:] mechanistic interpretability
-

** Neuron-Level Knowledge Attribution in Large Language Models (EMNLP 2024)
아래는 EMNLP 2024 논문 “Neuron-Level Knowledge Attribution in Large Language Models” 의 핵심 내용을 정리한 설명입니다. 논문 개요 이 논문은 LLM 내부에서 특정 지식(facts)이 어떤 뉴런(neuron)에 저장되는지 정량적으로 찾아내는 뉴런 수준(neuron-level) attribution 방법을 제안합니다. 피쳐 단위(head, layer)보다 더 미세한 수준입니다. 기존 기법은 논문은 이를 해결하기 위해: 을 수행합니다. 배경 (왜 뉴런 수준인가?) 이전 연구들(Geva et…
-

Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering (Arxiv 2024)
논문 “Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering” (Pochinkov et al., 2024) 은 Transformer 기반 모델의 주의(attention) 뉴런 해석과 절제(ablation) 방법을 체계적으로 비교하고, 새로운 방식인 **Peak Ablation (정점 중심 절제)**을 제안한 연구입니다. 아래에 핵심 내용을 구조적으로 정리했습니다. 1. 연구 배경 및 문제의식 기존 절제 방식: 2. 제안 개념: Peak Ablation…
-

* Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps (EMNLP 2024)
다음 논문은 “Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps” (EMNLP 2024) 입니다 . 이 논문은 **LLM의 contextual hallucination(문맥 기반 환각)**을 attention map만을 사용해 탐지하고, decoding 단계에서 이를 완화하는 방법을 제안합니다. 1. 문제 정의: Contextual Hallucination 논문은 환각을 두 종류로 구분합니다: 이 논문은 **후자(context-grounded setting)**에 집중합니다. 대표 예:…
-
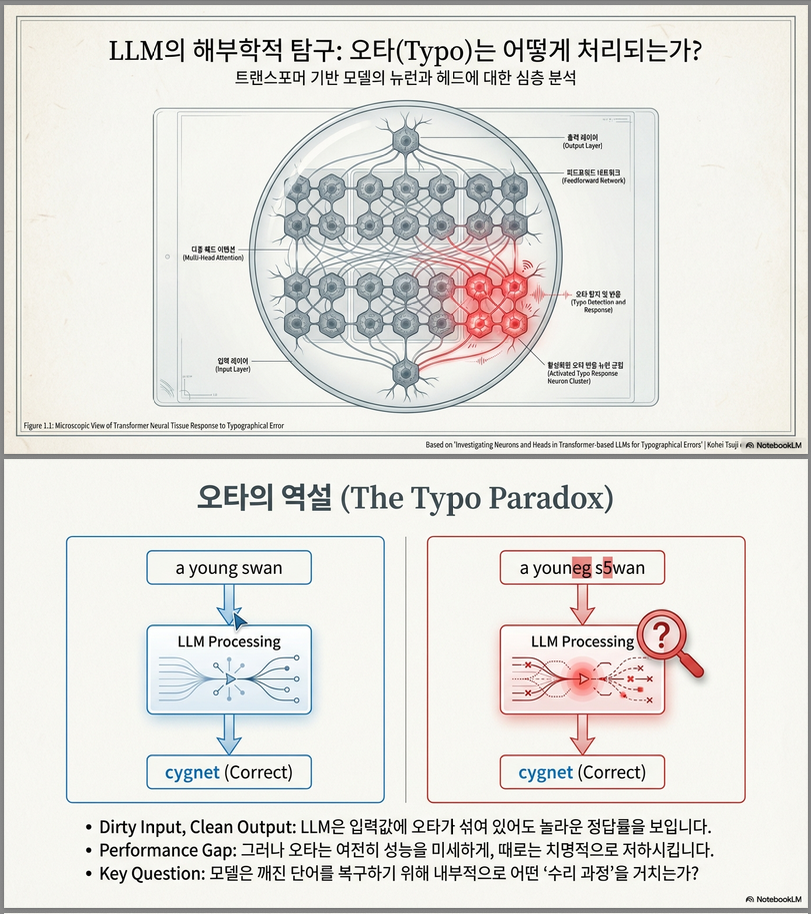
*** Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors (EMNLP 2025)
다음은 **EMNLP 2025 논문 “Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors”**에 대한 핵심 정리입니다. 연구 동기 LLM 입력에는 종종 **오타(typo)**가 포함되며, 모델은 때때로 이를 내부적으로 보정해 올바른 의미를 복원합니다. 그러나 경우에 따라 오타는 모델의 성능 저하를 유발합니다. 이 연구는: 어떤 뉴런(neurons)과 어떤 어텐션 헤드(attention heads)가 오타를 감지·보정하는지 밝혀내는 것이 목표입니다. 주요 연구…
-

** Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis (EMNLP 2025)
논문 “Enhancing Chain-of-Thought Reasoning via Neuron Activation Differential Analysis” (EMNLP 2025) 은 LLM의 연쇄적 사고(Chain-of-Thought, CoT) 능력을 뉴런 수준에서 해석하고 향상시키는 방법을 제안한 연구입니다. 아래는 핵심 내용을 정리한 설명입니다. 연구 배경 제안 방법 1. 대비 데이터셋(Contrastive Dataset) 구축 2. 뉴런 활성도 차이 계산 3. 핵심(reasoning-critical) 뉴런 선택 4. 뉴런 개입(Intervention) 주요 결과 모델 평균 성능…
-

** Retrieval Head Mechanistically Explains Long-Context Factuality (ICLR 2024)
아래는 「Retrieval Head Mechanistically Explains Long-Context Factuality」(ICLR 2024) 논문의 핵심을 문제의식 → 방법론 → 주요 발견 → 실험적 근거 → 시사점 순서로 정리한 설명입니다. 1. 문제의식 장문 컨텍스트(수만~십만 토큰)에서 LLM이 어떻게 필요한 정보를 정확히 찾아(faithful retrieval) 출력하는지 내부 메커니즘은 불분명했다. 특히 Needle-in-a-Haystack 유형에서 사실성이 유지되는 이유를 어떤 내부 구성요소가 담당하는가가 핵심 질문이다. 2. 핵심 가설…
-

*** Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization (ACL 2025)
논문 “Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization” (ACL 2025 Long Paper) 은 RAG 기반 LLM의 신뢰도 문제, 특히 문맥적 정합성(contextual faithfulness) 을 향상시키는 새로운 방법을 제안한 연구입니다 . 1. 연구 배경 2. 주요 아이디어: RHIO 프레임워크 RHIO = Retrieval Heads-Induced Optimization “retrieval head를 마스킹하여 비충실(unfaithful)한 샘플을 인위적으로 만들고, 이를 이용해…
-

*** Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings (ACL 2025)
논문 **“Interpret and Improve In-Context Learning via the Lens of Input-Label Mappings” (ACL 2025)**는 대형 언어 모델(LLM)의 In-Context Learning (ICL) 능력을 **입력-레이블 매핑(input-label mappings)**의 관점에서 분석하고, 해당 메커니즘을 해석하며, 향상시키는 방법을 제안합니다. 1. 연구 질문 LLM의 ICL 성능을 분석하기 위해 다음 세 가지 질문을 다룹니다: 2. 주요 기여 (1) 입력-레이블 매핑의 발견 (2) PC Patching 기법 (3) 매핑…
-
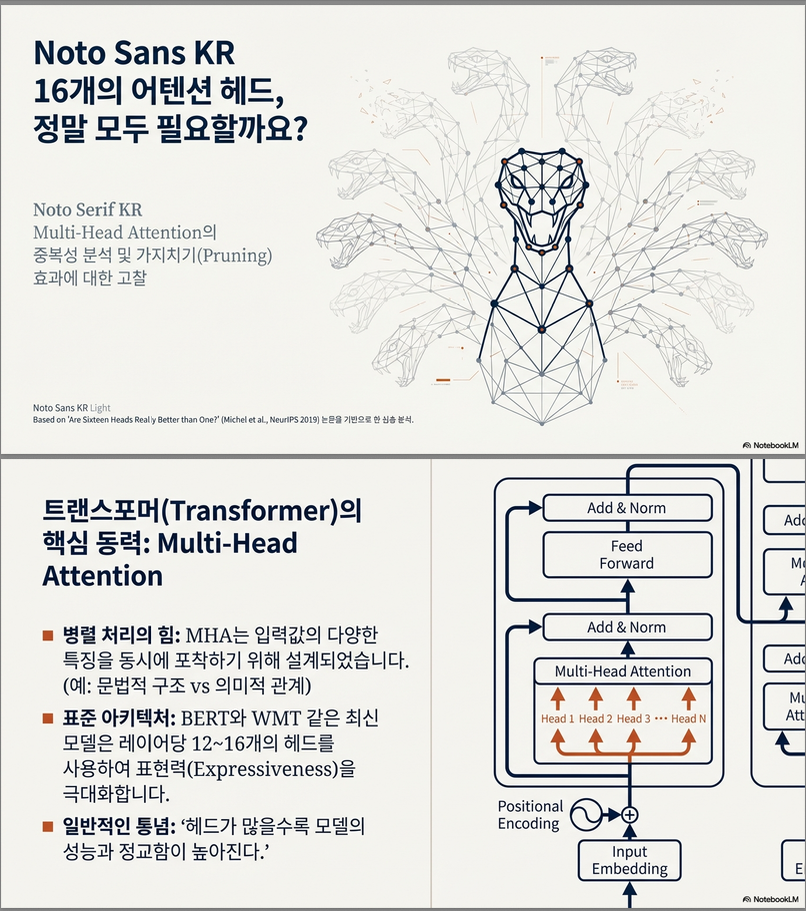
Are Sixteen Heads Really Better than One? (NeurIPS 2019)
이 논문은 **Transformer의 multi-head attention(MHA)가 정말로 많은 head를 필요로 하는가?**라는 매우 직관적인 질문을 실증적으로 파고든 고전적인 분석 논문입니다. 아래에서 문제의식 → 방법론 → 실험 결과 → 핵심 해석 → 이후 연구에 미친 영향 순서로 정리해 드릴게요. (논문: Are Sixteen Heads Really Better than One?, NeurIPS 2019) 1. 문제의식 (Motivation) Transformer에서 multi-head attention은 다음과 같은 이유로…
-

** LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models (arXiv 2025)
아래는 **arXiv 2025 논문 *“LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models”***에 대한 설명입니다. 설명은 배경 → 방법론 → 시스템 설계 → 시각화 및 결과 → 기여와 한계 순으로 정리했습니다. 1. 연구 배경과 문제의식 Logit Lens는 중간 layer의 hidden state를 최종 LM head로 바로 투사하여, “이 layer에서 이미 어떤 토큰을 예측하고 있는가?”를 관찰하는 대표적인 mechanistic interpretability 기법입니다.…