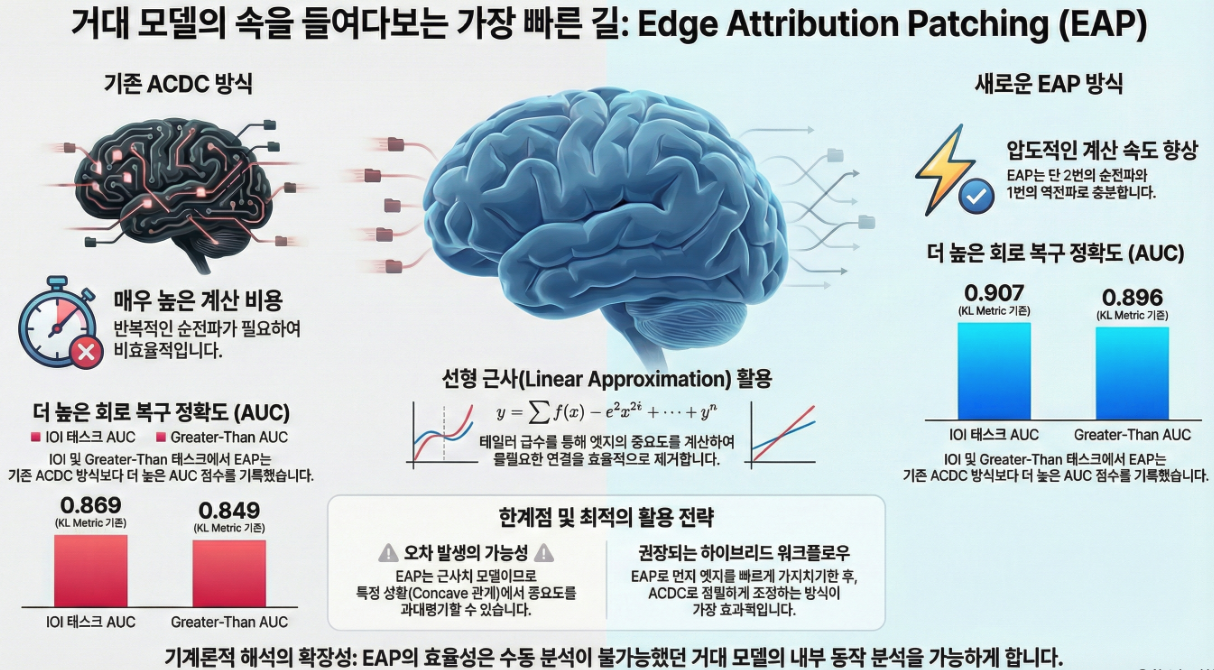




아래는 **BlackboxNLP 2024 논문 〈Attribution Patching Outperforms Automated Circuit Discovery〉**의 핵심 내용을 구조적으로 정리한 상세 설명입니다.
1. 논문의 문제의식 (Introduction)
메커니스틱 인터프리터빌리티의 핵심 목표는
LLM 내부에서 특정 작업(Task)을 수행하는 서브네트워크(circuit)를 자동으로 찾아내는 것이다.
기존 자동화된 방법의 대표는 **ACDC (Automated Circuit Discovery)**로,
각 *edge(노드 간의 activation flow)*가 해당 작업에 얼마나 기여하는지 activation patching을 반복적으로 수행해 측정한다.
하지만 문제는:
- Activation patching은 edge 하나당 한 번의 forward pass가 필요 → 매우 느림
- GPT-2 small 정도면 가능하지만, 더 큰 모델로 확장하기 어려움
- 메커니즘 분석을 확장하기 위한 자동화가 현실적으로 어렵다는 점
이에 저자들은 더 간단하고 빠른 방법인
Attribution Patching을 Edge 단위로 일반화한 **EAP(Edge Attribution Patching)**을 제안한다.
2. 핵심 아이디어: Edge Attribution Patching (EAP)
Activation Patching이란?
- 특정 edge의 activation을 “clean” → “corrupted” 값으로 치환(do-intervention)하여 **모델의 Loss 변화 |L(clean) – L(patched)|**를 측정
- 실제 causal effect를 반영하지만 → edge 하나당 forward pass 1번 필요 → 매우 느림
Attribution Patching이란?
Neel Nanda(2023)가 제안한 기법으로, activation patching의 효과를 1차 테일러 전개로 근사한다. 즉,
L(ecorr) − L(eclean) ≈ (ecorr − eclean)ᵀ · ∂L/∂e
→ 두 번의 forward pass + 한 번의 backward pass로
모든 edge의 영향을 한 번에 계산할 수 있다.
EAP는 Attribution Patching을 Edge 수준으로 확장한 것
- 모든 edge에 대해 attribution score ΔeL 추정
- 절대값이 큰 edge 순으로 sorting
- Top-k edge만 남긴 subgraph를 circuit으로 간주
이 방식은:
- ACDC보다 훨씬 빠르고
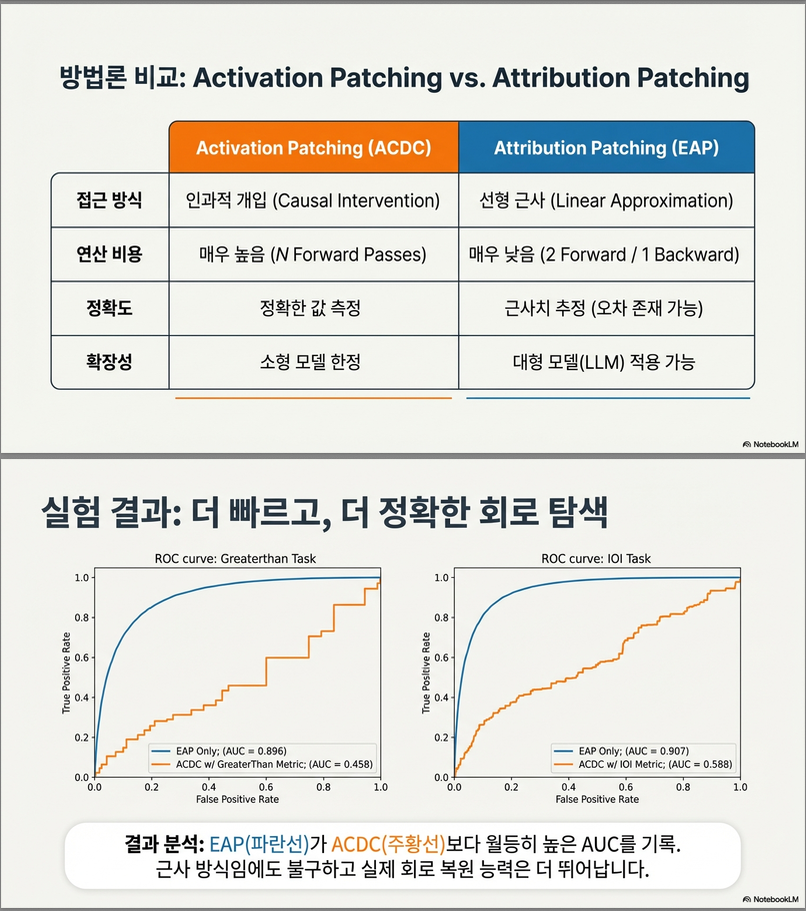
- **여러 태스크(IOI / Greater-Than / Docstring)에서 ACDC보다 높은 회복률(AUC)**을 보인다. (ROC curve는 PDF page 3(Figure 3) 참고)
3. 방법론 자세히
3.1 Computational Graph 상의 Edge 정의
Transformer의 구조를 다음과 같이 본다:
- Node: Attention head / MLP block
- Edge: 한 node의 출력을 다음 node의 residual stream 또는 Q/K/V 입력으로 전달하는 경로
즉, 특정 head → 다음 layer head로 이어지는 정보 흐름을 edge로 모델링한다.
3.2 Activation Patching 공식
(논문 식 (1) 기반)
|ΔL| = |L(x_clean | do(E = e_corr)) – L(x_clean)|
이것이 ground truth이지만 계산 비용이 너무 크다.
3.3 Attribution Patching 근사
(논문 식 (2) 기반)
L(ecorr) ≈ L(eclean) + (ecorr – eclean)ᵀ (∂L/∂e)
따라서 activation patching 효과는 다음으로 근사됨:
|ΔeL| = |(ecorr – eclean)ᵀ ∂L/∂eclean|
이 값이 바로 edge의 importance score가 된다.
3.4 EAP 전체 알고리즘
- Clean, corrupted 입력 쌍 (x_clean, x_corr)을 준비
- 모델을 두 번 forward → 각 edge의 e_clean, e_corr 계산
- Loss에 대한 gradient ∂L/∂e 를 한 번의 backward pass로 계산
- 모든 edge에 대해 ΔeL 계산
- 절대값 순으로 sorting
- Top-k edge를 사용한 서브그래프가 circuit
특히 중요한 점:
Residual 연결(edge type i)의 경우 종단점 노드에 대한 gradient만 있으면 충분함
→ Appendix F에서 수학적으로 증명됨
4. 실험 (Results)
4.1 비교 대상
- EAP
- ACDC (original, KL metric)
- ACDC (task-specific metric)
- Activation Patching (slow, Docstring에서만 가능)
ROC / AUC 결과 요약
(논문 Figure 3 참조)
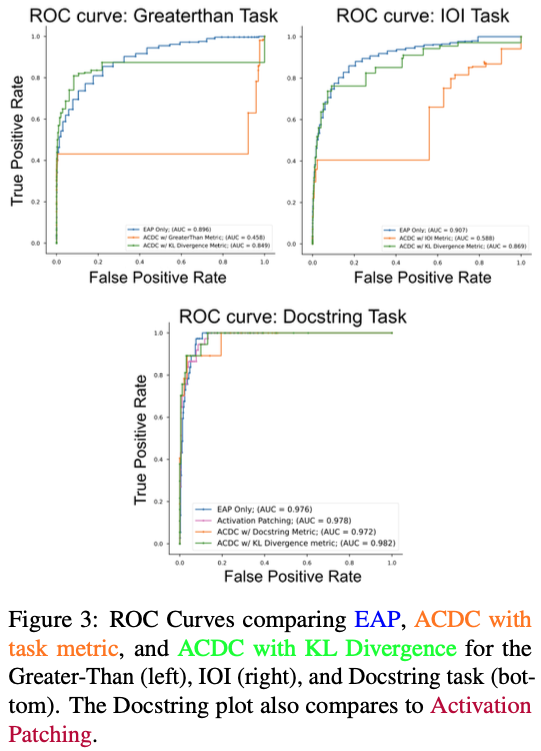
| Task | Best Method |
|---|---|
| IOI | EAP |
| Greater-Than | EAP |
| Docstring | ACDC(KL) ≥ EAP |
→ 평균적으로 EAP가 전체 task에서 가장 높은 AUC를 보임.
4.2 Attribution Score가 실제 Circuit을 잘 반영하는가?

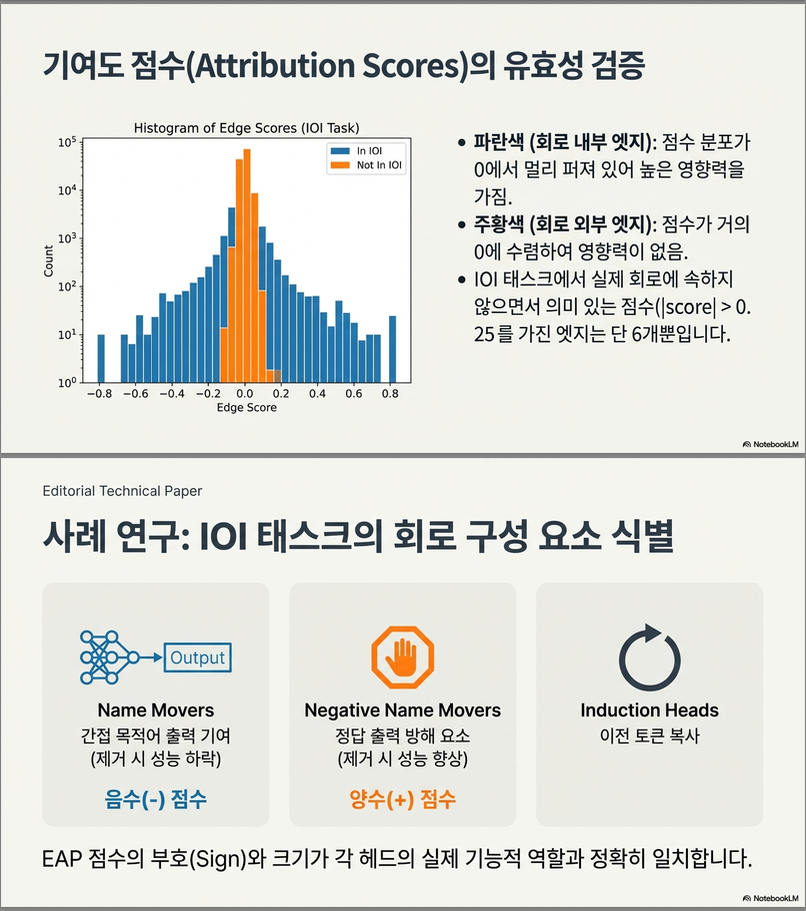
논문의 Figure 4에서 IOI task를 보면:
- Circuit 내부 edge는 분포의 꼬리(tail)에 더 넓게 퍼짐
- Circuit 외부 edge는 0 주변에 밀집
즉, EAP는 circuit 관련 edge를 잘 구분하는 경향을 보인다.
5. 한계 (Limitations)
5.1 Attribution Patching은 Activation Patching을 완벽히 근사하지 않는다
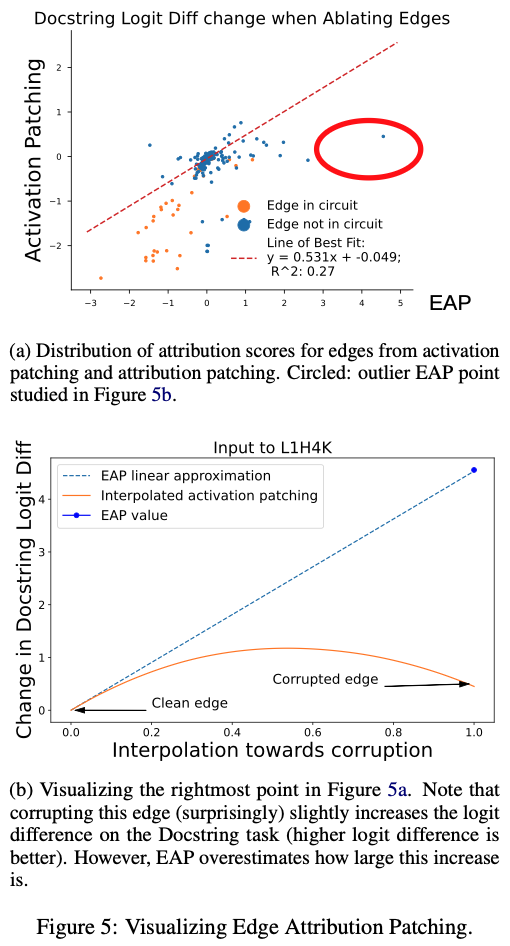
Figure 5(a) 분석:
- Activation patching vs Attribution patching 상관계수 R² = 0.27 → 매우 낮음
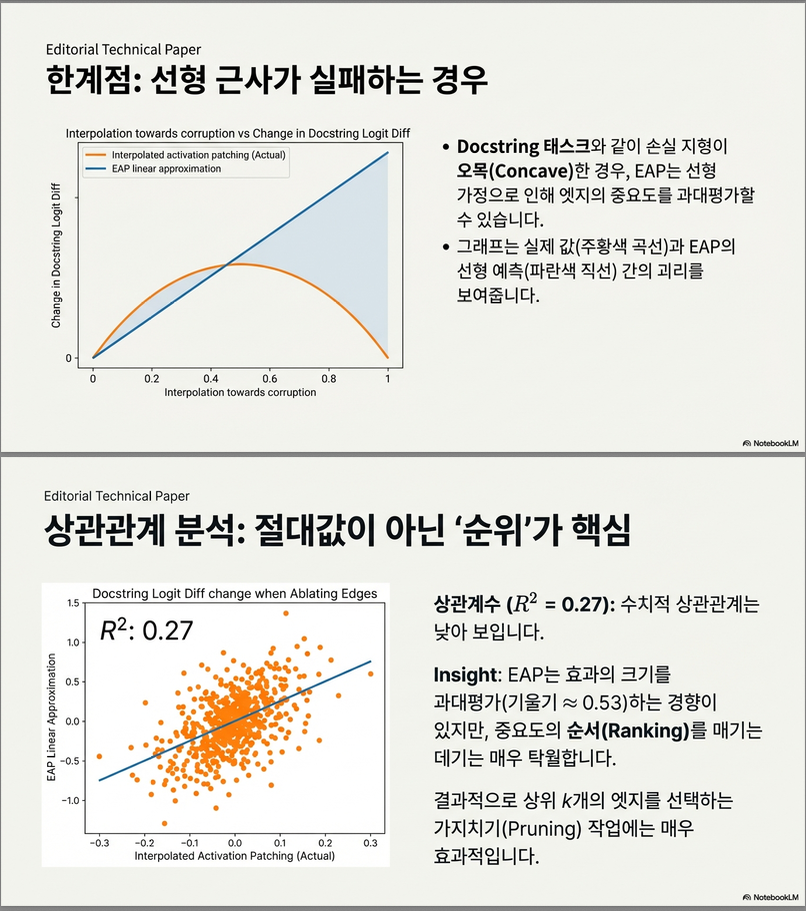
- Linear approximation이 **effect를 과대평가(overestimate)**하는 경향 존재
특히 입력 embedding layer 근처 edge에서 이런 오차가 자주 발생 (Appendix D).
즉, 근사는 부정확하지만 그럼에도 circuit을 잘 찾아낸다는 점이 흥미로운 결론.
5.2 ACDC는 완전히 필요 없어졌는가?
그렇지 않음.
- EAP가 후보 서브그래프를 찾고
- 그 위에서 ACDC를 다시 수행하면 → Docstring task에서 성능이 더 증가 (Figure 6 참고)
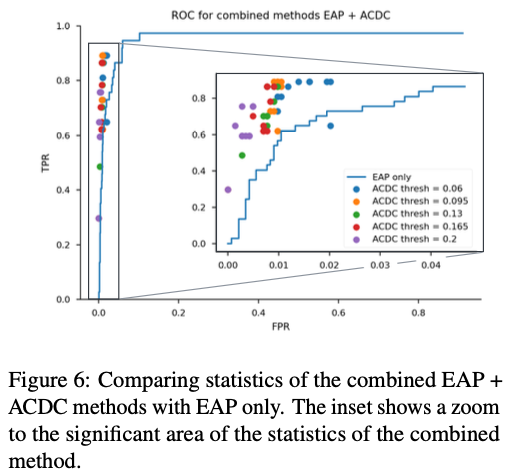
즉 “EAP → ACDC” 조합이 가장 정확한 circuit discovery pipeline.
6. 결론 (Conclusion)
요약하면, 이 논문의 핵심 메시지는 다음과 같다:
✔ Activation patching 기반 ACDC보다
✔ 단순한 1차 테일러 근사(attribution patching)를 적용한 EAP가
✔ 더 빠르고 정확하게 circuit을 복원한다.
그러나 EAP는 activation patching의 정확한 근사가 아니기 때문에
EAP로 1차 후보를 찾고, ACDC로 refinement하는 하이브리드 방식이 최적이라는 결론.
아래는 논문의 ‘방법론(Method)’ 섹션을 논문의 모든 수식·도표·부록 내용을 통합하여, 원 논문보다 더 명확한 구조로 재정리한 해설입니다.
방법론 (Method)
이 논문의 목표는 **“특정 NLP task를 수행할 때 중요한 회로(circuit)를 자동으로 찾는 것”**이며, 기존의 ACDC보다 더 빠르고 더 정확한 edge-level importance 측정 방법을 제안하는 것이다.
핵심 방법은 **Edge Attribution Patching(EAP)**이며, 아래 4단계로 구성된다:
- 모델을 computational graph로 정의 (edge 단위의 정보 흐름 설정)
- Activation Patching의 문제점 파악
- Attribution Patching으로 Activation Patching을 근사하는 수식 제시
- Edge Attribution Patching 알고리즘 정식화
아래에서 각 단계를 정교하게 설명한다.
Transformer를 Edge 기반 Computational Graph로 재해석
Transformer를 다음과 같이 본다:
- Node = Attention head 또는 MLP
- Edge = 한 node가 residual stream에 쓰고, 다음 node가 그 residual stream을 읽는 경로 (e.g., Layer 3 Head 5 → Layer 4 Head 2)
이 edge는 활성화 값(activation vector) e를 가지며, 이 값을 조작(교체/근사)함으로써 edge가 task에 미치는 영향을 측정할 수 있다.
즉:
Circuit discovery = 전체 edge 중 “task 성능에 가장 중요한 edge”를 찾는 작업
Activation Patching: 정확하지만 너무 느림
Activation patching은 causal tracing·interchange intervention과 동일한 개념이다.
✔ 개념
Clean prompt:
Corrupted prompt:
특정 edge E에 대해:
- clean forward pass에서 얻은 activation →
- corrupted forward pass에서 얻은 activation →
이제 clean 실행 중에 edge E를 강제로 corrupted 값으로 교체한다:
이를 기존 clean loss와 비교해 edge 중요도를 정의:
→ 문제점
edge가 수천 개일 경우 edge마다 forward pass 1번씩 필요 →
GPT-2 small에서도 매우 느림, 대형 모델에서는 사실상 불가능
Attribution Patching: Activation Patching을 1차 테일러 근사로 대체
Activation patching의 loss 변화를 다음처럼 1차 테일러 전개로 근사한다:
따라서 activation patching의 효과는:
이 식의 의미:
- edge 활성화 변화량 (e_corr – e_clean)
- 그 변화가 loss에 미치는 민감도(gradient)
두 벡터의 내적이 곧 edge 중요도이다.
계산 비용
- clean forward pass 1번
- corrupted forward pass 1번
- backward pass 1번 → 모든 edge의 ∂L/∂e 계산됨
따라서:
Activation patching 대비 수백~수천 배 빠름
Appendix F의 기술적 핵심
Residual stream으로 합쳐지는 edge는 입력 activation들의 합이므로
해당 edge의 gradient는 단순히 종단 노드(node endpoint)의 gradient로 충분하다.
즉, edge마다 gradient를 따로 계산할 필요가 없음
→ EAP가 “정말로 1 backward pass만 필요한” 이유.
EAP(Edge Attribution Patching) 알고리즘
이제 attribution patching을 edge 전체에 적용하여 회로를 찾는 알고리즘을 만든다.
Step 1. 모든 edge의 activation 쌍(e_clean, e_corr) 수집
각 (x_clean, x_corr) 입력 쌍에 대해 모델을 두 번 forward:
- Clean activations
- Corrupted activations
Step 2. Loss gradient 계산
clean 실행에서 loss L을 기준으로 backward pass 한 번 실행:
이 gradient는 모델 전체의 모든 edge endpoint에 대해 자동 계산된다.
Step 3. Edge Attribution Score 계산
각 edge E에 대해:
여기서 여러 입력 쌍에 대해 평균을 취한다.
Step 4. Edge 중요도 정렬 → Top-k 서브그래프 생성
score(E)가 큰 순서대로 정렬하여 top-k edge를 남긴다.
이 edge들의 집합이 task-specific circuit이다.
논문 Figure 7 (PDF page 7)는 IOI, Docstring, Greater-Than task에서
EAP가 복원한 서브그래프를 시각적으로 보여준다.

정리: 방법론의 핵심 포인트
✔ Activation patching을 직접 하지 않고
✔ 1차 테일러 근사로 “가짜 activation patching 효과”를 계산
✔ 그럼에도 실제 circuit discovery 성능은 ACDC보다 높음
✔ 계산량은 ACDC 대비 수백 배 빠름
✔ 전체 과정은 forward 2번 + backward 1번이면 끝
이 단순한 근사식이 놀랍게도 매우 좋은 circuit recovery accuracy를 보이며,
특히 GPT-2 기반 IOI, Greater-Than task에서 최고 성능을 달성했다.
아래 설명은 논문의 식(2) / Appendix F / Figure 1 내용을 기반으로,
특히 “Step 2. Loss gradient 계산에서 ‘edge로 편미분한다’는 무엇인가?”를
메커니스틱·수학적으로 완전히 명확하게 정리한 것입니다.
요약부터
EAP에서 말하는 **“edge로 loss를 편미분한다”**의 정확한 의미는:
해당 edge가 쓰는 activation e가 아주 조금 변하면, loss L이 어떻게 변하는지 측정하는 것.
즉, 를 구하는 것이다.
그리고 놀라운 사실은:
Transformer의 residual 구조 때문에, edge activation 자체를 따로 미분할 필요가 없고,
그 edge가 “더해지는 지점(=endpoint node의 residual 입력)”의 gradient만 구하면 된다.
(Appendix F에서 엄밀히 증명됨)
Edge activation( e )이란 무엇인가?
Transformer에서는 다음이 일어난다:
- 어떤 head/MLP의 출력 → residual stream에 더해짐
즉, **edge activation e**는
“어떤 node에서 계산된 벡터가 다음 layer의 residual stream에 더해지는 값”이다.
따라서 edge는 다음과 같이 모델 계산 그래프의 입력으로 사용된다:
(e_clean / e_corr) → residual_pre(l+1) → 다음 layer 전체 계산 → ... → loss LActivation Patching의 목표
Activation patching은 “edge activation e를 clean 값에서 corrupted 값으로 바꿨을 때 loss가 어떻게 변하는가”를 보고 싶다:
하지만 이는 forward pass를 하나 더 돌려야 한다.
그래서 논문은 이 변화를 1차 테일러 근사로 계산한다:
따라서 핵심은:
각 edge activation e에 대한 gradient, 즉 가 필요하다.
그런데 edge로 직접 편미분은 왜 어려운가?
Transformer 모델 코드에서 “edge”라는 객체는 실제로 존재하지 않는다.
즉,
- head output → projection → residual add 이 과정은 자동 미분이 계산하지만, “각 head output이 residual stream에 기여하는 edge”라는 개념은 모델 내부에 없기 때문에
를 직접 얻는 것은 쉽지 않다.
그래서 EAP는 훨씬 중요한 구조적 사실을 사용한다.
Residual 구조의 핵심: Edge activation은 노드 residual input의 일부
논문 Appendix F에 따르면:
Edge activation e 는, 그 edge가 도달하는 residual 노드의 입력 v 에 단순히 더해지는 형태이다.
즉:
따라서 미분 규칙(chain rule)에 의해:
그런데
따라서:
➡ 즉, edge activation에 대한 gradient는
endpoint residual 노드의 gradient와 동일하다.
따라서 EAP Step 2의 실제 동작은?
✔ Clean forward → Loss 계산
✔ 딱 한 번 backward() 수행
그러면 PyTorch가 자동으로 다음을 계산한다:
- 각 layer의 residual input, 즉 에 대한 gradient:
그러면 edge i 의 gradient는:
따라서:
EAP에서는 “edge에 대한 편미분”을 계산하는 것이 아니라,
edge가 도달하는 residual node의 gradient를 읽는 것만으로 충분하다.
정확히 왜 이것이 가능한가? (수식 재정리)
Activation patching 근사치는 다음과 같다:
여기서
따라서:
그리고 backward() 한 번이면
모델 전체의 모든 residual input v 에 대한 gradient가 자동으로 계산된다.
직관적 해석: Why does this work?
Residual stream은 transformer의 핵심 “공용 메모리 공간”이다.
각 node(head/MLP)의 출력은 여기에 단순 합(add)으로 적재된다.
따라서:
- 특정 node의 출력(edge activation)이 조금 바뀌면
- residual stream이 그만큼 바뀌고
- 그 residual이 downstream 연산 전체에 영향을 준다
이 전체 과정의 민감도를 나타내는 것이 바로
“residual input에 대한 gradient”이다.
그래서 edge gradient = residual gradient.
결론: Step 2의 의미
논문 Step 2 “Loss gradient 계산”의 의미:
“각 edge activation e 에 대해 ∂L/∂e 를 계산해야 한다.”
하지만 실제 구현에서는:
“각 edge가 쓰여지는 residual input v 에 대해
∂L/∂v 만 계산하면 된다.”
즉,
- backward() 한 번 → residual grad 얻고
- 그 grad를 edge별 activation 차이(e_corr – e_clean)에 내적하면
- edge importance score가 나온다.
그리고 이것이
EAP가 activation patching을 근사하면서도 매우 빠른 이유이다.
정리 문장 (매우 중요)
“Edge에 대한 loss gradient”란,
Edge가 도달하는 residual stream 입력에 대한 gradient를 의미한다.
이는 역전파 한 번으로 자동으로 계산되며,
Edge activation 변화가 loss를 얼마나 바꾸는지를 정량화한다.
논문에서 보고한 실험 결과만 쭉 정리해 볼게요. (IOI / Greater-Than / Docstring 세 태스크 기준)
1. EAP vs ACDC vs Activation Patching: 회로 복원 성능
실험 세팅
- 태스크:
- IOI (Indirect Object Identification) – GPT-2 small 기반 고전 실험
- Greater-Than – 숫자 비교
- Docstring – Python docstring completion (4-layer attention-only 모델)
- “정답 회로(ground-truth circuit)”:
- 기존 논문들에서 수작업/반자동으로 찾은 circuit을 기준으로 삼고, 자동 기법이 복원한 서브그래프와의 edge overlap으로 측정.
- 평가지표:
- ROC curve & AUC
- x축: FPR(정답이 아닌 edge를 circuit이라고 잘못 포함하는 비율)
- y축: TPR(정답 edge를 얼마나 잘 포함하는지)
- ROC curve & AUC
주요 비교 메서드
- EAP (Edge Attribution Patching) – 이번 논문의 주인공
- ACDC (원래 버전) – KL divergence를 metric으로 사용
- ACDC (task-specific metric) – IOI, docstring 등 각 태스크에 맞는 logit diff 등 사용
- Activation Patching 기반 반복 회로 탐색 – Docstring 태스크에서만 (모델이 작아서 가능)
결과 요약 (Figure 3 기준)
- IOI 태스크
- EAP의 ROC curve가 가장 위쪽에 위치 → AUC 최고
- ACDC(KL), ACDC(task metric)는 그보다 아래
- Greater-Than 태스크
- 역시 EAP가 최고 AUC
- ACDC 계열보다 안정적으로 정답 edge를 잘 복원
- Docstring 태스크
- 여기서는 ACDC + KL Divergence가 EAP보다 약간 우위
- Activation patching으로 구한 회로는 baseline으로 같이 비교되며, EAP는 activation patching과 ACDC 사이 정도의 성능
결론 1:
평균적으로 보면 IOI + Greater-Than에서의 우위를 감안할 때
EAP가 ACDC보다 “전반적으로 더 나은 회로 복원 성능(AUC)”을 보인다.
2. EAP Attribution Score가 실제 회로와 얼마나 잘 맞는가?
2.1 IOI 태스크의 score 분포 (Figure 4)
- 각 edge에 대해 EAP로 얻은 attribution score(=logit diff 변화량 근사)를 히스토그램으로 그림.
- **“정답 회로에 속한 edge” vs “그 외 edge”**를 나눠서 분포를 비교.
관찰:
- 회로 내부 edge들은 0에서 멀리 떨어진 값이 많이 나온다.
- 회로 외부 edge들은 0 근처에 크게 몰림 (분산이 매우 작음)
- IOI에서 회로 밖 edge 중, |score| > 0.25 정도로 크게 나온 건 6개뿐이라고 보고함.
결론 2:
EAP score는
- 회로에 속한 edge는 **“강하게 task에 영향을 주는 축”**으로 보내고
- 회로 밖 edge는 0 근처에 두는 경향이 뚜렷해서 회로/비회로 분리를 꽤 잘 해낸다.
2.2 Docstring / Greater-Than 태스크 분포 (Appendix B, Figure 8)
두 태스크에 대해서도 비슷한 분포 패턴:
- 회로 내부 edge는 score 분산이 크고 tail에 많이 분포
- 회로 외부 edge는 0 근처에 샤프하게 몰려 있음
3. EAP 근사의 “faithfulness” (Activation Patching과 얼마나 일치하나?)
3.1 Score 상관관계 (Figure 5a)
Docstring 태스크에서:
- x축: EAP score (attribution patching 근사값)
- y축: Activation patching으로 직접 측정한 실제 logit diff 변화
- 각 점 = 한 edge
결과:
- R² = 0.27 → 상관관계가 생각보다 약함
- 회귀직선 기울기 ≈ 0.531 → EAP가 실제 activation patching 효과를 대략 “두 배 정도 과대평가”하는 경향
- 오른쪽에 특이한 outlier cluster(타원으로 표시) 존재 → 이후 Figure 5b에서 분석
결론 3:
EAP는 activation patching을 매우 정확히 근사하는 것은 아니다.
하지만 그럼에도 불구하고 회로 복원 성능은 최고 수준이라는 게 흥미로운 포인트.
3.2 선형 근사 vs 실제 곡선 (Figure 5b & Appendix D/Figure 10)
특정 edge 하나를 잡고, clean→corrupted로 보간:
각 에서 activation patching을 실제로 수행했을 때의 logit diff 변화를 그려 보면:
- 곡선이 concave한 형태를 보임 (위로 굽는 모양)
- = 0에서의 접선(=EAP의 1차 근사)이 실제 = 1에서의 변화량을 과대평가하는 모습
특히 이 현상은:
- embedding 계층에서 residual로 들어가는 edge들에서 많이 나타남
- embedding을 linear interpolation해서 넣는 것이 모델에 비정상적인 입력으로 작용해 비선형 효과가 커지는 것으로 해석
결론 4:
- EAP는 activation patching의 1차 근사이지만, **실제 task metric은 상당히 비선형(특히 concave)**이라 정량적으로는 정확한 예측이 아님.
- 그럼에도 ranking 용도로는 꽤 유용하다 → “faithful enough for circuit discovery”.
4. EAP + ACDC 조합: 후처리로 ACDC를 쓰면?
실험: Docstring 태스크에서
- 1단계: EAP로 전체 그래프를 먼저 pruning
- score threshold를 바꿔가며 다양한 크기의 서브그래프 생성
- 2단계: 그 서브그래프 위에서 ACDC를 돌려 추가로 pruning/refinement
- 다양한 threshold 조합에 대해 TPR/FPR, 그리고 Youdens-J statistic = TPR − FPR를 평가 (Figure 6, Appendix C/Figure 9)
결과:
- EAP만 썼을 때의 ROC curve보다 EAP → ACDC 조합이 더 좋은 점들을 많이 차지
- 특히 특이 edge들(EAP가 과대평가한 edge 등)을 ACDC가 다시 걸러내면서 회로 복원 성능이 추가로 향상되는 패턴
결론 5:
“EAP로 먼저 크게 쳐내고, 그 위에서 ACDC로 세밀하게 다듬는 전략”이 최적.
즉, ACDC를 완전히 대체하기보다는
EAP를 front-end, ACDC를 back-end refinement로 쓰는 것이 좋다.
5. IOI 태스크에서 Edge 역할별 Attribution Score (Appendix E, Figure 11)
IOI 회로 분석에서 유명한 head 역할들(Induction, S-inhibition, Name Mover 등)에 대해
그 역할에 속한 edge들의 score 분포를 따로 그렸다.
관찰:
- Previous Token, Duplicate Token, Induction, S-inhibition edge들은 0 근처에 평균이 있는 비교적 대칭적인 분포
- 반면:
- Name Mover edge:
- score가 주로 음수 방향으로 치우침
- 해당 edge를 ablate하면 logit difference가 크게 감소(성능 나빠짐) → 중요하고 필요한 edge
- Negative Name Mover edge:
- score가 주로 양수 방향
- edge를 ablate하면 오히려 logit difference가 좋아짐 → 해로운 방향으로 작용하는 edge
- Name Mover edge:
결론 6:
EAP score는 단순히 magnitude만이 아니라
**edge가 “task에 이로운지 / 해로운지”에 대한 방향(sign)**까지 가지고 있고,
IOI에서 이미 알려진 역할 해석(Name mover vs Negative name mover)과 잘 일치한다.
6. Appendix A: 실제로 복원된 서브그래프 모양 (Figure 7)
각 태스크(IOI, Docstring, Greater-Than)에 대해:
- 적당한 threshold에서 EAP가 복원한 subnetwork를 그림으로 보여줌.
- node = MLP/attention head, edge = residual/attn 경로
- 인간이 찾은 circuit과 구조적으로 상당히 비슷한 connectivity를 보임.
이는 qualitative evidence로:
EAP가 실제로 “작업에 관련된 subgraph”를 잘 골라내고 있다는 시각적인 증거.
7. 전체 실험 결과에서 논문이 내린 최종 메시지
- 성능 측면
- IOI & Greater-Than에서 EAP가 ACDC보다 더 높은 AUC
- Docstring에서는 ACDC(KL)가 근소하게 앞서지만, 평균적으로는 EAP가 overall winner
- 효율 측면
- EAP: forward 2번 + backward 1번으로 전체 edge score 계산
- ACDC / activation patching: edge마다 forward 필요 → 훨씬 비싸다 → “빠르고, 그만큼 잘 먹힌다”는 게 핵심
- Faithfulness 측면
- Activation patching을 매우 정확히 근사하는 건 아니다 (R²=0.27)
- 하지만 ranking 용도로는 충분히 유의미하고, 실제 회로 복원 성능은 SOTA 수준
- 실용적 추천
- 앞으로 circuit discovery 할 때:
- EAP로 대략적인 후보 subgraph를 찾고,
- 그 위에 ACDC를 올려서 refinement 하라.
- 앞으로 circuit discovery 할 때:
답글 남기기