
연구 배경
- 문제의식:
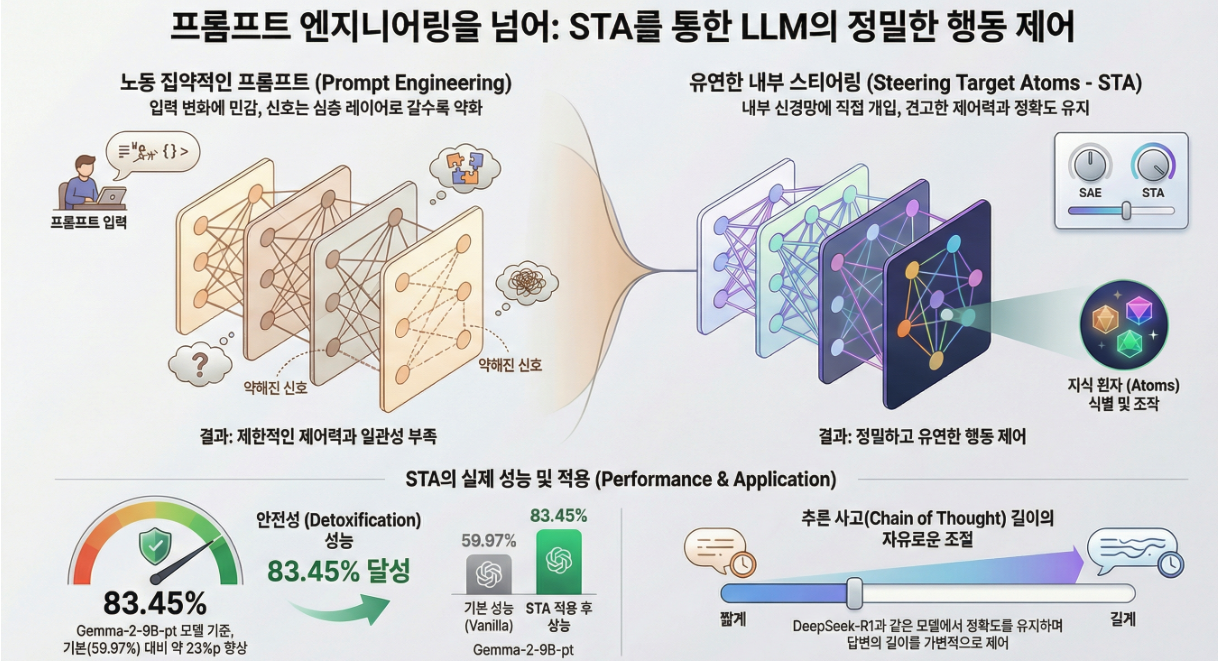
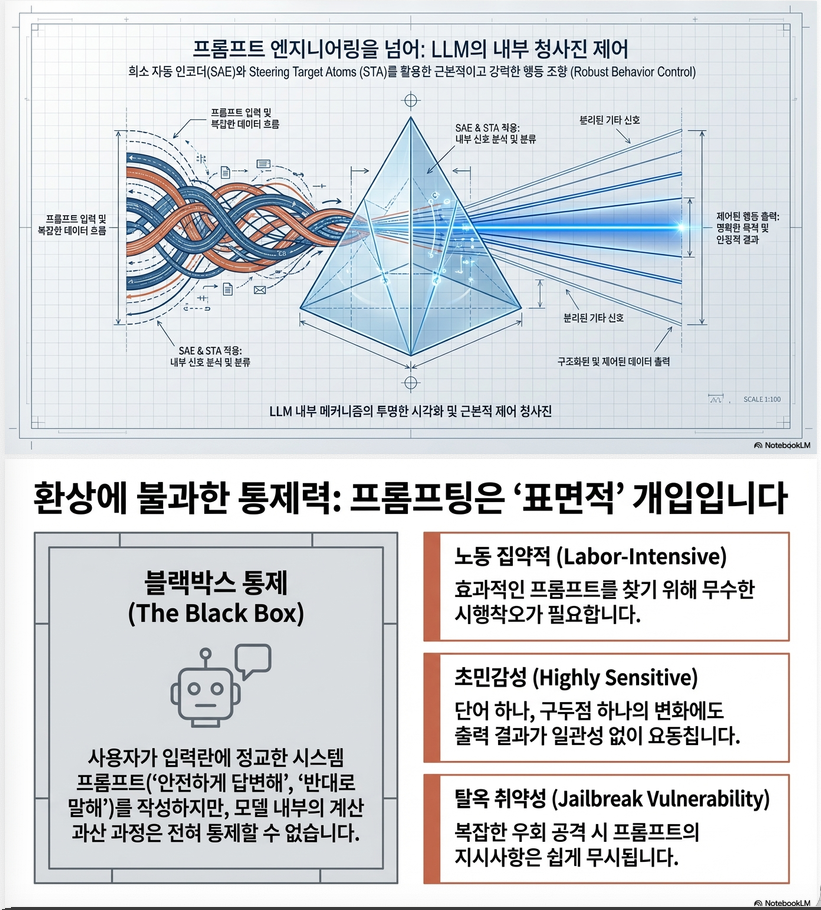
LLM의 행동을 안전하고 신뢰성 있게 제어하는 것은 중요하지만,- 프롬프트 엔지니어링은 전문가 의존적이고,
- 입력에 민감하며,
- 내부 작동 메커니즘이 불명확하다는 한계가 있습니다.
- 기존 대안:
최근에는 steering (조향) 이라는 방법이 제안되어,
모델의 은닉표현(hidden representation) 을 직접 수정하여 출력을 제어하려 했습니다.
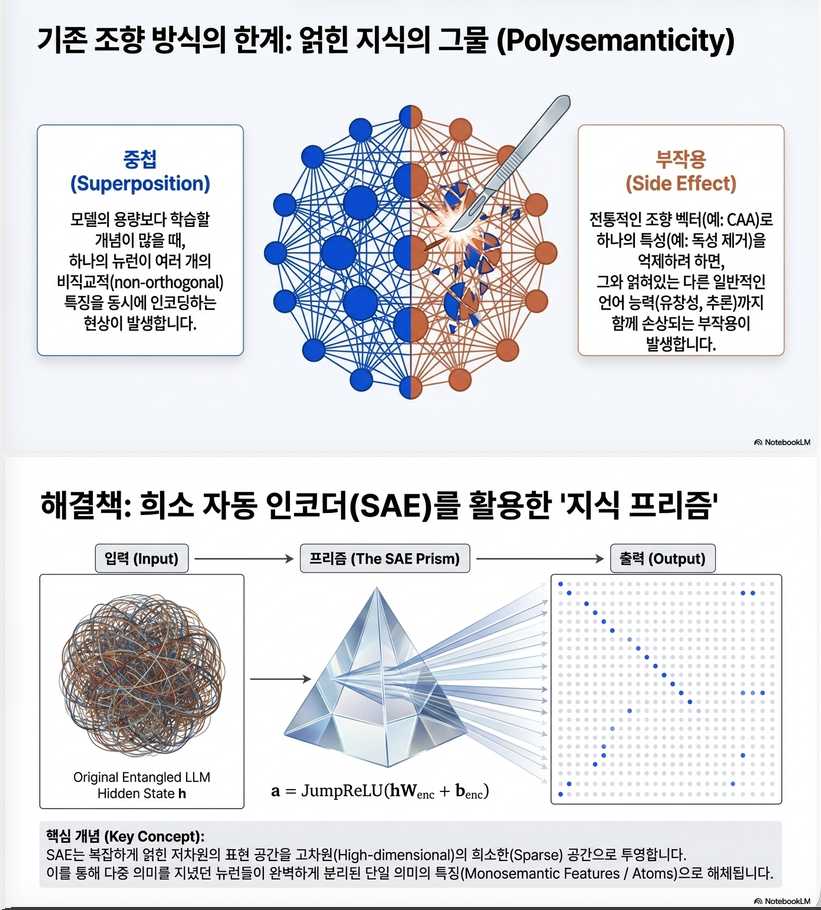
그러나 모델 내부 표현이 얽혀(entangled) 있어 특정 의미만을 정밀하게 제어하기 어렵고 부작용(side effect)이 발생합니다. - 핵심 아이디어:
LLM의 복잡한 표현을 Sparse Autoencoder (SAE) 로 분해(disentangle)하여
“원자적 지식 단위(atomic knowledge components)” 를 찾아내고,
이를 조작하여 안전성(safety) 과 정밀 제어를 동시에 달성합니다.
제안 방법: Steering Target Atoms (STA)
1. SAE 기반 표현 분해
모델의 은닉 상태 를 SAE를 통해 고차원, 희소 공간으로 투영합니다.
복원(reconstruction)은
여기서 각 row of 는 하나의 atom direction을 나타냅니다.
즉, 모델 표현을 구성하는 기본 단위입니다.
2. Target Atom 식별 (Identify Target Atoms)
positive(예: 안전한 응답)과 negative(예: 위험한 응답) 샘플의 SAE 활성도를 비교하여 활성 크기(Amplitude) 와 활성 빈도(Frequency) 차이를 계산합니다.
두 값이 모두 임계값 이상이면 “Target Atom”으로 선택:
3. Steering Vector 생성
선택된 target atoms를 원래 표현공간으로 역투영:
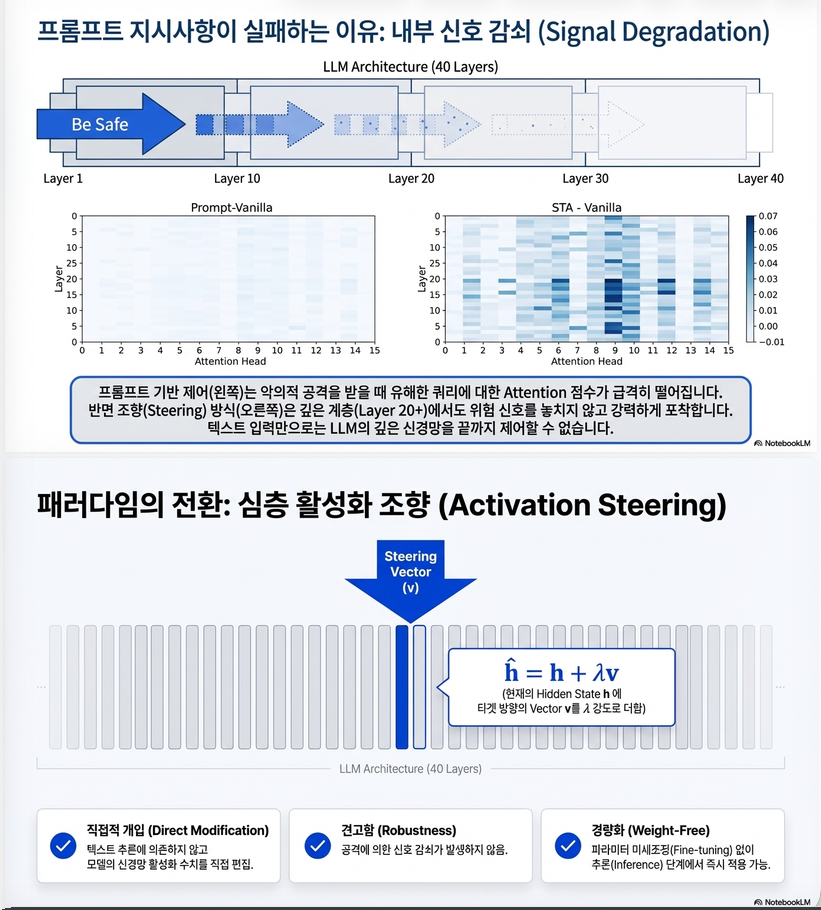
이를 모델의 중간 은닉상태에 추가하여 제어:
λ은 steering 강도를 조절하는 스칼라입니다.
실험
설정
- 모델: Gemma-2-9B (pt/it), Llama-3.1-8B
- SAE: GemmaScope, LlamaScope 활용
- 데이터셋:
- SafeEdit, RealToxicPrompts → 안전성 평가
- GSM8K, MMLU → 일반 성능 유지 확인
결과 요약
| Model | Method | Detox ↑ | General ↓ |
|---|---|---|---|
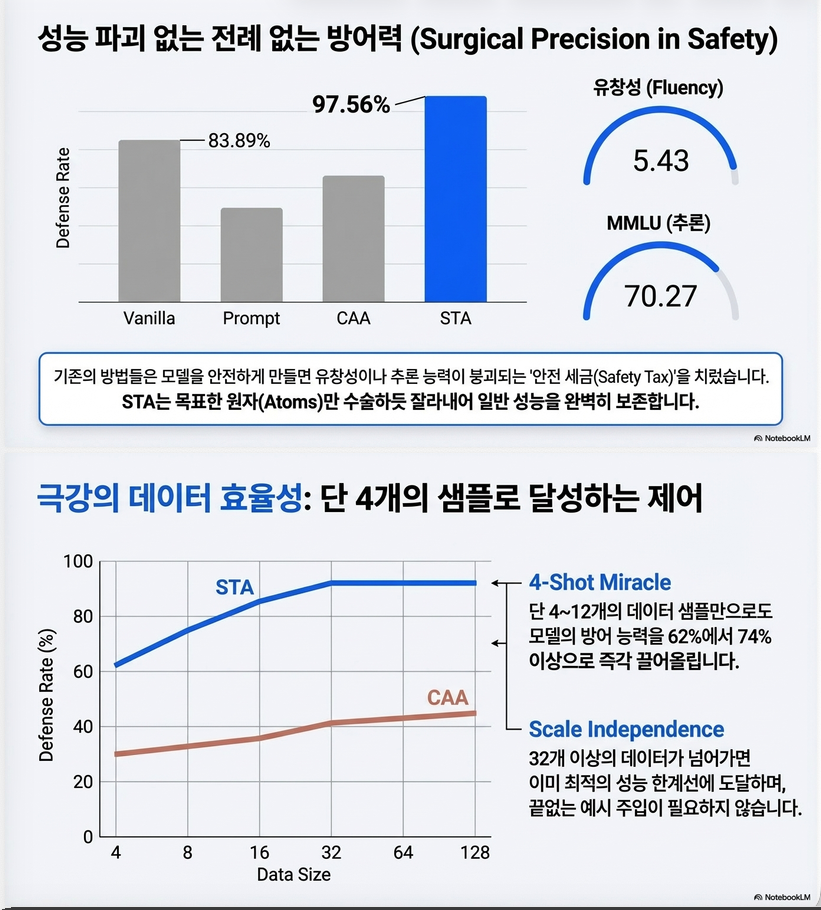
| Gemma-2-9B-pt | STA | 83.45% | 43.9% |
| Gemma-2-9B-it | STA | 97.56% | 49.1% |
| Llama-3.1-8B | STA | 72.23% | 33.9% |
- STA는 안전성(Detoxification) 에서 기존 CAA보다 최고 성능을 달성.
- 일반 성능(GSM8K, MMLU) 저하도 매우 미미함.
- 중간층(layers 20~25)에서의 steering이 가장 효과적.
- 소량 데이터(단 4~32 샘플)로도 robust steering vector 생성 가능.
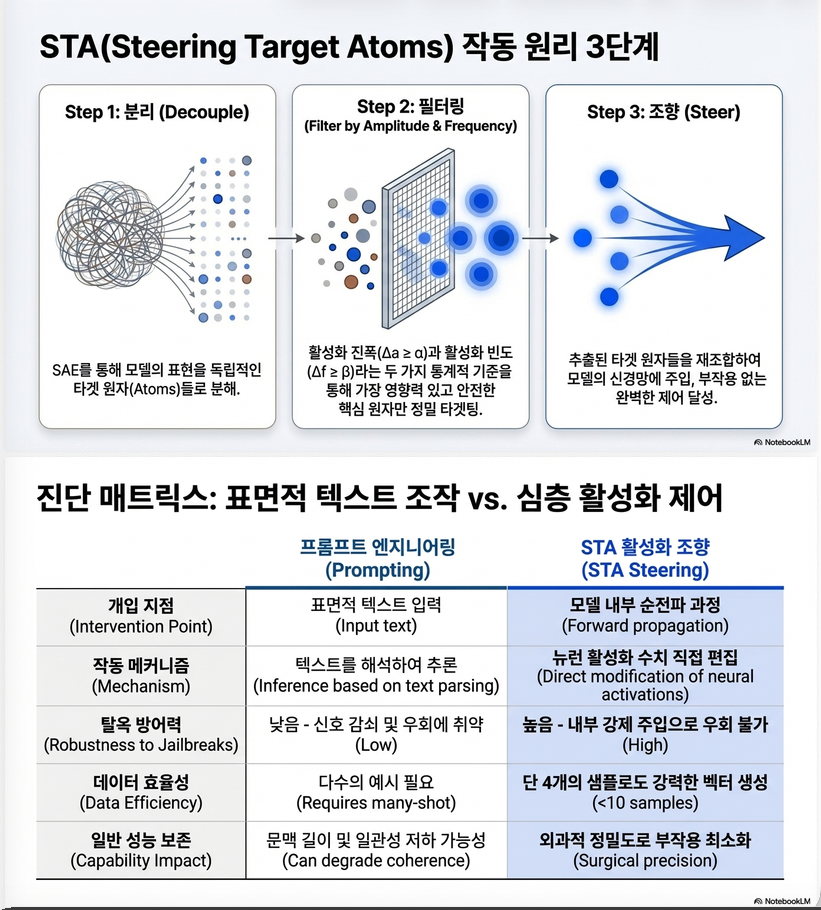
프롬프트 엔지니어링 vs Steering
| 비교 항목 | Prompting | Steering (STA) |
|---|---|---|
| 조작 단위 | 텍스트 입력 | 내부 활성값 |
| 해석가능성 | 낮음 | 높음 |
| 민감도 | 높음 (입력 변화에 취약) | 낮음 (layer-level 조정) |
| 제어 강도 | 제한적 | λ로 정밀 제어 가능 |
| 부작용 | 예측 어려움 | SAE로 최소화 |
| 변환 가능성 | STA로 벡터화 가능 | – |
- STA는 프롬프트를 벡터로 변환(“STAprompt”)할 수 있으며,
이렇게 만든 벡터는 원래 프롬프트보다 더 높은 안전성 유지율을 보임. - Layer-level 제어를 통해 공격적 프롬프트(jailbreak) 에도 강한 내성을 보임.
추가 실험: Reasoning Length 제어
- DeepSeek-R1 모델의 Chain-of-Thought 길이를 steering으로 조절.
- λ 값을 조절하면 추론 길이(token 수) 를 확장하거나 축소 가능.
→ 즉, “LLM이 얼마나 생각할지” 도 제어할 수 있음.
결론 및 의의
STA는 LLM의 행동을 안전하게, 정밀하게, 그리고 강건하게 제어할 수 있는 새로운 패러다임.
- SAE 기반 disentanglement을 활용하여 의미적으로 분리된 Target Atom을 찾아내고,
- 해당 atom을 조작해 LLM의 출력 방향을 steer.
- 프롬프트보다 안정적이며, layer-level fine control 가능.
- 향후 연구 방향:
- personality, multi-turn dialogue, reasoning domain으로 확장
- public SAE 부족 문제 해결 (예: R1-SAE 공개 예정)
논문의 방법론(Method) 부분을 공식·절차·의도까지 모두 포함해 정리합니다.
STA 방법론의 핵심 목표
LLM 은닉표현에는 여러 의미가 겹쳐(superposed / polysemantic) 있어서 특정 행동(예: 안전한 출력, 바람직한 성격, 짧은 추론)을 제어하기 위해 내부 activations을 조정하면 부수 효과(side effects) 가 발생합니다.
따라서 STA의 목표는:
모델 내부 표현을 SAE 기반으로 분해(disentangle)하여, “원자적 지식 단위(Target Atoms)”만 선별·조작함으로써 부작용 없이 행동을 조절하는 것.
STA 전체 Pipeline 요약
(1) Hidden states 수집 (positive vs negative pairs)
↓
(2) SAE로 latent activation으로 투영
↓
(3) 각 atom의 amplitude & frequency 차이 계산
↓
(4) 임계값 기준을 만족하는 Target Atoms 선별
↓
(5) Target Atoms를 decoder 공간으로 역투영 → Steering Vector 생성
↓
(6) Inference 중 특정 layer에서 hidden state에 Steering Vector 적용
Step 1 — Positive / Negative 활성 수집
LLM이 원하는 행동을 수행한 경우를 positive
원하지 않는 행동을 수행한 경우를 negative 로 두고,
예시:
| Task | Positive | Negative |
|---|---|---|
| Safety | 안전한 답변 | 유해한 답변 |
| Personality | 사려 깊은 응답 | 탐욕적·권력 추구 응답 |
| Reasoning | 짧은 CoT | 불필요하게 긴 CoT |
하나의 질문 ( q_i ) 에 대해 두 응답을 구성:
(q_i + x_i_pos) → positive activation
(q_i + x_i_neg) → negative activation
Step 2 — SAE를 통해 latent atom space로 분해
LLM 은닉상태 ( h ) 를 고차원·희소 latent space 로 투영:
여기서:
- = latent atoms (수천~수만 차원)
- 각 원소 = 하나의 atom activation
- SAE는 재구성 손실 + L0 sparsity 로 학습됨
SAE는 LLM 내부 표현을 다음 선형 결합으로 설명한다고 가정:
즉, = atom direction.
Step 3 — Amplitude & Frequency 비교
positive와 negative 응답의 평균 token activation을 사용:
Activation 등장 빈도 비교:
즉,
- Δa가 높다 → positive에서 더 강하게 발화되는 atom
- Δf가 높다 → positive에서 더 자주 등장하는 atom
Step 4 — Target Atoms 선택
두 기준 모두 만족하는 atom만 선택:
→ 이는 SAE 공간에서 부수 효과를 유발하지 않는 핵심 방향만 선택한다는 의미.
Step 5 — Steering Vector 생성 (역투영)
선택된 atom을 decoder 방향으로 다시 맵핑:
해석:
- STA는 기존의 neuron steering 방식(CAA) 과 달리 전체 vector에서 불필요한 차원을 제거하고 의미적으로 선별된 차원만 투사한다.
Step 6 — Inference 중 Forward Pass 조정
Forward 과정 중 특정 층 (중간~후반 잔차 스트림) 에 다음을 적용:
- λ > 0 → positive behavior 강화
- λ < 0 → negative behavior 강화
- λ 크기 → 제어 강도
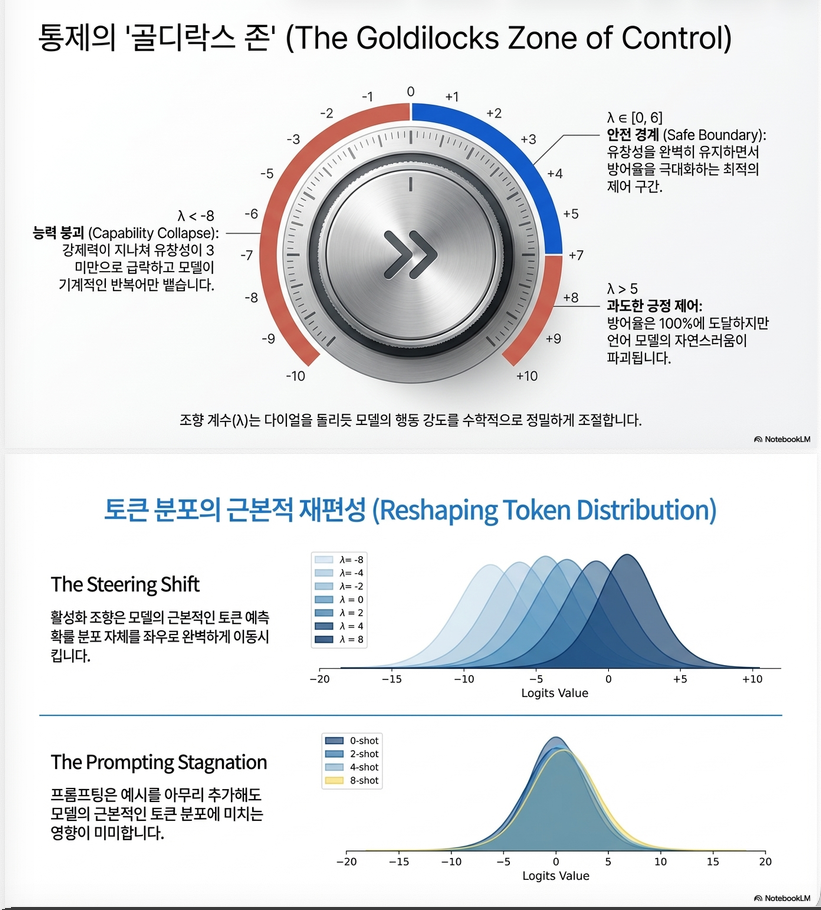
논문에서는 λ ∈ [0, 6] 범위를 안전하고 자연스러운 steering 범위로 제안.
기존 Steering vs STA 차이 정리
| 기능 | 기존 Neuron Steering | STA |
|---|---|---|
| 조정 단위 | 뉴런/차원 | Atom (SAE disentangled feature) |
| 표현 | 얽힌(polysemantic) | 단일 의미(monosemantic 경향) |
| 부작용 | 큼 | 매우 낮음 |
| 데이터 요구량 | 중간 | 4개 sample만으로도 안정적 |
| 정밀 제어 | 어려움 | 매우 높음 |
요약 한 문장
STA는 SAE로 분해된 고차원 모노세만틱 latent atom 중 행동에 의미적으로 기여하는 것만 선택해 steering vector를 만들고, inference 중 은닉상태에 적용하여 적은 부작용으로 매우 정밀한 행동 조정을 달성한다.
논문의 실험 결과를 핵심 지표 + 해석 + 분석까지 자세히 정리합니다.
실험 개요
| 목적 | 평가 항목 | 데이터셋 |
|---|---|---|
| 안전한 행동 제어 | Detoxification 성능 | SafeEdit, RealToxicPrompts |
| 부작용 측정 | 일반 성능 유지 | GSM8K, MMLU |
| 자연스러움 측정 | Fluency | N-gram 기반 |
| 제어력 분석 | Steering·Prompting 비교 | jailbreak 공격 상황 |
| 일반화 분석 | Reasoning 길이 조절 | GSM8K (DeepSeek-R1) |
모델은 Gemma-2-9B-pt, Gemma-2-9B-it, Llama-3.1-8B 3종을 사용함.
주요 결과 요약
STA 성능 요약
STA는 세 모델 모두에서 안전성 제어 성능 1위를 기록했으며, 일반 능력 손실은 최소로 유지.
| Model | Method | Detox ↑ | General ↓ |
|---|---|---|---|
| Gemma-2-9B-pt | STA | 83.45% (1위) | 43.9% |
| Gemma-2-9B-it | STA | 97.56% (1위) | 49.1% |
| Llama-3.1-8B | STA | 72.23% (1위) | 33.85% |
▶ 정리:
- 안전성 향상 폭이 가장 큼
- CAA/SAEAXBENCH 대비 높은 detox, 동일 수준 부작용
Detoxification 실험 (안전성)
STA는 프롬프트 기반 기법보다 확실히 우수,
그리고 기존 steering 기법(CAA, SAEAXBENCH)보다 더 높은 제거율.
– 예시(RealToxicPrompts, Gemma-2-9B-it):
| Method | Detox ↑ |
|---|---|
| PromptHand | 98.42% |
| PromptAuto | 98.92% |
| CAA | 98.75% |
| SAEAXBENCH | 98.42% |
| STA | 99.33% |
→ 거의 완전한 안전성 제어.
2. 일반 성능 영향 (Side Effects)
LLM 안전 제어가 일반 능력을 망가뜨리면 안 됨.
STA는 경미한 하락만 발생.
예시(Gemma-2-9B-it):
| Metric | Vanilla | STA |
|---|---|---|
| MMLU | 72.06 | 70.27 (-1.79) |
| GSM8K | 75.66 | 71.65 (-4.01) |
– 해석
- 안전 제어는 성공
- reasoning 능력 손상은 매우 적음
→ 기존 steering 대비 확실히 안정적
3. Fluency(자연스러움) 유지
STA 적용 시:
- 안전성은 향상
- 문장 자연스러움은 거의 변하지 않음
예시:
| Method | Fluency ↑ |
|---|---|
| Vanilla | 5.39 |
| STA | 5.43 |
– steer를 강하게 걸면(deg λ>6) fluency 저하가 발생하지만, 논문은 λ ∈ [0,6] 구간을 최적 영역으로 제시.
4. Steering Layer에 따른 효과
모든 모델에서 공통 패턴:
중간~후반부 레이어에서 steering이 가장 강력한 효과
Gemma-2-9B-pt 기준:
| Layer | Detox ↑ | Side Effect |
|---|---|---|
| 12~18 | 약함 | 낮음 |
| 20~26 | 최고 | 중간 |
| 28+ | 낮음 | 큼(성능 붕괴 경향) |
– 해석
- 비교적 후반부에서 의미 방향 정보가 안정적으로 분리되기 때문
- 논문 실험에서는 각 모델에 최적 레이어를 고정해 steering 수행
5. Data Efficiency — Few-Shot Steering
데이터가 4개만 있어도 강력한 성능.
| #Data | Detox ↑ |
|---|---|
| 4 | 62.30 → 74.60% |
| 32 | 지속적 향상 |
| 128 | plateau(상한 도달) |
– 결론
→ Steering vector 생성에 대규모 안전 데이터가 필요 없음
6. Prompt vs Steering Robustness
실험 결과:
| 비교 항목 | Prompting | STA |
|---|---|---|
| jailbreak 공격 내성 | 취약 | 강함 |
| 입력 민감도 | 큼 | 작음 |
| 지시 재해석 | 불안정 | 안정 |
| 제어 강도 | 제한적 | λ로 연속 제어 가능 |
흥미로운 결과:
프롬프트 자체를 STA로 변환(STAᵖʳᵒᵐᵖᵗ) 하면
원래 프롬프트보다 훨씬 강한 안전 제어 성능.
→ 명시적으로 “텍스트 지시”를 “벡터 지시”로 재해석할 수 있다는 의미.
7. 확장 실험 — Reasoning 길이 제어
DeepSeek-R1 reasoning 모델에서 chain-of-thought 길이 제어:
| λ 조절 | 결과 |
|---|---|
| λ > 0 | reasoning 길어짐 |
| λ < 0 | reasoning 짧아짐 |
| λ 매우 큰 값 | 반복·무의미 token 생성 (fluency↓) |
– 중요한 통찰
- 행동 제어(출력 내용)를 넘어서
**“사고 과정 제어(출력 방식)”**로 확장이 가능함
실험 결론 총정리
| STA가 달성한 목표 | 결과 |
|---|---|
| 높은 안전성 | 업계 최고 수준 |
| 낮은 부작용 | ✔ 유지 |
| 강한 제어력 | ✔ λ로 선형 제어 가능 |
| 높은 데이터 효율 | ✔ 4개 샘플로도 가능 |
| jailbreak 대응 | ✔ 매우 강력 |
| 확장 가능성 | ✔ reasoning 제어까지 |
프롬프트 기반 안전 제어를 대체할 수 있는 차세대 방식으로서 매우 유망
논문 안에는 “선택된 target atoms의 개수가 몇 개인가?” 를 고정된 숫자로 명시하지 않습니다.
대신 STA는 임계값 기반(α, β)으로 선택되는 atom 비율을 기준으로 자동 결정되며, 실제 실험에서는 다음 두 가지 기준을 사용했다고 명시되어 있습니다:
| 실험 구간 | 선택 기준 |
|---|---|
| 메인 실험 (Safety·Detoxification) | 상위 35% 위치의 α, β 값 사용 |
| Prompt → Steering 변환 실험 | 상위 4% 위치의 α, β 값 사용 |
즉, 원문 표현을 정리하면:
target atom의 개수를 고정한 것이 아니라
Δa(Amplitude)와 Δf(Frequency)의 상위 percentile 위치를 임계값으로 설정해
조건을 만족하는 atom을 variable-size set으로 선택.
→ 따라서 모델/층마다 선택되는 atom의 개수가 달라짐.
실제 규모 추정 (논문 실험 기준)
논문에 따르면 다음 SAE 모델들을 사용:
- Gemma-2-9B-pt: layer 24 SAE
- Gemma-2-9B-it: layer 20 SAE
- Llama-3.1-8B: layer 20 SAE
해당 SAE들은 수천~수만 차원의 atom(feature) 을 가짐.
따라서 선택 비율로 환산 시 대략적인 수량 범위는:
| 퍼센타일 | Atom 비율 | 예상 선택 개수(대략) |
|---|---|---|
| 상위 35% | 0.35M | 수백 ~ 수천 개 |
| 상위 4% | 0.04M | 수십 ~ 수백 개 |
즉:
- 안전성 실험에서는 꽤 넓은 스펙트럼의 feature를 포함하여 steering
- 프롬프트→steering 변환 실험에서는 매우 협소한 핵심 feature만 선택
왜 개수를 고정하지 않았는가?
논문에서 STA가 기존 steering 기법과 차별화되는 이유 중 하나가 바로 이것입니다:
개수를 미리 정하는 것이 아니라
Δa + Δf 통계 기반으로 의미 있는 atom만 남기므로
모델·태스크·층 구조에 자동 적응 (adaptive)
즉 고정된 top-k 방식(예: k=100) 이 아니라
확률적 활성 패턴 기반의 의미적 선택입니다.
정리
| 질문 | 답변 |
|---|---|
| “선택된 Target Atoms 개수는?” | 고정값이 아니라 Δa, Δf 기반으로 자동 결정 |
| “실험에서는 대략 몇 개?” | Safety 실험: 수백~수천 개, Prompt 변환 실험: 수십~수백 개 |
| “왜 개수를 공개하지 않았나?” | STA는 절대 개수보다 의미 기반 선택을 강조하기 때문 |
답글 남기기