
아래는 ACL 2025 논문 “Position-aware Automatic Circuit Discovery (PEAP)” 전체 내용을 기반으로 한 논문 설명입니다.
Position-aware Automatic Circuit Discovery — 논문 전체 설명
1. 논문 문제의식 (Why?)
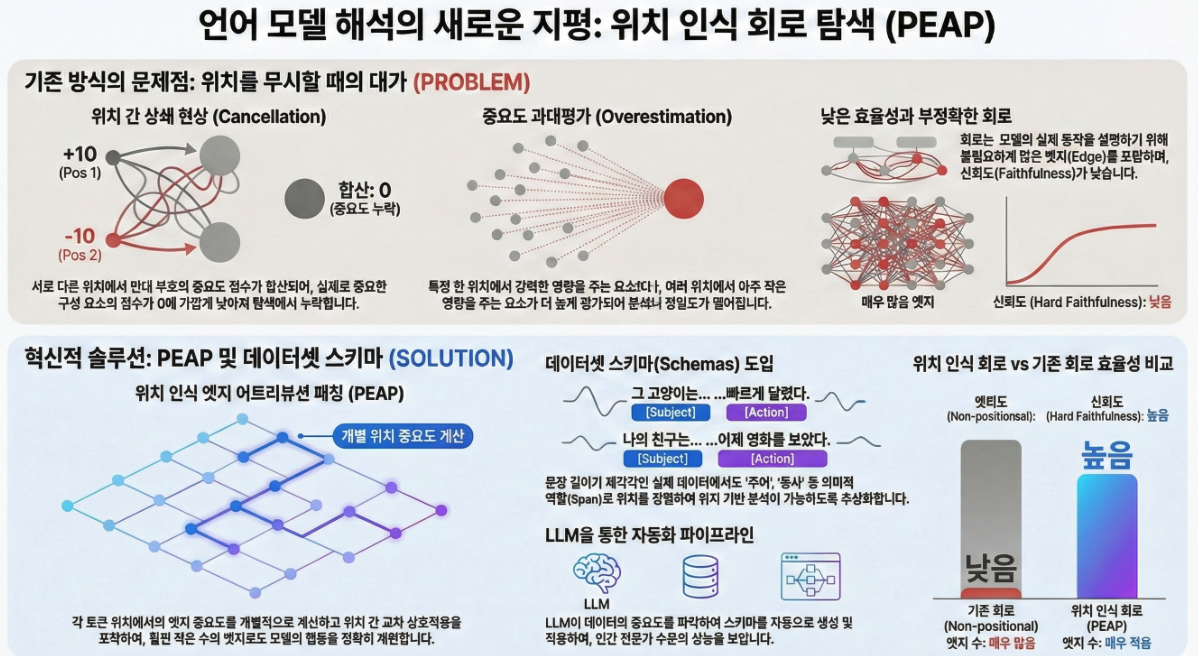
기존 자동 circuit discovery 기법(EAP, direct patching 등)은 “position-invariant” 가정을 한다.
즉,
- 어떤 attention head 또는 FFN이 한 번 포함되면 모든 토큰 위치에서 동일하게 포함된다고 가정함
- cross-position interaction(예: position t의 head가 position t′의 head에 미치는 영향)을 회색 처리
- 서로 다른 위치에서의 효과를 합산(summing across positions)하면서 중복/소거(cancellation) 발생 → Figure 2에서 명확히 보임:
- 한 위치에서 매우 중요한 edge라도 다른 위치의 음/양향 영향이 합산되면 중요도가 사라짐.
이로 인해
- Recall 낮음: 중요한 edge가 cancel됨
- Precision 낮음: 모든 위치에서 조금씩 영향을 주는 edge가 과대평가됨
- Circuit이 불필요하게 커지고, 정확도(faithfulness)도 낮아짐
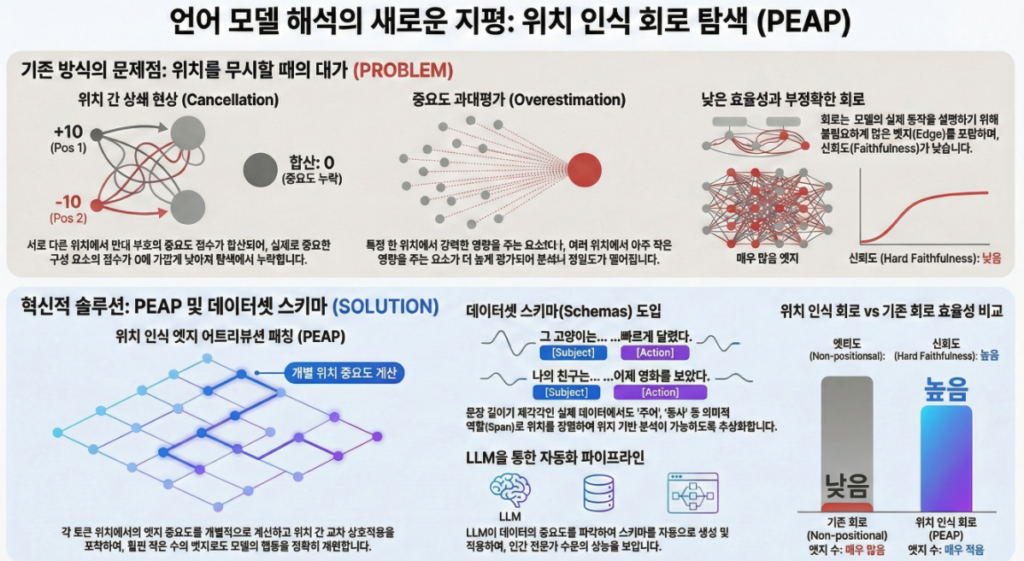
이 문제를 해결하기 위해 저자들은 **“Position-aware Edge Attribution Patching (PEAP)”**을 제안한다.
2. 제안 핵심 기여 (What?)
(1) PEAP: 위치 의존적 Edge Attribution 방식 도입
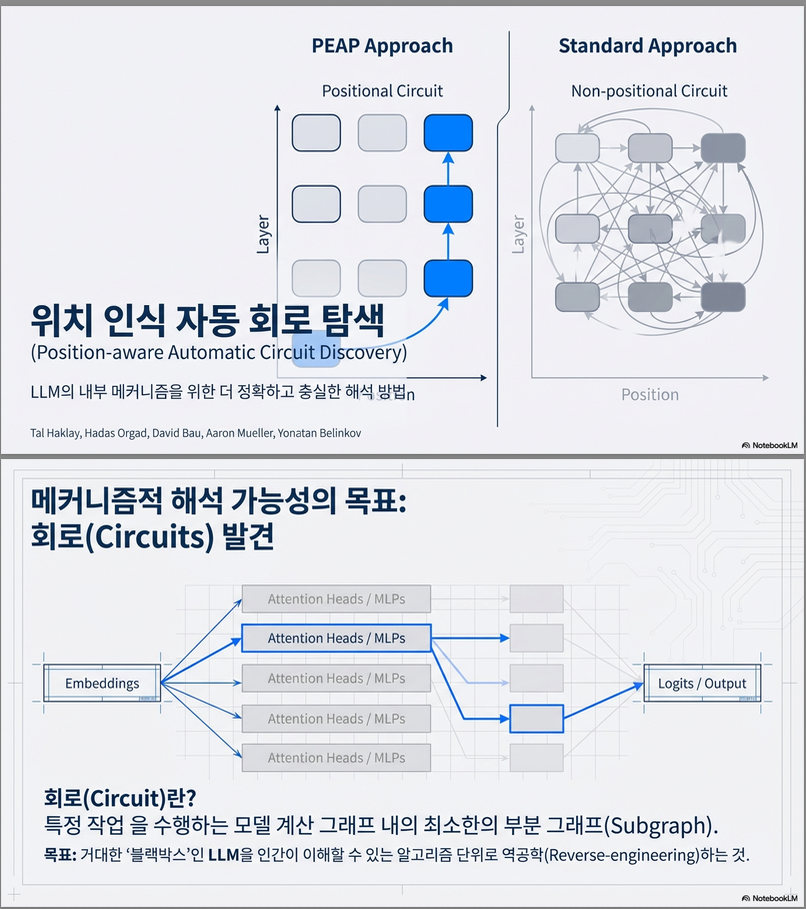
- 기존 EAP는 **동일 위치 내 edge (u→v)**만 고려
- PEAP는 **attention head 사이의 cross-position edge (value/key/query dependencies)**까지 고려
- 각 위치별(edge, position pair)별 중요도를 독립적으로 계산 → cancellation·overestimation 문제를 제거
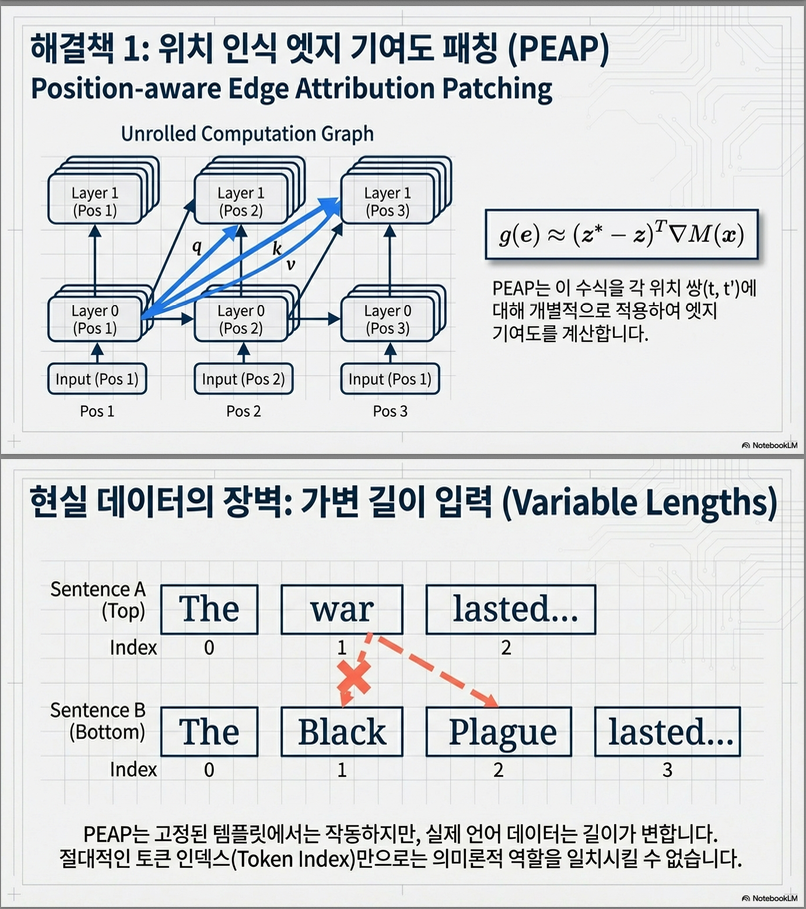
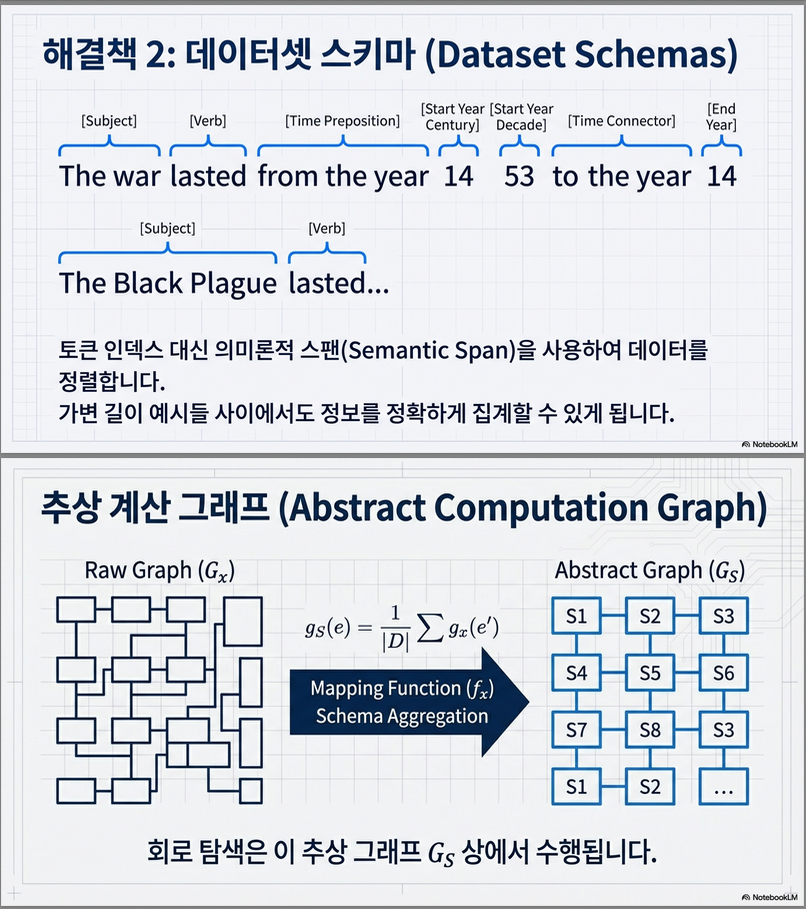
(2) Schema: Variable-length 입력에서 위치 정렬을 자동화하는 새로운 구조
대부분의 데이터셋(IOI, Winobias 등)은 예시마다 길이가 다르고 의미 구조도 다르기 때문에 “position” 자체가 고정적일 수 없다.
그래서 논문은 Schema 개념을 도입:
예시:
| 문장 조각 | Schema span |
|---|---|
| “The war lasted …” | SUBJECT |
| “from 1453 to 14” | START-YEAR, END-YEAR |
→ 예시마다 token 개수는 다르지만, 동일한 semantic 역할을 하는 span을 정렬할 수 있음
→ Variable-length 입력에서도 position-aware 회로 탐색 가능
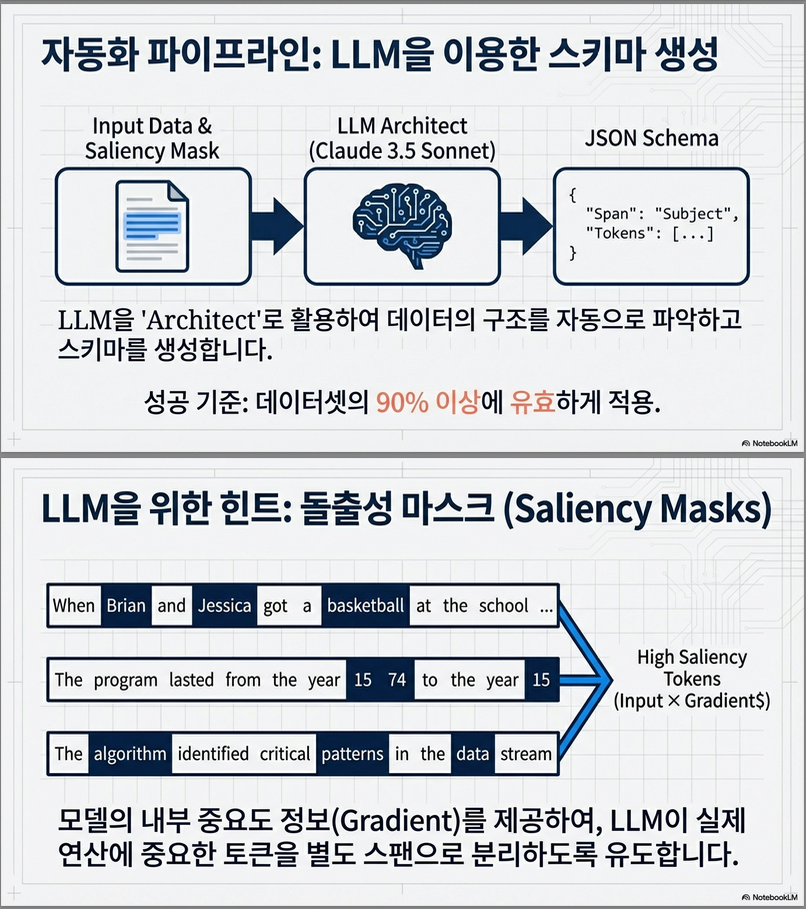
(3) LLM 기반 자동 Schema 생성·적용 파이프라인
- Claude 3.5 Sonnet을 활용해 schema 자동 생성
- 토큰 saliency(mask) 정보를 LLM에게 제공하여 → “모델이 실제로 중요하게 사용하는 위치”에 대한 정보를 기반으로 schema 설계
- manual schema와 유사하거나 더 좋은 faithfulness를 달성
3. PEAP 방법론 상세 (How?)
기존 EAP 공식
Edge e = (u→v)의 indirect effect:
PEAP의 차별점은:
✔ cross-position attention edge
의 attribution을 직접 근사
Figure 3 참고.
각 attention head 에 대해 value/key/query patching 시 output 변화를 계산.
수식 예(논문 Eq. 4–6):
- value patching:
- key patching
- query patching
이렇게 얻은 와 gradient를 내적하여 attribution score 산출.
결과적으로 다음을 포함한 새로운 “positional circuit” 생성 가능:
- 동일 head라도 t=5에서는 포함, t=1에서는 제외
- 특정 cross-position edge (예: head L3.H7 position t→t-1)만 선택
4. Schema 기반 Circuit Discovery (Variable-length 입력)
핵심 아이디어
- 예시마다 길이가 달라도, 모든 예시가 공유하는 semantic structure는 존재한다.
- → 이를 “schema span”으로 정리
- → 각 span을 하나의 abstract position으로 mapping
- → 모든 예시의 computation graph를 같은 “abstract graph”로 정렬 Figure 5 참고.
3단계 절차
- 각 예시 x에서 원래 Gₓ에서 edge score 계산
- schema 매핑 함수 f_x로 abstract edge e에 대응되는 원래 edge 집합 f_x(e)을 찾음
- 모든 예시에서 평균 내어 abstract graph 에 대한 산출:
- greedy algorithm으로 abstract circuit 선택
- 평가 시 다시 원래 Gₓ로 펼쳐서 circuit 구성
5. 실험 결과 (GPT2-small, Llama-3-8B)
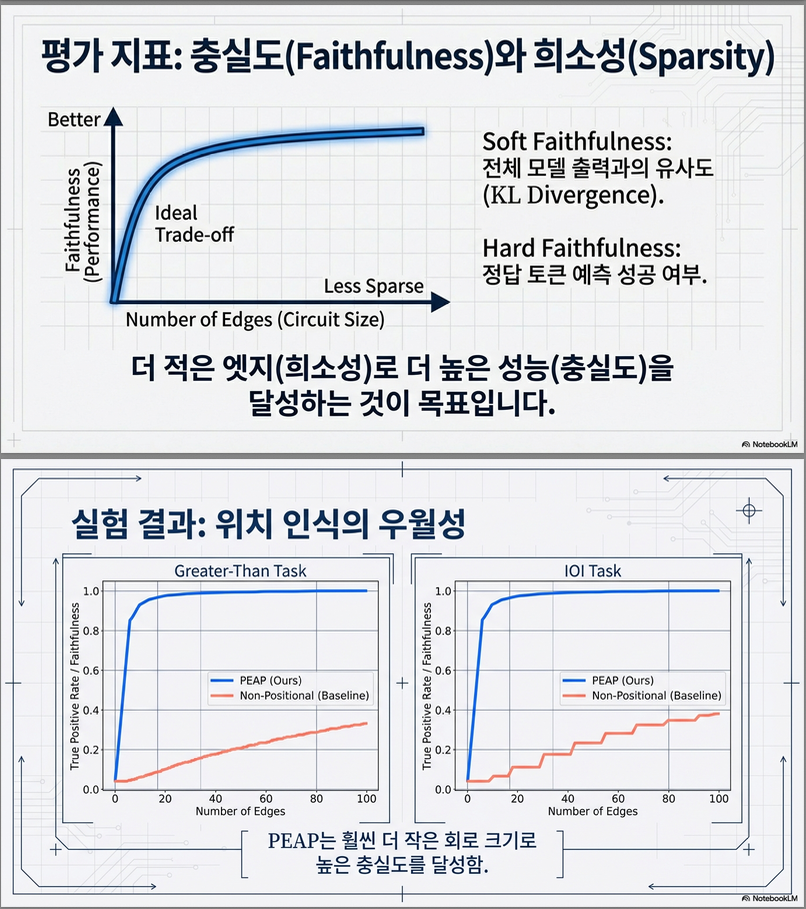
평가 지표
- Soft faithfulness:
- Hard faithfulness: 정답 토큰 동일 여부 Figure 6에 다양한 task 결과가 제시됨.
주요 결과
✔ Position-aware circuits는 non-positional circuits보다
훨씬 작고 훨씬 정확함
- 기존 방식은 수천 개 edges 필요
- PEAP는 수백 개 이하로 동일 faithfulness 달성
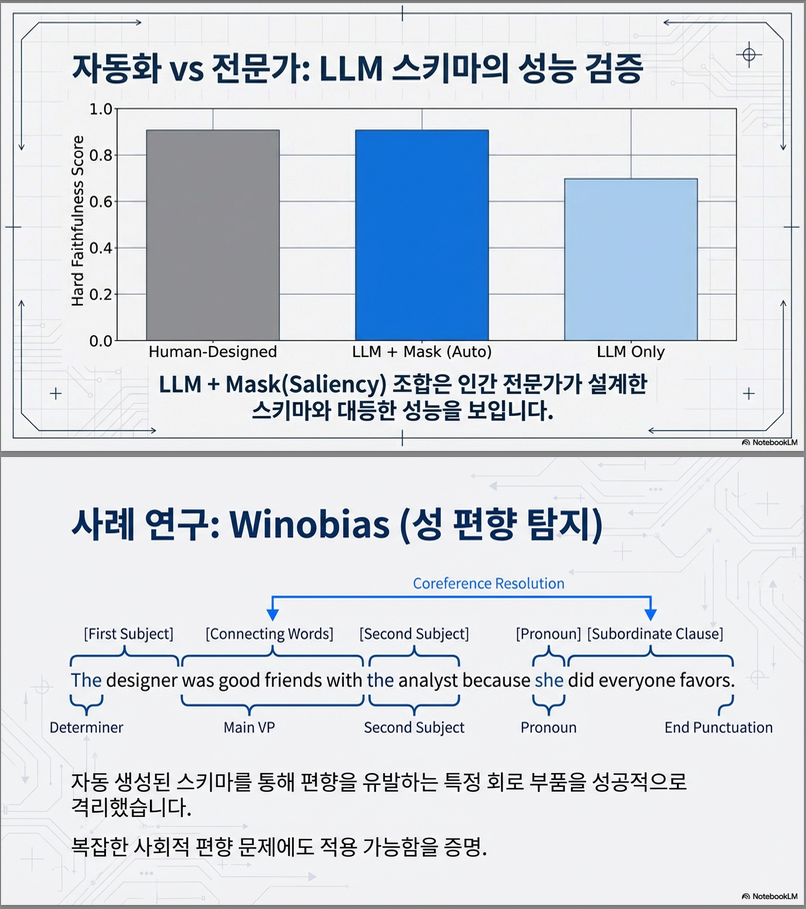
✔ LLM+saliency mask 기반 자동 schema는 human schema와 동급 또는 더 우수
특히:
- Greater-Than: human ≈ LLM+mask ≫ LLM-only
- IOI(Llama-3-8B): LLM+mask가 human보다 faithfulness 더 좋음
- Winobias: 자동 schema도 높은 성능
논문 결론:
자동 schema + PEAP 조합은 사람 전문가가 만든 회로 구조를 완전히 대체 가능하며, 오히려 더 좋은 회로를 찾을 수도 있다.
6. 논문의 의미 (Interpretability 측면)
- Transformer 계산 구조는 위치에 따라 크게 다르다
- 그럼에도 기존 자동 기법은 모든 위치에서 동일한 mechanism이라고 가정해 오류 발생
- 실제로 cross-position interaction(head-to-head)이 중요한 경우가 많다
- PEAP는 최초로 완전 자동 position-aware circuit을 실현
- schema 개념은 앞으로의 interpretability 연구에서 “variable-length 데이터 정렬” 문제를 크게 해결할 핵심 도구가 될 가능성이 큼
요약 한 줄
이 논문은 LLM 내부 메커니즘 분석에서 “position” 차원을 본격적으로 도입함으로써, 기존 회로 분석의 근본적 한계를 돌파한 첫 자동화 프레임워크이다.
논문에서 정리한 **관련 연구(related work)**는 크게 세 가지 축으로 나눌 수 있습니다.
전반적인 관련 연구 논의는 Appendix A “Related Work”와 서론/배경에서 흩어져 있습니다.
1. 기존 자동 position-aware 시도들
논문이 직접 겨냥하는 건 “위치까지 고려하는 자동 회로 발견”인데, 저자들은 이미 몇 가지 선행 연구가 position을 다루긴 하지만 한계가 뚜렷하다고 정리합니다.
1-1. Kramár et al. 2024 — AtP*
- 무엇을 했나?
- Edge Attribution Patching(EAP; Syed et al., 2023)의 변형인 **AtP***를 제안.
- 목적: LLM 행동을 “노드 단위 + 위치별”로 로컬라이즈하는 것.
- 한계 (이 논문 기준):
- 템플릿 기반, 완전히 정렬된(fully aligned) 데이터셋에서만 평가됨.
- 회로(circuit) 자체를 찾는 데 사용되지 않았음 — 즉, “중요한 node/edge를 찾는다” 수준이고, 이 논문처럼 faithfulness–size trade-off를 갖는 서브그래프 전체를 구성하지 않음.
→ 이 논문: AtP*처럼 위치는 보지만,
- edge 수준으로,
- 실제 circuit을 구성하고,
- variable-length + 비정렬 데이터셋까지 다룸.
1-2. Marks et al. 2025 — Sparse Feature Circuits
- 무엇을 했나?
- Sparse Feature Circuits framework: SAE 기반 feature를 node로 보고, 여기에 token position을 포함하는 회로를 구성.
- 마찬가지로 템플릿 기반, fully-aligned 데이터셋에서만 실험.
- 이 논문이 비판하는 점:
- node-level faithfulness만 보고 edge-level은 보지 않음.
- 하지만 Ge et al. (2024)은 edge-level circuit이 task 회로를 더 잘 포착한다고 보고.
- “edge” 정의가 완전히 다름:
- Sparse Feature Circuits에서 edge는 “노드 효과를 outgoing edges에 분산시키는 추상 객체”
- 실제 computation graph 상에서 연결돼 있지 않아도 “경로(path)”를 edge라고 부름.
- 이 논문은
- 진짜 연산 그래프 상에서 u→v가 직접적으로 영향을 주면 edge로 간주하는, 더 직관적/구조적 정의 사용.
- node-level faithfulness만 보고 edge-level은 보지 않음.
→ 즉, Sparse Feature Circuits는 feature space에서의 추상 경로, 이 논문은 실제 연산 그래프의 물리적 edge에 집중.
1-3. Ge et al. 2024 — SAEs + Transcoders 기반 회로
- 무엇을 했나?
- Sparse Autoencoder(SAE) + Transcoder를 이용한 회로 발견 파이프라인을 제안.
- 여기서도 token position을 고려하는 구조를 포함.
- 이 논문과의 차이점:
- 회로 발견 방법:
- Ge et al.: SAE/Transcoder 기반
- 본 논문: PEAP(position-aware EAP) 기반
- 평가 범위:
- Ge et al.: **아주 적은 예시(cases)**에 국한, 스코프가 좁음.
- 이 논문: 3개 task, 각 500 예시, sequence length도 다양, GPT-2 Small + Llama-3-8B 등 서로 다른 규모 모델로 평가.
- 비정렬 데이터 처리:
- Ge et al.: 주로 정렬/단순 설정
- 이 논문: LLM으로 schema를 자동 생성해서 unaligned dataset까지 처리하는 것이 핵심 기여.
- 회로 발견 방법:
2. 기존 automatic circuit discovery (position 무시)
이 논문이 직접 확장하는 핵심 계열은 **“Edge Attribution Patching 계열 자동 회로 발견”**입니다.
2-1. Conmy et al. 2023, Syed et al. 2023, Hanna et al. 2024b
- Conmy et al. 2023:
- Direct activation patching + greedy로 자동 회로를 추출.
- Syed et al. 2023 (EAP):
- 직접 patching이 너무 비싸기 때문에,
- gradient 기반 linear approximation (Edge Attribution Patching) 도입.
- 이 논문이 PEAP에서 바로 확장하는 기반 수식.
- 직접 patching이 너무 비싸기 때문에,
- Hanna et al. 2024b:
- 회로의 faithfulness를 측정할 때 단순 overlap 대신 실제 성능(soft/hard faithfulness)을 강조하는 평가 프레임워크 제안.
본 논문 관점의 문제점:
- 모두 token position을 완전히 무시
- edge 중요도를 position별로 나누지 않고, 전체 위치에 대해 합산 → cancellation (서로 다른 위치에서 부호가 다른 기여가 상쇄) & → overestimation (많은 위치에서 약간씩 기여하는 edge 과대평가) 문제 발생. Figure 2 / Table 1이 그 사례.
3. 수동(manual) 회로 발견 & position-aware 분석
자동화 이전에, 수동 회로 분석은 이미 position을 매우 중요하게 다루고 있었다는 점도 논문에서 언급합니다.
대표 예시:
- Wang et al. 2023 — IOI 회로
- 레이어별 attention 패턴을 보고, IO, S1, S2, End 같은 역할(role)을 정의해 수작업으로 회로 구성.
- Hanna et al. 2024a — Greater-Than 회로
- Goldowsky-Dill et al. 2023 — Path patching 기반 local circuit 분석
이들은
- 위치별 역할 토큰을 직접 정의하고
- attention 패턴을 눈으로 보고 어느 head가 어느 위치에서 어떤 역할을 하는지 수동으로 추적.
한계 (이 논문 관점):
- Scalability 부족 — 사람이 일일이 head/position을 살펴야 함
- 편향(bias) 가능 — 인간이 눈에 보이는 strong attention만 보고 회로를 구성
- strong attention = 실제 causal 효과인지 보장되지 않음 (Jain & Wallace 2019 비판 인용).
→ 이 논문은
- 수동 방법이 보여준 “position-aware 회로가 중요하다”는 인사이트를 계승하면서,
- 자동 + 대규모 + faithfulness 정량 평가까지 확장한 연구로 자신을 위치시킴.
4. 이 논문이 전체 landscape에서 차지하는 위치
정리하면, 관련 연구 대비 이 논문의 포지션은:
- AtP*, Sparse Feature Circuits, SAE+Transcoder
- 이미 position-aware 요소를 도입했으나
- 템플릿 기반 / fully-aligned / 소규모 예시 / node-level 위주
- 회로 정의·edge 정의·평가 지표 측면에서 제한적.
- EAP 계열 자동 회로 발견
- 매우 실용적이지만 position 무시, cancellation/overestimation 문제.
- 수동 회로 분석(IOI, Greater-Than, Path Patching 등)
- position을 잘 활용하지만, 자동화·scaling 불가.
이 논문:
- EAP를 position-aware edge 수준으로 확장(PEAP)
- variable-length & unaligned dataset까지 처리하기 위해 schema + LLM 기반 자동 생성 도입
- edge-level faithfulness–size trade-off를 대규모 실험으로 정량 검증
- 결과적으로,
- “위치를 고려하는 자동 회로 발견” 분야에서
- 템플릿/소규모/노드 위주 → 실제 task·모델·데이터셋 수준의 edge-level 회로로 스케일업한 첫 시스템에 가깝다.
아래는 ACL 2025 Position-aware Automatic Circuit Discovery 논문의 방법론(Method) 전체를 정리한 내용입니다.
방법론(Method)
전체 개요
논문의 방법론은 크게 두 축으로 구성된다:
- PEAP (Position-aware Edge Attribution Patching)
- 기존 EAP를 “위치 의존(position-aware)” & “cross-position attention edge”까지 확장한 기법
- 목적: token 위치별 edge의 causal contribution을 분리하여 회로를 구성
- Schema 기반 Position-aware Circuit Discovery (Variable-length 입력 지원)
- variable-length, non-templatic dataset에서도 position-aware 회로를 만들 수 있도록
- 입력을 의미적 span 단위로 재정렬하는 “schema” 개념을 도입
- LLM 기반 automatic schema generation & application 포함
아래에서는 두 기법을 각각 상세히 설명한다.
1. Position-aware Edge Attribution Patching (PEAP)
기존 EAP(Syed et al., 2023)는:
- edge e = 의 indirect effect(IE)를
- direct causal intervention을 gradient 기반 linear approximation으로 계산:
단, 이는 “u와 v가 동일 token 위치에 있을 때만” 정의된다.
즉, cross-position attention edge를 다루지 못한다.
PEAP는 바로 이 한계를 해결한다.
1.1 Transformer 내 edge 정의 확장
Transformers에서 attention head 는 다음과 같은 구조적 연결을 갖는다:
- Query (단일 위치 t)
- Keys
- Values
즉:
따라서 PEAP에서는 다음 세 가지 cross-position edge 유형을 모두 개별 edge로 취급한다:
- Value edge :
- Key edge :
- Query edge :
이때 각 edge를 패치(patching)하여 causal contribution을 계산한다.
이 과정은 Figure 3에 시각화되어 있다.
1.2 Cross-position patching 수식
(1) Value patching (Eq. 4)
(2) Key patching (Eq. 5)
(3) Query patching (Eq. 6)
각각은 “단일 v/k/q vector를 counterfactual 값으로 교체했을 때 head output이 어떻게 변하는지” 평가하는 과정이다.
1.3 Attribution 계산
cross-position edge e의 importance:
→ 이로써 **모든 position pair (t′→t)**에 대해 edge-level causal score를 계산 가능.
이는 기존 EAP가 가지는 **cancellation & overestimation 문제(Figure 2)**를 해결한다:
- 위치별 score를 별개로 관리하므로 cancellation이 없다.
- 모든 위치에서 약하게 기여하는 edge의 과대평가도 사라진다.
1.4 회로 구성 알고리즘 (Greedy Edge Selection)
논문은 기존 Hanna et al. (2024b)의 greedy 절차를 확장하여 사용한다.
절차 요약:
- 모든 edge에 대해 g(e) 계산
- edge를 중요도 순으로 정렬
- 작은 집합부터 시작하여 점진적으로 edge를 추가
- soft/hard faithfulness 기준을 보면서 가장 작은 subgraph를 찾음
출력:
→ position-aware circuit C, 즉 특정 edge(e, t′→t)가 포함될 수도 있고 제외될 수도 있음.
2. Schema 기반 Circuit Discovery (Variable-length 입력 처리)
PEAP는 position-aware이므로, 예시 간 position alignment가 필요하다.
그러나 실제 데이터(IOI, Winobias 등)는:
- 길이가 다름
- 구문 구조가 다름
- 특정 위치의 토큰이 예시마다 의미가 다름
→ 단순 “position index(t)” 기반 회로 발견은 불가능.
그래서 논문은 Schema라는 새로운 개념을 도입한다.
2.1 Schema 정의: 의미 기반 position abstraction
Schema는 입력 예시를 다음과 같은 semantic span으로 재구성한다:
예: IOI
- Person-A1
- Person-A2
- Verb phrase
- Person-B
- Target location (end-of-prompt)
예: Greater-Than
- Subject
- Year-start-first-two-digits
- Year-start-last-two-digits
- Year-end-prefix
- Answer slot
Schema는 다음 조건을 만족한다:
- 모든 예시에서 같은 순서로 나타남
- 각 span은 연속된 토큰 구간
- 예시마다 길이는 달라도 역할은 동일
이 스키마 구성의 예시는 Figure 4에 나타난다.
2.2 Schema-level Graph 구성
각 예시마다 원래 computation graph 가 있다.
Schema S는 k개의 span을 가진다고 하자.
다음과 같이 **abstract computation graph **를 만든다:
- k개의 위치만 존재
- 각 span에 해당하는 모든 token positions을 하나의 abstract position에 매핑
- 원래 edge(e)의 score들을 해당 abstract edge()에 sum/avg하여 할당
공식:
여기서 : 예시 x에서 schema edge e에 대응하는 실제 edge들의 모음 (Eq. 7).
2.3 Schema Circuit → 원래 Circuit으로 되돌리기
abstract circuit 를 구성하면, 각 예시에 대해 이를 다시 원래 위치로 매핑하여:
→ 즉, abstract circuit이 선택한 span-level edge에 대응하는 모든 실제 token-position edge를 회로에 포함.
Figure 5 참고.
이로써 variable-length 데이터에서도 position-aware 회로를 만들 수 있게 된다.
2.4 Schema 자동 생성 (LLM 기반)
핵심 아이디어:
사람이 schema를 만들지 않아도, LLM이 입력 데이터를 읽고 의미 기반 span을 설계하도록 한다.
절차:
- 데이터의 일부 subset을 LLM에게 제공
- LLM에게 span 목록을 설계하도록 지시
- spans must be sequential
- must cover all tokens
- must appear in same order across examples
- 세 가지 다른 subset으로부터 schema 3개 생성 → LLM이 unify하여 final schema 생성
- validity check(>=80%) 실패 시 재생성
논문은 Claude 3.5 Sonnet이 가장 잘 작동한다고 보고한다.
2.5 Saliency 기반 Schema 강화
LLM schema가 model의 실제 causal 구조와 어긋날 수 있으므로,
논문은 token-level saliency mask를 첨부하여 schema 설계를 보조한다.
토큰 saliency:
softmax-normalized saliency가 평균보다 큰 위치는 mask=1, 그 외는 mask=0:
LLM은 이 mask를 토대로 “중요한 위치는 별도의 span으로 나눠야 함”을 학습하게 된다.
3. 방법론 전체 흐름 요약 (End-to-End Pipeline)
아래는 논문의 전체 방법론을 한 번에 정리한 End-to-End 알고리즘이다.
Step 1 — Position-aware edge scoring (PEAP)
- 입력 x에 대해 model forward
- 각 attention head 에서
- 모든 에 대해 v/k/q patching
- 각 patching에 대해 계산
- gradient 계산
Step 2 — Dataset-wise schema alignment
- LLM이 schema spans 생성
- LLM이 각 예시 x에 schema를 적용 (span 위치 매핑)
- token-level saliency로 schema 품질 강화
Step 3 — Abstract graph construction
- 모든 예시의 edge score를 schema-level edge에 집계
- abstract graph 완성
Step 4 — Greedy circuit selection
- 가장 높은 부터 회로에 추가
- faithfulness 평가
- 최소 edge subset을 찾음
Step 5 — Circuit evaluation on original examples
- 각 예시에 대해 schema-level circuit을 원래 edge로 복원
- soft/hard faithfulness 평가
핵심 요약 (연구 기여 관점)
- PEAP: 최초의 cross-position edge-aware EAP
- Schema: variable-length 입력에서도 position-aware circuit discovery 가능
- LLM-based schema generation: 완전 자동화 가능
- faithfulness–size trade-off가 non-positional 대비 압도적으로 우수 (Figure 6)
답글 남기기