



논문 개요
From Few to Many: Self-Improving Many-Shot Reasoners Through Iterative Optimization and Generation은 long-context LLM에서 many-shot ICL을 단순히 많이 넣는 방식으로 쓰는 것이 최적인가를 분석하고, 더 좋은 예제를 선택(optimize) 한 뒤 그 예제로 다시 reasoning path를 생성(generate) 하는 반복 알고리즘 BRIDGE를 제안한 논문입니다.
핵심 주장은 다음입니다.
many-shot 성능 향상은 모든 예제가 균등하게 기여해서가 아니라, 소수의 매우 영향력 있는 예제가 성능을 지배하는 경우가 많다.
따라서 좋은 예제를 찾고, 그 예제로 더 나은 reasoning examples를 다시 생성하면 many-shot ICL 성능을 더 높일 수 있다.
1. 문제 설정
논문은 reinforced ICL 설정을 사용합니다.
주어진 것은 다음입니다.
- train input
- 정답 label
- 중간 reasoning path는 없음
따라서 LLM이 먼저 train input에 대해 reasoning과 answer를 생성합니다. 그중 정답을 맞힌 예제만 demonstration pool로 사용합니다.
각 demonstration은 다음 형태입니다.
즉, 단순한 input-output pair가 아니라 LLM이 생성한 reasoning path를 포함한 예제입니다.
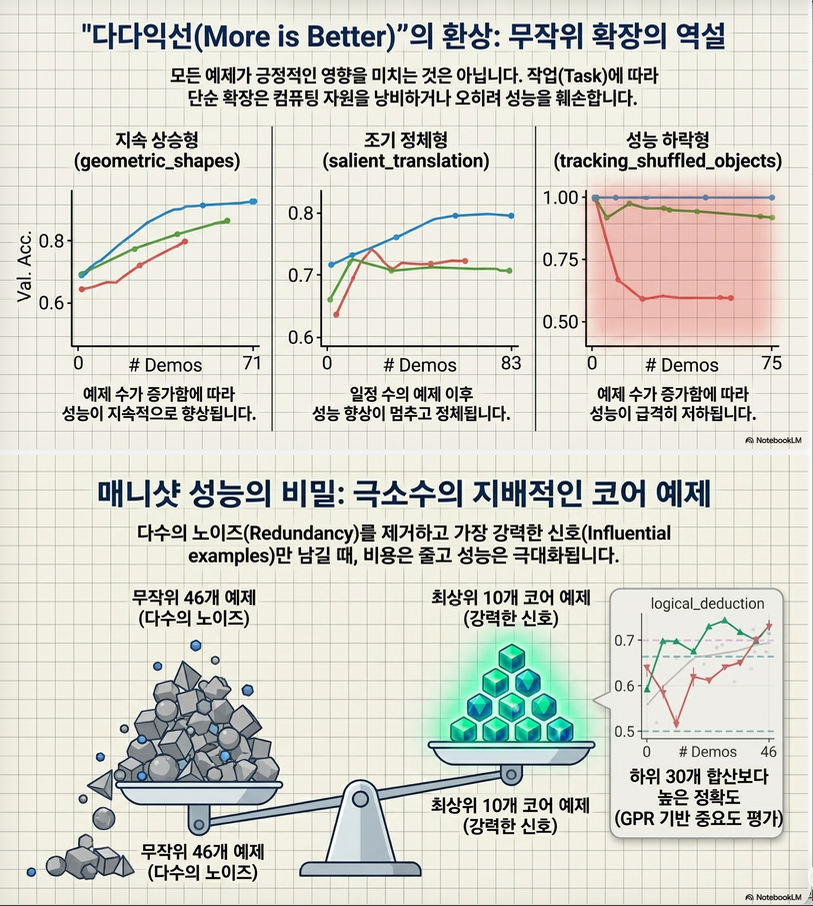
2. Many-shot ICL 분석: 좋은 예제 소수가 성능을 지배
논문은 먼저 many-shot ICL의 성능 향상이 정말 “많은 예제” 때문인지 분석합니다.
예제 집합을
라고 할 때, 어떤 subset 를 context에 넣었을 때 validation accuracy를
g(e)
라고 둡니다.
목표는 다음입니다.
하지만 가능한 subset 수가 이므로 완전 탐색은 불가능합니다.
논문은 이를 위해 **Gaussian Process Regressor(GPR)**를 사용해 g(e)를 근사합니다.
각 subset은 binary vector로 표현합니다.
여기서 1은 해당 예제가 demonstration에 포함됨을 의미합니다.
GPR은 다음 함수를 근사합니다.
그 후 각 예제의 영향도를 input gradient 기반으로 추정합니다.
이 점수가 높은 예제를 top-k, 낮은 예제를 bottom-k로 나눠 성능을 비교합니다.
결과적으로 논문은 다음을 보입니다.
- top-k 예제만 사용해도 전체 many-shot 성능에 근접하거나 초과한다.
- bottom-k 예제는 같은 개수여도 훨씬 성능이 낮다.
- 예제를 많이 넣는 것보다 어떤 예제를 넣는지가 더 중요할 수 있다.
- 많은 예제를 넣으면 오히려 성능이 감소하는 task도 있다.
3. BRIDGE 방법론
논문의 핵심 알고리즘은 BRIDGE입니다.
정식 명칭은:
Bayesian Refinement and Iterative Demonstration Generation for Examples
BRIDGE는 두 단계를 반복합니다.
- Optimize: 좋은 demonstration subset 를 찾음
- Generate: 그 subset을 seed로 사용해 train set의 reasoning examples를 다시 생성함
즉, 전체 구조는 다음입니다.
4. Generate 단계
초기에는 zero-shot 또는 few-shot prompting으로 train set에 대해 LLM을 실행합니다.
이때 정답을 맞힌 예제만 남깁니다.
여기서 는 LLM이 생성한 reasoning path입니다.
이후 optimize 단계에서 찾은 좋은 subset 를 demonstration으로 넣고, 다시 train set 전체에 대해 reasoning path를 생성합니다.
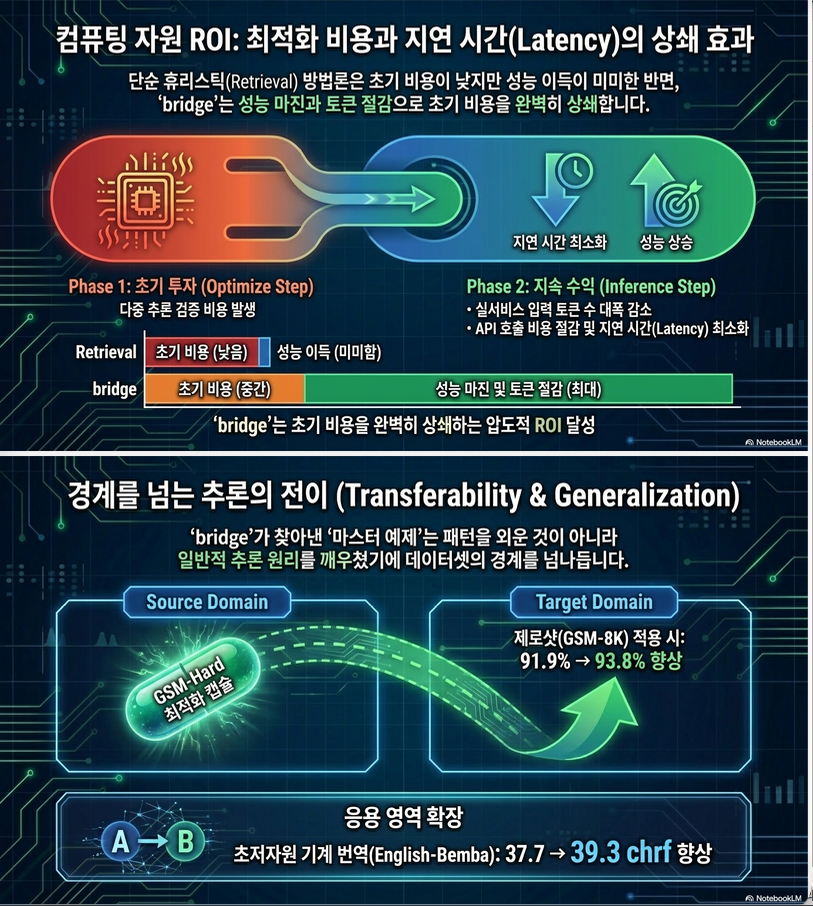
중요한 점은 입력과 정답은 같지만, 중간 reasoning path가 더 좋아질 수 있다는 것입니다. 따라서 단순히 예제를 선택하는 것이 아니라, 좋은 예제로 LLM을 유도해서 더 나은 many-shot examples를 재생성합니다.
5. Optimize 단계: Bayesian Optimization
Optimize 단계는 좋은 를 찾는 문제입니다.
하지만 subset 탐색 공간이 너무 크므로 Bayesian Optimization을 사용합니다.
5.1 초기 random subset 평가
먼저 개의 subset을 무작위로 샘플링합니다.
각 subset을 demonstration으로 사용해 validation set에서 성능을 평가합니다.
이 데이터로 GP surrogate를 학습합니다.
5.2 성능과 sparsity의 bi-objective optimization
논문은 단순히 validation accuracy만 최대화하지 않습니다.
이유는 validation set에 과적합될 수 있고, 너무 많은 예제를 선택하면 다음 generation 단계에서 memorization이 발생할 수 있기 때문입니다.
따라서 objective는 두 개입니다.
- 성능 최대화
- 선택 예제 수 최소화
즉, 좋은 subset은 성능은 높고 크기는 작은 subset입니다.
5.3 Random scalarization
이 bi-objective 문제를 풀기 위해 논문은 매 BO iteration마다 랜덤 가중치 를 샘플링합니다.
그리고 성능과 sparsity를 하나의 scalar objective로 합칩니다.
논문은 Tchebyshev scalarization을 사용합니다.
직관적으로는 다음과 같습니다.
즉, 어떤 iteration에서는 성능을 더 중시하고, 어떤 iteration에서는 작은 subset을 더 중시합니다. 이를 통해 다양한 Pareto front를 탐색합니다.
5.4 GP surrogate + Expected Improvement
각 iteration에서 GP는 scalarized objective 를 근사합니다.
그 후 acquisition function으로 **Expected Improvement(EI)**를 사용합니다.
EI는 현재까지 관측한 최고 성능보다 더 좋아질 가능성이 큰 subset을 선택합니다.
선택된 subset을 실제로 validation set에서 평가하고, 그 결과를 다시 BO에 추가합니다.
이 과정을 budget 만큼 반복합니다.
6. 전체 알고리즘 요약
BRIDGE는 다음처럼 동작합니다.
- train set에 대해 LLM이 reasoning과 answer를 생성
- 정답을 맞힌 예제만 모아 구성
- BO로 좋은 subset 탐색
- 를 demonstration으로 사용해 train set reasoning을 재생성
- 새 example pool 생성
- 다시 BO로 탐색
- 반복
- 최종 optimized examples를 사용해 test inference
7. 실험 결과
주요 실험 대상은 다음입니다.
- BBH
- MATH
- GSM-Hard
- BIRD text-to-SQL
- 모델: Gemini 1.5 Pro, Gemini 1.5 Flash, Mistral Large, Mistral NeMo, Claude 3.5 Sonnet
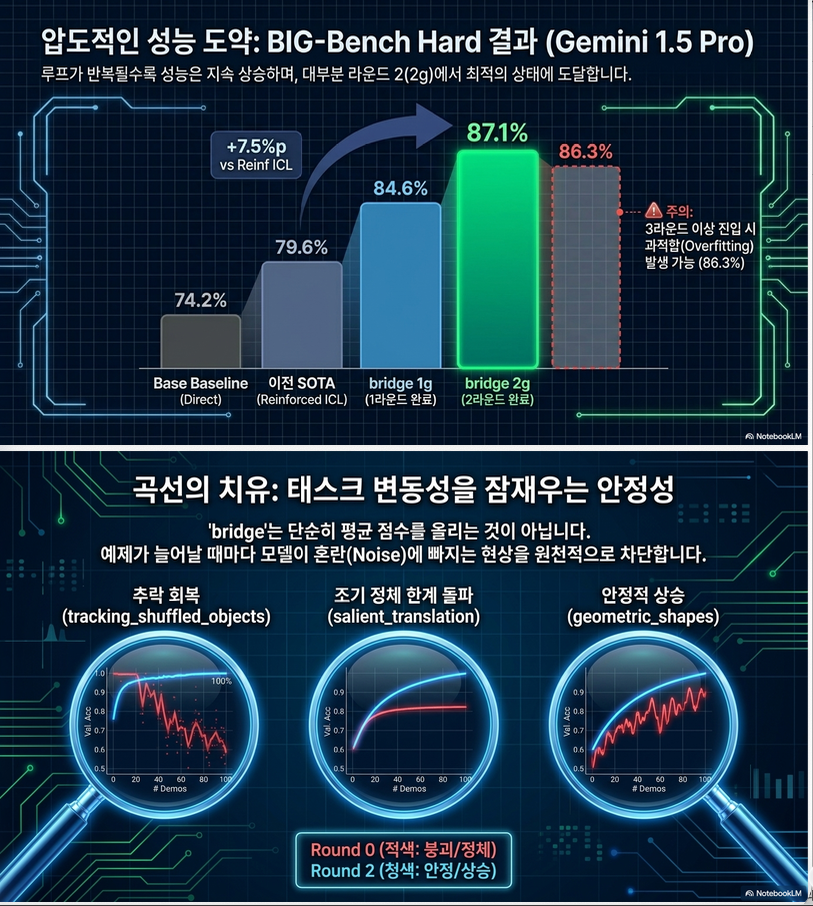
Gemini 1.5 Pro의 BBH 결과에서 평균 정확도는 대략 다음 흐름을 보입니다.
| 방법 | 평균 정확도 |
|---|---|
| All Direct | 74.22 |
| All CoT | 74.06 |
| All Infill | 78.70 |
| Reinforced ICL | 79.61 |
| Iterative Reinforced ICL | 82.37 |
| BRIDGE 2g | 87.13 |
즉, BRIDGE는 reinforced ICL보다 약 7%p 이상 향상됩니다.
특히 단순히 반복 generation만 하는 Iterative Reinforced ICL보다도 BRIDGE가 더 좋습니다. 이는 Optimize 단계가 핵심 구성 요소임을 보여줍니다.
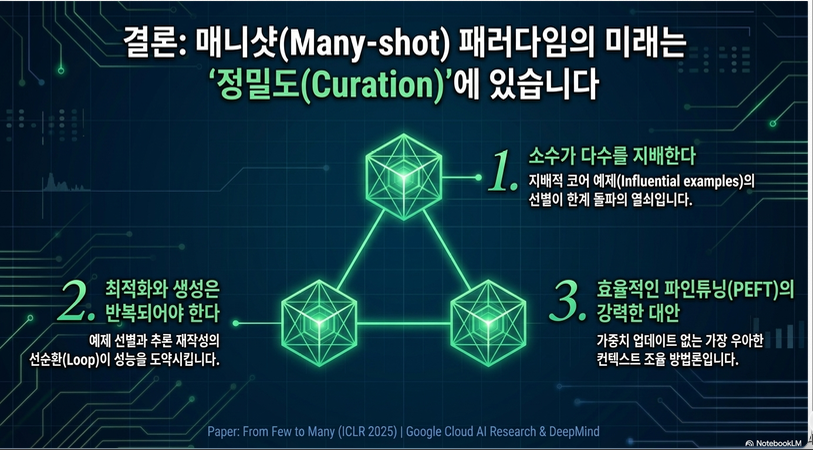
8. 논문의 핵심 기여
이 논문의 기여는 크게 세 가지입니다.
- Many-shot ICL의 성능 원인 분석
many-shot 성능이 단순히 예제 수 증가 때문만은 아니며, 소수의 영향력 있는 예제가 성능을 지배할 수 있음을 보였습니다. - Optimize + Generate 프레임워크 제안
좋은 subset을 찾은 뒤, 그것을 seed로 사용해 더 나은 reasoning examples를 재생성하는 구조를 제안했습니다. - Bayesian Optimization 기반 subset search
예제 선택을 combinatorial black-box optimization으로 보고, GP surrogate와 EI를 사용해 sample-efficient하게 탐색했습니다.
한 줄 요약
이 논문은 many-shot ICL에서 “많이 넣는 것”보다 “좋은 예제를 고르고, 그 예제로 더 좋은 reasoning examples를 다시 생성하는 것”이 중요하다는 점을 보이고, 이를 위해 Bayesian Optimization 기반 BRIDGE 알고리즘을 제안한 논문입니다.
5.3 Random Scalarization 자세히
논문의 Optimize 단계는 사실상 다목적 최적화(Multi-Objective Optimization) 문제입니다.
최적화하려는 목표가 두 개이기 때문입니다.
목표 1: Validation 성능 최대화
여기서
- e: 선택된 demonstration subset
- g(e): validation accuracy
목표 2: Example 수 최소화
여기서
즉,
- 적은 수의 demonstration 사용
- redundancy 제거
- generation 단계에서 memorization 감소
를 유도합니다.
왜 단순 weighted sum을 안 쓰나?
보통은
같이 할 수 있습니다.
하지만 문제는:
- task마다 optimal 가 다름
- 어떤 task는 많은 example이 필요
- 어떤 task는 적은 example이 더 좋음
즉,
같이 고정하면 특정 task에서는 매우 비효율적입니다.
Random Scalarization 아이디어
매 BO iteration마다
를 샘플링합니다.
예:
| Iteration | \beta_t |
|---|---|
| 1 | 0.95 |
| 2 | 0.32 |
| 3 | 0.78 |
| 4 | 0.51 |
그러면 iteration마다 다른 objective를 탐색합니다.
β=0.95
거의 accuracy 중심
β=0.3
sparsity 중심
β=0.7
중간
Tchebyshev Scalarization
논문은 weighted sum 대신
Tchebyshev scalarization(TCH) 을 사용합니다.
식은
여기서
입니다.
직관
예를 들어
후보 A
g(e)=0.90
|e|=50
후보 B
g(e)=0.88
|e|=10
weighted sum은
0.5g-0.5|e|
형태라 scale 문제가 발생합니다.
반면 TCH는 가장 부족한 objective를 개선하는 방향으로 동작합니다.
그래서 Pareto front 전체를 더 잘 탐색합니다.
이는 Multi-Objective BO에서 자주 사용하는 방법입니다.
왜 Random Scalarization을 쓰는가?
만약 로 고정하면
BO는 항상 같은 Pareto 영역만 탐색합니다.
Random scalarization은
를 계속 바꾸므로 다양한 Pareto optimal subset들을 탐색하게 됩니다.
결과적으로 후보들을 더 넓게 살펴볼 수 있습니다.
5.4 GP Surrogate + Expected Improvement
이제 실제 Bayesian Optimization 부분입니다.
문제
우리가 최적화하려는 함수 를 평가하려면, 실제로 LLM inference를 돌려야 합니다.
즉,
- subset 선택
- validation inference
- accuracy 측정
을 해야 합니다.
엄청 비쌉니다.
예를 들어, 100개 example이 있으면 가능한 subset은 개입니다.
전수탐색 불가.
GP Surrogate
그래서 BO는 실제 함수 대신 Gaussian Process(GP)를 학습합니다.
현재까지 평가한 데이터
를 이용해 GP를 학습합니다.
입력
binary subset vector
예:
e=(1,0,1,0,0,1)
출력
scalarized score
그래서 GP는
를 근사합니다.
GP의 출력
GP는 단순 prediction만 하지 않습니다.
각 점마다
평균
분산
를 제공합니다.
논문 식 (2):
의미
평균 높음
→ 좋아 보임
분산 큼
→ 아직 안 가본 영역
평균 낮음 + 분산 작음
→ 별로
Kernel
논문은 k(e,e’)로 Matérn 2.5 kernel 사용.
여기서 binary subset 사이의 similarity는 직관적으로
즉, 공통으로 포함된 example 수에 의해 결정됩니다.
예
e=(1,1,0,1,0)
e’=(1,0,0,1,1)
공통 원소
2개
→ similarity 높음
Expected Improvement(EI)
BO의 핵심.
다음 evaluation 위치를 결정합니다.
현재 최고값
새 후보 e에서 개선량
하지만 h(e)는 모름.
GP posterior를 사용합니다.
따라서
EI(e) = E[I(e)]
를 계산합니다.
논문 식:
EI의 특징
후보 A
거의 확실히 좋음
후보 B
운 좋으면 최고점 가능
EI는
을 자동으로 균형 맞춥니다.
최종 선택
BO는
를 선택합니다.
논문에서는
라고 표현합니다.
전체 흐름 요약
Random subset 평가
↓
GP 학습
↓
μ(e), σ(e) 계산
↓
EI 계산
↓
가장 EI 큰 subset 선택
↓
실제 LLM 평가
↓
GP 업데이트
↓
반복즉 BRIDGE의 Optimize 단계는 본질적으로
“example subset 선택” 문제를
GP surrogate + EI acquisition을 사용하는
combinatorial Bayesian Optimization 문제로 변환한 것이며,
Random Scalarization을 통해 성능과 sparsity 사이의 Pareto front를 효율적으로 탐색하는 것이 핵심입니다.
답글 남기기