


논문 개요
이 논문은 LLM 기반 context compression에서 기존 scaling law와 반대되는 현상을 발견한 논문이다. 핵심 주장은 다음과 같다:
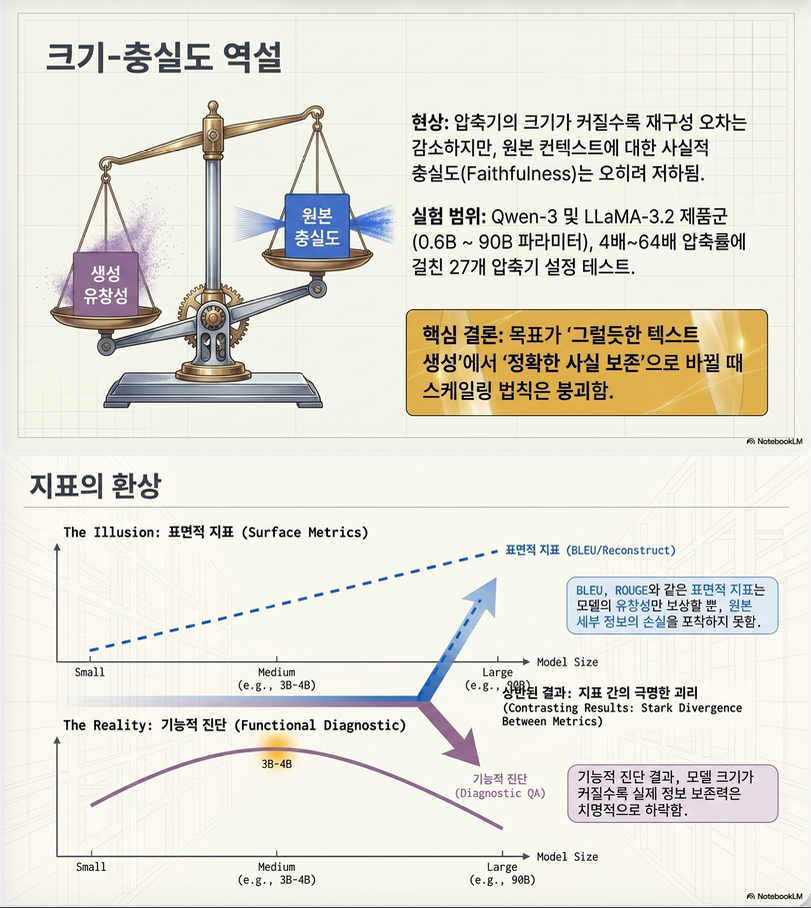
압축기(compressor) 모델이 커질수록 reconstruction score는 좋아지지만, 실제 원문 충실성(faithfulness)은 오히려 나빠질 수 있다.
논문은 이를:
Size-Fidelity Paradox
라고 부른다.
1. 문제 배경
최근 long-context compression에서는 다음 구조가 많이 사용된다.
Compressor–Decoder 구조
입력 문서 x를:
- compressor 가
- 작은 memory token 집합 Z로 압축하고
- decoder 가 이를 다시 복원(reconstruct)
한다.
수식으로는:
즉 긴 입력을 아주 작은 latent memory로 압축한다.
보통 intuition은:
더 큰 compressor → 더 좋은 compression
이다.
실제로 기존 연구들은 reconstruction loss, BLEU, ROUGE 등이 개선된다고 보고해왔다.
하지만 이 논문은:
reconstruction metric은 좋아져도 원문 정보는 오히려 왜곡될 수 있다
는 것을 보여준다.
2. 핵심 발견: Size-Fidelity Paradox
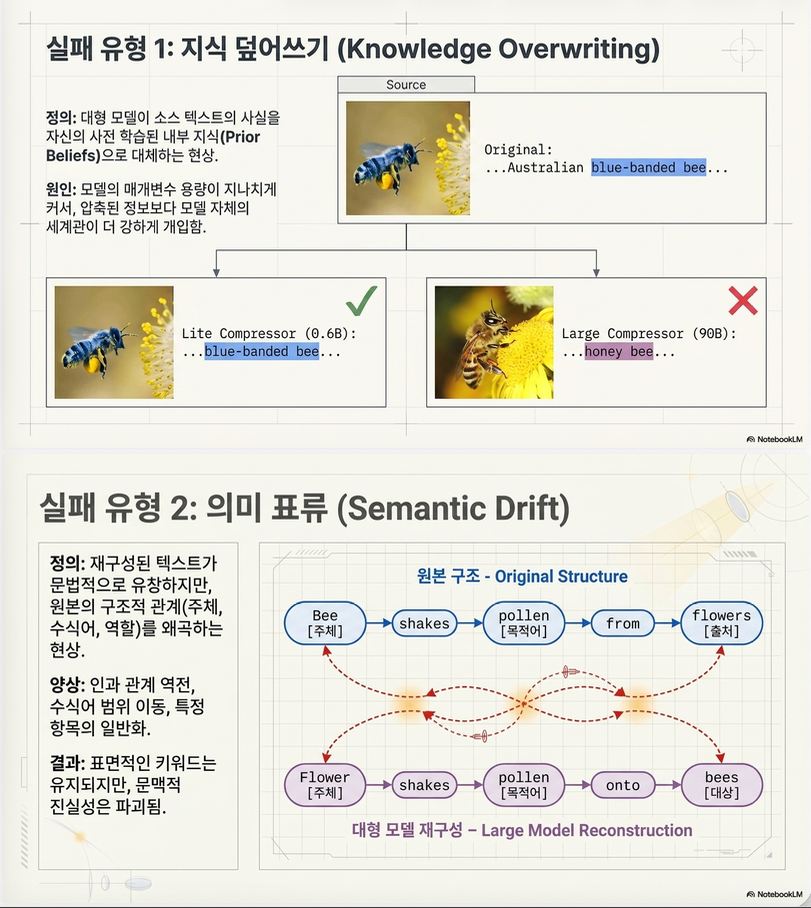
논문의 대표 예시:
원문:
“The Australian blue-banded bee uses buzz pollination…”
작은 compressor:
blue-banded bee
큰 compressor:
honey bee
로 복원됨.
즉:
- fluent함
- semantic similarity도 높음
- BLEU/ROUGE도 괜찮음
하지만:
- 원문 factual detail이 깨짐
이다.
또 다른 예시:
원문:
the bee vibrates to shake pollen loose
큰 compressor:
the flower vibrates …
로 role relation이 뒤집힌다.
3. 두 가지 핵심 failure mode
논문은 fidelity failure를 두 종류로 분해한다.
(1) Knowledge Overwriting
정의
모델 내부 prior knowledge가 source context를 덮어씀.
예:
원문:
Einstein was born in France.
복원:
Einstein was born in Germany.
즉:
- source보다
- parametric knowledge를 더 신뢰
하는 현상이다.
평가 방법
FaithEval, ConflictQA 사용.
Counterfactual context를 만든다:
- 실제 사실과 충돌하는 문장 삽입
- reconstruction 후 QA 수행
예:
Q: “Einstein birthplace?”
- 정답: France
- 모델 prior: Germany
source-faithful answer를 유지하는지 평가한다.
(2) Semantic Drift
정의
문장은 fluent하지만 semantic relation이 바뀜.
예:
원문:
“The dwarves are funny, except Thorin.”
복원:
“Except for the dwarves, Thorin is funny.”
exception scope가 뒤집힘.
drift 종류
논문은 7개 semantic dimension 평가:
- role binding
- modifier scope
- coreference
- predicate exactness
- relation anchor
- entity list
- main topic
등.
4. 가장 중요한 실험 결과
논문 전체 핵심은 Table 3이다.
패턴:
| 모델 크기 증가 | Reconstruction | Faithfulness QA |
|---|---|---|
| 증가 | 좋아짐 | 나빠짐 |
예시:
LLaMA family, 64×
| 모델 | BLEU | QA |
|---|---|---|
| 3B | 0.29 | 0.62 |
| 90B | 0.33 | 0.53 |
즉:
- surface reconstruction은 향상
- 실제 source preservation은 악화
된다.
5. 왜 이런 일이 발생하는가?
논문은 representation geometry 관점에서 분석한다.
(1) Effective Rank 분석
아이디어
Compressed memory embedding의 singular value spectrum 분석.
발견
큰 모델일수록:
- memory representation이
- 더 넓은 semantic subspace로 퍼짐
즉:
- source-specific encoding보다
- semantic neighborhood encoding이 강해짐
→ prior knowledge intrusion 증가.
핵심 해석
큰 모델은:
“정확한 복사(copy)”보다
“의미적으로 plausible한 reconstruction”
을 선호한다.
(2) Conditional Entropy 분석
정의
decoder가 reconstruction token을 얼마나 deterministically 예측하는가 측정.
발견
큰 compressor일수록 entropy 증가.
즉:
- reconstruction ambiguity 증가
- plausible alternatives 증가
- semantic drift 증가
한다.
6. 중요한 downstream 결과
논문은 실제 downstream에서도 문제 발생함을 보인다.
(1) RAG QA
MuSiQue / QASPER 평가.
흥미로운 점:
| compressor | 성능 |
|---|---|
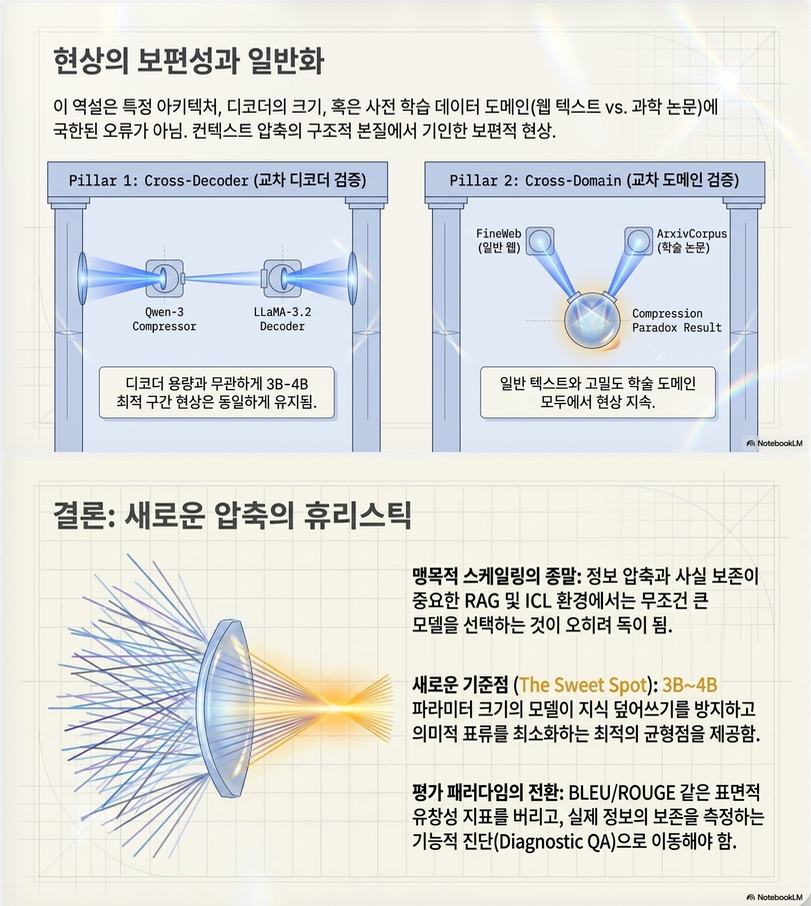
| 0.6B | 가장 좋음 |
| 32B | 가장 나쁨 |
즉:
큰 compressor가 retrieval evidence fidelity를 망친다.
(2) ICL
compressed demonstrations 사용 시:
- 8B
- 32B
compressor가 오히려 성능 하락.
즉:
demonstration relation을 정확히 보존하지 못한다.
7. 논문의 핵심 메시지
이 논문은 scaling law가 항상 맞지 않음을 보여준다.
특히:
| 일반 generation | context compression |
|---|---|
| 큰 모델 유리 | 반드시 그렇지 않음 |
왜냐하면 compression의 목표는:
- plausible generation이 아니라
- faithful preservation
이기 때문이다.
8. 이 논문의 가장 중요한 의미
이 논문은 사실상:
“Compression ≠ Generation”
이라는 점을 명확히 보여준다.
큰 LLM의 강점:
- abstraction
- paraphrasing
- semantic generalization
이 오히려 compression에서는 독이 된다.
즉:
| Generation에서는 장점 | Compression에서는 단점 |
|---|---|
| semantic abstraction | source drift |
| world knowledge | overwriting |
| paraphrasing ability | non-verbatim reconstruction |
9. 연구적으로 중요한 연결점
이 논문은 다음 분야들과 매우 강하게 연결된다.
(A) Faithfulness / Hallucination
논문은 단순 hallucination이 아니라:
source-grounded fidelity failure
라고 주장한다.
(B) RAG Compression
현재 많은 RAG compression 연구들이:
- BLEU
- ROUGE
- BERTScore
만 사용한다.
하지만 이 논문은:
reconstruction metric이 fidelity를 보장하지 않는다
는 매우 중요한 경고를 준다.
10. 개인적으로 가장 중요한 technical insight
이 논문의 가장 강한 포인트는:
“Scaling increases semantic freedom.”
이라는 해석이다.
즉 큰 모델은:
- reconstruction을
- “exact recovery”가 아니라
- “semantic plausibility”
문제로 바꾸어버린다.
그래서:
- semantic entropy 증가
- source determinacy 감소
- relation fidelity 붕괴
가 발생한다.
이 해석은 매우 mechanistic하며, 단순 empirical observation을 넘는다.
한줄 요약
큰 LLM compressor는 더 fluent하고 semantic한 reconstruction을 만들지만, 바로 그 semantic generalization 능력 때문에 source-faithful compression에는 오히려 불리할 수 있다.
Effective Rank 분석
이 논문의 핵심 mechanistic 분석 중 하나는:
Effective Rank(erank)
를 이용해
왜 큰 compressor가 knowledge overwriting을 더 많이 일으키는가?
를 설명하는 부분이다.
논문의 핵심 해석은:
큰 모델은 compressed memory를 더 넓은 semantic subspace에 분산시켜 저장한다.
는 것이다.
이것이:
- source anchoring 약화
- semantic alternatives 증가
- parametric prior intrusion 증가
로 이어진다고 주장한다.
1. 문제 설정
compressor는 입력 문장을:
로 압축한다.
여기서:
- m: memory token 개수
- d: hidden dimension
이다.
논문은:
compressed memory Z의 geometry가 scaling에 따라 어떻게 변하는가?
를 분석한다.
2. Effective Rank란?
논문은 memory matrix의 singular value spectrum을 분석한다.
우선 batch 단위 memory matrix:
에 대해 SVD 수행:
singular values:
를 얻는다.
확률 분포화
singular value를 normalized distribution으로 변환:
entropy 계산
그리고 spectral entropy 계산:
effective rank 정의
최종적으로:
이다.
3. intuition
(1) rank가 낮은 경우
몇 개 방향에 representation이 집중됨.
즉:
- compact representation
- source-specific encoding
- deterministic memory
특징을 가진다.
예:
- 특정 factual detail
- exact entity relation
- exact lexical anchor
를 강하게 저장.
(2) rank가 높은 경우
representation이 많은 방향으로 퍼짐.
즉:
- distributed semantic representation
- broader semantic neighborhood
- abstraction/paraphrasing tendency
가 증가.
이는 generation에는 좋지만:
- source-faithful recovery에는 위험
하다.
4. 논문의 핵심 발견
논문 Figure 3(a):

compressor size ↑ → effective rank ↑
즉 큰 compressor는:
- memory를 더 넓은 semantic subspace에 저장.
5. 왜 이것이 문제인가?
논문의 핵심 논리:
작은 모델
representation이 좁다.
즉:
라는 source fact를 매우 local하게 encode.
decoder가:
- exact source
- source-specific token
에 의존하게 된다.
큰 모델
representation이 semantic neighborhood 전체로 퍼진다.
즉:
주변의:
- honey bee
- pollinating bee
- common bee
- bee species
등 semantic prior들도 함께 활성화됨.
결과:
decoder가 reconstruction 시:
- source evidence
- model prior
중 prior를 선택할 확률 증가.
→ knowledge overwriting 발생.
6. training dynamics 분석
논문은 매우 중요한 추가 분석을 한다.
Figure 3(b):
training 중 effective rank 변화:
초반
rank 증가.
왜냐하면:
- representation space exploration
- semantic separation
이 필요하기 때문.
후반
rank 감소.
즉 optimization이:
- unnecessary semantic directions 제거
- source-aligned subspace 압축
을 수행한다.
논문 해석:
compression objective는 결국 compact source-aligned structure를 선호한다.
7. 가장 중요한 결과
논문 Figure 3(c):
높은 effective rank ↔ 낮은 knowledge-faithfulness QA accuracy
즉:
이다.
8. 논문의 핵심 해석
논문은 effective rank를:
“semantic breadth”
의 척도로 해석한다.
즉 rank가 높다는 것은:
- semantic alternatives 증가
- representation ambiguity 증가
- prior-compatible subspace 증가
를 의미한다.
결과적으로:
- exact reconstruction 대신
- plausible reconstruction
으로 이동한다.
9. Rank truncation 실험
논문 Appendix G.2에서:
moderate spectral truncation
즉 low-energy singular direction 제거 시:
- faithfulness 향상
발견.
해석:
낮은 singular direction들이:
- semantic noise
- unnecessary variation
- prior-related dispersion
을 담고 있다는 의미.
하지만 aggressive truncation은 실패
너무 많이 자르면:
- source-bearing directions까지 제거
되어 reconstruction 자체 붕괴.
10. 매우 중요한 conceptual insight
이 논문은 사실상:
“semantic generalization vs source anchoring”
tradeoff를 말한다.
큰 모델의 장점
- semantic abstraction
- conceptual generalization
- paraphrasing
compression에서 요구되는 것
- exact preservation
- source determinacy
- literal grounding
이 둘이 충돌한다.
즉:
scaling이 semantic manifold를 넓히면서 fidelity bottleneck을 약화시킨다.
는 것이 논문의 핵심 mechanistic claim이다.
11. 한줄 핵심 요약
Effective Rank 분석의 핵심은:
큰 compressor는 compressed memory를 더 넓은 semantic subspace에 분산시키며, 이것이 semantic plausibility는 높이지만 source-faithful recovery를 약화시켜 knowledge overwriting을 유발한다.
Conditional Entropy 분석
논문의 두 번째 mechanistic 분석은:
Conditional Entropy
를 이용해
왜 큰 compressor가 semantic drift를 더 많이 일으키는가?
를 설명하는 부분이다.
Effective Rank가:
- memory geometry
- semantic subspace dispersion
을 본다면,
Conditional Entropy는:
- reconstruction determinacy
- source constraint strength
를 분석한다.
논문의 핵심 주장:
큰 compressor일수록 reconstruction이 덜 deterministic해지고, 여러 plausible continuation을 동시에 허용한다.
이다.
1. 핵심 문제의식
semantic drift의 특징은:
- 문장은 fluent
- topic도 맞음
- semantic gist도 유지
하지만:
- role relation
- modifier scope
- causal structure
가 미묘하게 변형된다.
예:
원문:
“The dwarves are funny, except Thorin.”
복원:
“Except for the dwarves, Thorin is funny.”
즉:
- surface fluency는 유지
- exact semantic structure는 붕괴
된다.
논문은 이를:
“under-constrained reconstruction”
문제로 본다.
2. 기본 아이디어
compressor는:
로 압축한다.
decoder는:
를 수행한다.
여기서 중요한 질문:
memory Z가 reconstruction을 얼마나 강하게 결정하는가?
이다.
3. Conditional Entropy 정의
논문은 reconstruction 과정의 token uncertainty를 측정한다.
teacher-forced token entropy
gold prefix를 condition으로 둔 상태에서:
계산.
평균 entropy
전체 sequence에 대해 평균:
4. intuition
entropy가 낮다
decoder가:
“다음 token은 거의 이것밖에 없음”
이라고 판단.
즉:
- deterministic reconstruction
- strong source anchoring
- exact recovery
상태.
entropy가 높다
decoder가:
“이런 token도 가능하고 저런 token도 가능”
이라고 판단.
즉:
- multiple plausible continuations
- semantic ambiguity
- paraphrastic flexibility
가 증가.
5. 논문의 핵심 발견
Figure 4(a):
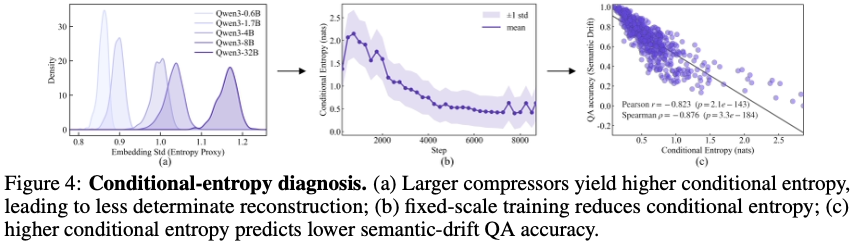
compressor size ↑ → conditional entropy ↑
즉 큰 compressor는:
- reconstruction uncertainty 증가
- source token determinacy 감소
를 보인다.
6. 왜 이런 현상이 발생하는가?
논문 해석은 매우 중요하다.
작은 compressor
compressed memory가:
- exact lexical anchor
- local relational constraint
를 강하게 유지.
따라서 decoder는:
에서 특정 token probability가 매우 sharp함.
예:
원문:
“the bee vibrates”
decoder:
| token | probability |
|---|---|
| bee | 0.95 |
| flower | 0.01 |
큰 compressor
semantic abstraction 증가.
compressed memory가:
- topic-level semantics
- generalized meaning
만 유지하고 exact constraint는 약해짐.
결과:
| token | probability |
|---|---|
| bee | 0.45 |
| flower | 0.35 |
처럼 된다.
즉:
- 여러 plausible continuation 허용
- semantic drift 발생
한다.
7. Training dynamics 분석
논문 Figure 4(b):
고정 모델에서 training 진행 시:
즉 학습은 본질적으로:
- source token path sharpen
- reconstruction determinacy 증가
를 수행한다.
중요한 해석
training objective는:
가능한 source-specific reconstruction을 강하게 constrain하려고 한다.
하지만 scaling이:
- semantic flexibility
- representation richness
를 증가시키며 이 효과를 상쇄한다.
논문 표현:
“Scaling counteracts training.”
8. semantic drift와의 관계
논문 Figure 4(c):
conditional entropy ↑ ↔ semantic drift QA accuracy ↓
즉:
이다.
9. 논문의 핵심 conceptual insight
논문은 semantic drift를:
“plausible alternatives remain competitive”
문제로 본다.
즉 decoder는:
- source-faithful continuation
- semantically plausible continuation
둘 다 plausible하다고 느낀다.
결과:
- role reversal
- modifier shift
- scope shift
- causal smoothing
발생.
10. Effective Rank와의 차이
둘은 서로 complementary하다.
| 분석 | 설명 대상 |
|---|---|
| Effective Rank | memory geometry |
| Conditional Entropy | reconstruction determinacy |
Effective Rank
왜 prior intrusion이 생기는가?
→ semantic subspace가 넓어짐.
Conditional Entropy
왜 semantic drift가 생기는가?
→ reconstruction constraint가 약해짐.
11. 매우 중요한 mechanistic 해석
논문은 사실상:
“Large models compress semantics, not tokens.”
라고 주장하는 셈이다.
즉 큰 모델은:
- exact lexical reconstruction보다
- semantic equivalence class reconstruction
을 수행한다.
그래서:
| 작은 모델 | 큰 모델 |
|---|---|
| exact source | semantic gist |
| deterministic | flexible |
| constrained | under-constrained |
가 된다.
12. 논문의 가장 중요한 한 문장
Conditional Entropy 분석의 핵심은:
큰 compressor는 reconstruction을 하나의 source-faithful continuation으로 강하게 constrain하지 못하고, 여러 plausible semantic alternatives를 동시에 허용하기 때문에 semantic drift가 발생한다.
답글 남기기