[태그:] SAE
-

** Improving LLM Reasoning through Interpretable Role-Playing Steering (Findings of EMNLP 2025)
논문 “Improving LLM Reasoning through Interpretable Role-Playing Steering” (Findings of EMNLP 2025) 은 역할 수행(role-playing) 기반 추론 강화 기법을 LLM 내부 표현 수준에서 해석 가능하게 제어하는 새로운 접근법을 제안합니다. 핵심은 Sparse Autoencoder(SAE) 로 모델 내부 활성화 패턴을 분석하고, 역할 수행 시 활성화되는 잠재 특징(latent features)을 추출하여 Residual Stream에 주입(steering) 함으로써 모델의 “역할 일관적(reasoning-consistent)” 사고를 유도하는…
-
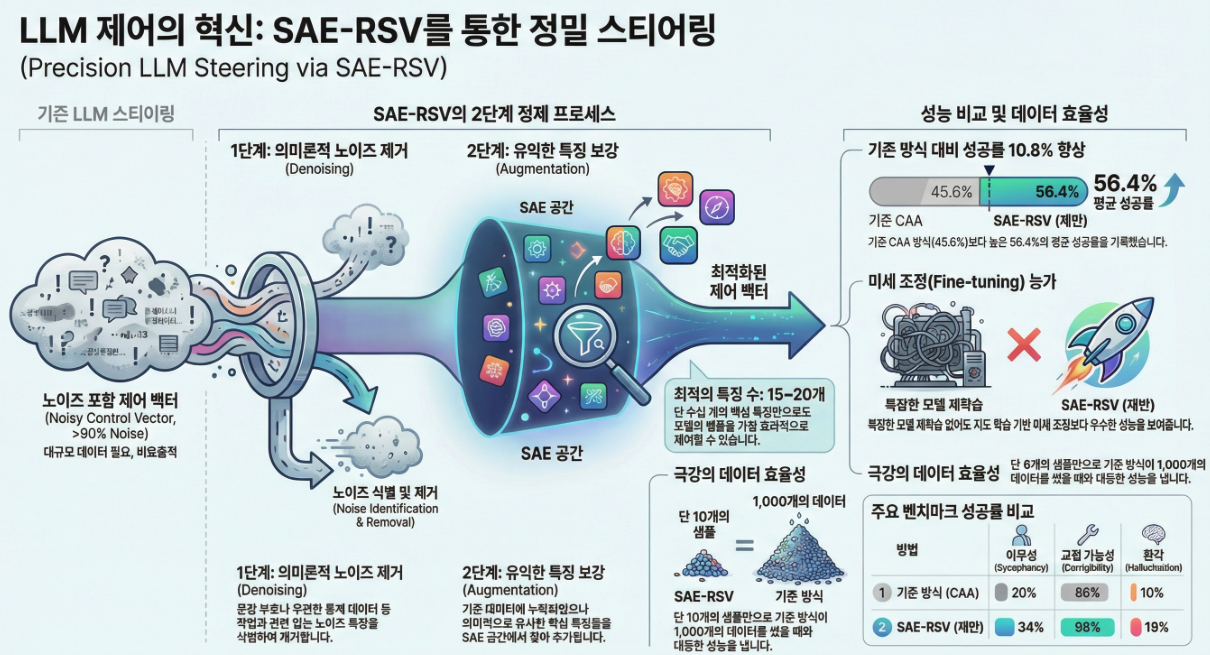
** Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (Arxiv 2025)
아래에서는 「Enhancing LLM Steering through Sparse Autoencoder-based Vector Refininement (SAE-RSV)」 논문의 관련연구, 방법론, 실험 결과를 핵심만 구조적으로 정리해 설명합니다. 1. 관련연구 (Related Work) (1) Steering / Difference-in-Means 계열 (2) Sparse Autoencoder(SAE) 기반 Steering (3) 본 논문의 포지션 2. 방법론 (Methodology) 논문은 **SAE-RSV (Sparse Autoencoder-based Refinement of Steering Vector)**라는 2-단계 정제 프레임워크를 제안합니다. (1) 기본 Steering…
-

* Latent Inter-User Difference Modeling for LLM Personalization (EMNLP 2025)
아래에서는 **EMNLP 2025 논문 “Latent Inter-User Difference Modeling for LLM Personalization”**을 중심으로 관련 연구, 방법론, 실험 결과를 연구 흐름 관점에서 정리해 설명합니다. (설명은 논문 전체 내용을 종합한 요약입니다) 1. 관련 연구 (Related Work) (1) LLM 개인화의 주류: Memory-Retrieval Paradigm (2) Inter-User Difference를 명시적으로 다룬 연구 (3) Latent-Space Personalization –> 이 논문의 핵심 포지션 “Inter-user difference는…
-
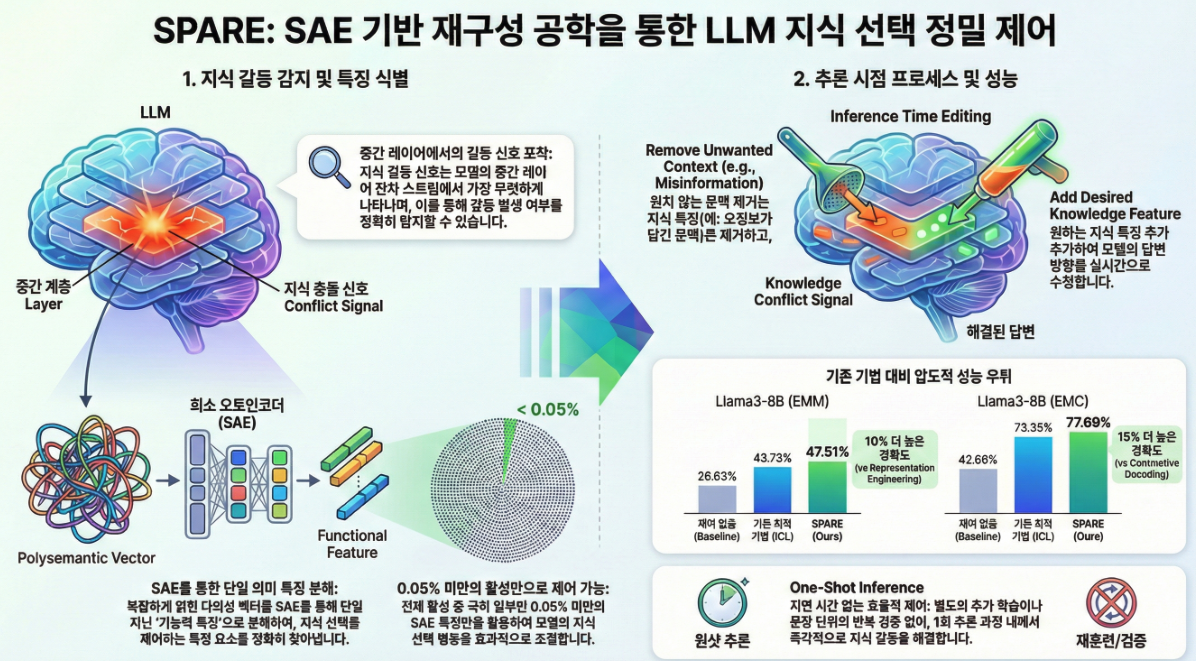
*** Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering (NAACL 2025)
논문 **“Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering” (NAACL 2025)**은대형 언어모델(LLM)이 내부 파라미터(기억된 지식, parametric knowledge)와 입력 문맥(contextual knowledge) 간의 지식 충돌(knowledge conflict) 상황에서 어떤 지식을 사용할지 조절하는 방법을 제안한 연구입니다. 핵심 내용은 다음과 같습니다. 1. 문제 배경: Knowledge Conflict LLMs는 내부적으로 방대한 사실 지식을 학습하지만,새로운 컨텍스트(예: 검색 결과, 최신 정보)가 주어지면 기존 지식과 충돌할 수…
-
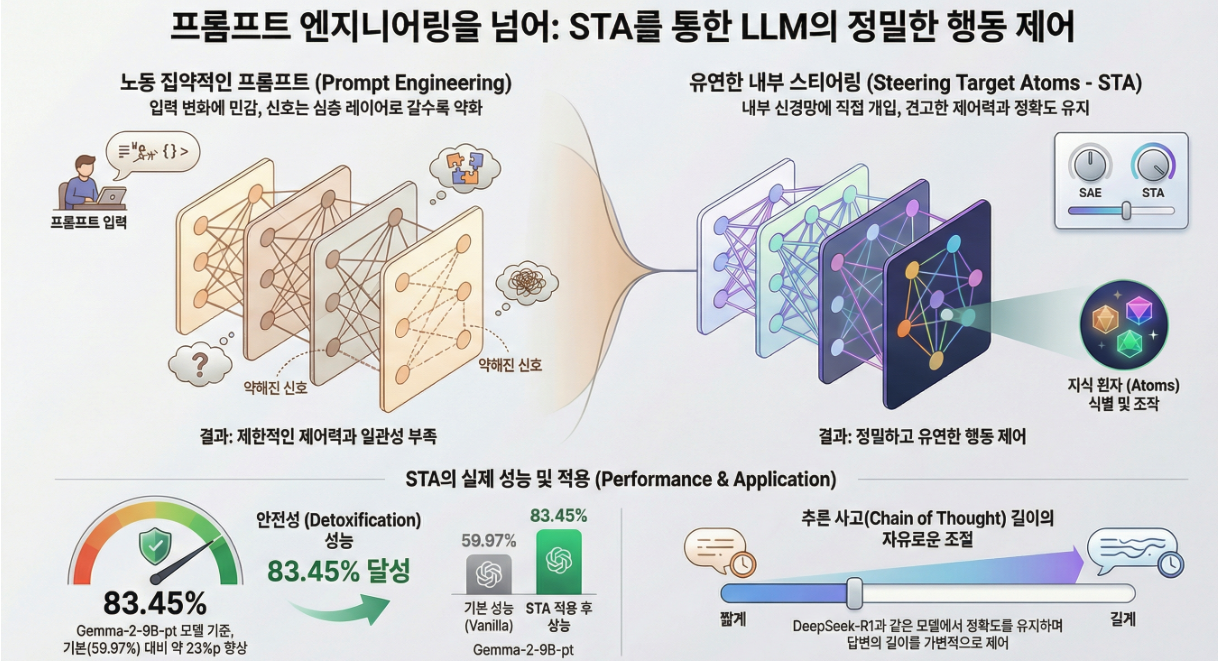
*** Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms (ACL 2025)
논문 **“Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms” (ACL 2025)**은 대형 언어모델(LLM)의 행동 제어(behavior control) 문제를 다루며, 기존의 *프롬프트 엔지니어링(prompt engineering)*의 한계를 극복하기 위해 Steering Target Atoms (STA) 라는 새로운 방법을 제안합니다. 연구 배경 제안 방법: Steering Target Atoms (STA) 1. SAE 기반 표현 분해 모델의 은닉 상태 hh 를 SAE를 통해 고차원, 희소…