다음은 ACL 2025 논문 “Steering off Course: Reliability Challenges in Steering Language Models”의 핵심 내용 요약입니다.
1. 연구 배경 및 동기
LM Steering의 등장
- Steering methods는 대규모 언어 모델(LLM)의 **내부 활성화(activation)**를 조작하여 모델의 출력을 원하는 방향으로 유도하는 기법입니다.
- 장점:
- 모델 파라미터를 수정하지 않음 → **추가 학습(fine-tuning)**보다 경량(lightweight).
- 적은 데이터로도 수행 가능.
- 대표적인 활용:
- 사실성(factuality) 향상
- 바람직하지 않은 특성 제거(예: 편향, 유해 콘텐츠 생성 억제)
문제의식
- 기존 연구들은 소수의 모델에서만 평가가 이루어짐.
- 실제 다양한 모델과 규모에서 일관성이 검증되지 않음 → 일반화 가능성 불확실.
- 본 논문은 세 가지 대표적인 steering 기법의 **신뢰성(reliability)**과 일관성을 대규모 실험으로 분석함.
2. 연구 목표와 실험 구성
목표
- 세 가지 주요 steering 기법의 범용성 및 신뢰성 평가
- DoLa (Decoding by Contrasting Layers): Logit Lens 기반
- Function Vectors (FV): Activation Patching 기반
- Task Vectors (TV): Activation Patching 기반
- 총 36개 모델 (14개 모델 패밀리, 1.5B ~ 70B 파라미터)을 테스트.
주요 실험 세팅
| 실험 요소 | 설명 |
|---|---|
| 모델 패밀리 | LLaMA, Qwen, OLMo, Pythia, Mistral 등 |
| 평가 데이터셋 | TruthfulQA, FACTOR (사실성 평가) |
| ICL(Task Vector) | 11개의 언어 및 사실성 기반 태스크 (영어-불어/독일어/스페인어 번역, 반의어, 과거 시제 등) |
| 평가 방식 | 0-shot, 5-shot 성능 비교 |
3. 세 가지 Steering 기법
(1) DoLa (Logit Lens 기반)
- 가설: 사실적 지식을 담은 뉴런은 후반부 레이어에 집중되어 있으며, 이들의 확률 상승을 강조하면 사실성을 높일 수 있음.
- 핵심 아이디어:
- 최종 레이어(
qL)와 “조기 레이어”(premature layer,qP)의 확률 분포 차이를 비교. - Jensen-Shannon Divergence(JSD)를 사용하여
qL과 가장 다른 레이어를qP로 선택. - 이후 특정 토큰들의 확률을 강조하고, 낮은 확률의 토큰을 제거.
- 최종 레이어(
문제점 발견: 다양한 모델에서
qL과qP의 차이가 사실성과 강하게 연관되지 않음 → 일부 모델은 오히려 성능 저하.
(2) Function Vectors (FV)
- 목적: 특정 태스크 수행 시 중요한 어텐션 헤드들의 평균 활성화 값을 벡터화하여 스티어링에 사용.
- 과정:
- 모든 샘플의 어텐션 헤드 활성화 평균 계산
- Causal Mediation Analysis를 통해 중요한 헤드(
An) 선정 - 선택된 헤드들의 평균을 합산 → Function Vector 생성
- 패치 공식:
- α: 원래 활성화 비중 (FV는 α=1)
- λ: 스티어링 강도 조절 계수
결과: 일부 모델/태스크에서만 유효하며, 특정 모델에서는 매우 많은 헤드(예: 512개) 필요 → “Localization Hypothesis”가 항상 성립하지 않음.
(3) Task Vectors (TV)
- 목적: In-Context Learning(ICL)을 통째로 하나의 벡터로 압축.
- 특정 태스크의 예시(prompt)에서 나온 특정 레이어의 hidden state 자체를 스티어링 벡터로 사용.
- 패치 공식은 FV와 동일하나, TV는 α=0으로 기존 활성화를 무시하고 교체.
결과: FV보다 안정적이지만 여전히 모델 간 변동성이 크며, 특정 레이어 선택이 매우 중요.
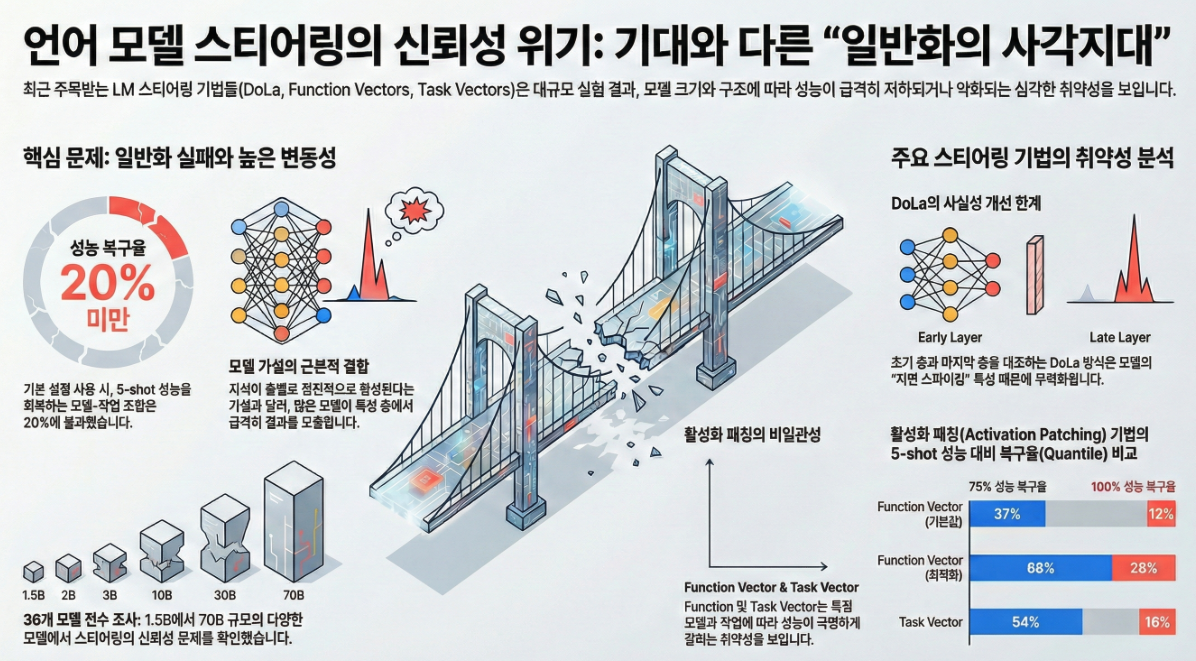
4. 주요 실험 결과
DoLa 성능 (TruthfulQA, FACTOR)
| 모델 | MC1 (Baseline → DoLa) |
|---|---|
| LLaMA-1 7B | 0.26 → 0.32 |
| LLaMA-2 70B | 0.37 → 0.34 (성능 하락) |
| Qwen-2 72B | 0.44 → 0.39 (성능 하락) |
| OLMo 7B | 0.25 → 0.25 (변화 없음) |
해석:
- LLaMA-1에서는 일부 개선되었으나, 다른 모델들은 효과 미미 혹은 성능 저하.
- JSD로 선택한
premature layer가 모델마다 의미가 다르기 때문.
Function Vectors / Task Vectors
| 기법 | 5-shot 성능의 50% 이상 복원 비율 |
|---|---|
| FV (기본 파라미터) | 20% |
| FV (탐색 최적화) | 52% |
| TV | 35% |
시사점:
- 최적화해도 FV와 TV 모두 범용성이 낮음.
- 모델과 태스크에 따라 전혀 다른 결과를 보임.
- Post-trained 모델은 일부 태스크에서 성능 상승하나 일관적이지 않음.
5. 실패 원인 분석
저자들은 성능 변동의 원인을 다음과 같이 가설화:
- Pretraining 방식
- 일부 모델은 두 단계 사전학습(mid-training) 사용 → 후반부 레이어의 동역학이 달라짐.
- 그러나 실험에서는 명확히 확인되지 않음.
- 모델 아키텍처 차이
- 레이어 수, 어텐션 헤드 수, 컨텍스트 길이 등 비교 → 명확한 패턴 발견 못함.
- 예외: Knowledge Distillation으로 학습된 Gemma 2 9B는 극단적으로 다른 특성을 보임.
- 학습 데이터 차이
- 토큰 수, 데이터 품질, 스타일 등도 영향을 줄 수 있음.
6. 결론 및 시사점
- 세 가지 Steering 기법(DoLa, FV, TV) 모두 **매우 취약(brittle)**하며,
- 모델 간 일관성 부족,
- 하이퍼파라미터에 민감,
- 일부 모델에서는 아예 작동하지 않음.
- Steering 기법의 기본 가정(레이어의 점진적 지식 축적, 로컬화된 정보 등)이 보편적으로 성립하지 않음을 확인.
- 향후 연구 방향:
- 다양한 모델과 태스크를 아우르는 체계적이고 대규모 평가 필요.
- 현재의 steering 방법은 실제 배포 환경에서 사용하기 어려움.
7. 한 줄 요약
스티어링 기법은 일부 모델에서만 작동하며, 일반화되지 않는다.
기존의 해석 기반 steering 가정은 흔들리고 있으며, 이를 위해서는 훨씬 더 체계적이고 다양한 평가가 필요하다.
논문 *”Steering off Course: Reliability Challenges in Steering Language Models”*의 방법론(Methodology) 부분을 정리해 드리겠습니다.
이 논문은 세 가지 주요 steering 기법인 DoLa, Function Vectors (FV), **Task Vectors (TV)**를 집중적으로 분석하고, 다양한 모델과 태스크에서 일반화 가능성을 실험적으로 평가합니다.
1. 개요 (Overview)
본 연구는 크게 두 가지 대표적인 steering 접근법을 실험합니다.
| 접근 방식 | 핵심 아이디어 | 대표 기법 |
|---|---|---|
| Logit Lens 기반 | 특정 레이어의 출력(logit)을 비교하여 사실성 향상 | DoLa |
| Activation Patching 기반 | 특정 레이어의 활성화(activation)를 다른 벡터로 교체하거나 추가 | Function Vector, Task Vector |
- Logit Lens: 모델 내부 representation을 vocab space로 투사하여 중간 레이어가 어떤 단어를 예측하려 하는지 관찰.
- Activation Patching: 특정 레이어의 hidden state를 직접 수정하여 모델의 동작을 제어.
2. DoLa (Decoding by Contrasting Layers)
2.1 핵심 가설
- 사실적 지식을 담고 있는 뉴런은 후반부 레이어에 집중되어 있으며,
- 모델이 초반에 잘못된 방향으로 예측하다가, 후반부 레이어에서 이를 수정함.
- → 따라서 최종 레이어의 확률에서 초반 레이어의 확률을 보정하면 사실성이 향상될 수 있음.
2.2 수식 및 알고리즘
- 각 레이어의 확률 분포 계산
- 특정 시점 에서 레이어 의 출력 를 vocab space로 투사:
- 여기서 는 unembedding matrix.
- 특정 시점 에서 레이어 의 출력 를 vocab space로 투사:
- Premature Layer 선택
- 최종 레이어 과 가장 다른 확률 분포를 가진 레이어 를 선택:
- : 후보 레이어(bucket) 집합
- JSD(Jensen-Shannon Divergence)로 유사도 측정
- 최종 레이어 과 가장 다른 확률 분포를 가진 레이어 를 선택:
- 최종 확률 업데이트
- α (threshold): 낮은 확률 토큰 제거 정도 조절.
2.3 하이퍼파라미터
| 파라미터 | 설명 |
|---|---|
| B (Bucket) | Premature layer 후보 집합 (예: 하위 25%, 중간 50%, 상위 50%) |
| α | 확률 컷오프(threshold) 조정 값 |
2.4 평가 실험
- 데이터셋:
- TruthfulQA (사실성 측정)
- FACTOR (뉴스 기반 factual completion)
- 모델:
- LLaMA-1, LLaMA-2, LLaMA-3 (7B ~ 70B)
- Pythia 6.9B
- OLMo 7B
- Qwen-2 (7B, 72B)
- Mistral 7B 등 총 10개 모델.
3. Activation Patching 기반 접근법
Activation Patching은 특정 레이어의 hidden state를 수정하여 모델의 동작을 제어합니다.
- : 원래 hidden state 비중 (TV는 0, FV는 1)
- : steering strength 조절 계수
- : steering vector
3.1 Function Vectors (FV)
(1) 목적
- 특정 태스크 수행 시 중요한 어텐션 헤드들의 평균 활성화 값을 추출하여 steering vector로 사용.
(2) 벡터 생성 과정
- 어텐션 헤드 활성화 평균 계산
- : 레이어 ℓ의 헤드 j의 활성화 값
- : 해당 태스크의 모든 prompt 집합
- 중요 헤드 선택
- **Causal Mediation Analysis (Pearl, 2009)**로 가장 영향력이 큰 헤드 선택 → 집합 .
- Function Vector 생성
- 패치 적용
- 선택된 레이어 의 hidden state에 추가:
- 선택된 레이어 의 hidden state에 추가:
(3) 주요 하이퍼파라미터
| 파라미터 | 설명 |
|---|---|
| n ( 크기) | 선택할 상위 헤드 수 (예: 2, 16, 32, …, 1024) |
| λ | steering 강도 (예: 0.5, 1, 2, 4, …, 64) |
| ℓ | 패치를 적용할 레이어 위치 |
3.2 Task Vectors (TV)
(1) 목적
- 특정 태스크의 예시(prompt) 전체를 하나의 vector로 압축하여 사용.
(2) 벡터 생성
- 태스크 prompt 를 모델에 입력.
- 특정 레이어 의 hidden state 를 추출.
- 이를 그대로 Task Vector로 사용:
(3) 적용
- TV는 α=0으로 기존 hidden state를 완전히 교체:
- 보통 λ=1 고정.
4. 실험 설계
4.1 ICL 태스크
- 총 11개 태스크 사용:
- 영어 단어의 반의어 생성
- 동사의 과거형 변환
- 국가 → 수도
- 영어 ↔ 불어/독일어/스페인어/이탈리아어 번역
4.2 모델 스펙트럼
- 14개 모델 패밀리, 36개 모델
- 크기 범위: 1.5B ~ 70B
- 대표 모델:
- GPT-J
- Pythia
- LLaMA 1, 2, 3
- Mistral v0.1, v0.3
- Qwen 2, 2.5
- OLMo, OLMo 2
- Gemma 2
- Amber
- Falcon 3 등
5. 평가 지표
| Steering 기법 | 평가 지표 |
|---|---|
| DoLa | TruthfulQA → MC1, MC2, MC3 / FACTOR → Accuracy |
| FV / TV | 0-shot 성능이 5-shot ICL 성능의 몇 %까지 복원되는가 |
- 예: 5-shot 성능의 50% 이상 복원 → steering이 절반의 효과를 내는지 측정.
6. 핵심 포인트
- DoLa는 사실적 지식이 특정 레이어에서만 점진적으로 축적된다는 가정에 의존 → 다양한 모델에서 실패.
- Function Vector는 중요한 어텐션 헤드만 조작하면 충분하다는 가정 → 실제로는 많은 헤드가 필요.
- Task Vector는 FV보다 안정적이나 특정 레이어 선택이 매우 중요하고 모델 간 변동성 큼.
- 실험 전반에서 하이퍼파라미터와 모델 선택에 극도로 민감.
7. 시각적 비교
| 특징 | DoLa | Function Vector (FV) | Task Vector (TV) |
|---|---|---|---|
| 기반 | Logit Lens | Activation Patching | Activation Patching |
| 데이터 필요 | 없음 | Task Prompt 필요 | Task Prompt 필요 |
| 수정 범위 | 확률 분포 | 선택된 헤드 | 전체 hidden state |
| 하이퍼파라미터 | Bucket, α | ℓ, λ, n | ℓ |
| 범용성 | 낮음 | 낮음 | 중간 |
8. 요약
방법론의 핵심은 모델의 내부 표현을 “조작”하여 모델 출력을 제어하는 것입니다.
그러나 본 논문의 실험 결과, 세 기법 모두 특정 모델과 태스크에서만 작동하고,
모델 간 일반화가 매우 취약함을 확인했습니다.
답글 남기기