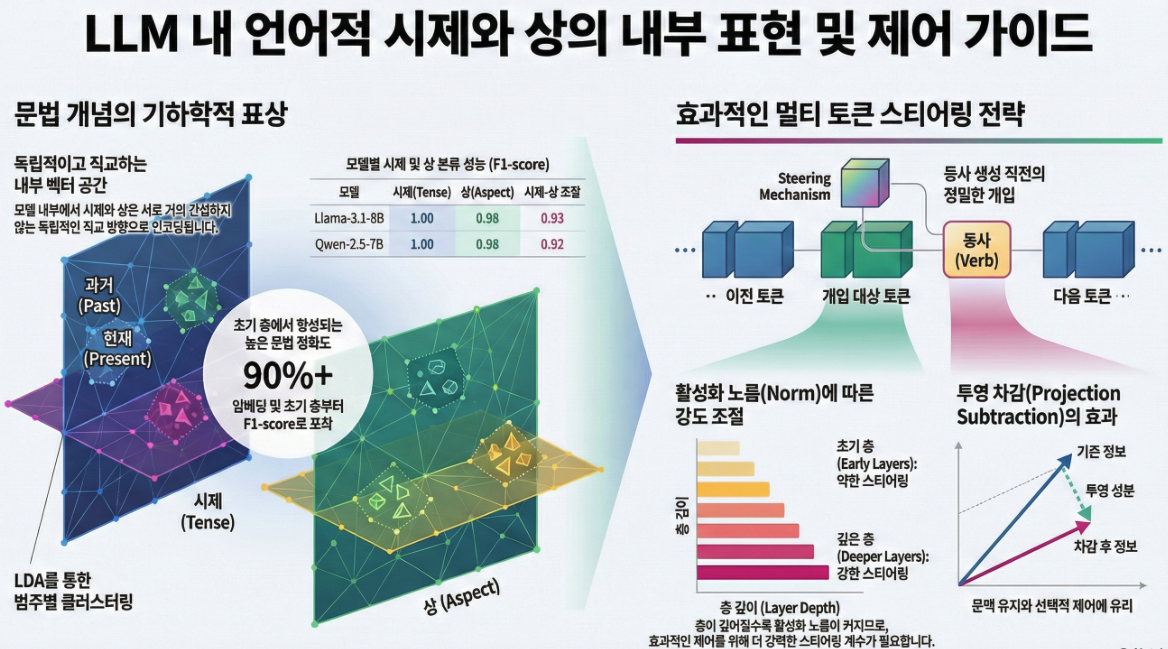
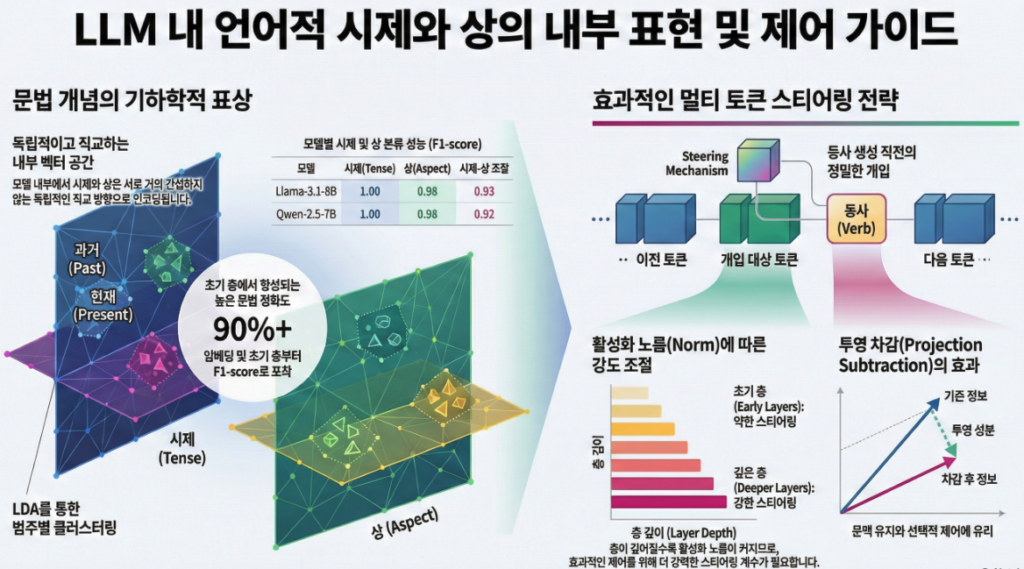
이 논문 “Steering Language Models in Multi-Token Generation: A Case Study on Tense and Aspect” (EMNLP 2025) 은 LLM 내부 표현에서 시제(tense) 와 상(aspect) 이 어떻게 구조적으로 표현되고, 이를 multi-token 생성 과정에서 조절(steering) 할 수 있는지를 체계적으로 분석한 연구입니다 .
아래는 핵심 내용을 정리한 해설입니다.
🧩 연구 배경
기존의 LLM 해석 연구는 주로
- 단일 토큰 수준(binary contrast) (예: 단수-복수, 긍정-부정)
- 행동적 평가(behavioral evaluation) — 예: perplexity, grammaticality benchmark
에 초점을 맞췄습니다.
하지만 실제 문법적 현상은 다차원적이고 조합적(multidimensional and compositional) 입니다.
저자들은 시제(현재·과거·미래) 와 상(단순·진행·완료·완료진행) 이라는 복수의 이산적·위계적 문법 속성을 선택하여,
이들이 LLM의 은닉 공간(residual space) 에 어떻게 선형적으로 부호화되는지,
그리고 해당 방향을 조작하여 생성 문법을 제어할 수 있는지를 탐구했습니다 .
⚙️ 방법론 요약
1. LDA 기반 문법 개념 탐색 (Representation Localization)
- Linear Discriminant Analysis (LDA) 를 변형하여 각 문법 범주(예: PAST, PRESENT, FUTURE)를 서로 독립적인 방향 벡터 ℓ̄₍ₜ₎ 로 계산함.
- 각 방향은 “그 클래스의 평균 활성화 차이”를 나타내며, 시제/상 간의 구조적 관계를 표현하는 feature subspace 형성.
- 실험 모델: Llama-3.1-8B-Instruct 와 Qwen-2.5-7B-Instruct.
결과: tense와 aspect는 서로 거의 직교(orthogonal) (cos ≈ 0.02)하며, 각 범주는 3D latent space에서 명확한 클러스터로 분리됨 .
2. Causal Steering in Multi-Token Generation
(1) 개념
각 토큰의 residual activation 에 대해 목표 개념 방향 을 추가 또는 조정함으로써
생성되는 문장의 시제나 상을 제어.
(2) 세 가지 steering 방식
| 방법 | 수식 | 설명 |
|---|---|---|
| TA (Target-Addition) | 가장 단순한 방법 | |
| TA + SS (Source-Subtraction) | 기존 시제/상을 억제 | |
| TA + Proj-SS | source 방향 성분만 제거 |
(3) 실험 과제
- Random Sentence — 자유 생성
- Repetition Task — 주어진 문장을 반복
- Temporal Translation — 문장을 다른 시제/상으로 “변환”
📊 주요 결과
(1) Steering 효과
- 시제(tense) > 상(aspect) : 시제가 훨씬 쉽게 제어됨.
- 무제약 생성보다 few-shot (복잡한) 태스크에서 제어가 어려움.
- Llama-8B < Qwen-7B 의 α 값: 모델별 activation norm 차이 때문.
(2) Selectivity 분석
- Source-subtraction(SS)은 선택성을 오히려 감소시킴. Projection subtraction은 이를 부분적으로 완화함 .
- 이는 시제와 상 벡터가 실제로는 완전히 독립적이지 않음을 시사.
(3) Layer 및 Strength 영향
- 깊은 레이어일수록 activation norm이 커져 더 큰 α 필요.
- 적절한 α 조정은 degenerate 출력(반복·비문 등)을 줄이는 핵심.
🧠 정성적 분석 (Qualitative Study)
| 위치 | 결과 |
|---|---|
| Prompt Steering | 효과 제한적 (특히 변환 task 에서는 실패) |
| Generation-time Steering | 가장 안정적·효과적 |
| Verb 이전 토큰에서 개입 | 가장 성공적, 문법적으로 일관된 결과 |
| Steering 지속시간 | 너무 길면 topic shift 및 degeneration 유발 |
예: “He is crying.” → (PAST steering) “He was crying.”
하지만 랜덤 생성에서는 시제는 변하지만 주제 전환 발생 .
🧩 결론 및 의의
- LLM은 시제와 상을 구조적으로 구분하여 인코딩 하며, 서로 거의 독립된 하위공간으로 표현함.
- 해당 방향을 조작해 문법적 속성(시제·상)을 인과적으로 제어 가능.
- 그러나 multi-token steering은 부작용(topic shift, degeneration) 에 민감하며, 강도·위치·지속시간 의 세 매개변수를 세밀히 조정해야 함.
- 자동화된 최적 steering 탐색 및 side-effect 모니터링 이 향후 과제.
🔍 연구 기여 요약
| 구분 | 기여 |
|---|---|
| Representation Analysis | LDA로 tense/aspect의 독립 방향 탐색 |
| Causal Steering | multi-token 단위 문법 제어 검증 |
| Empirical Findings | steering 강도·위치 · 모델 별 차이 정량 분석 |
| Linguistic Insight | 시제·상의 위계적 표상 및 인간 언어 유사 조직성 발견 |
요약하면,
이 논문은 **“시제와 상을 제어 가능한 인코딩으로서 조작해 LLM 문장 생성을 제어할 수 있다”**는 것을 보여주며, multi-token steering 의 효과와 한계를 정밀하게 규명한 대표적 연구입니다 .
아래는 논문 방법론(Methodology) 을 핵심 아이디어 → 수식 → 실험 설계 흐름으로 정리·해부한 설명입니다.
1️⃣ 문제 설정: 다차원 문법 개념의 표현 + 인과적 제어
- 대상 개념:
- 시제(Tense) = {past, present, future}
- 상(Aspect) = {simple, progressive, perfect, perfect progressive}
- 특징:
- 이산적(categorical)
- 조합 가능(tense × aspect)
- multi-token에 걸쳐 실현됨 (“will have been driving”)
➡️ 목표는
(1) 이 개념들이 LLM 잔차 스트림(residual stream) 에서 어떻게 표현되는지 찾고
(2) 그 방향을 generation 중에 개입해 문법을 바꾸는 것.
2️⃣ Step A — 문법 개념
위치 찾기(Localization)
A.1 선형 프로빙 (Linear Probing)
각 레이어 l에서 문장 전체의 hidden state를 집계한 뒤,
시제 / 상 / 시제-상 조합을 예측하는 multinomial logistic regression을 학습.
🔹 토큰 집계 방식
논문에서 가장 성능이 좋았던 방식:
- N: 문장 길이
- 이유: 길이 변화에 대해 안정적이며 다른 pooling보다 F1이 높음
➡️ 결과
- embedding layer 근처부터 시제/상 정보가 이미 강하게 존재
- depth가 깊어질수록 tense–aspect 조합 분리 성능 증가
3️⃣ Step B — 문법 개념을 벡터 방향으로 추출 (LDA 기반)
핵심은 Park et al. (2024) 의 categorical LDA 프레임워크를 확장한 것.
B.1 범주 개념을 “이진 특징들의 집합”으로 분해
예시 (TENSE):
- IS_PAST vs NOT_PAST
- IS_PRESENT vs NOT_PRESENT
- IS_FUTURE vs NOT_FUTURE
👉 각 범주를 서로 독립적으로 벡터로 추출 가능
B.2 LDA 변형을 이용한 방향 계산
각 이진 특징 w에 대해:
(1) 정규화된 방향 벡터
- 클래스 평균과 공분산의 pseudo-inverse 사용
- between-class covariance 제거 → 범주 간 구조를 강제하지 않음
(2) 스케일 반영된 최종 개념 벡터
➡️ 결과:
- 시제 3개 방향, 상 4개 방향이 residual space에 형성
- 서로 거의 직교(orthogonal)
B.3 Binary Contrast (잠재 차원 만들기)
범주 내부 비교를 위해 차이 벡터 사용:
➡️ 이를 통해
- tense 축
- aspect 축 을 형성 → 2D/3D 투영 시 명확한 군집
4️⃣ Step C — Multi-Token Steering(인과 개입)
이제 찾은 개념 벡터를 generation 중에 직접 주입.
C.1 개입 위치
- 레이어 l
- 각 generation step의 마지막 토큰 residual:
C.2 세 가지 Steering 전략
(1) TA (Target Addition) — 기본
- 가장 안정적
- 논문에서 전반적으로 최고 성능
(2) TA + SS (Source Subtraction)
- 기존 시제/상 제거 목적
- ❌ 실제로는 selectivity 감소
(3) TA + Projection-SS (부분 제거)
- source 방향 성분만 제거
- SS의 부작용 완화
5️⃣ Step D — 평가 프로토콜 (자동 + 구조적)
D.1 평가 태스크
- Random sentence generation
- Repetition (few-shot copy)
- Temporal translation (tense/aspect 변환)
D.2 평가 방식 (중요)
- 생성 후 다시 forward
- 개입 없이 probe 적용
- 사람이 직접 라벨링 ❌
정의된 지표
- Steering Success
- Degenerate Rate (반복, 비문, verb 누락)
- Efficacy = 성공 ∧ 비퇴행
- Selectivity = 다른 문법 속성 유지 여부
- Perplexity 변화
- BERTScore (topic shift 분석)
6️⃣ Step E — 위치·강도·지속시간 분석 (Case Study)
정량 실험 + 정성 분석을 통해:
핵심 발견
- ✔ Generation-time steering > Prompt steering
- ✔ 동사 직전 토큰에서 개입이 최적
- ❌ 너무 길게 개입 → topic shift / degeneration
- 모델별 activation norm 차이 → α 스케일 조정 필수
🔑 방법론 핵심 요약 (한 줄씩)
- LDA 기반 categorical direction 추출 → 다차원 문법 개념 처리 가능
- Residual stream 개입 → multi-token 문법 제어 가능
- TA만으로 충분 → source subtraction 불필요
- 위치·강도·지속시간이 steering 성패의 결정 변수
아래는 논문의 실험 결과(Experimental Results) 를
① 정량 결과 → ② 비교 분석 → ③ 정성 분석 → ④ 핵심 해석 구조로 정리한 설명입니다.
(steering 연구 관점에서 왜 이런 결과가 나왔는지에 초점을 둡니다)
1️⃣ 표현 분석 결과 (Probing & Geometry)
1.1 Probing 성능 (Table 1)
| Target | Llama-3-8B | Qwen-2.5-7B |
|---|---|---|
| Tense | 1.00 | 1.00 |
| Aspect | 0.98 | 0.98 |
| Tense–Aspect | 0.93 | 0.92 |
해석
- 시제/상 정보는 embedding layer 근처부터 매우 강하게 존재
- fine-grained한 tense–aspect 조합은 deeper layer에서 더 잘 분리됨 → 문법 정보가 early + compositional 하게 인코딩됨
1.2 LDA 투영 결과 (Figure 1–3)
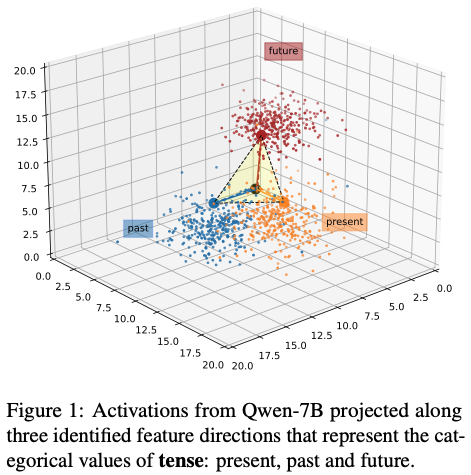
(1) 시제 (past / present / future)
- 3D 공간에서 3개 클러스터가 명확히 분리
- 설명 분산 ≈ 72%

(2) 상 (simple / progressive / perfect / perfect-progressive)
- 4개 군집 분리
- 설명 분산 ≈ 70%
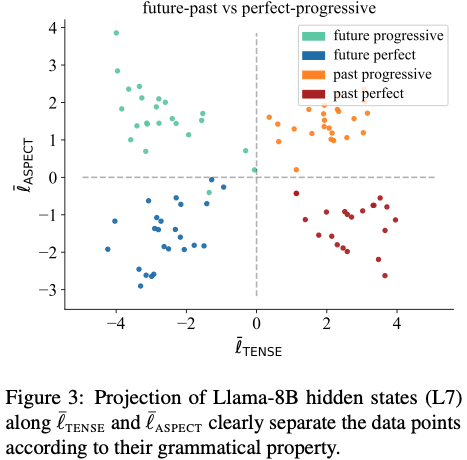
(3) 시제 vs 상 관계
- tense 축과 aspect 축의 cosine similarity ≈ 0.02
- → 거의 완전한 직교
핵심 결론
LLM 내부에서
- 시제 내부 값들은 structured subspace
- 시제와 상은 서로 독립적인 문법 차원 으로 표현됨
2️⃣ Steering 정량 결과 (Main Results)
2.1 Steering Efficacy (Figure 4)
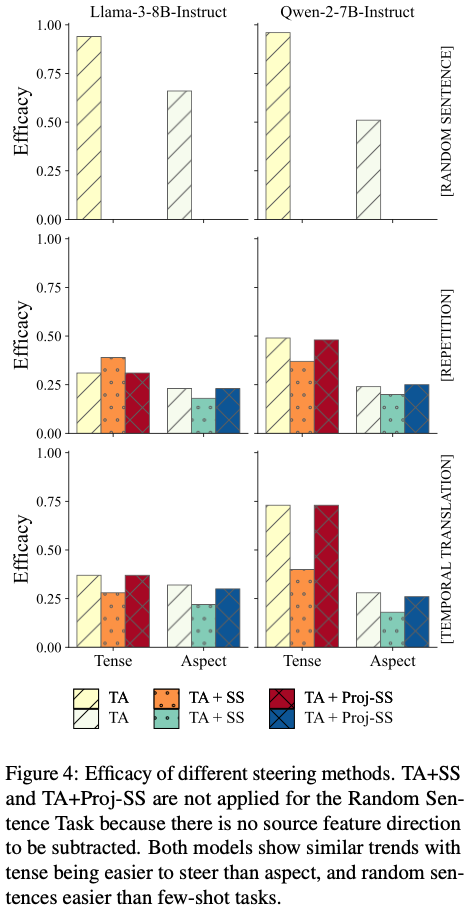
전체 경향
- Tense ≫ Aspect
- Random sentence ≫ Few-shot tasks
대표 수치
- Random Sentence:
- Tense: 94–96%
- Aspect: 51–66%
- Few-shot (Repetition / Translation):
- Tense 최고 ≈ 73%
- Aspect 최저 ≈ 18%
해석
- tense는 비교적 국소적 + 선형적
- aspect는 분산적·구성적(multi-token) → steering 어려움
2.2 Steering 방식 비교 (Figure 4 & 5)

(1) TA vs TA+SS vs TA+Proj-SS
| 방법 | Efficacy | Selectivity |
|---|---|---|
| TA | ✅ 최고 | ✅ 안정 |
| TA + SS | ❌ 감소 | ❌ 감소 |
| TA + Proj-SS | △ 회복 | △ 개선 |
중요한 발견
- source vector를 그대로 빼는 것은 오히려 해로움
- 이유:
- tense/aspect 방향이 완전히 독립적이지 않음
- residual stream에 불필요한 disturbance 유발
- projection subtraction은 부분 완화 효과
➡️ 실전 결론
categorical steering에서는 Target Addition만으로 충분
2.3 α (Steering Strength) 분석
| 모델 | 최적 α 범위 |
|---|---|
| Llama-8B | 5–25 |
| Qwen-7B | 100–250 |
원인 분석
- Qwen의 activation norm이 훨씬 큼
- 깊은 레이어일수록 norm ↑ → α도 ↑ 필요
➡️ α ≈ activation scale compensation
2.4 Perplexity 변화
- 대부분 시나리오에서 perplexity 증가 미미
- → steering은 fluency를 크게 해치지 않음
(단, 실패 케이스는 degeneration 동반)
3️⃣ 정성 결과 (Qualitative Analysis)
3.1 Topic Shift 분석 (Table 2)
| Task | BERTScore (↑ 유지) |
|---|---|
| Random Sentence | 0.56 |
| Repetition | 0.69 |
| Temporal Translation | 0.77 |
해석
- 자유 생성일수록 topic drift 큼
- few-shot은 context constraint 덕분에 안정
3.2 생성 예시 (Table 3, 4)
성공 케이스
- 시제는 정확히 바뀜
- 문법적 일관성 유지
실패 케이스
- 주제 전환
- 문장 의미 재작성
- 반복·중단 (degeneration)
중요
probe 기반 정량 지표만으로는 semantic side-effect를 포착 못함
4️⃣ Steering 위치·지속시간 분석 (Case Study)
핵심 발견 요약
| 요소 | 결과 |
|---|---|
| Generation-time vs Prompt | Generation-time 압승 |
| Verb 이전 개입 | 최고 성능 |
| Verb 이후 지속 개입 | topic shift ↑ |
| Prompt 전체 개입 | repetition만 부분 성공 |
직관적 해석
- 문법 결정은 verb 생성 직전에 집중됨
- 너무 이르면 덮어쓰기 실패
- 너무 늦으면 의미까지 교란
5️⃣ 실험 결과의 핵심 메시지 (정리)
✔ 가능한 것
- 시제·상은 실제로 제어 가능한 개념
- multi-token 문법도 steering 가능
- tense/aspect는 독립적 문법 축
⚠ 한계
- aspect는 여전히 어려움
- side effect (topic shift) 존재
- steering은 하이퍼파라미터 민감
🔑 실전 교훈
- TA only
- Generation-time
- Verb 직전
- α는 activation norm 기준으로
아래는 Park et al. (2024) 에서 제안된 categorical LDA (Categorical Linear Discriminant Analysis) 프레임워크 를 핵심 개념부터 수식까지 정리한 설명입니다.
(LLM interpretability / steering 연구에서 왜 이게 중요한지 를 중점으로 설명합니다.)
✅ 1. 왜 Categorical LDA가 필요한가?
전통적인 LDA (Linear Discriminant Analysis) 는
- 범주형(class) 구분
- 입력이 연속적
- 각 클래스가 정규성(gaussian) + 공분산 동일성(shared covariance) 가정
을 전제로 합니다.
하지만 LLM의 residual stream hidden activation 은
- 낮은 레이어는 gaussian에 가깝지만
- 깊은 레이어는 비정규적 + 비구형 분포 가 됨 → traditional LDA는 잘 동작하지 않음.
그리고 우리가 원하는 것은
➡️ 각 범주(categorical linguistic feature) 에 대한 “선형 방향(direction)” 을 찾는 것.
예) tense = {past, present, future}
→ 이들 범주 각각이 latent space에서 분리되는 방향
기존 LDA는 이 값들을 선형 축 하나로 모으면 범주 간 cluster structure 전체를 반영하지만, LLM steering/interpretation 관점에서는
👉 binary contrast(2-class) 마진 방향을 개별로 분류 하는 것이 더 의미있습니다.
✅ 2. 핵심 아이디어:
categorical LDA
categorical LDA는 다음을 만족합니다:
✔ 각 범주 w 에 대해 독립적인 direction vector 를 구한다
✔ 여러 클래스가 있어도 각각의 binary contrast 로 분해 가능
✔ high-dimensional, non-gaussian activation에 상대적으로 robust
즉,
“클래스 w vs not w” 를 분리하는 방향 벡터를 residual space에서 추출
하는 것이 목표입니다.
✅ 3. 기본 수식/정의
대표적으로 다음 3개의 개념이 등장합니다.
🔹 A. Binary Feature Indicator
각 범주에 대해:
- w = +1 if sample belongs to class w
- w = -1 otherwise
예: IS_PAST
→ tense가 past면 +1, 아니면 -1
이렇게 이진 target을 만들면
→ binary contrast 방향을 찾을 수 있습니다.
🔹 B. Between-class Expectation
예를 들어:
이는 class w의 평균 activation minus not-w의 평균 activation 을 나타냅니다.
🔹 C. Covariance + Pseudoinverse
이때 공분산 행렬 공식을 약간 변형합니다:
그런데 activation은 high-dimensional + rank-deficient이므로
→ pseudoinverse 사용
✅ 4. Direction Vector 계산
categorical LDA의 핵심 수식은 다음 두 단계입니다.
📌 Step 1:
Normalized direction
설명
✔ : class mean difference
✔ : covariance 구조에 맞춰 방향 보정
✔ 분모 정규화 : 순수한 방향만 남김
즉,
covariance 구조가 크거나 작은 축을 가중치로 설정
하는 효과.
📌 Step 2:
Scaled categorical direction
여기에 스케일을 붙이는 이유는:
✔ magnitude 정보를 보존 → downstream steering에서 효과가 큼
✔ 방향 + strength를 모두 반영
✅ 5. 왜 이게 좋은가? (직관적 설명)
| 특징 | 의미 |
|---|---|
| class w activation의 주 방향 | |
| 분포 흩어짐 + 축 약함 보정 | |
| normalized + scaled | direction + magnitude 유지 |
| independent w vectors | multi-category separability |
즉,
class별로 orthogonal에 가까운 heading vector를 찾고
residual stream에서 각 개념의 선형적 표현 구성 가능
합니다.
실제로 실험에서는
- tense vectors끼리 orth ≈ 0.02
- aspect vectors끼리도 분리됨 → 활성화 공간에서 구조화된 representation 이 존재합니다.
✅ 6. LDA vs 기존 Probe/Regression
| 방법 | output | 장점 |
|---|---|---|
| linear probe | scalar score | 범주 예측 정확 |
| PCA | 최대 분산 | 의미 없음 |
| LDA (traditional) | multi-class separation | gaussian 가정 |
| categorical LDA | binary contrast per category | scaling + covariance 보정 |
가장 큰 차이는:
👉 traditional LDA는 class 간 공통 subspace 를 찾지만
👉 categorical LDA는 각 category별 direction 을 뽑습니다.
이는 steering에서 방향 주입 → 개념 조작 으로 직결됩니다.
✅ 7. Practical Recipe
1️⃣ sample sentences with labels
2️⃣ compute per token
3️⃣ aggregate to sentence-level vectors
→ mean / sum-pool
4️⃣ compute for each w
5️⃣ compute
6️⃣ extract
7️⃣ scale →
이후 steering에서:
→ h := h + α
처럼 additive intervention 가능
🔁 요약
categorical LDA는
✅ 각 문법 범주의 steering 방향을 벡터로 분해
✅ covariance 구조까지 반영
✅ high-dimensional residual space에서 robust
한 방법입니다.
이 논문의 결과는 사실상 최근 activation steering 계열 방법들(CAA / SADI / FGAA / SAE) 을 하나의 공통 좌표계 위에 올려서 비교·재해석할 수 있는 교과서적인 사례입니다.
아래에서는 각 방법의 핵심 가정 → 이 논문의 실험 결과가 주는 해석 → 시사점 순서로 정리하겠습니다.
0️⃣ 공통 전제: 이 논문이 제공한 “기준 좌표계”
이 논문은 먼저 다음을 경험적으로 확정합니다.
- Tense / Aspect는 residual space의 선형 방향으로 존재
- 두 개념은 거의 직교 (cos ≈ 0.02)
- 각 category 내부(past/present/future)는 structured subspace 형성
- 이 방향은 causal (steering으로 실제 생성 변화)
➡️ 즉, “잘 정의된, 사람이 해석 가능한 개념 subspace” 가 실제로 존재함을 보여줌
이제 이를 기준으로 각 방법을 재해석합니다.
1️⃣ CAA (Contrastive Activation Addition) 관점
CAA의 핵심 가정
- 두 분포 A vs B (예: harmful vs harmless)
- 차이 벡터
- 이 벡터를 더하면 개념이 바뀐다
🔁 이 논문 결과의 CAA적 해석
(1) Categorical LDA = CAA의 정제된 일반화
- 이 논문의 는 본질적으로
- 단순 mean-diff보다:
- noise 축 제거
- category 간 leakage 감소
➡️ “CAA를 category-wise로, 더 정교하게 만든 형태”
(2) 왜 TA만으로 충분했는가?
- CAA에서도 종종 source subtraction 불필요
- 이 논문에서도:
- TA+SS → 성능 하락
- TA → 최고 성능
이유 (CAA 관점):
- target direction이 이미 decision boundary를 넘어감
- source를 빼면 불필요한 residual disturbance
➡️ CAA의 경험적 관찰을 문법 개념에서도 재현
✅ CAA 관점 핵심 메시지
Tense / Aspect는 “CAA가 가장 이상적으로 작동하는 개념”에 가깝다 (선형·직교·명확)
2️⃣ SADI (Semantics-Adaptive Dynamic Intervention) 관점
SADI의 핵심 가정
- 고정 steering vector는 불충분
- 토큰 / 위치 / 의미 상태에 따라 개입을 조절해야 함
- “언제, 얼마나”가 중요
🔁 이 논문 결과의 SADI적 해석
(1) Generation-time > Prompt steering
- SADI가 주장한 바 그대로:
- prompt-level 개입은 의미 결정 전에 너무 이르다
- generation-time이 semantic control에 핵심
이 논문:
- prompt steering → 거의 실패
- generation-time → 성공
➡️ SADI의 정당성 강화
(2) “Verb 직전 개입” 결과 = token-adaptive gating
- 논문:
- verb 직전 토큰에서만 개입할 때 최적
- 너무 길면 topic shift
이는 SADI에서 말하는:
- semantic relevance peak
- dynamic gating window
과 정확히 대응
(3) Aspect가 어려운 이유 (SADI 관점)
- aspect는:
- 여러 토큰에 분산
- auxiliary verb + main verb 조합
- → single-shot steering 불충분
➡️ SADI식으로는:
- aspect steering은
- multi-step
- token-aware
- adaptive α 필요
✅ SADI 관점 핵심 메시지
이 논문은 “왜 SADI가 필요한지”를 문법 개념으로 실증한 사례
3️⃣ FGAA (Feature-Guided Activation Addition) 관점
FGAA의 핵심 가정
- steering은 feature-level 로 해야 안정적
- coarse vector는 side effect 유발
- feature filtering + effect approximator 필요
🔁 이 논문 결과의 FGAA적 해석
(1) LDA direction = “manual feature selection”
- categorical LDA는 사실상:
- 문법적으로 정제된 feature 집합
- noise feature 제거된 상태
➡️ FGAA에서 말하는:
- “good feature set”을
- 사람이 문법 지식으로 설계한 셈
(2) Projection-SS가 SS보다 낫다
- FGAA 관점:
- full subtraction = 과도한 feature 제거
- projection = 필요한 성분만 제거
논문 결과:
- TA+SS ❌
- TA+Proj-SS ⭕ (부분 회복)
➡️ FGAA의 “feature-local intervention” 주장과 일치
(3) Aspect 실패 = feature entanglement
- aspect는:
- auxiliary verb
- tense overlap
- semantic duration
- → feature들이 얽혀 있음
FGAA 관점:
- disentangled feature 없이는
- selectivity ↓
- degeneration ↑
✅ FGAA 관점 핵심 메시지
이 논문은
“좋은 feature를 고르면 FGAA 없이도 된다”는 예시이자,
“나쁜 feature(aspect)는 FGAA가 필요하다”는 반례
4️⃣ SAE (Sparse Autoencoder) 관점
SAE의 핵심 가정
- LLM 내부에는 monosemantic feature가 존재
- 이를 SAE로 분해 가능
- steering은 feature on/off 로 해야 안정적
🔁 이 논문 결과의 SAE적 해석
(1) Tense = SAE-friendly feature
- 특성:
- 선형
- 직교
- 국소적
- → SAE로 깨끗한 feature 나올 가능성 높음
실제로:
- Brinkmann et al. (2025)에서도 tense SAE feature 존재
(2) Aspect = SAE가 필요한 영역
- aspect는:
- multi-token
- multi-head
- auxiliary verb circuit
- → 하나의 LDA 방향으로는 부족
SAE 관점:
- aspect는
- 여러 sparse feature의 조합
- feature-wise gating 필요
(3) Topic shift = SAE 부재의 결과
- LDA vector는 coarse
- SAE feature는 content-preserving control에 유리
➡️ 이 논문의 topic drift는
“SAE-level disentanglement가 없기 때문”
으로 해석 가능
✅ SAE 관점 핵심 메시지
이 논문은
“어떤 개념은 SAE 없이도 충분”
“어떤 개념은 SAE 없이는 불가능”
를 명확히 구분해 줌
5️⃣ 한 장으로 요약 (통합 비교)
| 관점 | 이 논문 결과의 의미 |
|---|---|
| CAA | categorical LDA = 정제된 CAA |
| SADI | 위치·타이밍 중요성 실증 |
| FGAA | feature quality가 전부 |
| SAE | aspect는 SAE 필요 영역 |
6️⃣ 메타 결론 (중요)
이 논문은
“steering 방법의 성능 차이는
알고리즘 차이 이전에
‘개념이 얼마나 선형·국소·분리되어 있느냐’에 달려 있다”
는 것을 보여줍니다.
즉,
- tense → CAA/LDA로 충분
- aspect → SADI + FGAA + SAE 필요
답글 남기기