





아래에서는 ACL 2025 논문 Personalized Text Generation with Contrastive Activation Steering(Zhang et al., 2025)을 기준으로 관련 연구, 방법론, 실험 결과를 구조적으로 정리해 설명합니다. 설명은 논문 본문(Sections 1, 3, 4, 5)과 표·그림(Table 1–3, Figure 1–5 등)을 종합한 것입니다.
1. 관련 연구 (Related Work)
1.1 Personalized Text Generation
기존 개인화 텍스트 생성 연구는 크게 두 계열로 나뉩니다.
- RAG (Retrieval-Augmented Generation)
- 사용자 히스토리 에서 입력 x와 의미적으로 유사한 과거 텍스트를 검색해 프롬프트에 삽입
- 장점: 학습 불필요, 비교적 단순
- 한계:
- 스타일–콘텐츠 얽힘: 검색은 의미 유사도 중심 → 스타일 신호 희석
- 확장성: 히스토리가 길수록 검색 지연 증가
- PEFT (Parameter-Efficient Fine-Tuning)
- 사용자별 LoRA/Adapter를 학습
- 장점: 스타일 반영이 비교적 정확
- 한계:
- 사용자마다 파라미터 저장 필요
- 잦은 업데이트/대규모 사용자 환경에서 비현실적
이 논문은 **“스타일을 텍스트/파라미터가 아닌 표현 공간(direction)으로 분리”**해야 위 한계를 동시에 해결할 수 있다고 주장합니다.
1.2 Activation Engineering
최근 연구들(Activation Addition, CAA 등)은
LLM 내부 활성값 공간에서 특정 행동/개념이 선형 방향으로 존재
함을 보여주었습니다.
- 대비(contrastive) 샘플 간 activation 차이를 벡터로 추출
- 추론 시 hidden state에 벡터를 더해 행동을 제어
본 논문은 이 아이디어를 **“사용자 고유 글쓰기 스타일”**에 최초로 본격 적용합니다.
2. 방법론 (Method)
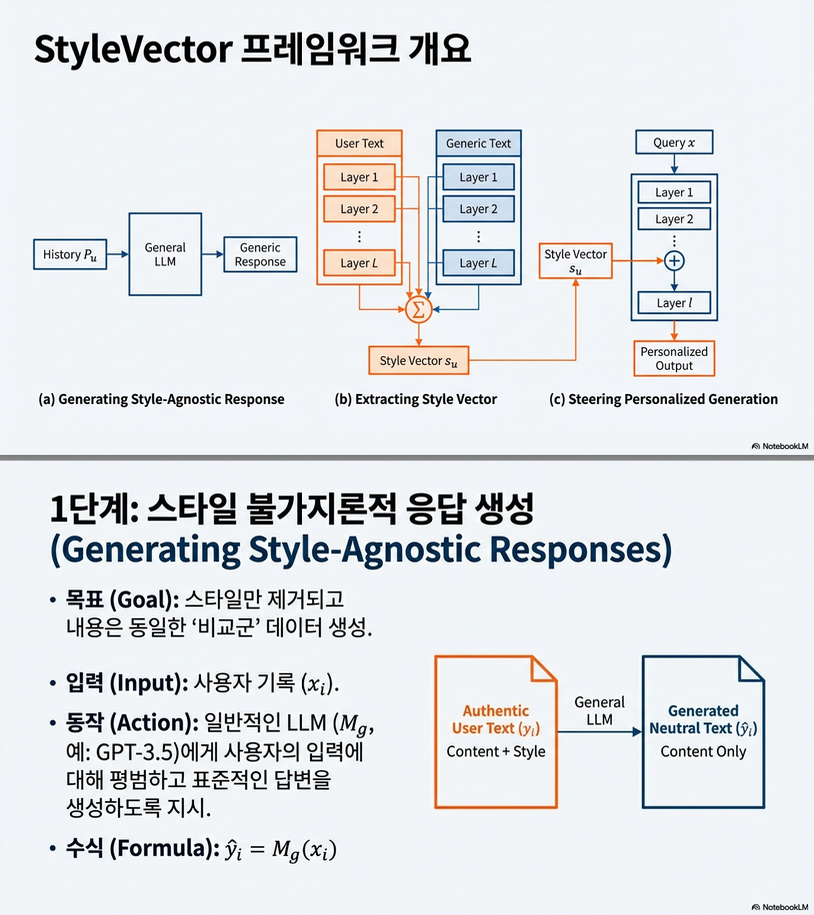
논문의 핵심 제안은 StyleVector라는 training-free 개인화 프레임워크입니다. 전체 흐름은 Figure 1에 요약되어 있습니다.
2.1 문제 핵심 아이디어
- 사용자 히스토리 응답 : 콘텐츠 + 스타일
- 일반 LLM이 생성한 응답 : 콘텐츠 중심, 스타일 중립
- → 두 응답의 activation 차이 = 스타일 신호
즉,
*“같은 의미를 말하지만, ‘누가 썼는가’에 따른 차이”*를 activation 공간에서 직접 분리
2.2 Stage 1: Style-Agnostic Response 생성
각 사용자 히스토리 쌍 에 대해
- : 사용자 스타일을 모르는 일반 LLM (GPT-3.5, DeepSeek 등)
- 목적: 콘텐츠는 유지, 스타일은 제거
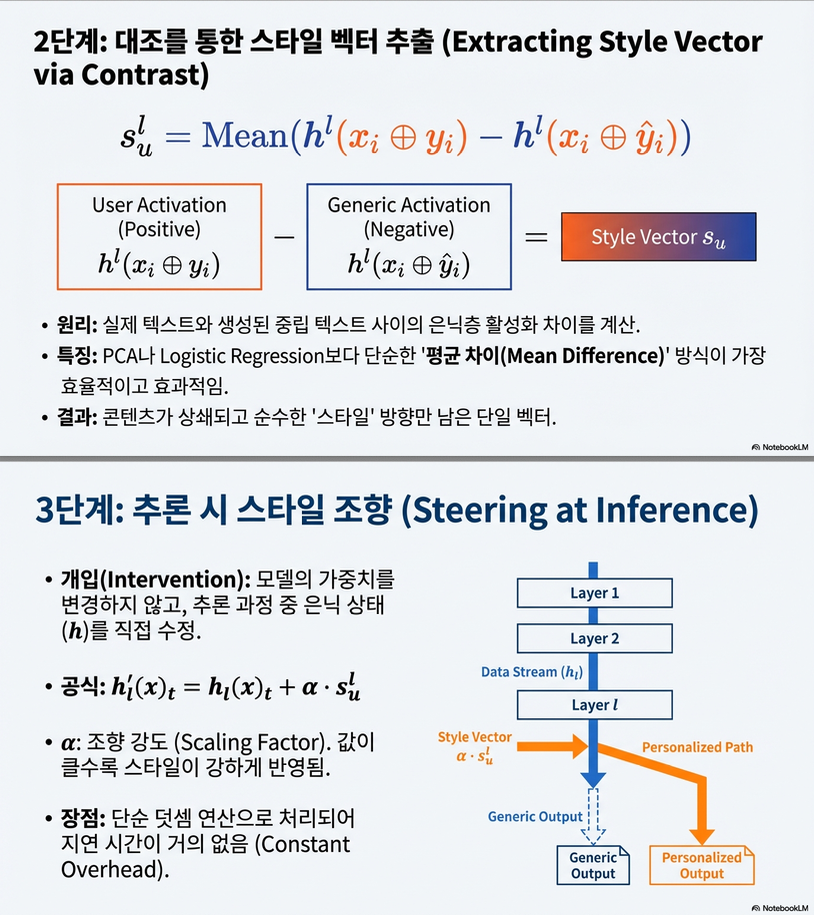
2.3 Stage 2: Style Vector 추출 (핵심)
레이어 에서 마지막 토큰 hidden state를 사용:
이후 사용자 u의 스타일 벡터 를 다음 중 하나로 계산:
- Mean Difference (기본 선택)
- 단순하지만 실험적으로 가장 안정적
- Logistic Regression Direction
- positive / negative activation을 분리하는 초평면의 법선 벡터
- PCA 기반 방향
- activation 차이의 분산을 최대화하는 주성분
👉 논문 실험에서는 Mean Difference가 성능·안정성 면에서 최선으로 나타남
2.4 Stage 3: Inference-Time Activation Steering
추론 시 레이어 의 hidden state에 선형 개입:
- : 스타일 강도 조절 파라미터
- 파라미터 업데이트 ❌, retrieval ❌
- O(1) 추가 연산만 발생
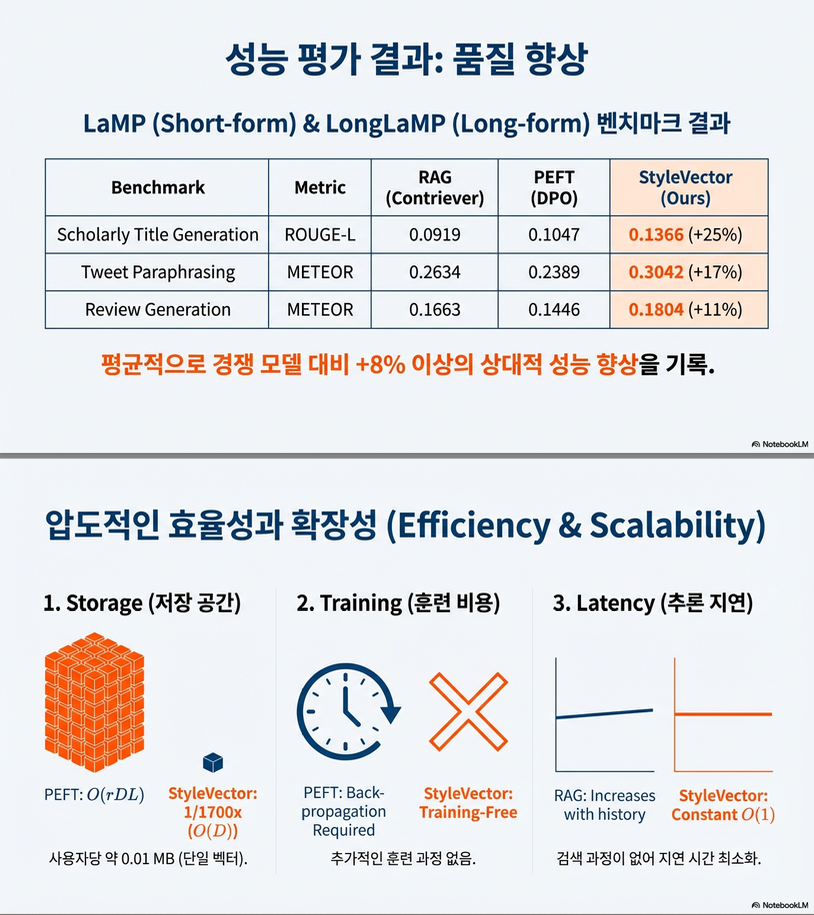
2.5 효율성 요약 (Table 1)
| 항목 | RAG | PEFT | StyleVector |
|---|---|---|---|
| 사용자별 학습 | ❌ | ⭕ | ❌ |
| 추론 지연 | O( | Pu | ) |
| 저장 공간 | 히스토리 전체 | LoRA 파라미터 | D 차원 벡터 1개 |
3. 실험 결과 (Experiments)
3.1 실험 설정
- 데이터셋: LaMP (short-form), LongLaMP (long-form)
- 모델: LLaMA-2-7B-chat
- 비교 대상:
- Non-personalized baseline
- RAG (BM25, Contriever)
- PEFT (LoRA-SFT, LoRA-DPO)
- 지표: ROUGE-L, METEOR
3.2 주요 성능 (Table 2)
- 모든 태스크에서 StyleVector가 최고 또는 차상위
- 평균적으로:
- ROUGE-L / METEOR 기준 약 8% 상대 성능 향상
- 특히:
- Scholarly Title, Tweet Paraphrasing 등 → 스타일 영향이 큰 태스크에서 큰 폭의 개선
3.3 효율성 비교 (Table 3)
- 저장 공간:
- PEFT 대비 약 1/1700
- 추론 지연:
- 사용자 히스토리 길이에 무관
- 현실적 대규모 배포 가능성을 명확히 입증
3.4 분석 실험
(1) Intervention Layer (Figure 2)
- 스타일 정보는 **중·후반 레이어(≈15층 이후)**에서 가장 효과적
- → 표현이 점진적으로 스타일 차원으로 정제됨
(2) Intervention Strength α (Figure 3)
- α > 0: 스타일 강화
- α < 0: 스타일 제거 (anti-style)
- 너무 크면 문장 붕괴 → 적정 범위 필요
(3) Probing 분석 (Figure 4)
- 모든 레이어에서 AUC > 0.85
- 깊어질수록 분리도 증가 → 스타일은 LLM 전반에 분산되지만, 후반부에서 선형적으로 가장 잘 드러남
3.5 Case Study (Figure 5)
- 실제 사용자 헤드라인 예시에서:
- StyleVector가 “:”, “Tips for”, “What … Need” 같은 반복 패턴을 정확히 포착
- RAG는 의미 유사 문서만 검색 → 스타일 실패
- Style ranking ≠ Semantic ranking → 스타일과 의미 분리가 왜 중요한지 직관적으로 보여줌
4. 정리 (한 줄 요약)
이 논문은 사용자 글쓰기 스타일을 LLM activation 공간의 선형 방향으로 모델링하고, 학습·검색 없이 inference-time 개입만으로 고성능 개인화 텍스트 생성을 달성한, activation steering 기반 personalization의 대표적 사례입니다.
답글 남기기