


1. 연구 배경 및 문제 설정
문제의식
- Ontology Engineering (OE) 는 복잡하고 수작업 중심이며, 논리/지식표현 전문성이 요구됨.
- 기존 방법론(Methontology, NeOn, XD 등)은 체계적이지만 자동화 수준이 낮음.
- LLM이 코드 생성·지식 추출 등 다양한 작업에서 성능을 보이므로, **“LLM이 OWL ontology 초안을 자동 생성할 수 있는가?”**가 핵심 질문.
2. 연구 질문 (RQs)
논문은 세 가지 질문을 다룸:
- LLM이 요구사항을 만족하는 ontology를 생성할 수 있는가?
- LLM 생성 ontology를 어떻게 평가해야 하는가?
- LLM 생성 ontology의 강점과 약점은 무엇인가?
3. 핵심 기여
(1) 두 가지 새로운 Prompting 기법 제안
- Memoryless CQbyCQ
- Ontogenia
(2) 다차원 평가 프레임워크 제안
- 단순 CQ coverage 외에도:
- OOPS! pitfall 분석
- Superfluous element 비율
- 전문가 정성 평가
(3) Benchmark Dataset 구축
- 10개 ontology
- 100개 CQ
- 29개 user stories
- 각 CQ에 대응하는 minimal ontology module 제공
4. 핵심 개념 정리
Ontology 정의
- Class, Object property, Data property, Axiom의 집합
Modelled CQ
- CQ를 검증할 수 있는 SPARQL query 작성에 필요한 모든 요소가 ontology에 존재하면 “modelled”
Minimal Ontology Module
- 특정 CQ에 필요한 최소한의 ontology 구성요소만 남긴 모듈
Superfluous Element
- 어떤 CQ 검증 SPARQL에도 사용되지 않는 class/property
5. 방법론
5.1 Ontology 생성 방식
(A) Independent Ontology Generation
- CQ 하나씩 독립적으로 생성
- 각 CQ별 minimal module 생성
(B) Incremental Ontology Generation
- 여러 CQ를 하나의 ontology로 통합 생성
- Story 단위로 cohesive ontology 생성
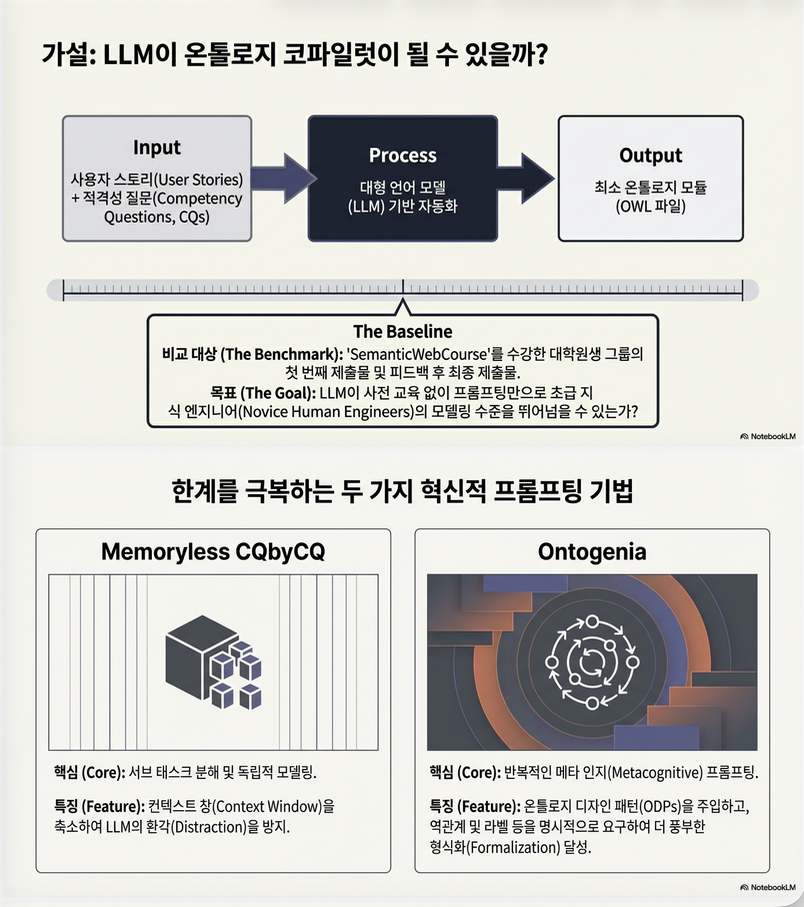
6. 두 가지 Prompting 기법
6.1 Memoryless CQbyCQ
특징
- CQ를 하나씩 독립적으로 모델링
- 이전 ontology 상태를 context에 제공하지 않음
- context size 약 60% 감소
의도
- 긴 context → LLM distraction 문제 해결
- partial solution 병합은 human-in-the-loop 처리
장점
- CQ coverage 높음
- 단일 CQ 모델링에 강함
단점
- superfluous element 증가
- 구조적 일관성 부족 가능성
6.2 Ontogenia
기반
- Metacognitive Prompting (CoT 확장)
- eXtreme Design methodology 통합
- Ontology Design Pattern (ODP) 활용
단계적 구성
- 요구사항 해석
- CQ 분해
- ODP 선택 및 통합
- 모델 확장 (restriction, rule)
- reasoning 기반 self-validation
특징
- iterative re-evaluation 포함
- labels, comments, inverse relation 명시 요청
7. 평가 체계
7.1 Proportion of Modelled CQs
- 가장 기본적인 정량 평가
7.2 OOPS! Pitfall Scanner
- Critical modeling 오류 탐지
- 대표 오류:
- multiple domain/range
- wrong inverse property
- missing namespace
7.3 Structural Analysis
- superfluous class/property 비율
7.4 Expert Qualitative Evaluation
- 두 명의 ontology expert 평가
- Cohen’s κ = 0.61 (substantial agreement)
8. 주요 실험 결과
Independent Generation
| Method | CQ Coverage |
|---|---|
| Memoryless CQbyCQ | 0.91 |
| Ontogenia | 0.84 |
→ minor issue 무시 시 0.94 / 0.89
Incremental Generation
최고 성능 조합:
OpenAI o1-preview + Ontogenia
- 학생 baseline보다 유의미하게 높음
- 기존 SOTA(CQbyCQ)보다 우수
문제점
(1) Multiple domain/range 문제
OWL에서 multiple rdfs:domain은 intersectionOf 의미
→ 원치 않는 inference 또는 inconsistency 발생
(2) Superfluous 요소 다수 생성
예:
- employedSince
- employmentStartDate
같은 의미의 property 중복 생성
9. 모델 비교
| Model | CQ Coverage | 구조적 품질 |
|---|---|---|
| o1-preview | 최고 | 상대적으로 안정 |
| GPT-4 | 중간 | 적당 |
| Llama-3.1 | CQ는 괜찮음 | superfluous 매우 많음 |
→ Open-source LLM은 아직 ontology co-pilot 수준 미달
10. 다차원 평가의 중요성
논문에서 매우 중요한 주장:
단일 metric은 ontology 품질을 평가할 수 없다.
예:
- CQ coverage 높아도
- superfluous 많으면 실사용성 낮음
- OOPS! critical 오류 있으면 위험
따라서:
Coverage + Structural quality + Pitfall + Expert review를 모두 고려해야 함.
11. 한계점
- 데이터 leakage 가능성
- multi-module ontology 실험 부족
- superfluous 제거 자동화 미흡
- history-dependent modeling에는 memoryless 기법 부적합
12. 결론
요약
- LLM은 novice ontology engineer 수준 이상 가능
- 특히 o1-preview는 실질적 co-pilot 가능성 보임
- 그러나:
- domain/range 오류
- inverse 오류
- superfluous 요소
- 구조적 일관성 문제 존재
13. 연구적 관점에서의 해석
이 논문은 단순 “LLM 잘한다”가 아니라:
- Prompt design이 ontology 품질에 미치는 영향
- Context size vs Quality trade-off
- Ontology evaluation framework의 다차원성 필요성
을 구조적으로 분석했다는 점에서 의미 있음.
방법론 정리 (Methodology)
본 논문의 방법론은 단순 “LLM에게 ontology 생성 요청”이 아니라,
(1) 구조화된 dataset 설계 →
(2) prompting 전략 설계 →
(3) 생성 방식 분리 →
(4) 다차원 평가 체계 구축
이라는 실험 프레임워크 전체 설계에 초점이 있다 .
아래에서 단계별로 정리한다.
1. Dataset 설계
1.1 Ontology 선택 기준
선택 조건:
- (i) Competency Questions (CQs) 포함
- (ii) User Stories 포함
이는 eXtreme Design (XD) 방법론 기반.
1.2 Dataset 구성
- 10개 ontology
- 100개 CQ
- 29개 user stories
- 각 CQ에 대해 minimal ontology module 구축
1.3 CQ 난이도 분류
| 유형 | 개수 | 난이도 |
|---|---|---|
| Data Property | 10 | Simple |
| Object Property | 25 | Simple |
| Reification | 62 | Complex |
| Restriction | 3 | Complex |
→ 대부분이 Reification (62%) → 고난도 모델링 문제 포함
1.4 Minimal Ontology Module 생성 절차
각 CQ에 대해:
- 중복 CQ 제거
- superfluous element 제거
- 최소 class/property만 유지
- 두 명의 ontology engineer cross-check
이렇게 만들어진 minimal module이 gold standard 역할을 수행한다.
2. Ontology 생성 방식 (Generation Setting)
논문은 생성 방식을 두 가지로 분리한다.
2.1 Independent Ontology Generation
정의
- CQ 하나씩 독립적으로 모델링
- 각 CQ → 독립 OWL module 생성
목적
- CQ 단위 모델링 능력 평가
- inter-CQ dependency 제거
장점
- 순수 모델링 능력 평가 가능
- 오류 분석 용이
2.2 Incremental Ontology Generation
정의
- 하나의 story에 포함된 여러 CQ를 통합 생성
- 최종적으로 하나의 cohesive ontology 생성
두 가지 구현 방식
| 방식 | 설명 |
|---|---|
| Memoryless merge | CQ별 생성 후 최종 병합 |
| Ontogenia incremental | 매 단계마다 이전 ontology 포함 |
3. Prompting 기법
이 논문의 핵심.
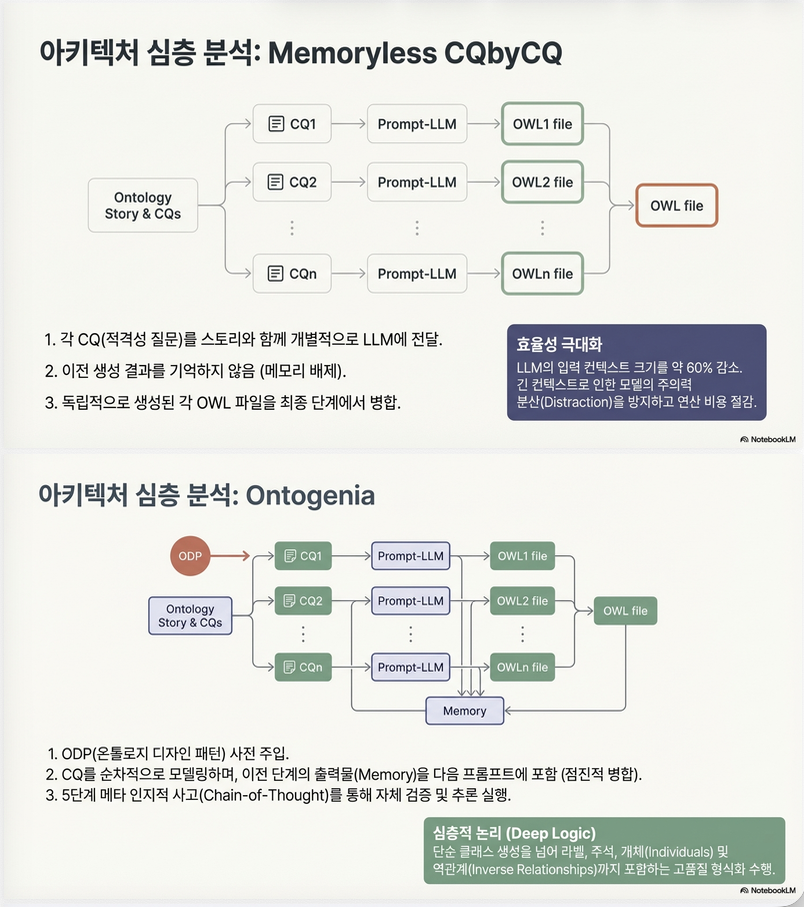
3.1 Memoryless CQbyCQ
기본 아이디어
- CQ 하나씩 모델링
- 이전 ontology를 context에 제공하지 않음
- context size 약 60% 감소
Prompt 구성 요소
- Ontologist persona 부여
- Turtle syntax 지침 제공
- User story 포함
- CQ 포함
- Common pitfalls 명시
핵심 직관
긴 context → LLM distraction → 성능 저하
따라서:
Memory 제거 → 독립 modeling → 나중에 병합장단점
장점
- 높은 CQ coverage
- 단순 CQ에 강함
단점
- superfluous 증가
- global consistency 낮음
3.2 Ontogenia
기반 이론
- Chain-of-Thought (CoT)
- Metacognitive Prompting (MP)
- eXtreme Design
- Ontology Design Patterns (ODP)
단계 구조 (5단계)
① 요구사항 해석
- story + CQ 분해
② 모델 구성
- class / property 식별
③ ODP 선택 및 통합
- pattern 기반 formalization
④ 확장
- restriction, rule 추가
⑤ Self-evaluation
- instance 생성
- reasoning 검증
특징
- labels / comments 명시 요청
- inverse property 명시
- iterative re-evaluation
4. 실험 세팅
사용 LLM
- GPT-4-1106
- OpenAI o1-preview
- Llama-3.1-405B-instruct
Hyperparameter
- GPT-4: temperature=0
- o1, Llama: default
5. 평가 체계
이 논문의 방법론적 강점.
5.1 Proportion of Modelled CQs
정의:
Score =
Minor issue 무시한 relaxed score도 계산.
5.2 OOPS! Pitfall Analysis
Critical error만 집계:
- Multiple domain/range
- Wrong inverse
- Cyclic hierarchy
- Namespace 오류
5.3 Structural Analysis
Superfluous rate 계산:
Class / Object property / Data property 별로 계산.
5.4 Expert Evaluation
두 명의 KE 전문가 평가:
- Usability
- Completeness
- Accuracy
- CQ adequacy
Cohen’s κ = 0.61
6. 전체 방법론 구조 요약
Dataset 설계
↓
Prompting 설계 (Memoryless vs Ontogenia)
↓
Generation 방식 분리 (Independent vs Incremental)
↓
다차원 평가
- CQ coverage
- Pitfall
- Structural
- Expert review7. 방법론의 핵심 통찰
1. Context size는 성능에 직접 영향
- Memoryless > CQbyCQ
- 긴 context → distraction
2. Coverage ≠ Quality
CQ 많이 맞춰도:
- superfluous 많으면 실사용성 낮음
- domain/range 오류 치명적
3. Prompt engineering이 ontology 품질을 결정
단순 CoT가 아니라:
- ODP injection
- iterative reflection
- meta-evaluation
이 성능 차이를 만든다.
8. 연구 설계의 장점
- multi-dimensional evaluation
- minimal module gold standard
- novice baseline과 비교
- open vs closed model 비교
9. 연구 설계의 한계
- multi-module ontology 실험 부족
- superfluous 자동 정제 없음
- history-dependent modeling에는 memoryless 부적합
🔎 연구적으로 보면
이 논문은:
“LLM이 ontology를 만들 수 있는가?”
가 아니라
“LLM 기반 ontology generation을 어떻게 실험 설계해야 하는가?”
에 대한 methodological contribution이 더 크다.
실험 결과 정리
논문은 두 가지 생성 설정(Independent / Incremental)과 세 가지 모델(GPT-4, o1-preview, Llama-3.1)을 비교하며, 다차원 평가 체계(Coverage, OOPS!, Structural, Expert)를 통해 결과를 분석한다 .
1. Independent Ontology Generation 결과
설정
- CQ 하나씩 독립 모델링
- GPT-4 사용
- Memoryless CQbyCQ vs Ontogenia 비교
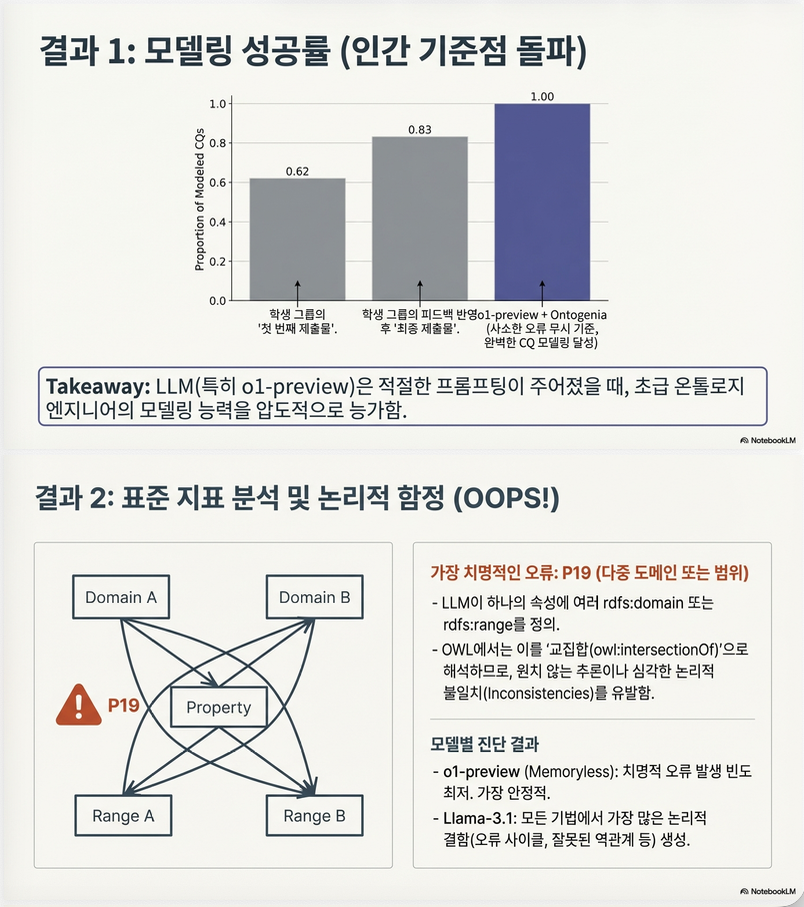
CQ Coverage
| Method | Strict | Minor Issue 무시 |
|---|---|---|
| Memoryless CQbyCQ | 0.91 | 0.94 |
| Ontogenia | 0.84 | 0.89 |
해석
- 단일 CQ 모델링에서는 Memoryless가 가장 안정적
- Minor issue(객체 property 1개 누락 등)를 무시하면 두 방법 모두 0.9 이상
- 복잡 CQ(Reification, Restriction)에서는 성능 급락
- 특히 reification 모델링이 어려움
2. Incremental Ontology Generation 결과
설정
- 하나의 story에 속한 여러 CQ를 통합 생성
- 세 모델 비교:
- GPT-4
- OpenAI o1-preview
- Llama-3.1-405B
CQ Coverage (전체)
최고 성능 조합:
Ontogenia + OpenAI o1-preview
- 학생 baseline보다 유의미하게 높음
- 기존 SOTA(CQbyCQ)보다 우수
전반적 경향
| 모델 | 성능 경향 |
|---|---|
| o1-preview | 가장 높은 CQ coverage |
| GPT-4 | 안정적이나 o1보다 낮음 |
| Llama-3.1 | 단순 CQ는 괜찮으나 complex에서 약함 |
특히:
- Reification CQ에서 Llama 성능 저하
- Restriction CQ는 전체적으로 어려움
3. OOPS! Pitfall 분석
Incremental 설정에서 OOPS!로 critical error 분석.
주요 오류 유형
| Pitfall | 설명 |
|---|---|
| P19 | Multiple domains or ranges |
| P05 | Wrong inverse relationship |
| P06 | Cycles in class hierarchy |
| P39 | Ambiguous namespace |
모델별 경향
o1-preview
- Memoryless + o1 → 가장 적은 critical issue
- Ontogenia + o1 → 거의 zero 수준 domain 오류
GPT-4
- Multiple domain/range 문제 자주 발생
Llama-3.1
- Inverse 오류 다수
- domain/range 다수
- namespace 문제
- hierarchy cycle 발생
Multiple domain/range 문제
OWL에서:
→ 의미는:
이는 의도하지 않은 inference를 유발할 수 있음.
이 오류는 모든 모델에서 공통적으로 나타남.
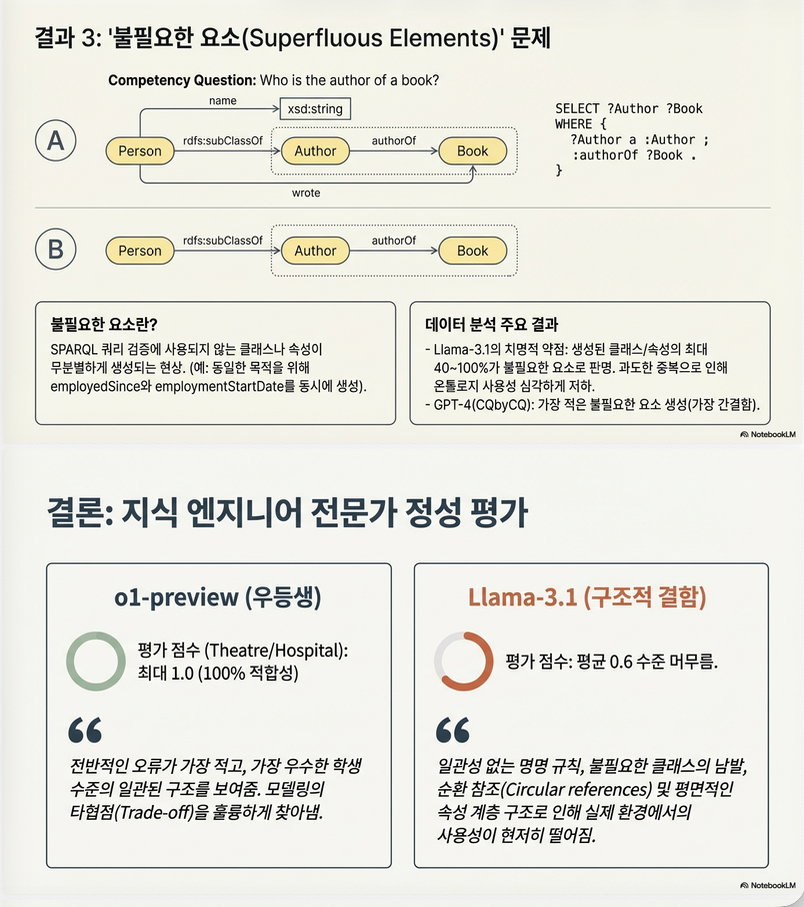
4. Structural Analysis (Superfluous Elements)
이 논문의 매우 중요한 결과.
Superfluous rate 계산:
결과 경향
CQbyCQ (기존 방법)
- superfluous 적음
Memoryless
- 중간 수준 (20~40%)
Ontogenia
- GPT-4: moderate
- o1: moderate
- Llama: 매우 높음 (최대 40~60%)
Llama 문제점
- 불필요한 class/property 대량 생성
- 거의 40% 수준
- 구조적 일관성 부족
예시 문제
- employedSince
- employmentStartDate
같은 의미 property 중복 생성
5. Expert Qualitative Evaluation
두 명의 ontology engineer 평가.
Cohen’s κ = 0.61 (substantial agreement)
Adequate CQ modelling (%)
| Story | Llama | o1-preview |
|---|---|---|
| Music (Ontogenia) | 0.86 | 0.96 |
| Theatre (Ontogenia) | 0.63 | 1.0 |
| Hospital (Ontogenia) | 0.66 | 1.0 |
전문가 평가 요약
Llama
- naming inconsistent
- redundant classes
- malformed cardinality
- flat hierarchy
- namespace 오류
o1-preview
- student 수준 이상
- Ontogenia와 결합 시 매우 우수
6. 전체 결과 요약
| 기준 | 최고 성능 |
|---|---|
| CQ Coverage | Ontogenia + o1 |
| Pitfall 최소 | Memoryless + o1 |
| Structural 안정성 | GPT-4 CQbyCQ |
| Expert 평가 | Ontogenia + o1 |
7. 중요한 통찰
(1) Context 줄이면 성능 개선
Memoryless > CQbyCQ
→ 긴 context가 오히려 성능 저하 유발
(2) Coverage ≠ Quality
CQ coverage 높아도:
- superfluous 많으면 실사용성 낮음
- domain/range 오류 치명적
(3) Closed model 우위
- Open-source Llama는 아직 ontology co-pilot 불충분
- o1-preview가 가장 현실적 대안
8. 논문의 핵심 메시지
LLM은:
- novice ontology engineer 수준 이상 가능
- draft ontology 생성에 유용
- 그러나:
- structural refinement 필요
- human-in-the-loop 필수
CQ (Competency Question) 예제 설명
이 논문에서 CQ는 ontology가 반드시 표현할 수 있어야 하는 질의이며,
LLM이 생성한 ontology의 요구사항 충족 여부를 검증하는 기준이다 .
아래는 논문에서 정의한 CQ 유형에 맞춰 예제를 체계적으로 정리한 것이다.
1. Simple CQ 예제
1.1 Data Property Modeling
CQ 예시
“What is the publication date of a book?”
필요 ontology 요소
- Class: Book
- Data property: publicationDate
- Domain: Book
- Range: xsd:date
Turtle 예시
:Book rdf:type owl:Class .
:publicationDate rdf:type owl:DatatypeProperty ;
rdfs:domain :Book ;
rdfs:range xsd:date .1.2 Object Property Modeling
CQ 예시
“Who is the author of a book?”
필요 요소
- Class: Book
- Class: Author
- Object property: hasAuthor
- Domain: Book
- Range: Author
:Book rdf:type owl:Class .
:Author rdf:type owl:Class .
:hasAuthor rdf:type owl:ObjectProperty ;
rdfs:domain :Book ;
rdfs:range :Author .2. Complex CQ 예제
논문에서 가장 어려웠던 유형은 Reification (62개).
2.1 Reification 예제
CQ 예시
“Which musician performed which song at which concert?”
여기서는 단순 triple로 표현 불가능:
Musician --performed--> Song만으로는 “어디서” 정보 표현 불가.
해결 방법: Event Reification
:Performance rdf:type owl:Class .
:hasPerformer rdf:type owl:ObjectProperty ;
rdfs:domain :Performance ;
rdfs:range :Musician .
:performedSong rdf:type owl:ObjectProperty ;
rdfs:domain :Performance ;
rdfs:range :Song .
:atConcert rdf:type owl:ObjectProperty ;
rdfs:domain :Performance ;
rdfs:range :Concert .→ Performance라는 중간 클래스를 도입.
2.2 Restriction 예제
CQ 예시
“Which patients have exactly one primary doctor?”
필요 표현
- Class: Patient
- Object property: hasPrimaryDoctor
- Cardinality restriction
:Patient rdf:type owl:Class ;
rdfs:subClassOf [
rdf:type owl:Restriction ;
owl:onProperty :hasPrimaryDoctor ;
owl:cardinality "1"^^xsd:nonNegativeInteger
] .3. Minor Issue 예제
논문 Appendix 예시 기반
CQ:
“Who is the author of a book?”
생성된 ontology:
- Book
- Author
하지만 object property 누락
→ property 하나만 추가하면 해결 가능
→ Minor Issue로 간주
4. Superfluous Element 예제
CQ:
“Who is the author of a book?”
생성된 ontology:
- Book
- Author
- Person
- name
- wrote
SPARQL 작성에 사용되지 않는:
- Person
- name
- wrote
→ superfluous
5. SPARQL 기반 CQ 검증 예제
CQ가 modelled되었는지 판단 기준은:
SPARQL query 작성 가능 여부
예:
SELECT ?author
WHERE {
?book rdf:type :Book .
?book :hasAuthor ?author .
}필요 요소가 ontology에 존재하면
→ CQ modelled로 판단
6. 실제 데이터셋 도메인 예시
논문 dataset 도메인:
- Hospital
- Music
- Theatre
- Semantic Web Course
- Polifonia
- Onto-DESIDE
- WHOW
- IKS
예시 (Hospital)
CQ:
“Which doctor treats which patient?”
예시 (Theatre)
CQ:
“Which actor performs which role in which play?”
→ reification 필요
7. CQ 난이도에 따른 LLM 성능 차이
| 유형 | LLM 성능 |
|---|---|
| Data Property | 매우 높음 |
| Object Property | 높음 |
| Reification | 낮음 |
| Restriction | 낮음 |
특히:
- Reification 구조 설계 능력이 핵심 병목
- Cardinality restriction은 문법 오류 자주 발생
8. 연구적 관점에서 중요한 점
CQ는 단순 질문이 아니라:
즉:
- CQ → graph pattern
- CQ → class introduction
- CQ → property typing
- CQ → logical restriction
을 강제한다.
답글 남기기