


다음 논문은 LLM을 활용한 온톨로지 개발 방법론을 제안하고, 이를 자율주행 차량의 Driver–Vehicle Interface(DVI) 도메인에 적용한 연구입니다.
1. 연구 목적과 문제의식
핵심 질문
- LLM(ChatGPT-4o)을 온톨로지 설계에 체계적으로 활용할 수 있는가?
- LLM의 생성 능력 + 인간 전문가 검증을 결합한 재사용 가능한 방법론을 만들 수 있는가?
동기
전통적인 온톨로지 개발은:
- 시간 소모적
- DL/OWL 전문지식 필요
- 개념 누락 및 설계 일관성 문제 발생 가능
LLM은:
- 개념 추출
- 클래스 구조 생성
- OWL 코드 생성
- 암묵적 관계 추론
이 가능하지만,
- hallucination
- 형식적 OWL 제약 위반
- 규제/법적 요소 누락
문제가 존재합니다.
따라서 이 논문은 Human-in-the-loop 기반 LLM 온톨로지 개발 프로세스를 제안합니다 .
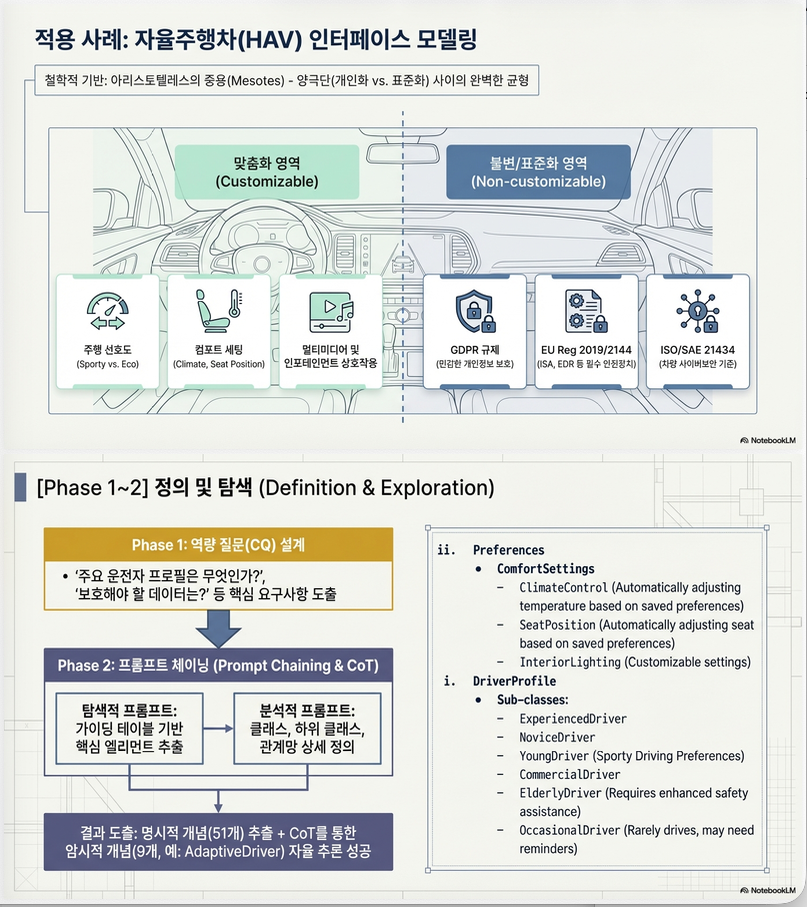
2. 전체 방법론 구조 (7단계)
논문에서 제안하는 프로세스는 아래와 같습니다 :
Phase 1. Theoretical Definition
- 도메인 정의
- 목적 정의
- Competency Questions(CQ) 설정
- 클래스/속성 초기 구조 설계
→ 전통적 Noy & McGuinness 방법론 기반
Phase 2. Exploration & Analysis (LLM 적극 활용)
여기서 LLM이 본격적으로 개입합니다.
(A) Exploration Prompts
- Table 2 형태로 요구사항을 구조화하여 입력
- 목적, 사용자, 규제, 커스터마이징 가능 여부 등 명시
(B) Analytic Prompts
LLM에게 다음을 생성하도록 요청:
- Classes / Subclasses
- Object properties
- Data properties
- Axioms
그리고 추가적으로:
- 암묵적 개념 추론
- OWL 제약 (intersection, union, restriction 등) 추가
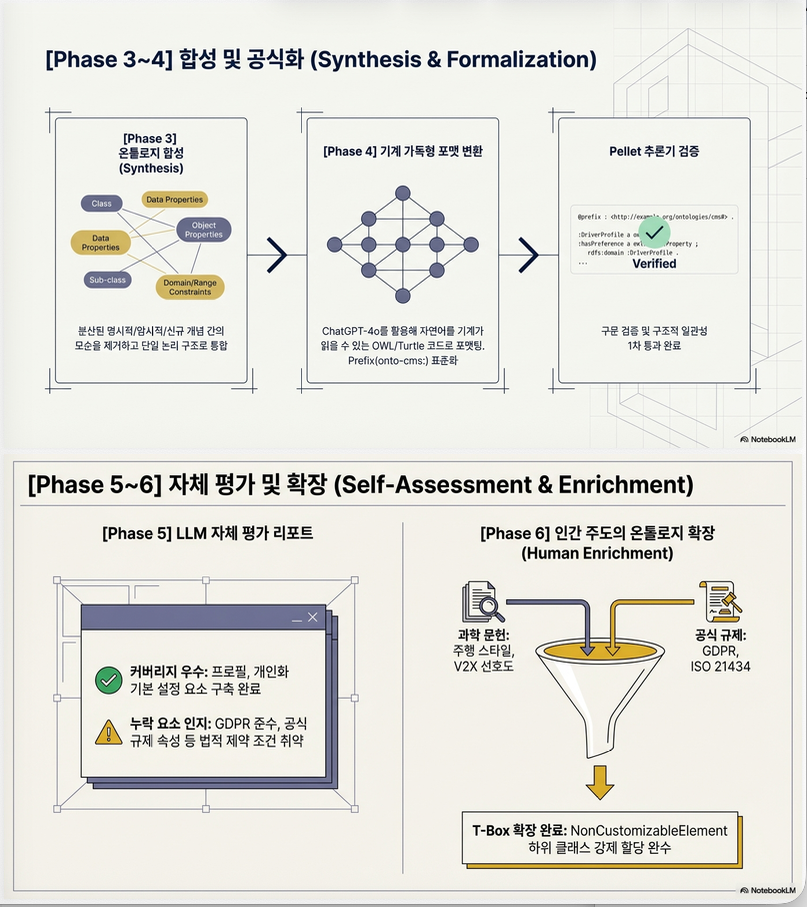
Phase 3. Ontology Synthesis
LLM이:
- 명시적 개념
- 암묵적 개념
- 신규 도입 개념
을 통합하여 하나의 구조로 합성
논문에서 정리한 결과 :
| 유형 | 개수 |
|---|---|
| Concepts | 65 |
| Relationships | 19 |
| Data Properties | 26 |
| Axioms | 21 |
Phase 4. OWL Formalization
Prompt로 OWL/Turtle 생성:
- rdfs:domain
- rdfs:range
- subClassOf
- disjointWith
- functional property
생성 후:
- Protégé + Pellet reasoner 검증
Phase 5. Self-Assessment (LLM 자기평가)
LLM에게 스스로 다음을 평가하도록 요청:
- Coverage
- Missing elements
- Innovations
- Improvement suggestions
예시 결과 :
- Privacy 규제 표현 부족
- GDPR compliance 누락
- Legal requirement 표현 없음
→ 인간이 보완
Phase 6. Ontology Enrichment
(A) 논문 기반 확장
HMI/AV 연구 논문 분석 후 클래스 추가
(B) 규제/표준 기반 확장
- EU Regulation 2019/2144
- GDPR
- ISO 15005
- ISO 26262
- UNECE R155
등을 반영하여
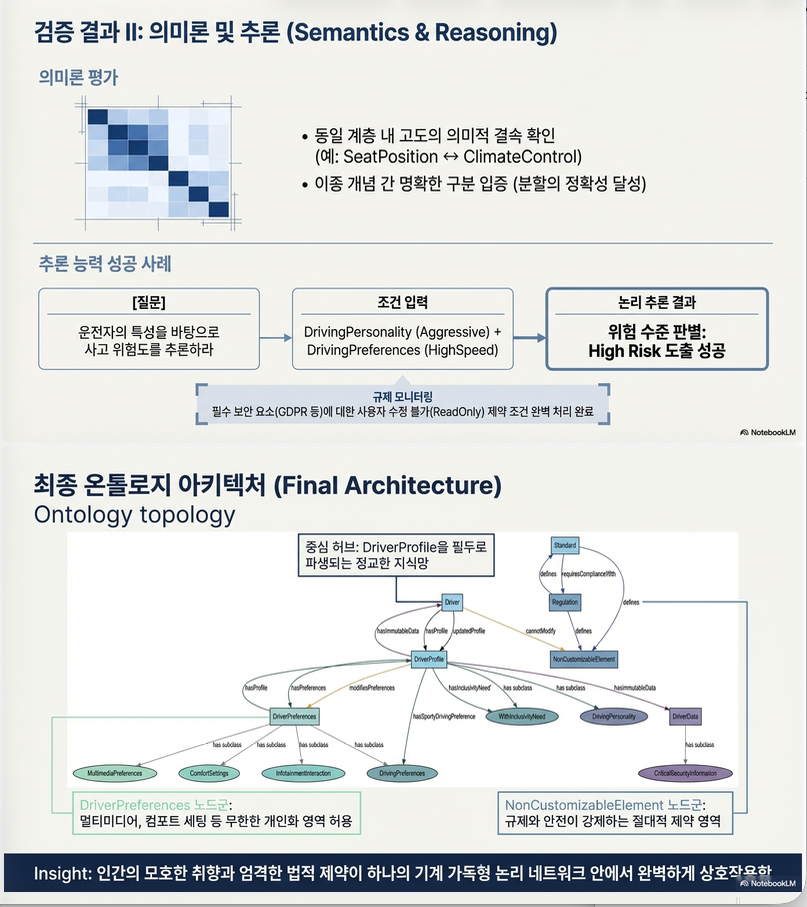
NonCustomizableElement 클래스로 규제 요소 명시 .
Phase 7. Technical Validation
(1) Logical consistency
- Pellet reasoner
- 디버깅 성공
(2) Structural metrics (OntoMetrics)
주요 수치 :
- 621 axioms
- 111 classes
- DL expressivity: ALCHIQ(D)
- inheritance richness = 0.90 (수평적 구조)
- attribute richness ≈ 0.15 (속성 부족 문제)
→ 전문가 지적 후 data property 추가
(3) Semantic similarity 평가
- Wu & Palmer similarity
- Li et al. similarity
결과:
- 같은 서브트리 내 클래스 → 높은 유사도
- 이질 도메인 간 클래스 → 낮은 유사도
→ taxonomic coherence 확인
(4) SPARQL 추론 테스트
Competency Questions 기반 질의 수행
예:
- 공격적 + 고속 선호 → High Risk 추론
- Calm + Expert → 적합 안전 시스템 자동 연결
모두 성공적으로 추론됨 .
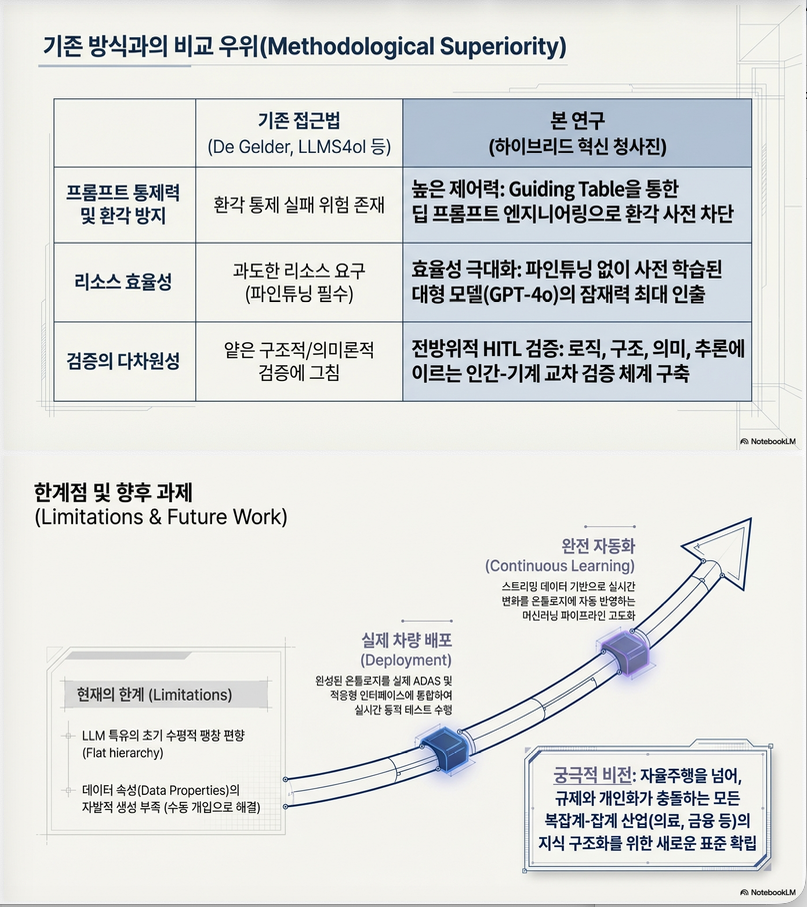
3. 핵심 기여
논문에서 강조하는 가장 중요한 기여는 다음입니다 :
① LLM-통합 온톨로지 방법론 제안
기존 연구들은:
- term extraction
- ontology learning task
- relation extraction
중심이었음
이 논문은:
→ end-to-end 개발 프로세스 통합
② Guiding Table (Table 2)
가장 중요한 설계 도구:
- 질문
- 답
- 예시
를 구조화한 테이블을 통해
LLM 생성 방향을 통제
→ hallucination 완화
→ 요구사항 추적성 확보
③ Human-in-the-loop 구조 명확화
두 역할 구분:
| 역할 | 설명 |
|---|---|
| User | 도메인 지식 보유 |
| Validator | 온톨로지 전문가 |
4. 한계
논문에서 명시한 한계 :
- 프롬프트 품질에 강하게 의존
- OWL 제약 자동 생성 미흡
- Data property 부족 문제
- 완전 자동화는 불가능
- 여전히 전문가 검증 필수
5. 연구적 관점에서의 의의
이 논문은 기술적으로는 혁신적 알고리즘을 제안한 것이 아니라:
“LLM을 실제 온톨로지 엔지니어링 워크플로에 어떻게 통합할 것인가?”
에 대한 방법론 논문입니다.
특히:
- Prompt engineering 기반 ontology engineering
- Self-assessment 기반 LLM 검증 루프
- 규제 기반 ontology enrichment
은 실무 적용성이 높습니다.
6. 요약
| 항목 | 내용 |
|---|---|
| 목적 | LLM 기반 온톨로지 개발 방법론 |
| 적용 도메인 | 자율주행 차량 DVI |
| 모델 | ChatGPT-4o |
| 검증 | Pellet + OOPS! + OntoMetrics + SPARQL |
| 핵심 기여 | Guiding Table + Human-in-the-loop 방법론 |
| 한계 | 완전 자동화 불가, 전문가 필수 |
다음은 논문의 **LLM-기반 온톨로지 개발 방법론(Methodology)**을 구조적으로 정리한 내용입니다. 이 방법은 전통적 온톨로지 공학 절차를 유지하면서, LLM을 단계별로 통제된 방식으로 통합하는 것이 핵심입니다 .
1. 전체 아키텍처 개요
논문은 7단계 순환적 프로세스를 제안합니다:
- Theoretical Definition
- Exploration & Analysis (LLM 중심)
- Ontology Synthesis
- Formalization (OWL 변환)
- Self-Assessment (LLM 자기평가)
- Enrichment (문헌·규제 통합)
- Technical Validation
이 과정은 전통적 Noy & McGuinness 방법론을 확장하여, 각 단계에 LLM을 “보조 엔진”으로 삽입한 구조입니다 .
2. Phase 1: Theoretical Definition
목적
- 도메인 범위 정의
- 온톨로지 목적 명확화
- Competency Questions(CQs) 설정
- 기본 클래스/속성 설계
특징
- 전통적 온톨로지 설계 방식 유지
- 아직 LLM을 사용하지 않음
- 이후 LLM 프롬프트의 구조적 기준점 제공
3. Phase 2: Exploration & Analysis (핵심 단계)
이 단계가 방법론의 중심입니다.
3.1 Guiding Table 기반 Few-shot Prompting
논문의 핵심 혁신은 Guiding Table (Table 2) 입니다 .
구성:
- 질문
- 답변
- 구체적 예시
예:
- 온톨로지 목적
- 접근 가능한 시스템 구성요소
- 커스터마이징 가능 요소
- 규제 기반 필수 요소
- 개인정보 보호 항목
효과
- 생성 방향 통제
- hallucination 감소
- 요구사항 추적성 확보
- 반복적 refinement 가능
3.2 Prompt 전략
(A) Exploration Prompts
- 도메인 개념 추출
- 주요 클래스 후보 생성
(B) Analytic Prompts
LLM에게 다음 구조를 명시적으로 요구:
- Classes / Subclasses
- Object Properties
- Data Properties
- Axioms (subClassOf, disjointWith 등)
(C) 암묵 개념 유도
LLM에게 명시되지 않은 개념을 추론하도록 요청
→ Explicit / Implicit / Newly introduced 개념 구분
4. Phase 3: Ontology Synthesis
LLM이 이전 단계 결과를 통합:
- 중복 제거
- 계층 정리
- 관계 정합성 유지
결과적으로:
- 명시 개념
- 암묵 추론 개념
- 신규 도입 개념
을 통합한 구조 생성 .
5. Phase 4: Formalization (OWL/Turtle 변환)
Prompt 예시 구조
- rdfs:domain / range 명시
- ObjectProperty 연결
- DataProperty 타입 정의
- OWL restriction 추가
생성 후:
- Protégé + Pellet reasoner 검증
여기서 인간이:
- namespace 정리
- domain/range 수정
- cardinality 보완
6. Phase 5: Self-Assessment (LLM 자기검증)
LLM에게 다음을 평가하도록 함:
- Coverage adequacy
- Missing elements
- Innovations
- Improvement suggestions
예:
- GDPR 미반영 지적
- 규제 표현 부족 지적
→ Human refinement로 이어짐
7. Phase 6: Ontology Enrichment
(A) 학술 문헌 기반 확장
HMI/AV 논문 분석 → 클래스 추가
(B) 규제 기반 확장
- EU Regulation 2019/2144
- GDPR
- ISO/SAE 21434
- UNECE R155 등
→ NonCustomizableElement 하위에 통합
이 단계는 완전 자동이 아니라:
- 문헌 분석: 수동
- 구조 통합: LLM 보조
- 제약 정의: 인간
8. Phase 7: Technical Validation
8.1 Logical Consistency
- Pellet reasoner
- OWL satisfiability 확인
8.2 Structural Metrics
- OntoMetrics 활용
- inheritance richness, attribute richness 분석
8.3 Semantic Similarity
- Wu & Palmer
- Li et al. similarity
→ taxonomic coherence 검증
8.4 SPARQL 기반 CQ 검증
- 추론 테스트
- 규칙 기반 위험 추론 성공
9. 방법론의 구조적 특징
① Classical Ontology Engineering 유지
- Domain → Terms → Hierarchy → Formalization → Validation
② LLM 통합 위치 명확화
LLM은:
- 개념 생성기
- OWL 코드 생성기
- 자기평가 도구
하지만:
- 최종 검증자는 인간
③ Human-in-the-loop 구조
| 역할 | 기능 |
|---|---|
| User | 도메인 설계 |
| LLM | 구조 생성 |
| Validator | 논리 검증 |
10. 방법론의 이론적 의의
이 방법론은 단순한 ontology learning이 아니라:
“LLM 기반 온톨로지 엔지니어링 프로세스 설계”
라는 점에서 의미가 있습니다.
기존 연구들이:
- term typing
- relation extraction
- ontology population
수준에 머문 반면,
이 논문은:
- 설계
- 합성
- 형식화
- 검증
- 규제 통합
까지 포함한 end-to-end 프레임워크를 제안합니다 .
11. 핵심 요약
| 단계 | 인간 | LLM | 도구 |
|---|---|---|---|
| Theoretical | ✓ | ||
| Exploration | ✓ | ✓ | Prompt |
| Synthesis | ✓ | ||
| Formalization | ✓ | ✓ | OWL |
| Self-check | ✓ | ||
| Enrichment | ✓ | ✓ | Literature |
| Validation | ✓ | Pellet, OOPS |
다음은 **실험 결과(Section 5–6)**를 정리한 내용입니다. 본 논문은 새로운 학습 알고리즘의 성능 비교가 아니라, 생성된 온톨로지의 품질·일관성·추론 능력을 다각도로 검증하는 평가 실험을 수행합니다 .
1) Logical Consistency & Quality (형식적 일관성 검증)
방법
- Protégé 5.6.5 + Pellet reasoner로 OWL 일관성 검사
- Inconsistent debugging 수행
- **OOPS! (Ontology Pitfall Scanner)**로 잠재 오류 진단
결과
- 논리적 불일치 없음, 모든 OWL 제약 satisfiable
- OOPS! 결과: 대부분 minor 이슈
- 누락된 annotation 다수
- inverse property 일부 미정의
- 치명적/중대 오류는 발견되지 않음
→ 형식적·논리적 정합성 확보.
2) Structural Evaluation (구조적 메트릭)
OntoMetrics로 base / schema / graph 메트릭을 계산 .
Base Metrics
- Axioms: 621
- Classes: 111
- Object properties: 47
- DL expressivity: ALCHIQ(D)
→ 비교적 높은 논리적 표현력과 공리 밀도.
Schema Metrics (개념 설계 품질)
- Attribute richness ≈ 0.15 → 클래스당 데이터 속성 평균이 낮음
- Inheritance richness = 0.90 → 수평적(폭 넓은) 계층 구조
- Relationship richness = 0.33 → 중간 수준의 의미적 연결성
- Axiom/Class ratio = 5.59 → 공리 밀도 높음
- Inverse ratio = 0.021 → inverseOf 활용 낮음
→ 장점: 논리적 밀도 높음
→ 약점: 서술적 속성 부족(데이터 프로퍼티 빈약)
전문가 리뷰도 동일 문제를 지적했고, 이후 data property를 보강 .
Graph Metrics (계층 구조 특성)
- Root classes: 13 (모듈성 높음)
- Leaf classes: 64 (폭 넓은 구조)
- Avg depth: 2.08 / Max depth: 3 → 비교적 얕은 계층
- Tangledness: 0.018 → 다중 상속 거의 없음
→ 모듈형·평면적(horizontally rich) 구조로 해석 가능.
3) Semantic Similarity Evaluation (의미적 일관성)
두 가지 메트릭 사용 :
- Wu & Palmer (1994)
- Li et al. (2003)
결과
✔ 동일 서브트리 내 개념
예: SeatPosition, ClimateControl, InteriorLighting
- Wu & Palmer ≈ 0.80
- Li ≈ 0.44
→ 높은 유사도 → taxonomic coherence 확인
✔ 이질적 개념 쌍
예: BiometricData vs SportMode
- Wu & Palmer < 0.30
- Li < 0.12
→ 낮은 유사도 → 기능적 분리 명확
→ 두 지표 모두에서 일관된 경향 확인 → 의미적 구조 안정성 검증.
4) SPARQL 기반 추론 평가 (Competency Questions)
Competency Questions(CQ)와 SPARQL 질의를 매핑하여 검증 .
검증 범주
- Driver profile taxonomy
- Customizable properties
- Privacy constraints
- Behavioral inference
- Safety system allocation
대표 추론 결과
- Aggressive + HighSpeed → High Risk 자동 추론
- Calm + Expert → 적합 안전 시스템 자동 연결
- 비수정 가능 요소(NonCustomizableElement)는 수정 불가로 추론
모든 CQ에 대해 기대 결과와 일치.
→ OWL restriction + 규칙 기반 추론 정상 작동.
5) 전문가 평가 (Expert Review)
독립적인 온톨로지 전문가 검토 수행 .
지적 사항
- 데이터 프로퍼티 부족
- inverse property 부족
- 일부 OWL restriction 미흡
→ 인간이 보완 후 재검증.
6) 종합 결과 요약
| 평가 항목 | 결과 |
|---|---|
| Logical consistency | 완전 통과 |
| OWL satisfiability | 모두 만족 |
| Structural richness | 수평적 구조 우수 |
| Attribute depth | 초기 부족 → 보강 |
| Semantic coherence | 높음 |
| SPARQL inference | 성공 |
| Hallucination | 일부 누락·제약 미흡 존재 |
7) 해석
이 실험 결과는 다음을 보여줍니다:
✔ LLM이 구조적 온톨로지 초안을 잘 생성함
✔ 논리적 일관성 확보 가능
✔ 의미적 계층 구조는 상당히 안정적
✖ OWL 제약 및 데이터 프로퍼티는 인간 개입 필수
즉,
LLM은 “초기 구조 생성 + 개념 확장”에 강하고,
형식적 정교화는 전문가가 보완해야 한다.
8) 연구적 의미
이 논문의 실험은 알고리즘 성능 비교가 아니라:
- 생성 품질
- 형식적 타당성
- 의미적 일관성
- 추론 가능성
을 다층적으로 검증한 ontology engineering validation study입니다 .
답글 남기기