




다음 논문은 LLMs4OL: Large Language Models for Ontology Learning (ISWC 2023)이며, LLM을 Ontology Learning(OL)에 직접 적용한 최초의 체계적 실험 연구입니다.
1. 문제 설정: 왜 LLM으로 Ontology Learning인가?
Ontology Learning (OL)이란?
텍스트로부터 다음을 자동으로 추출하여 구조화하는 작업입니다:
- L: lexical entries (용어)
- T: conceptual types (개념 타입)
- : type taxonomy (is-a 계층)
- R: non-taxonomic relations (비계층적 관계)
- A: axioms (제약/추론 규칙)
전통적 OL은:
- Hearst pattern 기반 lexico-syntactic rule
- clustering
- seed-based bootstrapping
문제점:
- 도메인 전문가 의존
- 비용/시간 소모
- 확장성 한계
논문 핵심 가설
LLM의 emergent capability가 Ontology Learning에도 적용될 수 있는가?
LLM은:
- 대규모 텍스트에서 semantic pattern 학습
- 복잡한 reasoning 가능
- zero-shot task generalization 가능
→ 그렇다면 ontology primitive 추출도 가능하지 않을까?
2. LLMs4OL 패러다임
논문은 OL을 3개 핵심 태스크로 정의합니다.
Task A: Term Typing
lexical term → type 분류
예:
“Paris is a place in France.”
Paris is a [MASK].→ expected: city / capital / location
Prompt 형식 (cloze):
[L] is a [MASK].평가 지표:
- MAP@1
Task B: Taxonomy Discovery
type 간 is-a hierarchy 판별
예:
A tumor is a disease. This statement is [MASK].→ true / false
평가 지표:
- F1 score
Task C: Non-Taxonomic Relation Extraction
type 간 비계층적 관계 판별
예:
Drug treats Disease. This statement is [MASK].→ true / false
3. 사용 데이터셋
| Domain | Source |
|---|---|
| Lexicosemantic | WordNet |
| Geography | GeoNames |
| Biomedical | UMLS (NCI, SNOMEDCT, MEDCIN) |
| Web types | schema.org |
중요한 점:
- WordNet: Task A만 가능
- GeoNames: Task A, B
- UMLS: Task A, B, C 모두 가능
4. 실험한 LLM들
총 11개 모델:
Encoder-only
- BERT-Large
- PubMedBERT (biomedical)
Decoder-only
- GPT-3
- GPT-3.5
- GPT-4
- BLOOM (1.7B, 3B)
- LLaMA-7B
Encoder-decoder
- BART-Large
- Flan-T5 (Large, XL)
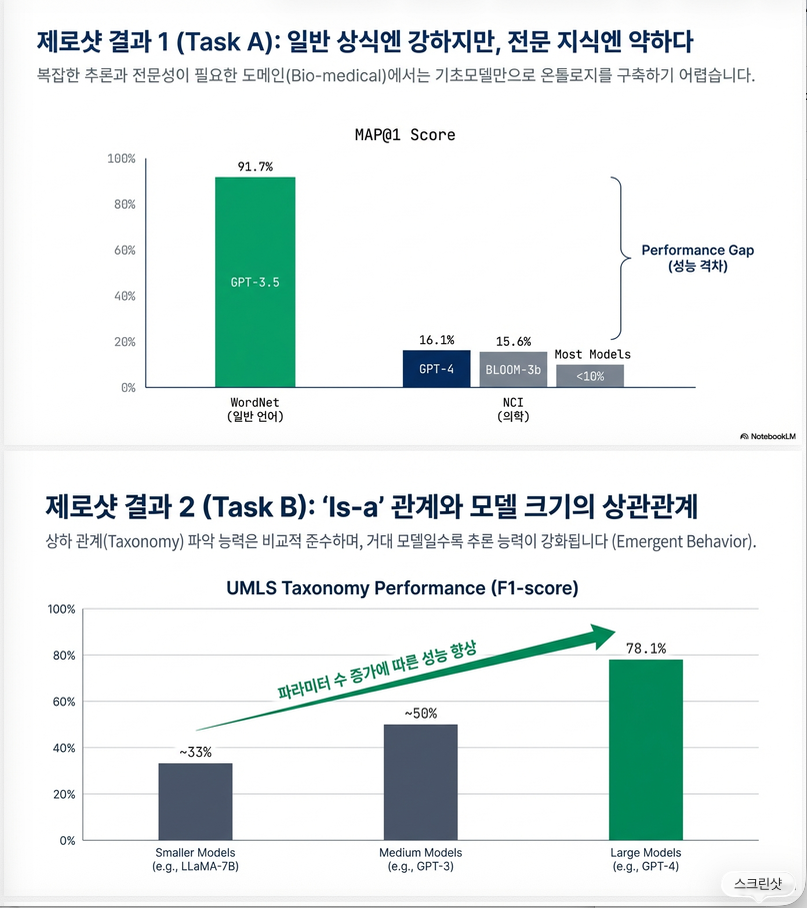
5. Zero-shot 결과 분석
RQ1: Term Typing
가장 쉬운 데이터셋: WordNet (4 types)
최고 성능:
- GPT-3.5: 91.7% (WordNet)
하지만:
- GeoNames (680 types) → 최고 39%
- Biomedical → 대부분 10~30%
📌 결론:
Term typing이 가장 어려운 task
RQ2: Taxonomy Discovery
최고:
- GPT-4 (UMLS): 78.1%
Open-source 중 최고:
- Flan-T5-XL: 64.3%
→ taxonomy는 비교적 잘 수행
RQ3: Non-Taxonomic Relation
최고:
- Flan-T5-XL: 49.5%
→ 절반 수준
중요한 패턴
- 파라미터 수 증가 → 성능 증가
- GPT 계열이 가장 강함
- Biomedical domain은 특히 어려움
- term typing > taxonomy > relation 순으로 어려움
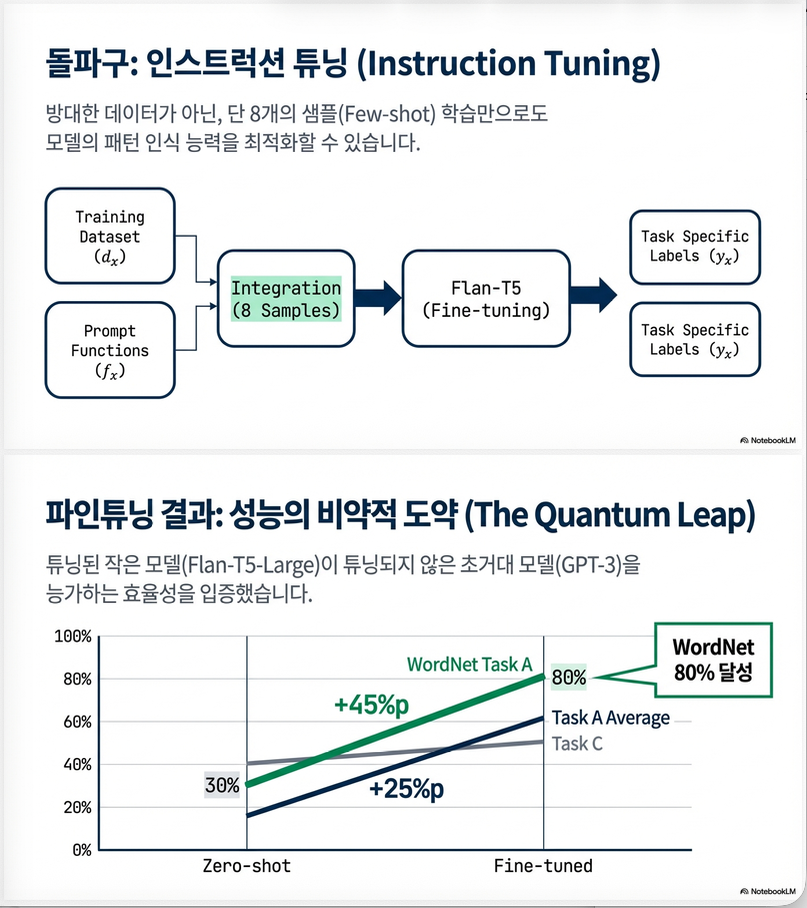
6. Finetuning 실험
논문은 Flan-T5를 instruction tuning 방식으로 finetune.
결과:
| Task | 평균 성능 향상 |
|---|---|
| Task A | +25% |
| Task B | +18% |
| Task C | +3% |
놀라운 점:
- finetuned 3B 모델이
- zero-shot 175B GPT보다 잘 나오는 경우 존재
→ ontology learning은 task-specific tuning이 매우 중요
7. 논문의 핵심 결론
- Foundation LLM은 OL에 충분하지 않음
- 그러나 fine-tuning하면 유의미한 성능 가능
- LLM은 ontology construction assistant로 유망
- term typing이 가장 어려움
- parameter scaling 효과 존재
8. 이 논문의 의의
① LLMs4OL 패러다임 제안 (개념적 공헌)
② 3가지 OL task를 LLM prompt 기반으로 정식화
③ 11개 LLM을 통합 비교
④ 공개 코드 제공
9. 한계점
- 복잡한 reasoning prompt (CoT, ToT) 미사용
- ontology axioms는 실험 안 함
- multi-hop 구조 학습 없음
- latent representation 분석 없음
10. 연구적으로 중요한 포인트
이 논문은 다음 연구 방향으로 확장 가능:
- CoT 기반 taxonomy reasoning
- latent space clustering 기반 type discovery
- hybrid (pattern + LLM)
- EAP 기반 ontology edge detection
- multi-hop reasoning ontology induction
최종 요약
| 질문 | 답 |
|---|---|
| LLM이 OL 가능한가? | 부분적으로 가능 |
| zero-shot으로 충분한가? | 아니오 |
| fine-tuning하면? | 상당히 개선됨 |
| 가장 어려운 task? | term typing |
| scaling 효과? | 존재함 |
LLMs4OL 방법론 정밀 분석
본 논문의 방법론은 Ontology Learning(OL)을 3개 분해 가능한 태스크로 정식화하고, 이를 LLM prompt 기반 inference 문제로 환원하는 것입니다.
핵심은:
Ontology primitive 추출을 “prompt → completion → structured decision” 문제로 변환
1. 전체 방법론 구조
논문의 구조는 다음 4단계로 구성됩니다.
Ontology primitive 정의
↓
OL task formalization (3 tasks)
↓
Prompt template 설계
↓
Zero-shot + Finetune 실험2. Ontology Formalization
논문은 Ontology를 다음 primitive 집합으로 정의합니다.
- L: lexical entries
- T: conceptual types
- taxonomic hierarchy
- R: non-taxonomic relations
- : relation heterarchy
- A: axioms
이 중 실험은:
- Task A →
- Task B →
- Task C → R
3. Task A — Term Typing
3.1 문제 정의
주어진 lexical term 에 대해:
Prompt 기반 formulation
Cloze Prompt:
Prefix Prompt:
추론 방식
LLM은 token 확률 분포:
top-1 type을 선택
3.2 평가
Metric:
MAP@1
즉,
4. Task B — Taxonomy Discovery
4.1 문제 정의
두 type
목표:
4.2 Prompt Formulation
Expected output:
- true / false
4.3 데이터 구성 방식 (수학적 정의)
논문은 transitivity까지 고려합니다.
False relation은:
→ balanced positive/negative pair 구성
4.4 평가
5. Task C — Non-Taxonomic Relation Extraction
5.1 문제 정의
주어진 relation
5.2 Prompt
예:
Drug treats Disease. This statement is [MASK].6. Zero-Shot Evaluation 설계 철학
이 논문은 OL을:
“emergent ability test” 로 간주
즉,
- 모델을 OL로 명시적으로 학습시키지 않음
- 단지 prompting만 사용
이는 LAMA-style knowledge probing 접근과 유사
7. Finetuning 방법론
7.1 Instruction Tuning 기반
Flan-T5를 선택
Finetune 방식:
- 각 task별 training set 일부 사용
- instruction + label supervision
예:
Let's say that "Tumor is a disease."
Can we now say that "'Tumor' is kind of [LABEL]?"7.2 학습 objective
표준 seq2seq cross-entropy:
8. 핵심 방법론적 특징
① Ontology Learning을 classification 문제로 환원
- Term typing → multi-class classification
- Taxonomy → binary classification
- Relation → binary classification
② Prompt engineering을 체계적으로 탐색
- Task A/B: 8개 template 비교
- best template 결과만 보고
③ Domain 다양성 실험
- WordNet (lexico-semantic)
- GeoNames (geo)
- UMLS (biomedical)
- schema.org (web ontology)
④ Parameter scaling 분석
성능 증가:
9. 방법론의 구조적 강점
✔ Task decomposition 명확
✔ Multi-domain generalization 테스트
✔ Zero-shot vs Finetune 비교
✔ Large-scale 모델 비교
10. 방법론적 한계
❗ Ontology는 구조적 객체인데 → 독립 pair classification으로 분해
❗ Global consistency 보장 없음
❗ Graph-level learning 아님
❗ Axiom learning 미포함
❗ Multi-hop reasoning 미사용
답글 남기기