이 논문은 소프트웨어 공학 표준(SES) 문서로부터 LLM 기반 zero-shot triple extraction을 통해 **자동 온톨로지 생성(AOG)**을 수행하는 워크플로우를 제안합니다.
1. 문제 설정과 기여
문제 정의
- 대상 문서: Software Engineering Standards (SES)
- 길고 비정형적이며 노이즈가 많음
- 도메인 특화 용어 다수
- 목표:
- SES 텍스트 → (entity, relation, entity) triple 추출
- 이를 기반으로 ontology scaffold 생성
- 제약:
- open-set relation
- gold ontology 없음
- 문단 단위 이상의 article-level 처리
핵심 기여
- Assertion-led ABox–TBox co-extraction pipeline
- 기존 TBox-first 접근과 대비
- triple 중심 → 이후 타입/계층 유도
- 완전 자동화 workflow 설계
- segmentation
- noun/verb candidate mining
- constrained LLM inference
- normalization
- cross-section alignment
- 3종 reference set 구축
- Ref-Short / Medium / Long
- 서로 다른 granularity에서 평가 가능
- OpenIE baseline과 비교
- 7B open-source LLM (Mistral-7B) 사용
- precision 우위, recall 유사
2. 전체 워크플로우 구조
(Figure 1, p.2)
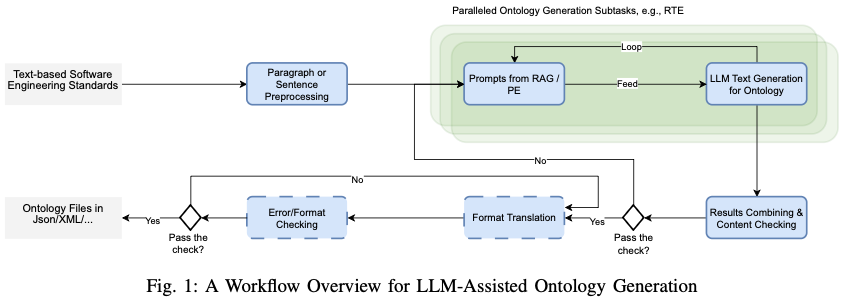
Workflow는 두 층으로 구성됩니다:
SES Text
↓
Sentence segmentation
↓
Parallel ontology generation subtasks (RTE)
↓
LLM text generation
↓
JSON parsing + validation
↓
Result combining
↓
Format translation (OWL/JSON/XML)3. 핵심 알고리즘: Ontology Scaffold 생성
Algorithm 1 (p.3)

목표:
G = (V, E)
단계별 설명
(1) Sentence-level 처리
각 문장에 대해:
- spaCy로 noun phrase 추출 → 후보 entity P
- verb 추출 → 후보 relation
(2) Constrained Prompt 구성
LLM 입력:
- 원문 문장 S
- 후보 noun phrase 집합 P
- 후보 verb 집합 Vb
→ JSON triple 형식으로 출력 요구
Temperature: 0.2
max_new_tokens: dynamic budget (256~1024)
(3) Strict JSON Parsing + Retry
- 최대 3회 retry
- 유효 JSON만 허용
- 실패 시 discard
(4) Term Normalization
- lemmatization
- acronym 보존
- similarity threshold 기반 aggressive change 방지
(5) Graph 구성
→ ontology scaffold 완성
4. Reference Dataset 설계
Gold ontology가 없기 때문에 수동 구축.
(Table I, p.3)
| Dataset | #Nodes | #Triples | #Islands |
|---|---|---|---|
| Ref-Short | 68 | 83 | 6 |
| Ref-Medium | 72 | 54 | 26 |
| Ref-Long | 32 | 25 | 8 |
설계 의도
- Ref-Short → high density (recall stress)
- Ref-Medium → balanced
- Ref-Long → backbone structure (precision focus)
5. 평가 방법
Threshold Sweep (Figure 3, p.4)
embedding similarity 기반 매칭
- 모델: sentence-transformers/all-mpnet-base-v2
- τ ∈ [0.1, 0.9]
- subject + relation + object concatenation 후 유사도 계산
- greedy 1:1 alignment
평가 지표:
- Precision
- Recall
- F1
Node-level / Triple-level 각각 평가
6. 주요 실험 결과
(1) Recall 특성
- Ref-Long → recall highest
- Ref-Short → recall lowest (dense graph이므로 어려움)
(2) Precision
Pred-LLM이 OpenIE보다 대체로 높음
특히:
- τ > 0.5에서 안정화
- τ ≈ 0.6에서 triple 신뢰도 높아짐
(3) Triple vs Node 난이도
Triple-level:
- head/relation/tail 중 하나라도 틀리면 miss
- precision/recall 더 낮음
(4) 결론적 성능
7B LLM이:
- node precision ↑
- triple precision ↑
- stricter ref set에서 recall ≈ OpenIE
7. 기존 연구와 차별점
| 기존 연구 | 본 논문 |
|---|---|
| TBox-first | Assertion-first |
| Closed relation set | Open-set relation |
| Sentence-level | Article-level |
| Commercial LLM 포함 | Open-source 7B only |
| Gold ontology 존재 | Gold 없음 → 자체 구성 |
8. 한계
- 단일 LLM만 사용
- 단일 annotator
- cross-sentence coreference 처리 부족
- OWL transformation 단계는 future work
9. 이 논문의 의미
이 논문은 다음 관점에서 흥미롭습니다:
1. Zero-shot RTE를 ontology scaffold 생성으로 연결
ZS relation extraction → ontology graph seed
2. Prompt engineering 의존도 감소
- 후보 term은 deterministic extraction
- LLM은 relation inference에만 집중
→ reproducibility 개선
3. Threshold-sweep 기반 평가
Embedding similarity 기반 연속적 평가 방식은
Open-set ontology generation에 적합한 평가 전략입니다.
10. 한 줄 요약
7B open-source LLM을 이용해 SES 문서에서 zero-shot triple extraction을 수행하고, 이를 ontology scaffold로 자동 구성하는 assertion-led AOG 워크플로우를 제안한 실증적 연구.
다음은 해당 논문의 **방법론(Methodology)**을 구조적으로 정리한 설명입니다.
(Algorithm 1 및 Figure 1 기반 정리)
1. 전체 설계 철학
Assertion-led ABox–TBox Co-extraction
기존 ontology learning은 보통:
TBox-first (type, taxonomy → instance)
이 논문은 반대로:
ABox-first (triple extraction → schema 후보 유도)
즉,
Triple을 먼저 안정적으로 추출하고,
이로부터 class/is-a/domain-range를 후처리 단계에서 유도합니다.
2. 전체 Workflow 구조
(Figure 1, p.2)
Phase 1: LLM 기반 Triple 생성
- Document segmentation
- Sentence-level 처리
- Candidate term mining
- LLM-based relation inference
- JSON strict parsing
Phase 2: Post-processing
- Term normalization
- Cross-section alignment
- Result combination
- Ontology format translation (OWL/JSON/XML)
3. 핵심 알고리즘: Ontology Scaffold 생성
목표
Ontology scaffold:
G = (V, E)
- V: term nodes
- E: relation edges (triples)
4. Sentence-level Triple Extraction 절차
(Algorithm 1, p.3)
Step 1: 문단 → 문장 분할
각 paragraph p에 대해:
Step 2: Candidate Term 추출
각 문장 s에 대해:
(1) Noun phrase 추출 → entity 후보
(2) Verb 추출 → relation 후보
spaCy 사용
Step 3: Clean + Deduplication
- stopword 제거
- 중복 제거
- 의미 없는 phrase 제거
Step 4: Constrained Prompt 구성
LLM 입력:
- 원문 문장 s
- 후보 noun phrase 집합 P
- 후보 verb 집합 Vb
- JSON triple 형식 강제
즉, LLM은 relation inference 전용 모듈로 사용됨.
왜 중요한가?
LLM이:
- entity hallucination
- format 불안정성
- 중복 생성
문제를 줄이기 위해
Candidate entity는 deterministic하게 먼저 추출
LLM은 관계 추론만 수행
Step 5: Dynamic Token Budget
max_new_tokens ∈ [256, 1024]
sentence complexity에 따라 조절
Step 6: Low-Temperature Inference
- temperature = 0.2
- retry ≤ 3
- strict JSON parsing
형식 오류 시 재시도
Step 7: Term Normalization
각 triple:
정규화:
- lemmatization
- acronym 보존
- similarity threshold 기반 필터링
예:
engineers → engineer
running → runStep 8: Graph 업데이트
5. Orphan Sentence 처리
Verb 후보가 없는 문장은:
- orphan으로 저장
- 후처리에서 V에 삽입
6. 결과: Ontology Scaffold
생성된 그래프는:
- low-noise
- normalized
- triple-based graph
이 단계에서는:
- class hierarchy 없음
- domain/range 명시 없음
→ 이후 단계에서 확장 예정
7. 평가 방법론
Open-set triple matching 문제 해결을 위해:
Embedding similarity 기반 매칭
subject+relation+object concatenation 후
sentence-transformer embedding 사용
τ sweep:
8. OpenIE와의 차별점
| OpenIE | 제안 방법 |
|---|---|
| fully rule-based | LLM-assisted |
| relation noise 많음 | constrained inference |
| no schema scaffold | ontology scaffold 생성 |
| sentence-level | article-level |
9. 방법론의 기술적 특징
(1) Hybrid Deterministic + Generative
- entity: deterministic
- relation: generative
(2) Strict Output Control
- JSON only
- retry mechanism
- format validation
(3) Open-set relation 대응
- predefined relation 없음
- verb 기반 candidate 생성
(4) Engineering Workflow 지향
- reproducibility 고려
- scaling 고려
- modular design
10. 방법론의 수학적 구조 요약
전체 pipeline을 함수 형태로 쓰면:
여기서:
11. 본 방법론의 핵심 아이디어
- LLM을 full generator로 쓰지 않는다
- relation inference 전용 모듈로 제한한다
- deterministic candidate mining으로 hallucination 감소
- strict parsing으로 안정성 확보
- ontology scaffold를 intermediate artifact로 둔다
다음은 논문의 실험 설정 및 결과 분석을 구조적으로 정리한 내용입니다.
(Section IV, Figure 2–3, Table I 기반)
1. 실험 설정
(1) 비교 대상 시스템
Pred-LLM (제안 방법)
- 모델: Mistral-7B-Instruct-v0.1
- open-set relation extraction
- fully automated (post-edit 없음)
- 5회 실행 평균 보고
Pred-OpenIE (Baseline)
- Stanford OpenIE (CoreNLP)
- sentence-level rule-based triple extraction
(2) 평가 데이터
SECEPP short version에 대해 3개 reference set 구성:
| Dataset | 특징 | 목적 |
|---|---|---|
| Ref-Short | dense graph | recall stress |
| Ref-Medium | balanced | middle ground |
| Ref-Long | backbone | precision focus |
(Table I 요약)
| Dataset | #Nodes | #Triples |
|---|---|---|
| Ref-Short | 68 | 83 |
| Ref-Medium | 72 | 54 |
| Ref-Long | 32 | 25 |
2. 평가 프로토콜
Open-set triple matching 문제 해결
정확한 string match가 아니라:
Embedding similarity 기반 매칭
- 모델: all-mpnet-base-v2
- triple을 다음과 같이 concat:
- cosine similarity 계산
- threshold sweep:
- greedy 1:1 alignment
평가지표:
- Precision
- Recall
- F1
Node-level / Triple-level 각각 평가
3. 주요 결과
Figure 3 (p.4)
6개 그래프:
- 위 3개: Node-level
- 아래 3개: Triple-level
- 각 column: Short / Medium / Long
4. 핵심 관찰 결과
(1) Recall 특성
Ref-Long에서 Recall ↑
이유:
- backbone graph
- triple 수 적음
- 매칭 쉬움
Ref-Short에서 Recall ↓
이유:
- dense graph
- 세밀한 clause 유지
- 놓치기 쉬움
즉,
(2) Precision 비교
대부분 τ에서
특히 triple-level에서 차이 명확
이유:
- OpenIE는 중복 및 spurious triple 많음
- LLM은 constrained inference로 noise 감소
(3) τ ≈ 0.6에서 안정화
논문 관찰:
τ ≈ 0.6 이상에서 triple 품질 안정
의미:
- semantic alignment가 충분히 강해짐
- false positive 감소
이는 open-set ontology evaluation에서
실질적 신뢰 구간 역할 가능
(4) Node vs Triple 난이도
항상:
이유:
Triple 매칭 조건:
하나라도 mismatch → 전체 실패
(5) 7B LLM의 경쟁력
결론:
- Node precision: 우수
- Triple precision: 우수
- Strict reference (Long)에서 recall ≈ OpenIE
→ 7B open-source 모델이 rule-based system과 경쟁 가능
5. 정량적 경향 요약
정확한 숫자는 threshold별로 변동하지만
경향은 다음과 같음:
| Metric | Pred-LLM | OpenIE |
|---|---|---|
| Node Precision | ↑ | ↓ |
| Node Recall | 약간 ↓ | 약간 ↑ |
| Triple Precision | ↑ | ↓ |
| Triple Recall | 약간 ↓ | 약간 ↑ |
즉,
LLM = precision-oriented
OpenIE = recall-heavy but noisy
6. 시각적 비교 (Figure 2)
Figure 2에서:
- Ref graphs: 구조 명확
- Pred-LLM: 비교적 compact
- OpenIE: edge 많고 noisy
LLM 그래프가 더 “ontology-like” 구조를 보임
7. 실험의 의미
(1) Open-set relation 환경에서 LLM 유효성 입증
Closed relation classification이 아닌
자유 relation 추출 상황에서도 성능 확보
(2) Engineering workflow의 실효성 검증
- constrained prompt
- candidate mining
- strict parsing
→ precision 개선에 기여
(3) Ontology scaffold 생성 가능성
단순 triple 추출이 아니라:
- graph connectivity
- concept consolidation 가능
8. 한계
- 단일 LLM
- 단일 annotator (IAA 없음)
- short document만 실험
- cross-sentence reasoning 미적용
9. 핵심 요약
7B open-source LLM은 open-set SES triple extraction에서 OpenIE 대비 높은 precision을 보이며, strict reference set에서는 recall도 유사한 수준을 달성하였다. Triple-level 평가는 node-level보다 엄격하며, embedding similarity threshold τ≈0.6 부근이 실질적 안정 구간으로 관찰되었다.
답글 남기기