


1. 연구 배경 및 문제의식
최근 LLM에서 reasoning 능력 향상은 주로 다음 방식으로 이루어집니다.
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning (RL) (특히 RLVR, GRPO)
하지만 기존 접근의 문제는 다음입니다.
| 방법 | 학습 파라미터 규모 |
|---|---|
| Full Finetuning | 수십억 |
| LoRA | 수백만 |
| LoRA rank=1 | 약 3M |
즉 parameter-efficient tuning이라 해도 여전히 수백만 파라미터가 필요합니다.
논문의 핵심 질문:
Reasoning을 학습하는 데 정말 수백만 파라미터가 필요한가?
이 논문은 놀라운 결과를 보여줍니다.
→ 단 13개의 파라미터로 reasoning 능력을 크게 향상 가능
2. 핵심 아이디어
TinyLoRA
기존 LoRA를 극단적으로 축소한 방법입니다.
목표:
LoRA: millions parameters
↓
LoRA-XS: thousands
↓
TinyLoRA: 1~100 parameters실험 결과:
- Qwen2.5-7B
- GSM8K accuracy
| 설정 | Accuracy |
|---|---|
| base model | 88.2% |
| TinyLoRA (13 params) | 91.8% |
| Full finetuning | 91.7% |
즉
13 parameters ≈ full finetuning
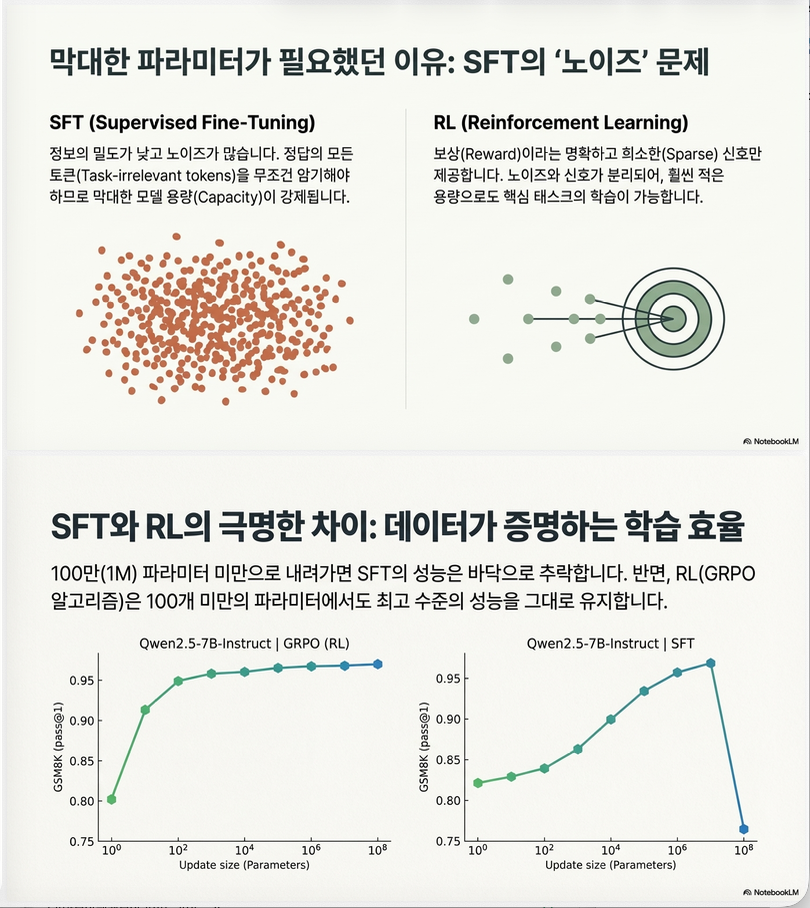
3. 왜 RL이 이렇게 효율적인가?
논문에서 가장 중요한 이론적 기여입니다.
SFT objective
즉
모든 토큰을 그대로 학습
문제:
- signal + noise 같이 학습
- 많은 정보 저장 필요
RL objective (policy gradient)
특징:
- reward만 중요
- irrelevant token 정보 제거
논문의 주장:
| 방법 | 정보 밀도 |
|---|---|
| SFT | noisy signal |
| RL | clean signal |
따라서
RL은 훨씬 적은 파라미터로 학습 가능
4. TinyLoRA 방법
기존 LoRA
W’ = W + AB
파라미터 수
O(dr)
LoRA-XS
SVD decomposition 활용
update
여기서
- 학습
파라미터 수
TinyLoRA
핵심 아이디어:
R을 직접 학습하지 않고 random projection 사용
- : trainable vector
- : fixed random tensor
최종 업데이트
파라미터 수
| 방법 | 파라미터 |
|---|---|
| LoRA | O(nmdr) |
| LoRA-XS | O(nmr²) |
| TinyLoRA | O(nmu) |
추가 trick:
weight tying
모든 layer가 같은 vector 사용
→ 1 parameter까지 가능
5. 실험
Dataset
- GSM8K
- MATH
- AIME
- AMC
- OlympiadBench
모델
- Qwen2.5 3B / 7B
- LLaMA 3
학습
- RL: GRPO
- reward: exact match
6. 주요 결과
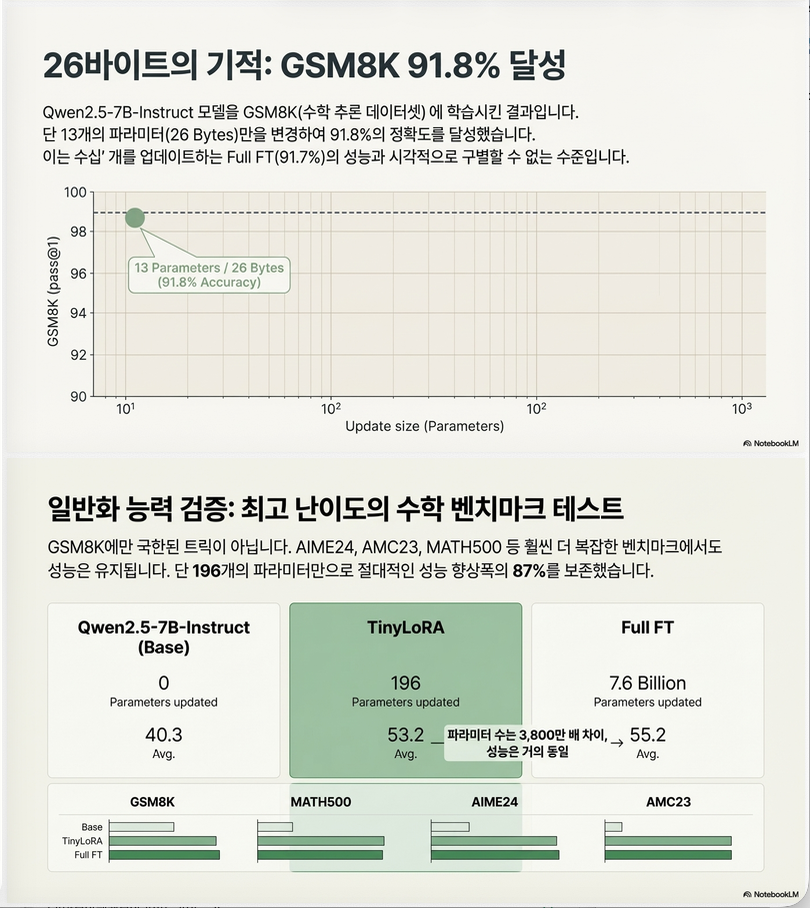
(1) 13 parameters로 reasoning 학습
| Params | GSM8K |
|---|---|
| 0 | 88.2 |
| 13 | 91.8 |
| 49 | 91.5 |
| 196 | 92.2 |
| full FT | 91.7 |
즉
13 parameters → full FT 수준
(2) RL vs SFT
| Params | RL | SFT |
|---|---|---|
| 13 | 91% | 83% |
| 120 | 95% | 84% |
결론
Tiny parameter regime에서는 RL이 필수
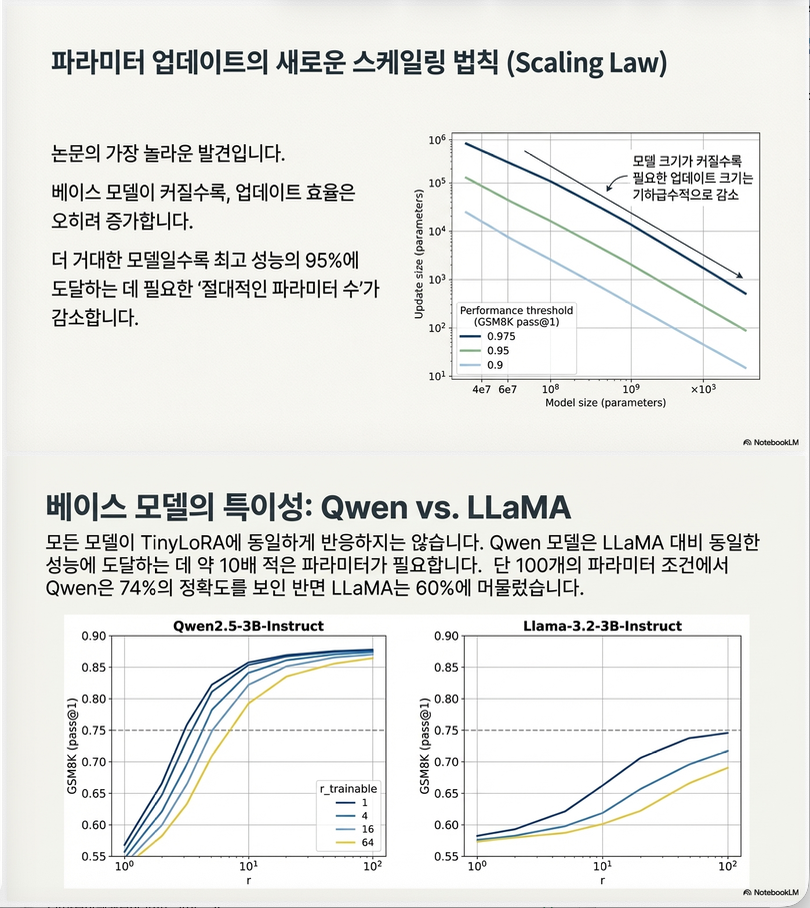
(3) 모델 크기 영향
Figure 3 (page 3) 결과:
모델이 클수록 필요한 update parameter가 감소
예
| 모델 | 필요한 파라미터 |
|---|---|
| 0.5B | 10k |
| 3B | 1k |
| 7B | 100 |
즉
모델이 클수록 “programming”이 쉬움
(4) Qwen vs LLaMA
결과:
- Qwen: 13 params → 91%
- LLaMA: 수백 params 필요
원인 추정:
- pretraining
- architecture
7. 중요한 해석
논문의 매우 흥미로운 해석:
reasoning capability는 이미 모델 내부에 존재
RL이 하는 일은
새 knowledge 학습이 아니라
reasoning mode activation즉, TinyLoRA가 하는 일
knowledge learning ❌
reasoning style switching ✅특히, longer reasoning traces을 생성하도록 bias를 바꾸는 것.
8. 한계
논문에서 인정한 한계
(1) Math dataset only
- reasoning domain 제한
(2) possible contamination
- GSM8K pretraining 포함 가능
(3) general reasoning 미검증
- science / planning 등
9. 연구적 의미
이 논문은 매우 중요한 질문을 던집니다.
(1) RL은 실제로 무엇을 학습하는가?
가능한 해석:
RL ≠ new knowledge
RL = activation routing change이는 다음 연구들과 연결됩니다.
- RL learns small subnetworks
- intrinsic dimension of finetuning
- LoRA low-rank update theory
(2) future: reasoning programming
TinyLoRA의 implication:
LLM ≈ programmable system몇 바이트로
- persona
- reasoning style
- task skill
을 제어 가능.
10. 정리
논문의 핵심 기여
(1) TinyLoRA 제안
- 1~100 parameter finetuning 가능
(2) RL vs SFT 분석
- RL이 low-parameter regime에서 훨씬 효율적
(3) 실험 결과
- 13 parameters → full finetuning 수준 reasoning
(4) 이론적 해석
- reasoning capability는 base model 내부에 이미 존재
논문의 방법론(Methodology)을 실제 학습 구조, 파라미터화 방식, 학습 파이프라인 중심으로 정리합니다.
1. 연구 목표 (Methodological Objective)
논문의 방법론적 목표는 다음입니다.
“update capacity”를 최소화하면서 reasoning 성능을 유지하는 parameter-efficient training 설계
즉 모델의 파라미터 대부분은 freeze하고, 매우 작은 update subspace만 학습합니다.
핵심 구성요소는 다음 3가지입니다.
- TinyLoRA parameterization
- parameter sharing (weight tying)
- RL 기반 training pipeline (GRPO)
2. TinyLoRA Parameterization 구조
2.1 기본 구조
Transformer의 linear layer
TinyLoRA는 다음과 같은 업데이트를 적용합니다.
여기서
구성요소:
| 요소 | 의미 |
|---|---|
| U, Σ, V | weight matrix의 truncated SVD |
| fixed random matrix | |
| trainable parameter |
즉, trainable parameters = v 뿐입니다.
2.2 Frozen SVD basis
TinyLoRA는 기존 LoRA와 달리 SVD basis를 frozen합니다.
- U, Σ, V → fixed
- update는 이 basis 위에서만 수행
즉, update subspace = singular directions of W
이 구조는 다음 의미를 갖습니다.
- pretrained weight의 principal directions 유지
- low-dimensional update 가능
2.3 Random projection parameterization
LoRA-XS에서도 을 학습해야 합니다.
TinyLoRA는 이를 다음으로 대체합니다.
여기서
- : fixed random tensor
- : scalar parameter
즉, matrix learning → scalar combination
이 방식은 다음 장점이 있습니다.
(1) parameter 수 감소
(2) update rank 유지
(3) optimization 안정성 유지
3. Parameter Sharing (Weight Tying)
TinyLoRA가 극단적으로 파라미터를 줄일 수 있는 이유입니다.
Transformer block에서 LoRA는 보통 다음 모듈에 적용됩니다.
- attention Q
- attention K
- attention V
- attention O
- MLP up
- MLP down
- MLP gate
즉 block당 7개 linear module.
기본 파라미터 수
layer 수 = n
module 수 = m
TinyLoRA parameter 수
n m u
Weight tying
논문은 다음 방식으로 parameter를 공유합니다.
즉, 모든 module이 동일 parameter 사용
파라미터 수:
최대 공유 시:
따라서, parameters = u
즉, u = 1 → single parameter training 가능합니다.
4. Reinforcement Learning Training Pipeline
TinyLoRA는 SFT가 아니라 RL로 학습됩니다.
논문은 GRPO (Group Relative Policy Optimization) 를 사용합니다.
4.1 RL objective
각 prompt x에 대해 모델이 여러 candidate 답을 생성
각 답에 대해 reward 계산: R(y)
4.2 GRPO gradient
policy gradient 형태
즉, reward 높은 trajectory 강화
4.3 reward function
논문에서 사용한 reward: Exact match
즉
- 정답이면 1
- 아니면 0
math task에서는 매우 강력한 signal입니다.
5. Training Pipeline
논문에서 사용한 전체 학습 pipeline입니다.
Step 1 — prompt sampling
dataset
- GSM8K
- MATH
Step 2 — multi-sample generation
각 문제마다
k = 4 (GSM8K)
k = 8 (MATH)candidate generation
Step 3 — reward computation
정답 여부 판단
Step 4 — policy gradient update
TinyLoRA parameter v만 업데이트
Step 5 — weight merge
training과 inference mismatch 해결을 위해
논문은 다음 trick을 사용합니다.
training → LoRA weights
inference → merged weights즉
6. vLLM 구현 트릭
논문에서 중요한 구현 포인트입니다.
문제:
vLLM LoRA minimum rank = 4TinyLoRA는 rank < 4 필요.
해결 방법
training에서는 LoRA model,
inference에서는 merged weight model 을 사용합니다.
그리고 mismatch를 줄이기 위해
truncated importance sampling 적용합니다.
7. Hyperparameter Design
논문에서 중요한 tuning 요소입니다.
learning rate sweep
각 parameter regime에서 best LR 선택
generation length
GSM8K
max length = 4096MATH
prompt = 1024
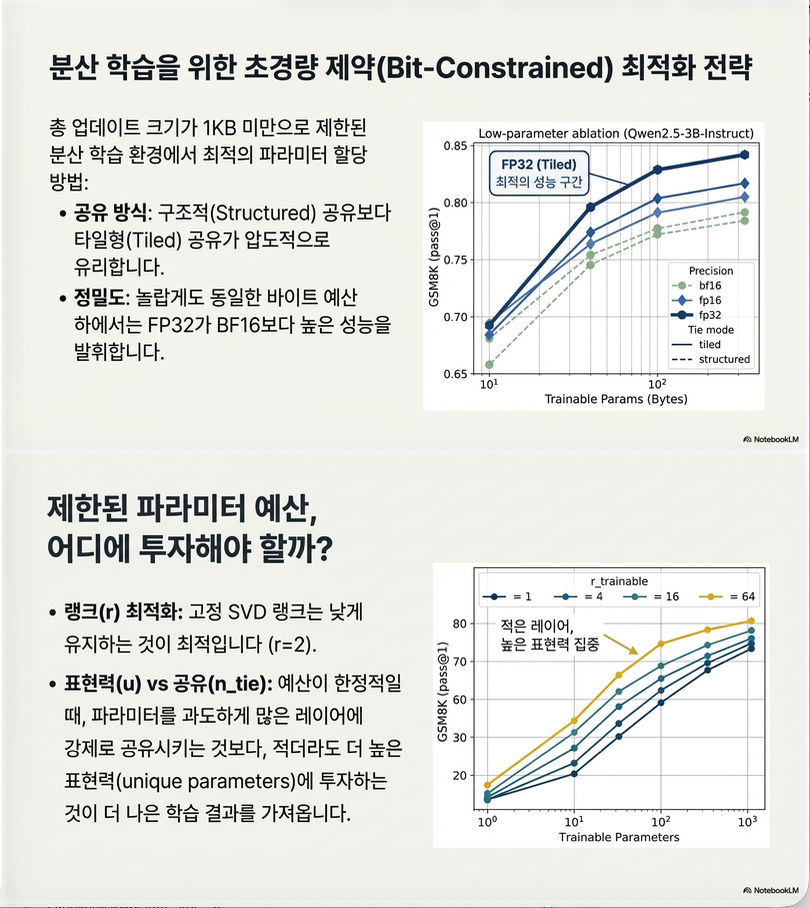
response = 30728. Parameter Budget Experiment Design
논문은 update size를 다음처럼 sweep합니다.
| regime | parameters |
|---|---|
| Tiny | 1 – 100 |
| small | 100 – 10k |
| medium | 10k – 1M |
| large | >1M |
이를 통해, update size vs performance curve를 분석합니다.
9. 핵심 methodological insight
이 논문의 방법론이 보여준 중요한 사실:
(1) reasoning tuning은 low-dimensional
업데이트가 필요한 dimension이 매우 작음.
(2) RL gradient는 sparse update
policy gradient는
reward correlated features만 업데이트(3) pretrained model은 이미 reasoning capability 보유
TinyLoRA는 capability learning 아님
capability activation에 가깝다는 결론.
10. 한 문장 요약 (방법론)
이 논문의 방법론은 다음 구조입니다.
Frozen Transformer
+
TinyLoRA (1~100 parameters)
+
RL training (GRPO)
↓
Reasoning capability amplification
답글 남기기