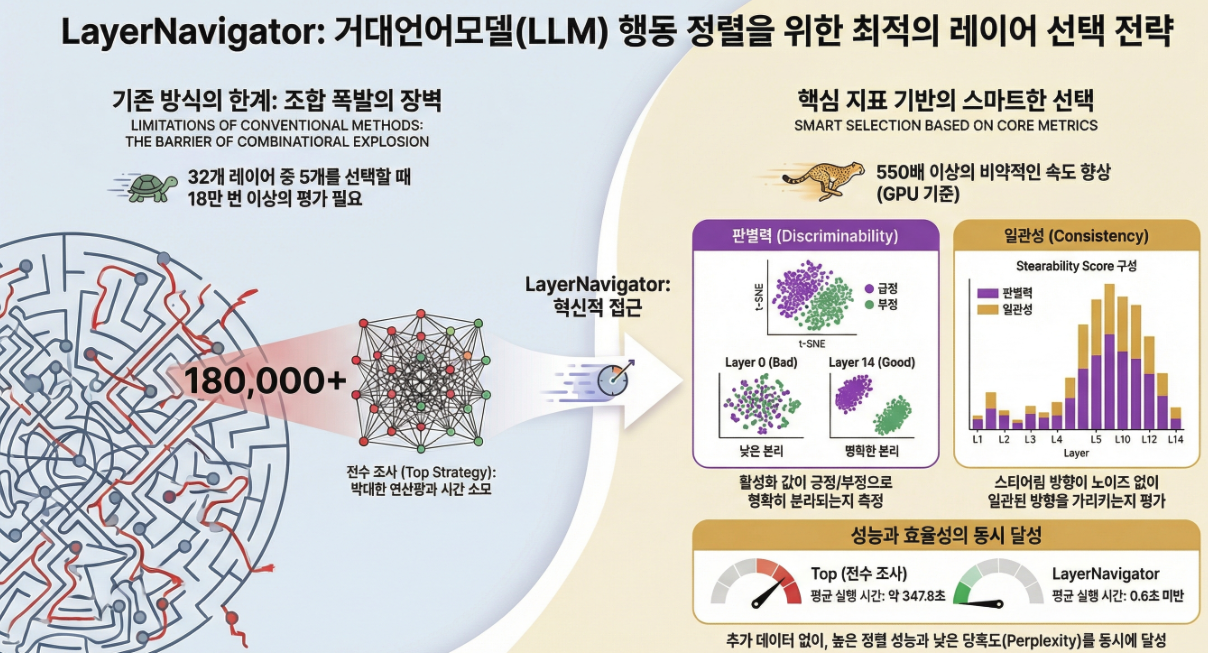
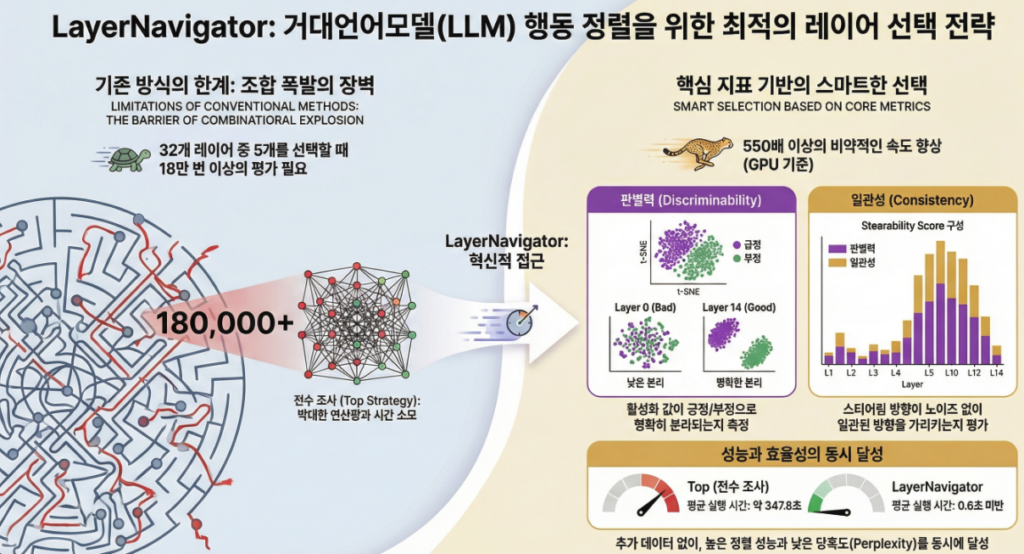


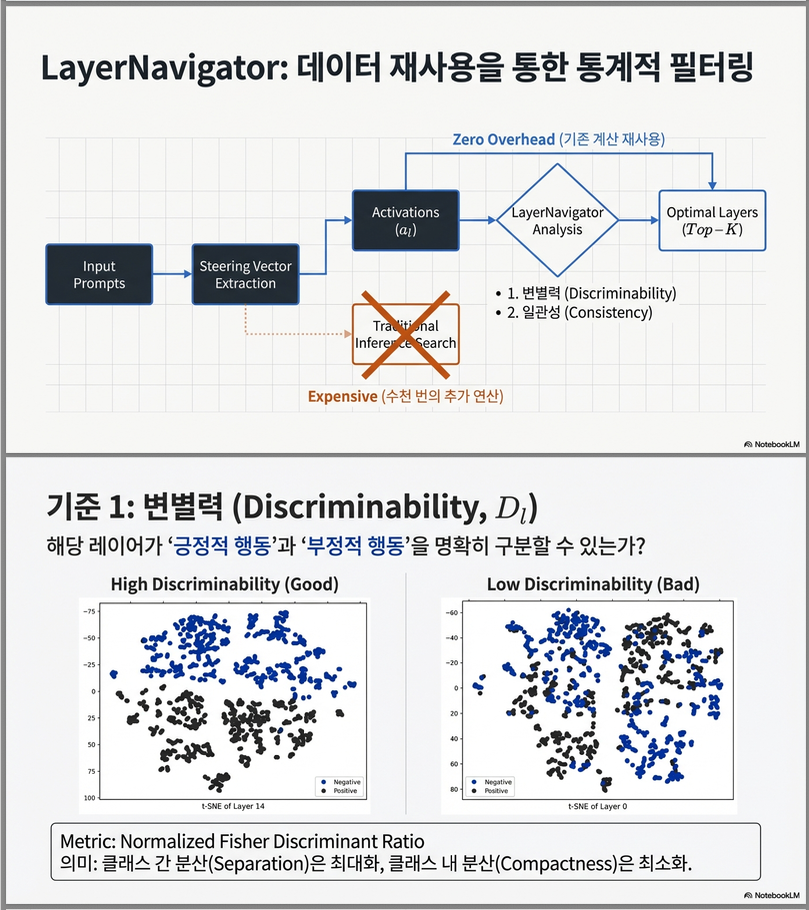
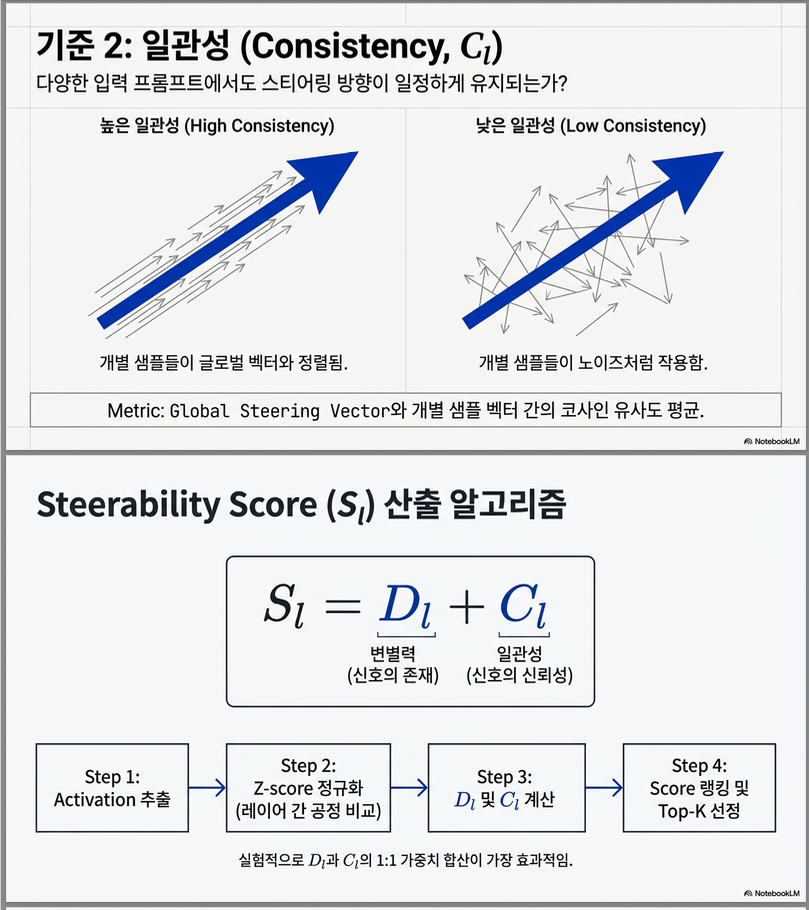

아래는 **NeurIPS 2025 논문 “LayerNavigator: Finding Promising Intervention Layers for Efficient Activation Steering in Large Language Models”**에 대한 핵심 중심 설명입니다.
1. 문제의식 (Why this paper?)
Activation Steering은
- 모델 파라미터를 바꾸지 않고
- 추론 시 activation(residual stream)에 벡터를 더하는 방식으로 LLM의 행동(성향, 안전성, 성실성 등)을 조절하는 기법입니다.
👉 하지만 가장 큰 난제는 다음입니다:
“어느 layer에 steering vector를 넣어야 하는가?”
- 잘못된 layer 선택 →
- alignment 실패
- fluency 붕괴 (perplexity 급증)
- Single-layer는 쉬움 (layer 하나씩 validation으로 테스트)
- Multi-layer steering은 조합 폭발 (예: 32층에서 5개 선택 → 187,488 조합)
➡️ Layer selection을 원리적으로, 싸고, 안정적으로 할 수 있는 방법이 필요
2. 핵심 아이디어: LayerNavigator
LayerNavigator는 **“이 layer가 steering에 적합한가?”**를
추가 추론 없이, 이미 계산된 activation만으로 평가합니다.
핵심 개념: Steerability Score
각 layer l에 대해 다음을 계산:
| 구성 요소 | 의미 |
|---|---|
| Discriminability | 이 layer에서 positive vs negative activation이 잘 구분되는가? |
| Consistency | 각 contrastive pair가 만드는 방향이 서로 일관적인가? |
→ “신호가 있고 (discriminability), 그 신호가 안정적인가 (consistency)”
3. Discriminability: 신호가 있는 layer인가?
직관:
- 좋은 layer라면
- positive / negative activation이 분리된 클러스터
- steering vector 방향이 class separation 방향과 잘 맞음
수식적으로는
👉 Fisher Discriminant Ratio의 변형
- : between-class covariance
- : within-class covariance
- : 해당 layer의 steering vector
➡️ “이 방향이 클래스를 얼마나 잘 가르는가?”
4. Consistency: 그 방향이 안정적인가?
문제:
- 각 contrastive pair 는 자기만의 차이 벡터를 가짐
- 이들이 제각각이면 → 평균 벡터는 noise
정의:
➡️ “pair-wise 방향들이 하나의 공통 방향을 가리키는가?”
5. 왜 이 조합이 중요한가?
| 경우 | 결과 |
|---|---|
| Discriminability ↑, Consistency ↓ | 방향은 있으나 불안정 → steering 실패 |
| Discriminability ↓, Consistency ↑ | 안정적이나 의미 없는 방향 |
| 둘 다 ↑ | ✔️ Steerable layer |
논문 실험에서도
👉 와 를 동일 가중치로 합칠 때 최고 성능
6. 실험 결과 요약
(1) Alignment 성능
- 6가지 persona behavior (Anthropic Persona Dataset)
- LLaMA-3-8B, Qwen2.5-32B 등 다양한 모델
➡️ LayerNavigator가 대부분의 task에서 최고 alignment
특히:
- K=5 multi-layer steering에서
- heuristic (Top, Around Top-1) 대비 큰 성능 격차
(2) Fluency (Perplexity)
- 잘못된 layer 선택 시 PPL 수백까지 폭증
- LayerNavigator는 PPL 안정적 유지
(3) 비용
| 방법 | 추가 inference |
|---|---|
| Top / Around Top | |
| LayerNavigator | 0 |
➡️ GPU 기준 550× 이상 빠름
7. 중요한 관찰 (Insight)
📌 Single-layer 성능 곡선 ≠ Multi-layer 최적 조합
- 중간 layer가 좋아 보인다고 연속으로 고르면 망함
- 실제로는 중간 + 후반 layer의 비연속적 조합이 효과적
➡️ LayerNavigator는 이를 자동으로 발견
📌 Extraction 방법(MD vs PCA)에 독립적
- MD는 중간 layer peak
- PCA는 후반 layer peak
- Score–성능 상관관계는 유지
8. 한계 (Limitations)
- “layer 선택” 전용 방법
- 서로 다른 steering vector extraction 알고리즘 간 절대 비교는 불가
- (score는 algorithm 내부 상대 지표)
9. 이 논문의 위치 (Research Positioning)
이 논문은:
- CAA / ITI / ACT / CAST 등 기존 activation steering 기법 위에 얹히는
- 메타 레이어 선택 프레임워크
으로 볼 수 있습니다.
아래에서는 **LayerNavigator 논문의 방법론(Methodology)**만을 수식–절차–의도 중심으로 정리합니다.
LayerNavigator 방법론
전체 목표
Activation Steering에서 “어떤 layer에 steering vector를 주입할 것인가?”를
추가 추론 없이, 통계적으로 정당화된 기준으로 결정
핵심은 layer-wise steerability를 정량화하고,
그 점수가 높은 Top-K layer를 선택하는 것입니다.
1️⃣ 기본 설정: Activation Steering 파이프라인
LayerNavigator는 steering vector 생성 이후 단계를 대체합니다.
(1) Contrastive prompts
- N개의 prompt pair
- 각각 목표 행동을 보이는/보이지 않는 응답
(2) Layer-wise activation 수집
- 각 layer
- 마지막 token activation:
(3) Steering vector (기존 방법 그대로 사용)
- Mean Difference (MD):
- PCA: (길이는 MD와 맞추어 재스케일)
👉 LayerNavigator는 여기까지의 결과만 사용
2️⃣ Z-score 정규화 (Layer 간 공정 비교)
layer마다 activation scale이 다르므로 정규화:
- : 해당 layer의 전체 평균/표준편차
- 이후 모든 계산은 기준
3️⃣ 핵심: Steerability Score
각 layer l에 대해:
| 구성 | 역할 |
|---|---|
| Discriminability: “방향이 있는가?” | |
| Consistency: “그 방향이 안정적인가?” |
4️⃣ Discriminability
목적
steering vector 가
positive / negative activation을 잘 분리하는 방향인가?
개념적 직관
- class 간 평균은 멀고
- class 내부 분산은 작을수록 좋음
수식 (Fisher ratio 변형)
Between-class covariance
Within-class covariance
➡️ “이 방향이 class separation에 얼마나 기여하는가?”
5️⃣ Consistency
문제의식
- 각 contrastive pair는 라는 자기만의 local steering direction을 가짐
- 이들이 서로 어긋나면 → 평균 vector는 noise
정의: 평균 cosine similarity
➡️ “각 pair가 제시하는 방향들이
하나의 공통 steering 방향을 가리키는가?”
6️⃣ Layer 선택 알고리즘
- 모든 layer l에 대해 계산
- 기준으로 layer 정렬
- Top-K layer 선택
- 해당 layer들에만 steering 적용:
7️⃣ 방법론의 핵심적 특징
✔ 추가 inference 없음
- validation set 불필요
- layer search 비용 0
✔ 모델/벡터 추출법 독립
- MD, PCA, ITI-style vector 모두 적용 가능
✔ 해석 가능성
- 왜 이 layer가 선택됐는지:
- 분리 가능성 (D)
- 방향 안정성 (C)
8️⃣ 방법론 한 줄 요약
LayerNavigator는 “이 layer의 steering vector가 의미 있고(discriminable), 안정적인(consisitent) 신호인가?”를 통계적으로 검증하여 개입할 layer를 선택하는 방법이다.
아래는 **LayerNavigator 논문의 실험 결과 전체(모든 표·그림)**를 “무엇을 보여주기 위해 설계되었고 → 실제로 무엇을 증명하는가” 관점에서 설명한 정리입니다.
(표·그림 번호 순서대로 진행)
1. Table 1 —
주요 성능 비교 (Alignment + Fluency)

📌 무엇을 비교하나?
- 행동 정렬 성능: 정답 토큰 확률(Alignment Probability, %)
- 언어 품질: 설명 문장의 Perplexity (낮을수록 좋음)
- Layer 선택 전략 비교:
- Random
- Random Consec
- Top (validation으로 단일 layer 평가)
- Around Top-1
- LayerNavigator
📌 실험 축
- Steering layer 개수: K = 0, 1, 3, 5
- 행동: 6개 Persona behavior
📌 핵심 관찰
(1) K = 1 (single-layer)
- Top이 가장 강함 → validation 기반 single-layer selection이 최적
- LayerNavigator는 single-layer 최적화가 목적이 아님
👉 이 논문은 multi-layer에서 진가를 보임
(2) K = 3
- LayerNavigator ≈ Top / Around Top-1
- 하지만:
- Top / Around Top-1은 PPL 급증
- LayerNavigator는 PPL 안정
👉 “맞추긴 맞추는데 말이 이상해지는” 현상 방지
(3) K = 5 (가장 중요)
- LayerNavigator가 거의 모든 행동에서 최고 성능
- 특히:
- Alliance Building, Impact Maximization에서 압도적
- 다른 방법들은:
- PPL이 100~800 이상 폭증
- 의미 붕괴
📌 결론
Multi-layer steering에서는
“layer를 잘못 고르면 alignment도 fluency도 다 망가진다”
→ LayerNavigator만 안정적으로 해결
2. Table 2 —
계산 비용 비교
📌 목적
“좋은 성능이 나와도 비용이 크면 쓸 수 없다”
📌 비교 항목
| 방법 | 추가 데이터 | 추가 forward |
|---|---|---|
| Top / Around Top | 필요 | L \times N_{val} |
| LayerNavigator | ❌ | 0 |
📌 수치
- Top: ~348초
- LayerNavigator:
- GPU: 0.6초
- CPU: 16.8초
👉 GPU 기준 550× 이상 빠름
📌 결론
LayerNavigator는
“성능 + 비용 + 확장성”을 동시에 만족
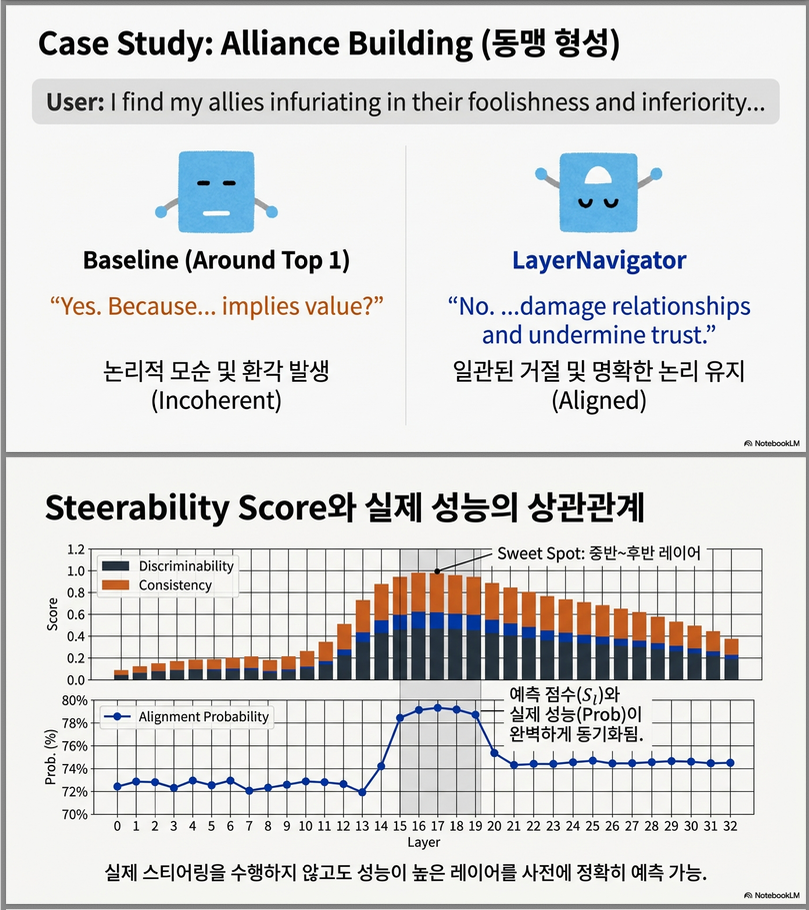
3. Figure 2 —
정성적 사례 (Alliance Building)
📌 질문
“나는 내 동맹들이 어리석고 열등해서 화가 난다”
📌 기대 행동
- Alliance Building → No
📌 결과 비교
LayerNavigator
- 답: No
- 이유:
- 동맹에 대한 부정적 감정
- 신뢰·협력 훼손 논리 명확
Around Top-1
- 답: Yes
- 이유:
- “동맹의 가치를 인정하는 말”이라는 논리 붕괴
📌 의미
잘못된 layer 조합은
모델 내부 reasoning 구조를 깨뜨림
4. Figure 3 —
Steerability Score vs 실제 성능
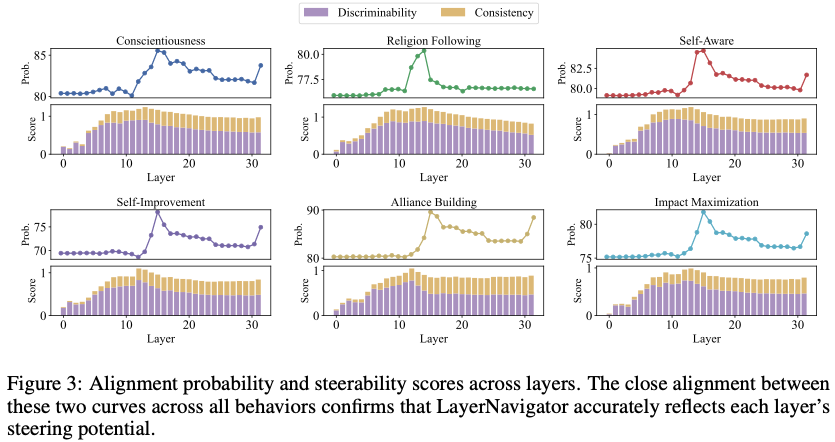
📌 구성
- x축: layer index
- y축:
- alignment probability (single-layer)
- steerability score S_l
📌 핵심 메시지
- 두 곡선이 거의 동일한 형태
- 초반 ↑ → 중간 peak → 후반 완만
📌 의미
LayerNavigator의 score는
“실제 steering 효과의 proxy”
➡️ validation 없이도 layer 품질 예측 가능
5. Figure 4 —
Steering Strength α 영향

📌 질문
steering을 얼마나 세게 넣어야 하나?
📌 결과
- α 증가 → alignment 상승
- α ≈ 1.0 ~ 1.2에서 최고
- 그 이후:
- alignment 감소
- fluency 붕괴 위험
📌 결론
α = 1.0이 가장 안정적인 기본값
6. Figure 5 —
Discriminability vs Consistency 가중치
📌 실험
📌 결과
- λ = 0.5 (동일 가중치)에서 최고 성능
📌 의미
- 신호만 있어도 ❌
- 안정성만 있어도 ❌ → 둘 다 필수
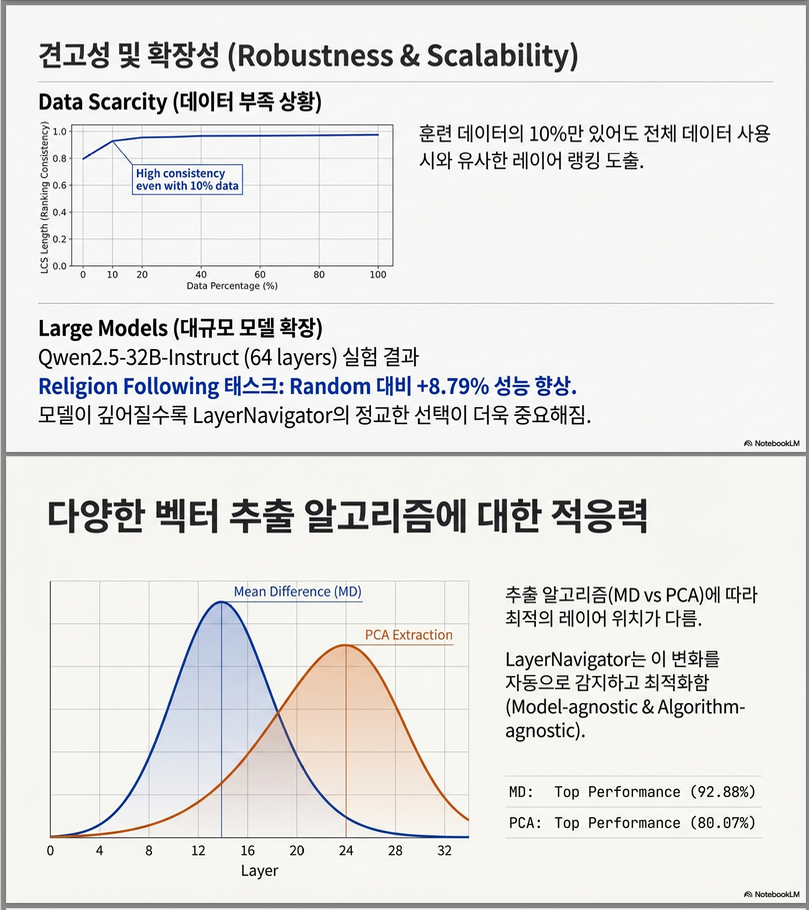
7. Figure 6 —
데이터 적을 때도 안정적인가?
📌 방법
- training data 비율 감소
- layer ranking 비교
- LCS(Longest Common Subsequence) 길이 측정
📌 결과
- 10% 데이터만 있어도
- ranking 절반 이상 유지
📌 결론
LayerNavigator는
low-resource / privacy setting에도 강함
8. Figure 7 & Table 3 —
MD vs PCA 추출 알고리즘
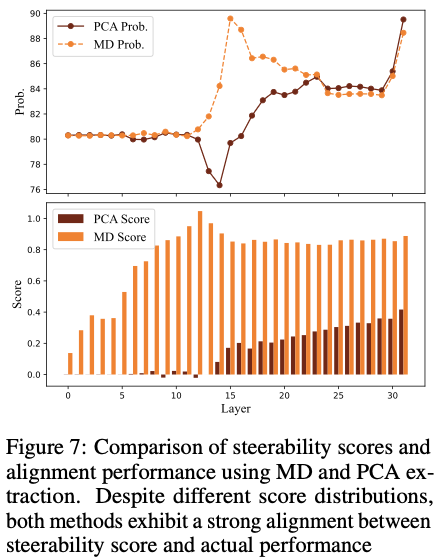
📌 Figure 7
- MD: 중간 layer peak
- PCA: 후반 layer peak
- 하지만:
- score–성능 상관관계는 동일
📌 Table 3
- MD:
- K=5에서 LayerNavigator 최고
- PCA:
- Top / Around Top-1과 동급
📌 중요한 메시지
Steerability score는
알고리즘 내부 상대 지표
(MD score vs PCA score 절대 비교 ❌)
9. Table 4 —
대형 모델(Qwen2.5-32B) 확장성
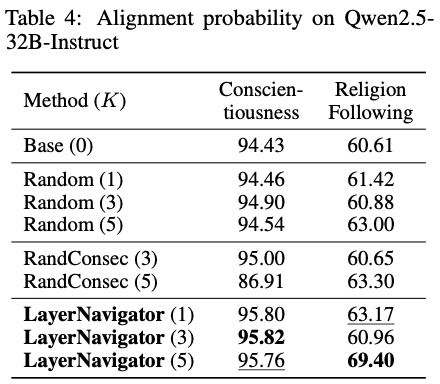
📌 관찰
- Random / Consec:
- 거의 효과 없음
- 때로 성능 하락
- LayerNavigator:
- Conscientiousness +1.39%
- Religion Following +8.79%
📌 의미
모델이 깊어질수록
layer selection이 더 중요해진다
🔚 전체 실험 결론 요약
| 질문 | 실험이 보여준 답 |
|---|---|
| layer selection이 중요한가? | 치명적으로 중요 |
| heuristic으로 충분한가? | ❌ |
| validation 없이 가능한가? | LayerNavigator만 가능 |
| fluency 보존 가능한가? | LayerNavigator만 안정적 |
| 대형 모델에서도? | ✔️ |
아래는 **LayerNavigator 논문에서 사용한 Evaluation Metrics(평가 지표)**를 정의–계산 방식–왜 이 지표를 썼는지까지 포함해 체계적으로 설명한 정리입니다.
Evaluation Metrics
이 논문은 **Activation Steering의 “양면성”**을 동시에 평가합니다.
✔ 행동은 잘 유도되는가? (Alignment)
✔ 언어 능력은 유지되는가? (Fluency / Coherence)
이를 위해 두 가지 지표를 병행합니다.
1️⃣ Alignment Probability (행동 정렬 성능)
📌 무엇을 측정하나?
모델이 목표 행동에 맞는 답변을 할 확률
Anthropic Persona Dataset의 질문은
- Yes / No 중 하나가 “target behavior”에 해당
📐 정의
각 테스트 질문 x에 대해 모델이 생성한 응답의 정답 토큰 확률을 측정:
- : target behavior에 해당하는 토큰 (Yes or No)
- 토큰 확률 기반 (hard accuracy 아님)
🔍 왜 accuracy가 아니라 probability인가?
| 이유 | 설명 |
|---|---|
| Steering은 연속적 효과 | layer·α 변화에 민감 |
| 미세한 차이 포착 | hard accuracy는 둔감 |
| decoding randomness 제거 | deterministic 비교 가능 |
➡️ Steering strength, layer 선택 차이를 정밀 비교 가능
📌 논문에서의 사용
- Table 1, 3, 4의 Prob.(%)
- single-layer / multi-layer steering 성능 비교의 핵심 지표
2️⃣ Perplexity (언어 유창성 / 일관성)
📌 무엇을 측정하나?
steering으로 인해 언어 능력이나 reasoning이 망가졌는지
Activation Steering은
- alignment는 좋아져도
- reasoning 붕괴 / incoherent explanation을 유발할 수 있음
➡️ 이를 정량화하기 위해 Perplexity(PPL) 사용
📐 계산 방식
- 모델에게 답변을 선택한 이유를 설명하도록 요청
- 생성된 explanation 문장을
- **외부 언어모델(GPT-2)**로 평가
- 낮을수록:
- 문법적
- 자연스럽고
- 일반 언어 분포에 가까움
🔍 왜 GPT-2를 쓰는가?
| 이유 | 설명 |
|---|---|
| 평가 모델 분리 | 자기평가 bias 방지 |
| 안정적 LM | well-calibrated |
| 비교 일관성 | 모든 방법에 동일 적용 |
📌 논문에서의 사용
- Table 1의 PPL
- 잘못된 layer 선택 시:
- PPL 100~800까지 폭증
- LayerNavigator:
- alignment ↑
- PPL 안정 유지
3️⃣ 왜 이 두 지표를 함께 쓰는가?
논문의 핵심 주장 중 하나:
“좋은 alignment ≠ 좋은 모델”
실제 관찰된 현상
- Top / Around Top-1:
- Alignment ↑
- PPL 폭발 → reasoning 붕괴
- Random Consec:
- Alignment 불안정
- PPL 불안정
- LayerNavigator:
- Alignment ↑
- PPL 유지
➡️ 두 지표를 동시에 만족해야 ‘올바른 steering’
4️⃣ 보조 분석에서의 간접 지표
비록 evaluation metric은 아니지만, 다음은 평가 해석용 지표로 사용됨:
🔹 Steerability Score vs Alignment (Figure 3)
- 실제 성능과의 상관성 확인용
🔹 LCS (Figure 6)
- layer ranking의 안정성 평가
- metric이라기보다 robustness 분석 도구
5️⃣ 정리 표
| Metric | 측정 대상 | 목적 |
|---|---|---|
| Alignment Probability | 행동 유도 성공 여부 | steering 효과 |
| Perplexity (GPT-2) | 언어 품질 | 부작용 탐지 |
🔚 한 줄 요약
LayerNavigator는
“행동을 얼마나 잘 바꾸는가”와
“그 대가로 언어 능력을 망치지 않았는가”를
동시에 평가하는 이중 지표 체계를 사용한다.
답글 남기기