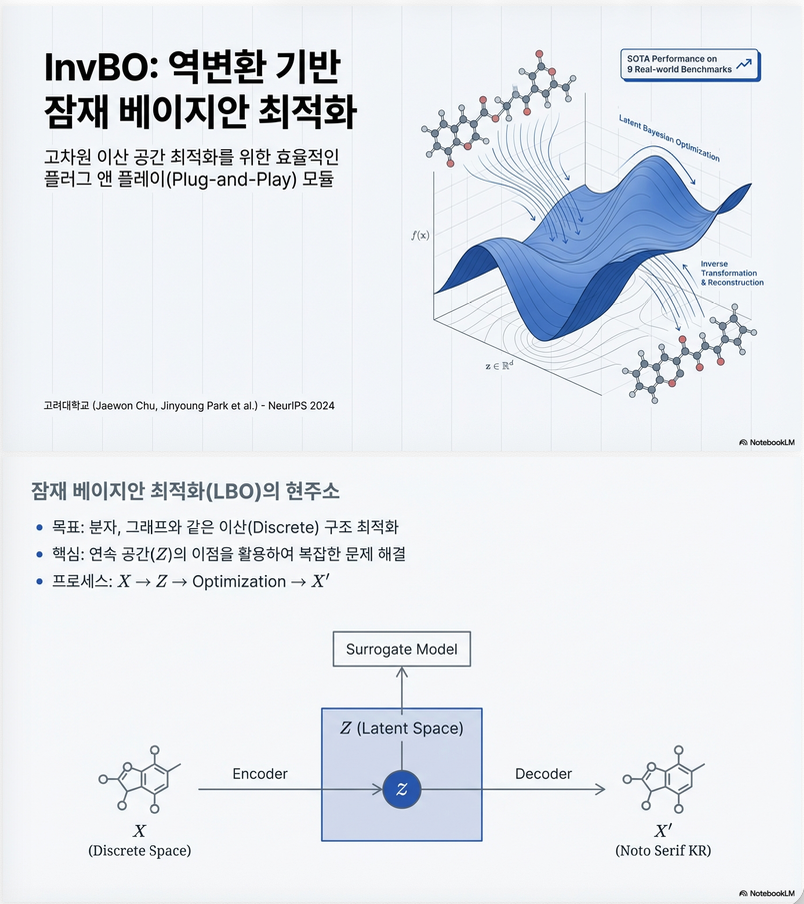

논문의 핵심은 Latent Bayesian Optimization (LBO)의 misalignment 문제를 inversion으로 해결하고, trust region anchor 선택을 개선하는 것입니다 .
1. 문제 배경: Latent Bayesian Optimization (LBO)
1.1 LBO의 기본 구조
LBO는 이산/구조적 입력 공간(예: 분자, 수식)을 연속 latent space로 매핑한 뒤 BO를 수행합니다.
- Encoder:
- Decoder:
- 목표:
Surrogate model g(z)는 사실상
를 근사해야 합니다 .
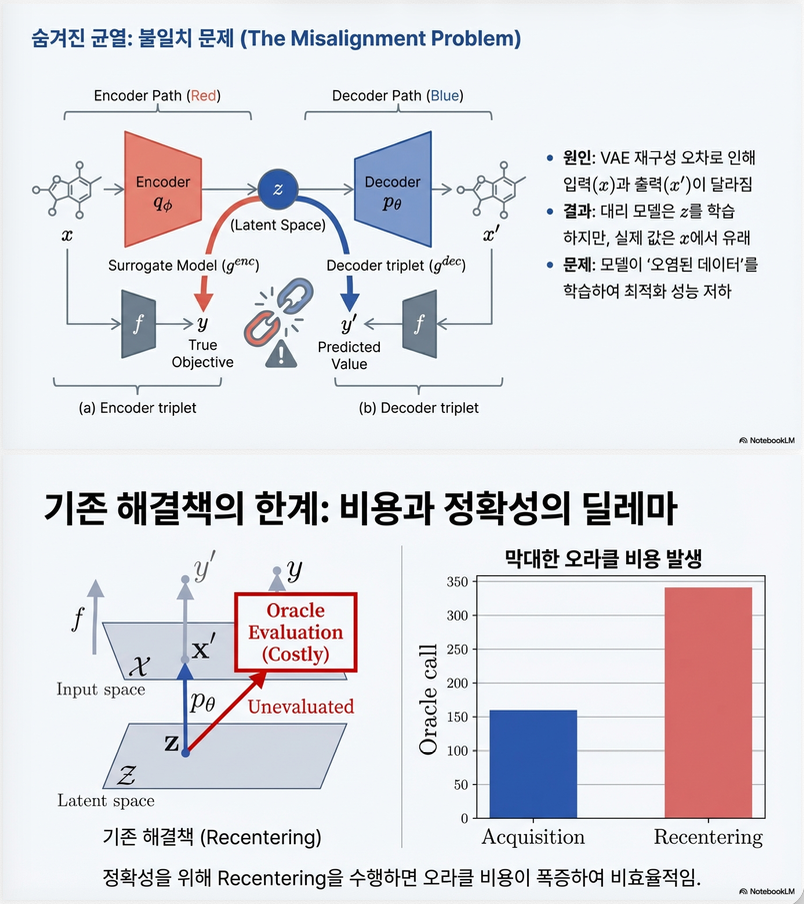
2. 핵심 문제: Misalignment
논문이 제기하는 가장 중요한 문제는 misalignment problem입니다.
2.1 왜 misalignment가 발생하는가?
VAE는 완벽한 reconstruction을 보장하지 않습니다:
즉, latent 는:
- encoder 관점에서는
- decoder 관점에서는
두 개의 서로 다른 objective 값을 갖게 됩니다.
그 결과:
- 동일한 z에 대해 서로 다른 y
- surrogate가 정확한 를 학습하지 못함
- BO 성능 저하
이를 논문에서는 misalignment problem이라 정의합니다 .
3. 기존 해결법: Recentering의 한계
이전 방법들 (LOL-BO, CoBO 등)은 다음을 수행:
- 새로 oracle 호출 →
이렇게 decoder triplet을 강제로 생성합니다.
하지만:
- 추가 oracle 호출 필요
- budget 낭비
- best score 갱신 없이 oracle 소모
이 한계를 논문이 지적합니다 .
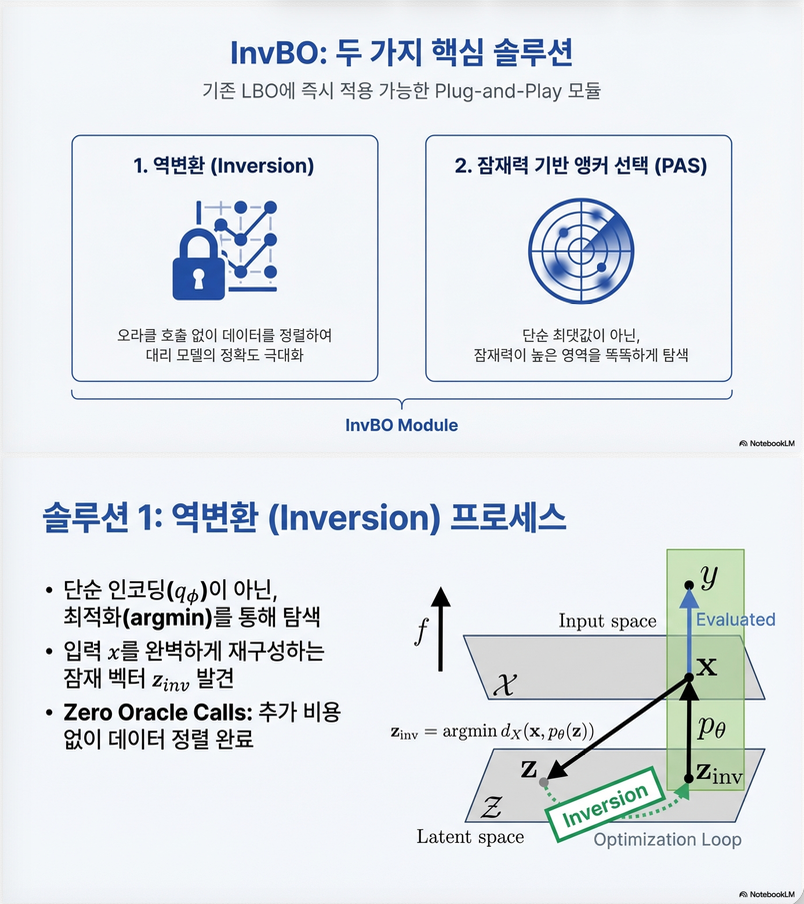
4. 제안 방법 1: Inversion
4.1 아이디어
Recenter는
z → x’ → f(x’)
InvBO는 반대로:
x → z_inv → pθ(z_inv) = x
즉, 이미 평가된 x를 완벽히 복원하는 latent를 찾습니다.
이때:
- normalized Levenshtein distance 사용 (문자열 기반 문제)
- 분자 설계에서는 Tanimoto similarity 가능
(식은 논문 Section 4.2에 명시)
4.2 알고리즘
- 초기값:
- 반복적으로 gradient descent
- reconstruction loss 최소화
- 이면 종료
이렇게 하면:
→ aligned decoder triplet (x, z_inv, y) 생성
→ 추가 oracle 호출 없음
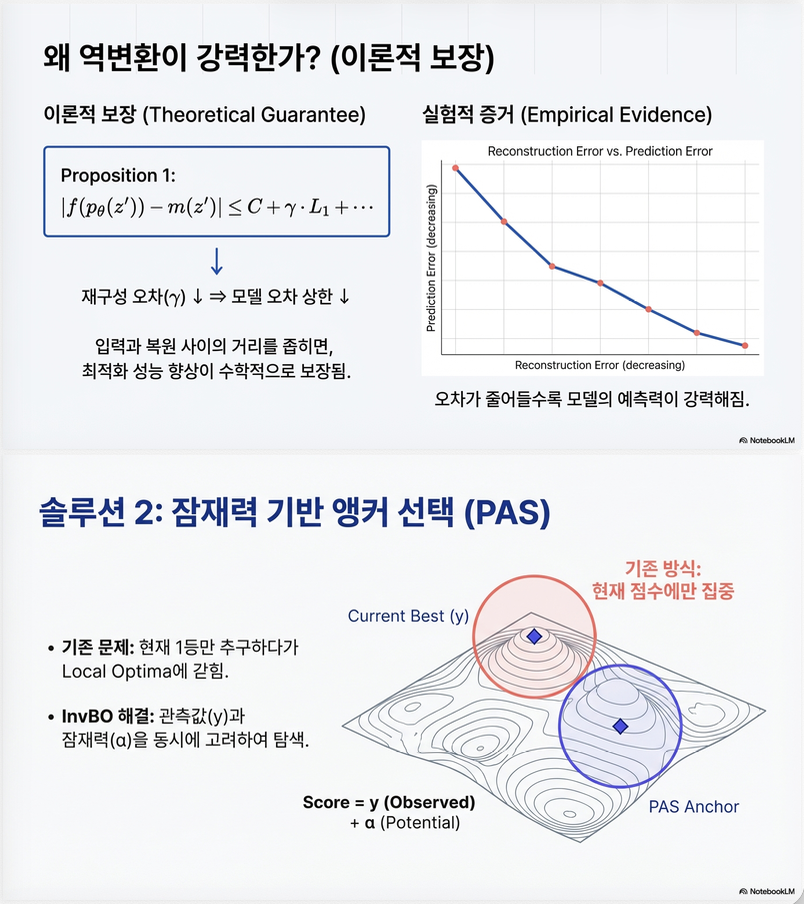
5. 이론적 분석 (Proposition 1)
논문은 surrogate prediction error의 upper bound를 제시합니다.
Trust region 내에서:
|
여기서:
- = trust region radius
- = Lipschitz constants
중요한 점:
inversion은 로 만든다.
따라서 upper bound가 직접 감소합니다 .
즉, 이 논문은 단순 empirical trick이 아니라
generalization bound 수준에서 misalignment를 설명합니다.
6. 제안 방법 2: Potential-aware Trust Region Anchor Selection (PAS)
기존 trust region anchor는:
(현재 best objective 값)
문제:
- uncertainty 고려 안함
- exploration 능력 부족
6.1 제안 방식
각 trust region 에 대해:
- Thompson sampling으로 surrogate에서 함수 샘플링
- 후보 latent들 중 최대 acquisition 계산
그 다음:
- objective 값과 scale 맞춤
- 최종 score:
→ exploitation + exploration 동시 고려
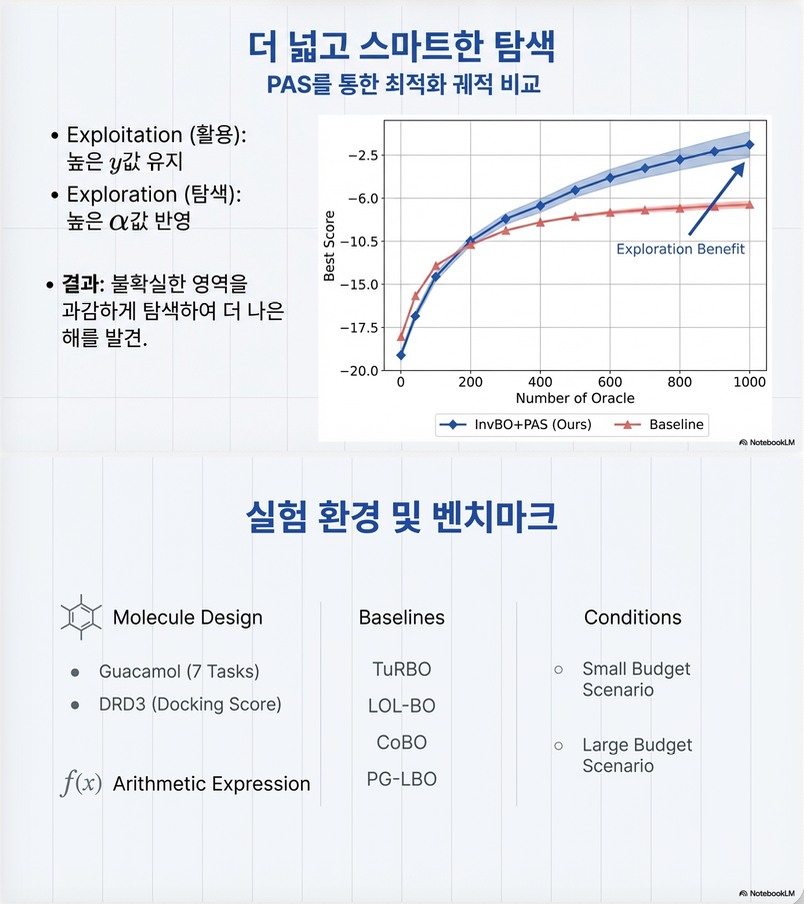
7. 실험 결과
7.1 벤치마크
- Guacamol (7 tasks)
- DRD3
- Arithmetic expression fitting
총 9개 task.
7.2 주요 결과
1. 모든 LBO 방법에 plug-and-play로 성능 개선
TuRBO-L, LOL-BO, CoBO 등 전부 향상
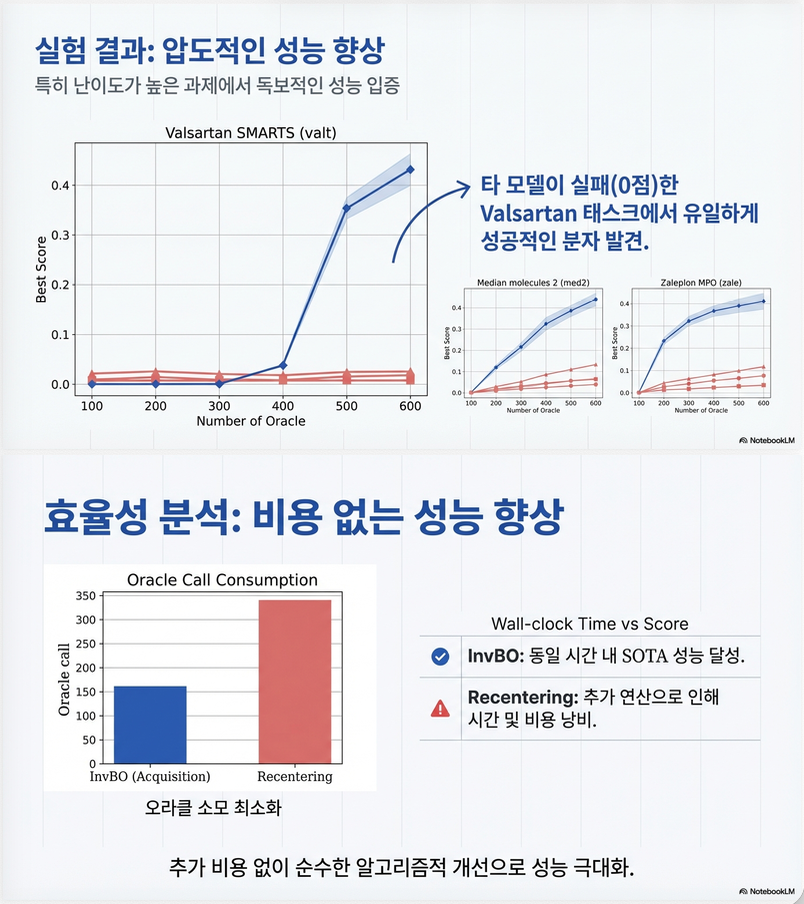
특히:
- Valsartan SMARTS task
- CoBO + InvBO: 0.348 점수
- baseline은 거의 0
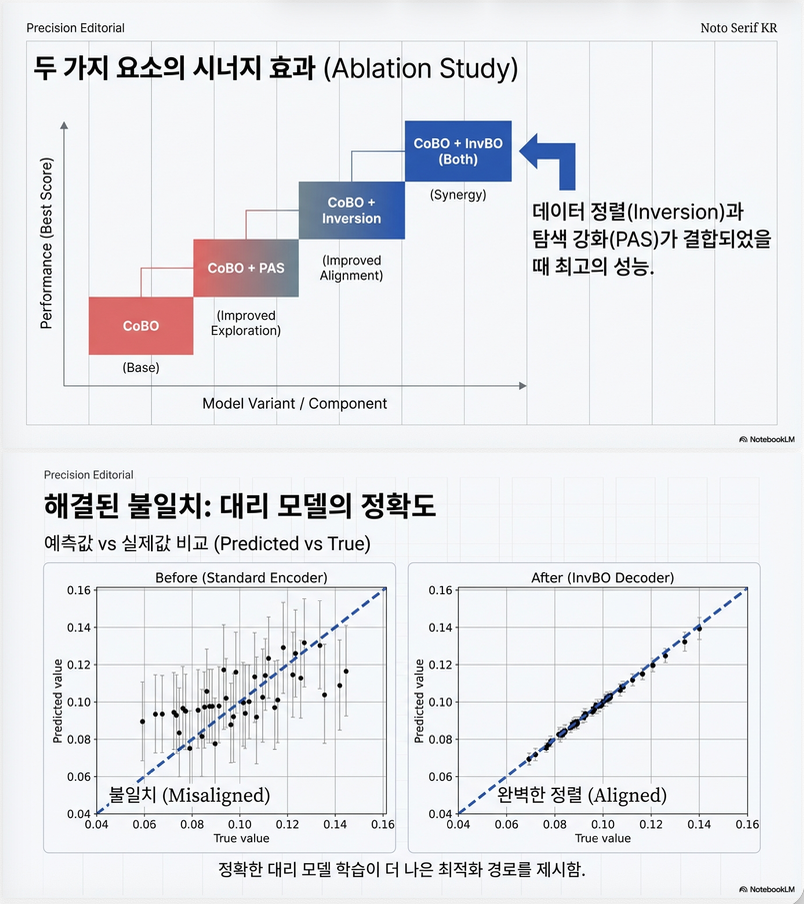
2. Ablation
- INV만 사용 → 개선
- PAS만 사용 → 개선
- 둘 다 사용 → 최대 개선
두 요소가 상호 보완적임
3. Misalignment 실험
- encoder triplet vs decoder triplet 비교
- decoder triplet이 surrogate fitting 훨씬 정확
misalignment가 실제로 surrogate를 망친다는 empirical 증거 제공
8. 이 논문의 구조적 의미
이 논문은 LBO에서:
| 문제 | 기존 | InvBO |
|---|---|---|
| misalignment | recentering (oracle 소모) | inversion (oracle 0 추가) |
| trust region anchor | objective 기반 | objective + potential |
| 이론 분석 | 없음 | Lipschitz bound 제공 |
즉,
LBO를 “정렬된 latent optimization 문제”로 재정의한 논문
9. 장점
- plug-and-play
- oracle 효율적
- 이론적 근거 명확
- 다양한 LBO에 일반화 가능
10. 한계
논문에서도 언급:
- generative model 품질에 의존
- decoder가 표현 못하는 영역은 여전히 최적화 불가
Inversion-based Latent Bayesian Optimization (InvBO) — 방법론 정리
본 논문의 방법론은 두 개의 핵심 모듈로 구성됩니다:
- Inversion-based Alignment
- Potential-aware Trust Region Anchor Selection (PAS)
전체 구조는 기존 VAE 기반 LBO 프레임워크에 plug-and-play 방식으로 삽입됩니다 .
1. 문제 설정
Latent Bayesian Optimization은 다음 문제를 풉니다:
- surrogate
Surrogate는 실제로 합성함수 를 근사해야 합니다 .
2. Misalignment 문제
초기 데이터는 보통:
latent는
하지만:
즉,
- surrogate는 로 학습
- 실제 BO는 를 평가
→ 동일한 z가 두 objective 값과 연결됨
→ surrogate가 잘못된 함수 학습
3. 방법 1: Inversion-based Alignment
3.1 목표
추가 oracle 호출 없이 aligned decoder triplet 생성:
단,
3.2 수식
Latent inversion은 다음 최적화 문제:
- : 입력 공간 distance
- 문자열 → normalized Levenshtein
- 분자 → Tanimoto similarity
3.3 알고리즘
초기화:
반복:
종료 조건:
→ 추가 oracle 호출 없음
→ 항상 aligned dataset 유지
4. 이론적 근거 (Proposition 1)
Trust region 내에서 surrogate 오차 상한:
여기서:
- : trust region radius
- : Lipschitz constants
핵심:
→ upper bound 감소
즉, misalignment 제거가 surrogate 일반화 성능을 직접 개선.
5. 방법 2: Potential-aware Trust Region Anchor Selection (PAS)
5.1 기존 방식
Anchor = 현재 best objective:
문제:
- exploitation 편향
- uncertainty 무시
5.2 제안 방식
각 trust region 에 대해:
(1) Thompson Sampling
(2) Potential Score
5.3 Scale 조정
5.4 최종 Anchor Score
즉,
- exploitation (observed )
- exploration (uncertainty 기반 potential)
동시 반영
6. 전체 알고리즘 흐름
Step 1: 초기 데이터 구성
- (x, y)
- inversion → (x, z_inv, y)
Step 2: GP surrogate 학습
- aligned decoder triplet 사용
Step 3: Trust region 생성
- PAS로 anchor 선택
Step 4: Acquisition 최적화
- Thompson sampling 기반
Step 5: 새로운 x 생성
- oracle 평가
- inversion 수행
- dataset 업데이트
7. 구조적 특징
| 구성 요소 | 역할 |
|---|---|
| Inversion | misalignment 제거 |
| PAS | exploration 강화 |
| Trust Region | high-dim 안정화 |
| GP surrogate | 합성함수 근사 |
8. 방법론의 핵심 철학
이 논문은 단순 heuristic 개선이 아니라:
“LBO의 실패 원인은 surrogate가 잘못된 함수를 학습하는 구조적 문제”
→ 이를 inversion으로 해결
이라는 점이 본질입니다
9. 연구적으로 중요한 포인트
특히 다음이 이론적으로 의미 있음:
- decoder inversion을 surrogate error bound에 직접 연결
- Lipschitz decomposition을 통한 오차 분석
- oracle-efficient alignment
이는 discrete prompt BO, latent adversarial attack, combinatorial BO 등에도 확장 가능.
LBO 계열(LOL-BO, CoBO, W-LBO) vs InvBO: 수학적 비교
아래 비교는 “surrogate가 근사해야 하는 함수가 무엇인가”와 “학습 데이터(triplet)가 그 함수와 정렬(alignment)되어 있는가”, 그리고 “trust region/regularizer가 어떤 항을 줄이려는가”라는 3축으로 정리합니다.
0) 공통 목표: LBO에서 surrogate가 근사해야 하는 진짜 함수
VAE decoder 를 통해 생성되는 후보를 평가하므로, latent에서의 진짜 목적함수는
따라서 surrogate m(z) (예: GP posterior mean)은 h(z) 를 근사해야 합니다 .
1) Triplet 정의와 “misalignment”의 수학적 핵심
(A) Encoder triplet (대부분의 LBO가 기본으로 쓰는 형태)
초기/업데이트 데이터가 로 주어질 때
.
하지만 실제 이고, 일반적으로
즉
→ 관측 레이블이 h(z)가 아니라 f(x) 로 섞여 들어가는 것이 misalignment .
(B) Decoder triplet (정렬된 데이터)
즉 가 진짜 함수 h와 정확히 정렬됩니다 .
2) W-LBO(Weighted Retraining) vs LOL-BO vs CoBO: 무엇을 “고친다”의 차이
2.1 W-LBO (NeurIPS 2020 계열) — “모델/데이터 분포를 목적에 맞게 재학습”
핵심 아이디어는 좋은 y 를 준 샘플에 더 큰 가중치를 주어 VAE를 재학습(또는 재샘플링)하며, 그 latent에서 BO를 수행하는 형태입니다.
- 수학적으로는 VAE 학습 목표가 처럼 가중(importance)된 재학습으로 바뀌는 것이 핵심입니다(“good region”을 더 잘 생성하도록 유도).
하지만 surrogate 학습이 encoder triplet에 머무르면,
로 인해 여전히
가 발생 가능하고, 즉 misalignment 자체를 구조적으로 제거하지는 않습니다. (좋은 샘플 쪽으로 VAE를 몰아도, “z–y” 정렬 문제는 별개)
요약: W-LBO는 “생성모델을 좋은 영역에 맞추는 분포 이동”이 주력이고, h(z) 정렬을 직접 보장하는 메커니즘은 약함.
2.2 LOL-BO (NeurIPS 2022) — “TuRBO식 trust region을 latent에 도입 + recentering”
LOL-BO의 큰 특징은 local BO: latent 공간에서 trust region을 두고
에서만 후보를 뽑아 고차원 BO의 난이도를 낮추는 것입니다(= TuRBO-L 스타일) .
그리고 misalignment를 줄이기 위해 prior work들은 recentering을 사용:
그럼 decoder triplet:
로 정렬은 되지만, 추가 oracle 호출로 를 얻어야 합니다(비용↑) .
요약: LOL-BO는 “localization(δ로 search space 축소)”이 주력이고, 정렬은 recentering으로 가능하나 oracle overhead가 큼.
2.3 CoBO (NeurIPS 2023) — “latent 거리와 objective 상관 구조를 학습(regularization)”
CoBO는 “좋은 latent space”를 만들기 위해, latent 거리 구조가 objective 변화와 상관되도록(= correlation) regularization을 둡니다. 논문(InvBO) 표현을 따르면 CoBO의 정규화는 성질을 낮추는 방향(= 감소)과 연결됩니다 .
InvBO의 Proposition 1에서 오차 상계가
인데, CoBO류 regularization은 주로 쪽(특히 )을 줄이려는 성격입니다 .
하지만 CoBO도 기본적으로 decoder triplet 확보를 위해 recentering을 쓰는 계열(= LOL-BO와 같은 병목)로 언급됩니다 .
요약: CoBO는 “latent geometry 개선( ↓ )”이 주력이고, misalignment는 recentering에 의존(oracle overhead 가능).
3) InvBO가 “수학적으로” 바꾸는 지점: γ 항 제거 + anchor 선택 목적함수 변경
3.1 Inversion으로 정렬: 를 직접 줄임
InvBO inversion은
로 평가된 x 를 정확히 재생성하는 latent를 찾아
를 달성합니다 .
→ 위 상계에서 를 거의 제거.
중요 차이:
- recentering: 로 내려가서 y’=f(x’)를 새로 얻음(oracle 필요)
- inversion: 로 올려서 를 바로 h에 정렬(oracle 추가 0) .
3.2 PAS로 anchor 선택 규칙 자체를 변경
기존 trust region anchor는 보통
(현재 best)인데, InvBO의 PAS는 Thompson sampling 기반 “potential”을 더해
로 선택합니다 .
→ 이는 “local search의 중심”을 단순 exploitation이 아니라 exploration 가치(불확실성/상향 가능성) 까지 반영하도록 목적함수를 바꾼 것.
4) 한 장 요약: 무엇을 줄이려는가(오차 상계 관점)
Proposition 1 상계:
- W-LBO: 생성분포/데이터 재가중으로 “좋은 영역 샘플링”을 늘림 (상계 항을 직접 겨냥하기보다 데이터 분포 이동)
- LOL-BO: trust region으로 를 관리(작게 유지/스케줄링)
- CoBO: latent-목표 상관 regularizer로 (및 간접적으로 )를 낮추려는 방향
- InvBO: inversion으로 (정렬) + PAS로 anchor 선택을 개선(실질적으로 더 좋은 local region을 선택)
이게 InvBO가 “다른 계열과 orthogonal하게 결합 가능”하다고 주장하는 근거입니다(논문에서도 기존 방법들에 plug-and-play로 성능 상승 보고) .
5) 실무적으로 어떤 조합이 가장 의미 있나?
- CoBO + InvBO가 논문에서 최상 성능을 반복적으로 보임: CoBO의 개선 + InvBO의 제거가 상계에서 서로 다른 항을 동시에 낮추는 조합이기 때문(논문 분석 섹션에서도 “complement”로 서술) .
답글 남기기