
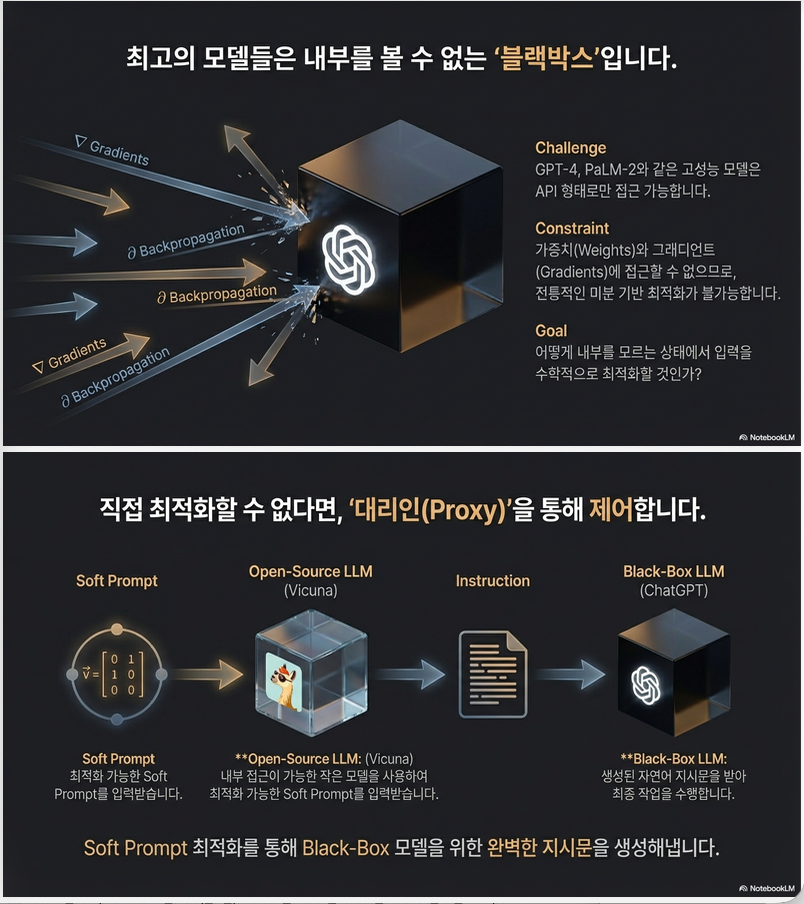



1. 문제 정의: 왜 Instruction 최적화가 어려운가?
LLM은 instruction-following 능력이 있지만, instruction phrasing에 매우 민감합니다.
동일한 의미라도 표현이 조금만 달라지면 성능이 크게 변합니다.
논문은 다음 문제를 다룹니다:
- : 최적의 instruction
- : black-box LLM (예: ChatGPT)
- : 정확도 등 평가 함수
핵심 난점
- Combinatorial Optimization
- instruction은 discrete text
- 구조적 제약 + 의미 제약
- gradient 없음
- Black-box Setting
- API만 제공됨
- backprop 불가능
- log-prob 접근 제한 (ChatGPT)
2. 핵심 아이디어
직접 instruction을 최적화하지 않는다.
대신,
Soft prompt를 최적화해서, open-source LLM이 좋은 instruction을 생성하도록 유도한다.
전체 구조 (2-stage LLM 구조)
Soft Prompt p → Open-source LLM g(·) → Instruction v
↓
Black-box LLM f(·)
↓
Zero-shot 성능3. 수학적 재정식화
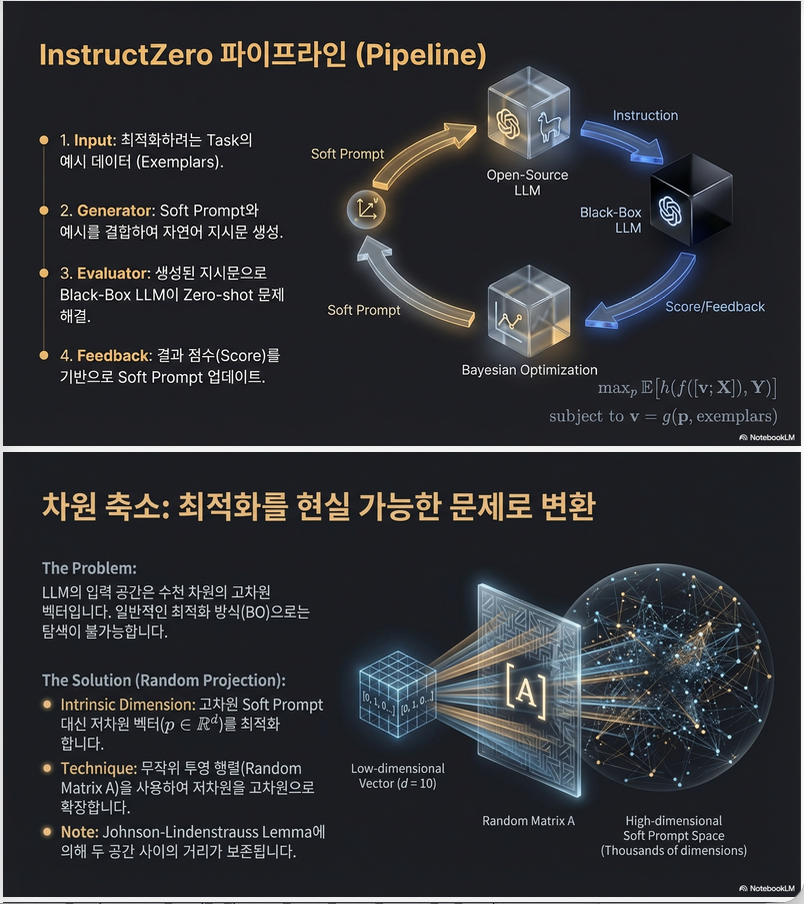
Instruction 는 open-source LLM이 생성:
그리고 최적화 대상은:
여기서
즉:
Instruction optimization → Low-dimensional soft prompt optimization
4. 차원 축소 전략
원래 soft prompt는 수천 차원.
논문은:
그리고 random projection:
- Johnson–Lindenstrauss lemma 활용
- 거리 보존 → kernel 구조 유지
–> Bayesian Optimization을 low-d space에서 수행 가능
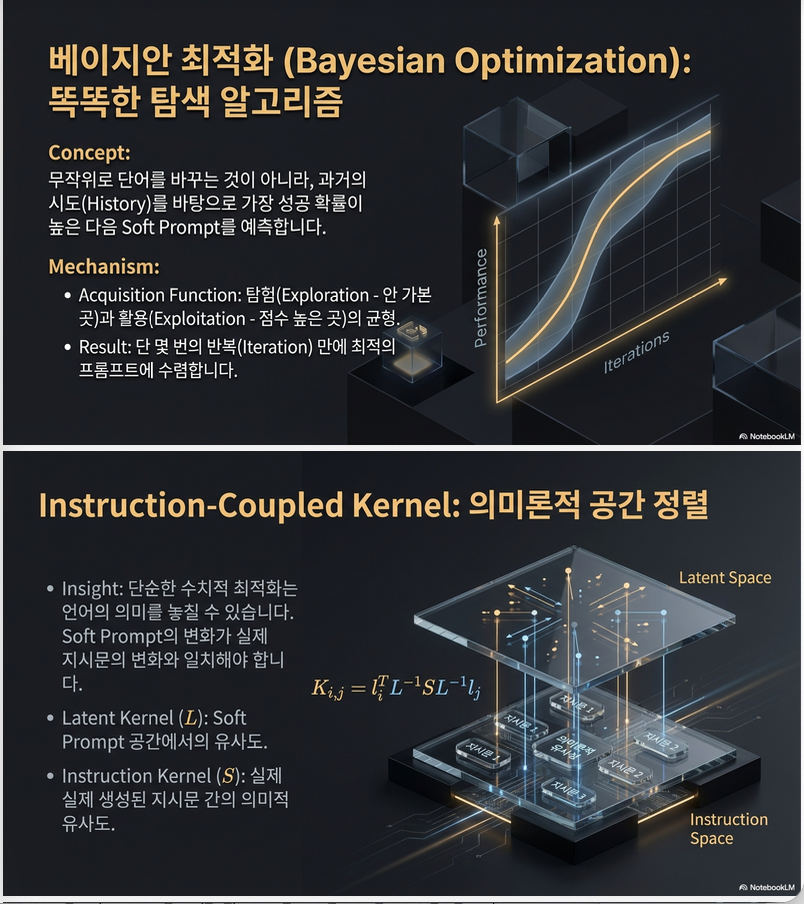
5. Bayesian Optimization (BO)
Gaussian Process 기반 BO 적용.
Posterior:
Acquisition function (Expected Improvement):
6. 논문의 핵심 기여: Instruction-Coupled Kernel
BO에서 가장 중요한 건 kernel 선택.
기존 방식:
- latent space kernel만 사용
문제:
- soft prompt similarity ≠ instruction similarity
해결책: Instruction-Coupled Kernel
두 개의 kernel 사용:
- : soft prompt kernel
- : instruction similarity kernel
instruction similarity 정의:
최종 kernel:
즉,
Soft prompt space에서 BO를 하면서 instruction space 구조를 강제로 반영
이게 이 논문의 기술적 핵심입니다.
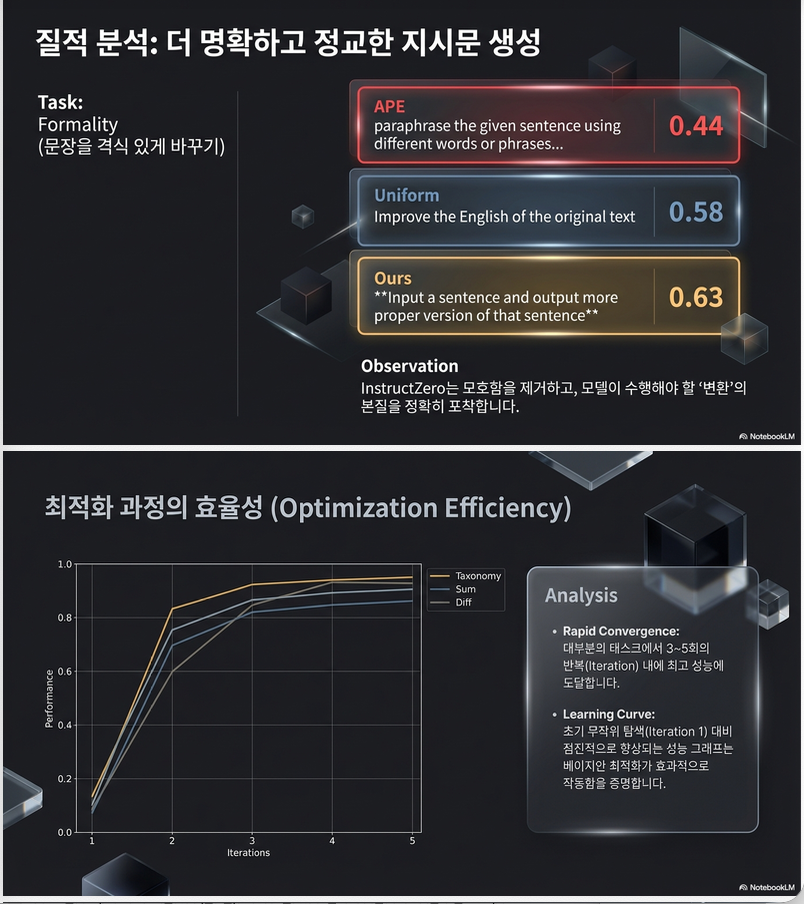
7. 실험 결과
32개 BIG-Bench task
- Open-source: Vicuna
- Black-box: ChatGPT (GPT-3.5)
결과:
- 32/32 task에서 SOTA
- APE 대비 대폭 개선
- 일부 task에서 +20~100% 개선
Ablation
| Variant | 성능 |
|---|---|
| Manual prompt | 낮음 |
| Exemplars only | 낮음 |
| INSTRUCTZERO | 가장 높음 |
Instruction-coupled kernel 제거 시 성능 하락.
8. 흥미로운 관찰
Scaling Law를 깨는 현상
- Vicuna (작은 모델)
- ChatGPT보다 instruction 생성 능력이 낮음
그런데도
Vicuna + BO > ChatGPT가 직접 생성한 instruction
즉,
“작은 모델 + optimization > 큰 모델의 단발 생성”
9. 이 논문의 의의
기술적 의의
- Black-box LLM에 대해 zeroth-order instruction optimization
- Structured combinatorial space → latent BO로 변환
- Instruction-coupled kernel 제안
개념적 의의
- Prompt engineering을 optimization 문제로 정식화
- API-only LLM에서도 성능 개선 가능
- RL 없이 discrete instruction 개선 가능
10. 한계
- 평가 비용 큼 (API 반복 호출)
- validation set 필요
- task-specific optimization (transferability 제한)
- BO 스케일 이슈
11. 연구 관점에서의 연결 지점
이 논문은 다음과 밀접하게 연결됩니다:
- Zeroth-order optimization
- Black-box adversarial attack
- Latent space BO
- Prompt optimization
- Structured kernel design
- Instruction induction
12. 한 문장 요약
Instruction을 직접 최적화하지 않고, soft prompt를 Bayesian Optimization으로 최적화하여 open-source LLM이 더 좋은 instruction을 생성하게 만드는 방법.
INSTRUCTZERO 방법론 정리
본 논문의 핵심은 black-box LLM의 instruction을 직접 최적화하지 않고,
그 대신 soft prompt를 최적화하여 open-source LLM이 더 좋은 instruction을 생성하도록 만드는 것입니다
아래에서 방법론을 구조적으로 정리합니다.
1. 문제 설정
우리는 black-box LLM f (예: ChatGPT)에 적용할 instruction 를 찾고 싶습니다.
목표:
- : human-readable instruction
- : API LLM
- : accuracy 등 평가 함수
- : task distribution
난점
- 는 discrete text (combinatorial)
- backprop 불가 (black-box)
- gradient-free search 필요
2. 핵심 아이디어: Instruction → Soft Prompt로 우회
직접 instruction을 최적화하지 않는다.
대신:
- : open-source LLM
- 최적화 대상 soft prompt
- A: random projection matrix
- : exemplar
즉,
Soft prompt → Open LLM → Instruction → Black-box LLM
3. 차원 축소 (Random Projection)
원래 token embedding 차원 d’는 매우 큼.
논문은:
그리고
이유:
- Johnson–Lindenstrauss lemma 기반 거리 보존
- BO가 가능한 저차원 공간 형성
결과적으로 최적화 문제는:
4. Bayesian Optimization
H(p)는 black-box function.
따라서 Gaussian Process 기반 BO 적용.
4.1 GP posterior
수집 데이터:
Posterior:
4.2 Acquisition (Expected Improvement)
다음 탐색점:
5. 논문의 핵심 기여: Instruction-Coupled Kernel
일반 BO는 latent space kernel만 사용:
하지만 soft prompt 유사도 ≠ instruction 유사도.
5.1 Instruction similarity 정의
즉,
두 instruction이 실제 task 예측에서 얼마나 비슷한지
5.2 Coupled Kernel
Soft prompt kernel matrix L
Instruction kernel matrix S
최종 kernel:
특징:
- 기존 point에서는 K = S 정확히 복원
- 새로운 point에서는 smooth extrapolation
결과:
BO가 instruction space 구조를 반영하도록 강제
6. 전체 알고리즘
반복:
- soft prompt 선택
- instruction
- black-box LLM 평가 → score
- GP 업데이트
- EI 최대화 → 다음
최종 출력:
7. 핵심 설계 포인트 요약
| 구성요소 | 역할 |
|---|---|
| Soft prompt | continuous optimization 대상 |
| Open LLM | instruction generator |
| Black-box LLM | 실제 성능 평가 |
| BO | gradient-free search |
| Instruction kernel | latent–text alignment |
8. 기존 방법과의 차이
| 방법 | 특징 |
|---|---|
| APE | LLM sampling 기반 탐색 |
| RLPrompt | RL 기반 discrete 탐색 |
| AutoPrompt | gradient 기반 trigger search |
| INSTRUCTZERO | latent BO + instruction-aligned kernel |
9. 방법론의 핵심 메시지
- Discrete instruction 최적화는 어렵다.
- Continuous latent space에서 우회하라.
- Kernel을 instruction space와 정렬하라.
- Zeroth-order BO로 해결하라.
연구 관점에서의 해석
이 논문은:
- Structured combinatorial BO
- Latent-space optimization
- Prompt tuning의 black-box 확장
- Instruction induction + BO 결합
이라는 관점에서 해석할 수 있습니다.
커널 개념을 처음 접하는 사람도 이해할 수 있도록, INSTRUCTZERO의
Instruction-Coupled Kernel을 직관 → 수학 → 의미 순으로 설명하겠습니다.
1. 커널이란 무엇인가? (아주 직관적으로)
✔ 커널 = “비슷함을 수치로 표현하는 함수”
두 개의 대상이 얼마나 비슷한지를 숫자로 표현합니다.
예시:
- 문장 A, 문장 B
- 벡터 x, y
- soft prompt
커널 함수는:
k(x, y)
- 크면 → 매우 비슷
- 작으면 → 덜 비슷
쉬운 예시
벡터 두 개:
이 둘은 거의 같으므로 커널 값은 큼.
z = (100, -50)
x와 z는 매우 다름 → 커널 값 작음.
2. Bayesian Optimization에서 커널의 역할
BO는 이렇게 생각합니다:
“비슷한 입력은 비슷한 성능을 낼 것이다.”
즉,
- soft prompt 가 좋았다면
- 그 근처의 prompt도 좋을 가능성이 높다
이 “근처” 개념을 정의하는 것이 커널입니다.
3. INSTRUCTZERO의 문제
우리가 실제로 최적화하고 싶은 것은:
instruction의 성능
하지만 BO는:
soft prompt 공간에서 탐색
문제는:
soft prompt가 비슷하다고 instruction이 비슷하지 않을 수 있음
직관적 예
- soft prompt A
- soft prompt B
벡터상 매우 가까움.
하지만 open LLM이:
- A → “Translate to German”
- B → “Translate to Spanish”
같이 완전히 다른 instruction 생성 가능.
즉,
latent 공간 거리 ≠ instruction 의미 거리
4. 그래서 등장한 Instruction-Coupled Kernel
논문은 두 가지 “비슷함”을 정의합니다.
4.1 Soft Prompt Kernel
→ 벡터 거리 기반 similarity
4.2 Instruction Kernel
의미:
두 instruction이 실제 task 예측 결과가 얼마나 비슷한가?
즉,
- 결과가 비슷하면 → 높은 값
- 결과가 다르면 → 낮은 값
5. 논문의 핵심 수학식
논문은 다음 커널을 제안합니다:
이걸 쉽게 풀어 설명하겠습니다.
6. 수학을 직관으로 번역
Step 1: 기존 관측된 데이터
지금까지 m개의 soft prompt를 평가했다고 합시다:
각각 instruction 생성:
그리고 성능도 알고 있음.
Step 2: 두 개의 행렬 생성
(1) Soft prompt kernel matrix
→ latent space similarity
(2) Instruction kernel matrix
→ instruction 결과 기반 similarity
7. 핵심 아이디어
논문은 다음을 강제합니다:
“기존 데이터들에 대해서는,
soft prompt kernel이 instruction kernel과 동일해야 한다.”
즉,
K = S
이 조건을 만족하도록 커널을 설계합니다.
8. 왜 가 등장하는가?
목표:
soft prompt 공간에서 계산한 커널이
instruction similarity를 정확히 복원해야 함.
수학적으로,
즉,
- 기존 포인트들에 대해선
- instruction similarity가 정확히 반영됨
9. 직관적 해석
이 커널은 이렇게 작동합니다:
기존 데이터에서는
soft prompt 유사도 대신 instruction 유사도를 강제로 사용
새로운 soft prompt에서는
soft prompt 기반 거리 + instruction 구조를 부드럽게 반영
10. 왜 이게 중요한가?
BO는 커널을 이용해:
- 평균 예측
- 불확실성 추정
을 계산합니다.
만약 커널이 instruction 구조를 반영하지 않으면:
BO는 “좋은 instruction 방향”으로 이동하지 못함.
하지만 이 커널은:
BO가 instruction space 구조를 보면서 탐색하게 만듦.
11. 비유로 이해하기
Imagine:
- 지도 위에서 위치 최적화 중
- 그런데 실제 목적지는 지도가 아니라 현실 공간에 있음
Instruction-Coupled Kernel은:
지도를 현실 좌표에 맞게 왜곡시켜, 올바른 방향으로 가도록 만드는 장치
12. 한 줄 요약
일반 커널:
“벡터가 비슷하면 성능도 비슷할 것이다.”
Instruction-Coupled Kernel:
“instruction 결과가 비슷하면 성능도 비슷할 것이다.”
그리고 이를 soft prompt 공간에 수학적으로 투영한 것.
13. 왜 단순히 S만 쓰지 않는가?
이유:
- 새로운 soft prompt는 아직 instruction 생성 안 됨
- S는 기존 데이터에만 정의 가능
- extrapolation 필요
따라서:
latent space 구조 + instruction 구조 결합
14. 이 논문의 수학적 의미
이 방법은 다음과 유사합니다:
- Structured Bayesian Optimization
- Manifold-aligned kernel learning
- Latent-to-structure alignment
즉,
Combinatorial space 구조를 continuous latent space에 주입하는 기법
Instruction-Coupled Kernel이 GP posterior에 어떻게 직접적으로 영향을 미치는지를
완전히 기초부터 설명하겠습니다.
1. Gaussian Process를 모른다고 가정하고 시작
우리가 하고 싶은 것
우리는 어떤 함수 H(p)를 최대화하고 싶습니다.
문제:
- 함수의 형태를 모름
- gradient 없음
- 매번 평가 비용이 큼 (API 호출)
그래서 우리는:
“함수를 직접 알 수 없으니, 함수를 추정하면서 최적점으로 가자”
이때 사용하는 것이 Gaussian Process (GP) 입니다.
2. GP를 아주 직관적으로 설명
GP = “가능한 함수들의 확률 분포”
우리는 생각합니다:
“H(p)는 어떤 매끄러운 함수일 것이다.”
GP는 말합니다:
“가능한 모든 매끄러운 함수들 중에서,
지금까지 본 데이터와 잘 맞는 함수들에 높은 확률을 주자.”
3. GP의 핵심 구성 요소
GP는 두 가지로 정의됩니다:
- : 평균 함수
- : 커널 (공분산 함수)
커널의 의미
= “와 에서 함수값이 얼마나 같이 움직일지”
즉,
- 값이 크면 → 두 점에서 함수값이 비슷할 것
- 작으면 → 상관 없음
4. 관측 데이터를 넣으면 posterior가 생긴다
지금까지 m개의 soft prompt를 평가했다고 합시다:
이걸 GP에 넣으면:
새로운 점 p에서 함수값의 확률분포가 업데이트됨
5. GP posterior 수식
논문에 나오는 식:
6. 이 식을 직관적으로 해석
기호 정리
- K: 기존 점들 사이 커널 행렬
- k: 새로운 점과 기존 점들 사이 커널 벡터
- H: 기존 관측 성능 벡터
6.1 평균 의미
이건 essentially:
기존 성능들의 가중 평균
가중치는?
즉,
“새로운 점이 기존 점들과 얼마나 비슷한지”
핵심
커널이 정의하는 similarity가
예측 평균을 직접 결정한다.
6.2 분산
의미:
“새로운 점이 기존 데이터로 얼마나 설명 가능한가?”
- 기존 점들과 매우 비슷 → 분산 작음
- 멀리 떨어짐 → 분산 큼
7. 이제 핵심 질문
GP posterior는 커널에 어떻게 의존하는가?
정답:
완전히 의존한다.
- 평균 계산에 K와 k가 들어감
- 분산 계산에도 K와 k가 들어감
즉,
커널이 바뀌면 posterior 전체가 바뀜
8. INSTRUCTZERO에서 커널이 하는 역할
기존 BO라면:
→ soft prompt 벡터 거리 기반
하지만 문제는:
soft prompt similarity ≠ instruction similarity
9. Instruction-Coupled Kernel을 쓰면?
커널이:
구조로 설계됨.
이때:
- S = instruction similarity matrix
즉,
GP가 보는 “함수의 구조”가 instruction 구조가 됨
10. GP posterior에 미치는 직접적 영향
(1) 평균이 바뀜
여기서
- k는 instruction 구조 반영
- K는 instruction similarity 기반
결과:
“instruction이 비슷한 방향으로 예측이 퍼진다.”
(2) 분산이 바뀜
결과:
instruction space에서 unexplored 영역에 높은 uncertainty 부여
11. 직관적 비교
일반 커널
BO는 생각한다:
벡터가 비슷하면 성능도 비슷
Instruction-Coupled Kernel
BO는 생각한다:
instruction 결과가 비슷하면 성능도 비슷
12. 왜 이게 중요한가?
Expected Improvement는:
EI는:
- 평균 ↑
- 분산 ↑
둘 다 좋아함.
커널이 instruction 구조를 반영하면:
EI가 instruction improvement 방향으로 이동
13. 한 문장 요약
GP posterior는:
“커널이 정의하는 similarity 구조 위에서
함수값을 보간(interpolate)하는 기계”
Instruction-Coupled Kernel은:
그 similarity를 instruction space 기준으로 재정의한 것.
14. 그림으로 요약
Soft Prompt Space → Kernel → GP Posterior
↓ ↑
Instruction Similarity ← Instruction-Coupled Kernel15. 수학적 의미 (한 단계 더 깊게)
GP는 RKHS 공간에서의 선형 회귀와 동일합니다.
즉,
Instruction-Coupled Kernel은
basis function을 instruction 구조에 맞게 재정의
16. 최종 정리
| 구성 | 역할 |
|---|---|
| 커널 | similarity 정의 |
| GP 평균 | similarity 기반 가중 평균 |
| GP 분산 | similarity 기반 불확실성 |
| Instruction kernel | similarity를 instruction 기준으로 교체 |
이번에는 Gaussian Process(GP) posterior 수식이 왜 그렇게 생기는지를
정말 기초부터, 다변량 가우시안의 조건부 분포 공식까지 포함해 유도해보겠습니다.
1. 우리가 풀고 싶은 문제
우리는 어떤 미지 함수:
H(p)
를 모릅니다.
이미 관측한 데이터:
이제 새로운 점 에서의 함수값 를 추정하고 싶습니다.
2. Gaussian Process란?
Gaussian Process는 말합니다:
“함수값들의 집합은 다변량 가우시안 분포를 따른다.”
즉, 임의의 점들을 선택하면:
3. 여기서 기호 의미
- K: 기존 점들 사이 커널 행렬
- k: 새 점과 기존 점 사이 벡터
4. 다변량 가우시안의 조건부 분포 공식
이제 핵심.
다변량 가우시안이:
일 때,
조건부 분포:
5. GP에 이 공식을 적용
우리는:
로 둡니다.
그러면:
보통 prior mean을 0으로 두면:
6. posterior variance
공식에 그대로 대입하면:
7. 왜 이런 형태가 되는가? (직관)
평균식
의 의미:
기존 함수값들의 가중합
가중치:
즉,
새 점이 기존 점들과 얼마나 상관있는지에 따라 가중 평균
분산식
의 의미:
- prior variance에서
- 기존 데이터로 설명 가능한 부분을 빼줌
8. 선형 회귀 관점 해석
GP는 사실:
커널 feature space에서의 Bayesian linear regression
과 동일합니다.
커널은:
라고 생각할 수 있습니다.
GP는:
이고 w에 대해 Bayesian inference를 수행하는 것과 동일.
9. 노이즈 포함한 경우
실제 관측은 노이즈 포함:
그러면:
따라서 최종식:
10. 핵심 요약
GP posterior 수식은:
다변량 가우시안의 조건부 분포 공식을 그대로 적용한 결과
11. INSTRUCTZERO와 연결
이 수식에서:
- K가 Instruction-Coupled Kernel로 대체됨
- 따라서 posterior 평균과 분산이 instruction similarity 기반으로 계산됨
즉:
커널이 posterior를 완전히 결정한다.
답글 남기기