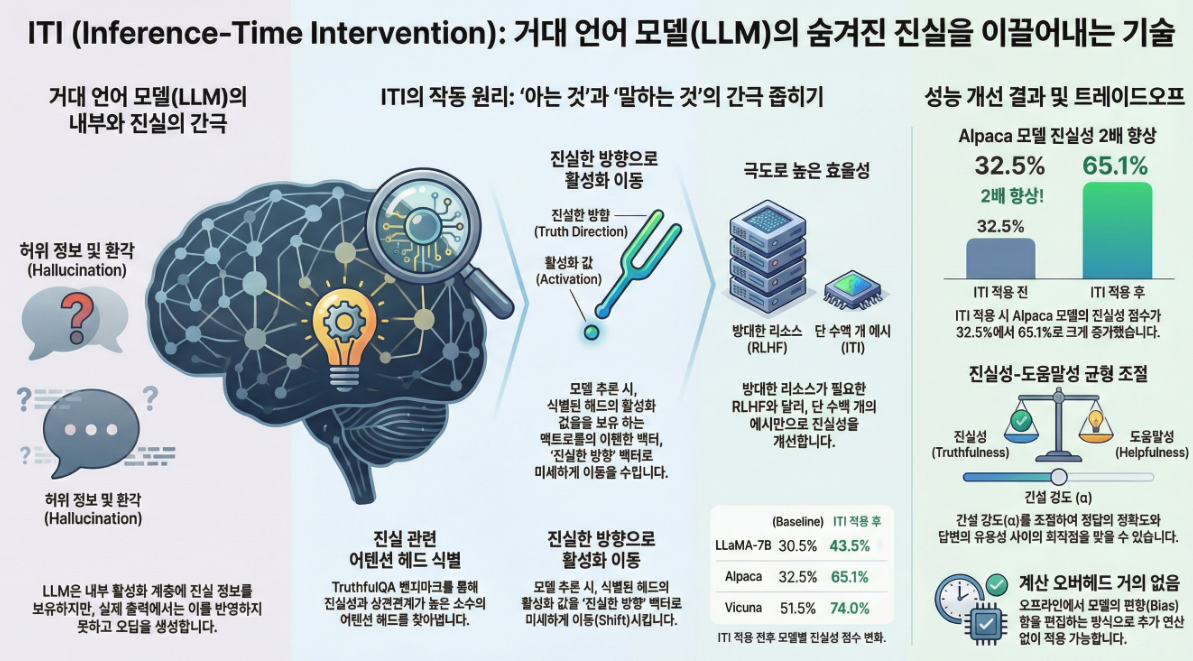

1. 문제의식: 모델은 “알지만 말하지 않는다”
이 논문의 출발점은 Generation–Discrimination Gap (G-D gap) 입니다.
- Generation accuracy: 모델이 실제로 생성한 답변의 정확성
- Probe accuracy: 중간 activation을 사용해 “이 답이 진실인가?”를 분류하는 정확성
LLaMA-7B + TruthfulQA에서:
- Generation 정확도 ≈ 30%
- Probe 정확도 ≈ 70%+
👉 모델 내부에는 ‘진실 여부’ 정보가 존재하지만, decoding 과정에서 그것이 제대로 반영되지 않는다는 강한 증거를 제시합니다
2. 핵심 아이디어: Inference-Time Intervention (ITI)
한 줄 요약
“진실과 강하게 상관된 attention head의 activation을, inference 중에 살짝 밀어준다.”
중요한 점
- ❌ 파라미터 업데이트 없음 (no finetuning)
- ❌ RLHF 없음
- ✅ Inference-time activation editing
- ✅ 매우 적은 supervision (수십~수백 샘플)
3. 방법론 핵심 구조
3.1 어디를 조작하나? → Attention head level
Transformer의 attention을 다음처럼 해석합니다:
- 각 attention head 출력 를 residual stream에 더함
- ITI는 Att 이후, Q 이전의 head activation 공간을 조작
👉 Residual 전체가 아니라, “선별된 head만” 조작 → minimal intervention
3.2 Truthful Head 찾기 (Probing)
- TruthfulQA의 (Q, A, y) 데이터로
- 각 (layer l, head h)에 대해 linear probe 학습:
- validation accuracy로 head ranking
- 상위 K개 head만 선택
👉 중요한 관찰:
- 대부분 head는 random 수준
- 소수의 head만 truthfulness와 강하게 연관
3.3 어느 방향으로 미는가? (Steering direction)
논문은 3가지 방향을 비교:
- Probe weight direction (결정경계 법선)
- Mass mean shift (false → true 평균 벡터)
- CCS direction (Burns et al.)
👉 Mass mean shift가 가장 안정적 & 성능 우수
3.4 실제 Intervention 수식
선택된 head에 대해:
- : intervention strength
- : 해당 방향의 표준편차
- autoregressive decoding 매 토큰마다 반복
4. 실험 결과 (중요 수치)
4.1 TruthfulQA (Generation)
| Model | True*Info |
|---|---|
| LLaMA-7B | 30.5 |
| LLaMA-7B + ITI | 43.5 |
| Alpaca | 32.5 |
| Alpaca + ITI | 65.1 |
| Vicuna | 51.5 |
| Vicuna + ITI | 74.0 |
→ instruction tuning 위에 얹어도 큰 개선
4.2 Trade-off: Truthfulness vs Helpfulness
- α ↑ → 진실 ↑
- 그러나 “I have no comment” 증가
- Upside-down U shape
👉 Safety / helpfulness trade-off를 명시적으로 조절 가능
4.3 Generalization (OOD)
TruthfulQA에서 찾은 direction을 그대로 적용:
| Dataset | Base | +ITI |
|---|---|---|
| Natural Questions | 46.6 | 51.3 |
| TriviaQA | 89.6 | 91.1 |
| MMLU | 35.7 | 40.2 |
→ Overfitting 아님을 실증
5. 왜 이 논문이 중요한가? (해석적 관점)
(1) “Truth neuron / truth subspace”의 실증
- Truthfulness가 선형 분리 가능
- 단일 방향이 아니라 subspace 구조
(2) Steering ≠ Finetuning
- RLHF의 “행동 학습”이 아니라
- 이미 존재하는 내부 지식의 readout 문제로 해석
(3) 이후 연구에 미친 영향
- Activation steering (CAA, SADI, PID steering)
- Circuit-level truth editing
- Inference-time safety control 계열 연구의 시초
6. 한계점 (중요)
- TruthfulQA 정의에 강하게 의존
- “truth ≠ correctness in all contexts”
- Helpfulness 저하 가능
- 메커니즘적 설명은 아직 부족 (head가 왜 truth인지?)
아래에서는 ITI (Inference-Time Intervention) 논문의 **방법론(Methodology)**만을, 수식·설계 선택·알고리즘 흐름 중심으로 정리합니다.
1. 문제 설정: Generation–Probe Gap 정식화
데이터셋을 (TruthfulQA)로 두고,
- Generation accuracy: 모델이 실제 생성한 답변의 truthfulness
- Probe accuracy: 중간 activation으로 (y)를 분류하는 정확도
LLaMA-7B에서 두 정확도 사이에 큰 격차가 관측됨 → 내부에는 진실 신호가 있으나 출력으로 반영되지 않음
2. 개입 위치: Attention Head Activation
Transformer 한 층에서의 MHA를 다음처럼 분해합니다.
- : residual stream
- : residual → head space
- : attention 연산
- : head → residual
개입 지점: 이후, 이전의 head output
→ residual 전체가 아닌 선별된 head만 조작 (minimally invasive)
3. Truthful Head 탐색 (Linear Probing)
3.1 Probe 학습
각 (layer , head )에 대해 head activation 로 이진 분류기 학습:
- 학습/검증 분할 후 validation accuracy로 head의 truth-relatedness 측정
- 관찰: 대부분 head는 무작위 수준, 소수의 head만 고성능
3.2 Head 선택
- 정확도 기준으로 상위 K개 head만 선택 (head-wise sparsification)
4. Steering Direction 결정
각 선택된 head에 대해 “어느 방향으로 밀 것인가?”를 정의합니다.
논문에서 비교한 방향들:
- Probe-weight direction: (결정경계 법선)
- Mass Mean Shift (채택):
- CCS direction (비지도, 비교용)
실험적으로 Mass Mean Shift가 가장 안정적이며 강한 개입에서도 성능 유지
5. Inference-Time Intervention 수식
선택된 head에 대해서만 다음과 같이 activation을 이동:
- : truthful direction
- : 해당 방향의 activation 표준편차 (스케일 정규화)
- : intervention strength
- 비선택 head는
특징
- 매 토큰 autoregressive decoding 동안 반복
- decoding 방식(greedy, sampling)과 독립적
6. 하이퍼파라미터와 트레이드오프
- K (head 수): sparsity ↔ 영향 범위
- α (강도): truthfulness ↑ ↔ helpfulness ↓
→ 성능은 inverted-U curve (과도하면 “I have no comment” 증가)
7. 계산 효율 및 오프라인 편집
- 런타임 오버헤드 ≈ 0 (상수 벡터 추가)
- 동일 효과를 bias 편집으로 오프라인 bake 가능:
→ inference-time 수정 없이 동일한 개입 효과
8. 방법론 요약 (Algorithmic View)
- TruthfulQA로 (layer, head)별 linear probe 학습
- Validation accuracy로 상위 K개 head 선택
- 각 head에 대해 mass mean shift 방향 추정
- Inference 시 선택된 head activation을 만큼 이동
- 모든 토큰 생성 시 반복
아래에서는 ITI (Inference-Time Intervention) 논문의 **실험 결과(Experimental Results)**를 지표–비교–분석 구조로 정리합니다. (방법론 설명은 생략하고 결과 해석 중심)
1. 핵심 실험 설정 요약
- 모델: LLaMA-7B, Alpaca, Vicuna
- 주 평가 벤치마크: TruthfulQA
- 평가 트랙
- Generation: 자유 생성 후 truthfulness 평가
- Multiple-choice (MC): 후보 답변 확률 비교
- 주요 지표
- True*Informative (TruthfulQA 핵심 지표)
- True
- MC accuracy
- CE / KL: 원래 모델 분포로부터의 이탈 정도
2. TruthfulQA – LLaMA-7B (핵심 결과)
2.1 Baseline 대비 ITI 효과
| Model | True*Info | True | MC Acc |
|---|---|---|---|
| LLaMA-7B (baseline) | 30.5 | 31.6 | 25.7 |
| LLaMA-7B + ITI | 43.5 | 49.1 | 25.9 |
- **+13.0p (True*Info)**의 큰 향상
- MC는 거의 유지 → hallucination 감소가 핵심 효과
- CE, KL은 증가하지만 제한적 (분포 붕괴 아님)
2.2 Few-shot / SFT 대비
| Method | True*Info |
|---|---|
| Supervised Fine-Tuning (5%) | 36.1 |
| Few-shot Prompting (50-shot) | 49.5 |
| Baseline + ITI | 43.5 |
| Few-shot + ITI | 51.4 |
👉 ITI는 prompting·finetuning과 직교적
→ “위에 얹을 수 있는(inference-time overlay)” 기법
3. Instruction-Tuned 모델에서의 효과
Alpaca / Vicuna
| Model | True*Info | True |
|---|---|---|
| Alpaca | 32.5 | 32.7 |
| Alpaca + ITI | 65.1 | 66.6 |
| Vicuna | 51.5 | 55.6 |
| Vicuna + ITI | 74.0 | 88.6 |
- instruction tuning이 이미 있음에도 추가로 큰 개선
- 특히 Alpaca에서 2배 가까운 향상
- ITI가 *alignment finetuning을 “대체”하지 않고 “보강”*함을 실증
4. Intervention Strength (α, K) 실험
4.1 Truthfulness–Helpfulness Trade-off
- α 증가 → Truth ↑
- 그러나 일정 이상 → “I have no comment” 증가
- 성능 곡선: inverted-U shape
👉 ITI는 사용자가 명시적으로 trade-off를 조절 가능
4.2 Head 수 K의 영향
- 적은 수의 head만 개입할 때 가장 효율적
- 모든 head 개입 시:
- CE/KL 급증
- informative score 하락
→ Head-wise sparsification이 핵심 설계 요소
5. Steering Direction 비교 실험
| Direction | True*Info |
|---|---|
| Random | 31.2 |
| CCS | 33.4 |
| Probe weight | 34.8 |
| Mass Mean Shift | 42.3 |
- Mean-shift가 가장 강력 + 안정적
- 강한 α에서도 성능 유지
- 단순한 “분류 경계 법선”보다 분포 구조 활용이 중요
6. Category-wise 분석 (TruthfulQA)
- 38개 subcategory 대부분에서 일관된 개선
- 특정 유형(misconception, conspiracy)에만 국한되지 않음
- → 단일 트릭이 아닌 범용 신호
7. OOD 일반화 실험
TruthfulQA에서 학습한 direction을 그대로 적용
| Dataset | Base | +ITI |
|---|---|---|
| Natural Questions | 46.6 | 51.3 |
| TriviaQA | 89.6 | 91.1 |
| MMLU | 35.7 | 40.2 |
- Zero-shot, no re-tuning
- 분포가 다른 QA에서도 일관된 향상
- → “Truthful direction”이 task-specific artifact가 아님
8. 계산 효율 실험
- Runtime overhead ≈ 0
- Bias editing으로 offline bake 가능
- 실제 배포 가능성 강조
9. 실험 결과의 핵심 메시지 (정리)
- Truthfulness는 내부에 이미 존재
- 문제는 learning이 아니라 elicitation
- 소수의 attention head가 핵심
- Inference-time steering만으로도 RLHF 수준 이상의 효과 가능
- Safety-helpfulness trade-off를 명시적으로 조절 가능
답글 남기기