아래는 논문 **“In-Distribution Steering: Balancing Control and Coherence in Language Model Generation (2025)”**에 대한 설명입니다.
📌 논문 핵심 요약
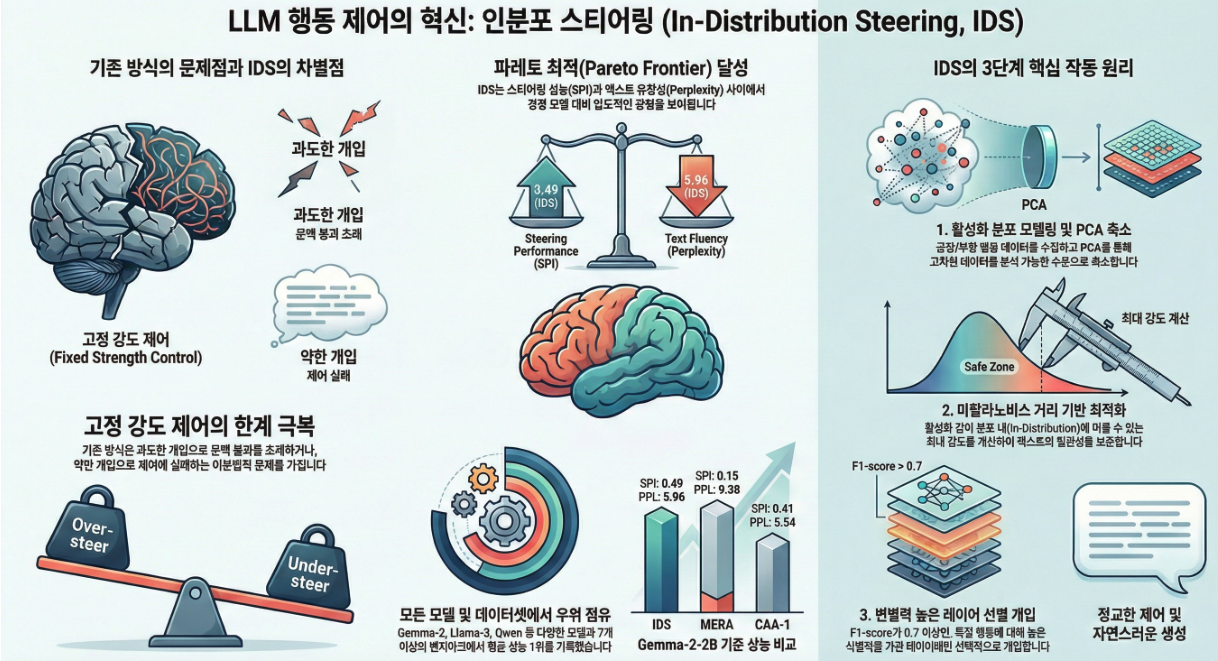
**IDS(In-Distribution Steering)**는 기존 Activation Steering 기법(CAA, MERA)의 가장 큰 한계를 해결하는 방법입니다:
“스티어링 강도 α를 고정하지 말고, 입력이 target-behavior distribution 안에 머물 수 있을 만큼만 동적으로 조절하자.”
⇒ 즉, 과소 스티어링 ↔ 과도 스티어링(activation collapse) 사이에서 최적 지점을 자동 조절해주는 방식.
IDS는 PCA + Mahalanobis distance 기반으로 각 layer, 각 token position별로 activation이 target 클래스 분포 안에 있도록 유지하면서 최대 α를 찾는 closed-form 솔루션을 제시합니다.
결과적으로:
- **SPI(Steering Performance Impact)**는 모든 baseline보다 우수
- **텍스트 품질(PPL)**은 높은 수준 유지
- 특히 open-ended generation에서 collapse를 막는 데 탁월
🧩 1. 문제의식 및 기존 기법 한계
논문이 보는 기존 Activation Steering 문제:
(1) 고정된 steering strength α
- CAA: α = 1 또는 1.5 (고정)
- MERA: probe score 기반으로 α 계산하지만, 여전히 over-steering 발생 가능
→ 입력마다 필요한 개입 강도가 다른데, 고정값은 미세한 조절 불가.
(2) Activation collapse & 비문 생성
특히 MERA는 open-ended generation에서 α가 너무 커져,
연속적인 token 위치에서 누적되며 distribution 밖으로 밀려나 문장 붕괴 발생.
예:
MERA output →
“amphe here for the Here Here…” (반복, incoherent collapse)
(3) open-ended generation을 위한 안정성 고려 부족
- 기존 steering 연구 대부분 classification에서만 성능 평가
- open generation에서 텍스트 일관성 평가 부족
🧪 2. IDS: In-Distribution Steering의 핵심 아이디어
IDS의 목표:
“activation을 최대한 steering하면서도 positive-class activation distribution 내부에 유지시키자.”
이를 위해 IDS는 3단계 프레임워크를 사용합니다.
⭐ 2.1 Step 1 — Activation Distribution Modeling
① Contrastive dataset 구성
- positive behavior (aligned) 데이터 → D⁺
- negative behavior 데이터 → D⁻
- 각 layer l의 마지막 token activation hₗ,−1을 수집해 두 분포를 모델링
→ diff-mean steering vector 계산
② PCA로 차원 축소
고차원 activation에서는 distance 측정이 불안정하므로 PCA로 약 40% variance만 유지하는 차원 축소 수행.
③ Mahalanobis distance 사용
Euclidean이 아닌 Mahalanobis를 사용하는 이유:
- 각 방향별 분산을 고려해야 함
- “concept direction”에 따른 분포 차이를 더 반영 가능
④ In-distribution threshold ε = 95% percentile
activation이 다음을 만족하면 “in-distribution”:
⭐ 2.2 Step 2 — Optimal α 계산 (논문의 핵심)
IDS의 핵심은 다음 최적화 문제입니다:
이 문제는 1차원 quadratic constraint optimization으로 환원되며 논문은 다음 closed-form을 도출합니다:
여기서
- a = ‖Mv‖²
- b = 2(Mv)ᵀ(…)
- c = initial distance − ε²
→ 즉, activation이 분포 바깥으로 벗어나지 않는 최대 α를 계산하는 과정.
⭐ 2.3 Step 3 — Layer Selection (F1 기반)
각 layer의 steering vector vₗ를 classifier로 사용했을 때 F1-score ≥ 0.7이면 해당 layer에서만 steering을 적용.
→ 실제로 behavior를 encoding하고 있는 layer에만 개입.
📊 3. 실험 결과 요약
✔ Single-logit tasks (classification)
IDS는 6개 모델 중 5개, 7개 dataset 중 5개에서 평균 1위.
(평균 Rank = 1.67로 최상)
표 1 기준:
- IDS가 MERA 대비 최대 18 point 높은 SPI
✔ Open-ended generation (가장 중요한 실험)
IDS는 모든 모델/데이터셋에서 SPI 1위,
그리고 collapse 없이 낮은 perplexity 유지.
예: refusal generation에서 MERA는 PPL 폭증(18~27) → 붕괴 발생.
IDS output (coherent):
“Here are some common symptoms you can tell your doctor…”
MERA output (collapse):
“amphe here for the Here Here…”
이는 IDS의 가장 중요한 장점을 명확히 보여줌:
- steering 강도를 adaptive하게 조절
- 누적 over-steering 방지
- 텍스트 coherence 유지
🔍 4. IDS가 좋은 이유 — 논문의 해석
(1) α를 자동으로 조절하는 유일한 방법
직관적으로, IDS는 다음을 보장:
activation이 target distribution 안에 있게 하면서 가능한 최대한 steering
즉:
- 입력이 이미 target behavior에 가깝다 → α 작게
- 입력이 멀다 → α 크게
- 단, 항상 distribution 밖으로 벗어나지 않도록 제약
(2) open-ended generation에서 누적 collapse 방지
MERA는 token별 α가 커서 아래와 같이 layer에서 계속 누적되는 패턴을 보임:
- layer 10 → 20 → 25로 갈수록 α 증가
- 결국 activation이 분포를 벗어나 PPL 폭증
반면 IDS는 α가 layer 깊어질수록 낮아지도록 자동 조절 → 안정적.
(3) PCA+Mahalanobis 기반의 수학적으로 해석 가능한 steering 방법
- RLHF나 prompt engineering보다 훨씬 투명
- activation distribution을 이용하므로 “plausibility” 보장
🔬 5. Ablation Study 주요 결과
(1) PCA variance retained
- 30–42%일 때 가장 좋은 SPI
- 너무 높으면 “curse of dimensionality”로 distance 의미 상실
(2) Mahalanobis threshold ε
- ε을 조금 높이면 SPI 약간 증가
(조금 더 distribution 밖을 허용 → 더 강한 steering 가능)
(3) F1 threshold
- F1 ≥ 0.8 이상으로 높이면
→ steering 적용 layer 수가 급감 → 성능 하락
🧭 6. 논문의 기여 정리
1) Adaptive steering strength: dynamically computed α
- 어떤 입력에도 고정 α를 쓰지 않음
- 분포 기반 α 최적화로 과/소 steering 모두 방지
2) Closed-form solution 제시
- inference-time에 빠르게 계산 가능
3) open-ended generation에서 collapse 방지
- steering 연구에서 매우 중요한 문제를 해결
4) strong SPI performance + low perplexity
- alignment 효과 + 텍스트 품질 둘 다 보장
📌 결론 한 줄 요약
IDS는 activation steering을 “분포 기반 최적화” 문제로 재정의하여,
가장 큰 난제였던 open-ended text collapse 문제를 해결하고,
가장 강력하면서도 안정적인 steering 방법을 제시한 논문이다.
아래에서는 논문 2장(IDS 핵심 아이디어)을 훨씬 더 직관적·수학적·메커니즘적으로 재구성하여
“왜 IDS가 필요한가, 어떤 원리로 동작하는가, 기존 steering과 무엇이 다른가”를
연구자 수준에서 완전히 이해할 수 있도록 정리해드립니다.
🔥 2. IDS: In-Distribution Steering의 핵심 아이디어 — 직관 + 수식 + 메커니즘
IDS(In-Distribution Steering)의 핵심은 단 하나의 질문에서 시작합니다:
“어떤 activation을 steering할 때, 얼마나 더하면 ‘너무 많이’ 더한 것이 될까?”
기존 steering(CAA, MERA)은 이 질문에 답하지 못했습니다.
- CAA: α = 1 또는 1.5 → 매우 거친 fixed strength
- MERA: probe error로 α를 정하지만 activation distribution을 고려하지 않아 over-steering 빈번
IDS는 이 문제를 activation distribution 관점에서 근본적으로 해결합니다.
✨ 핵심 철학: Steering은 Activation Distribution 내에 유지되어야 한다
LLM의 activation은 정규 분포와 비슷한 고차원 manifold 위에 존재합니다.
따라서:
- activation이 distribution 내부에 있으면 → “정상적·일관적·plausible text”
- activation이 distribution 밖으로 밀려나면 → “collapse, repetition, incoherent output”
즉, steering의 본질은 다음 제약을 만족해야 합니다:
여기서
- : layer l, token position p의 원래 activation
- : steering vector (positive-behavior direction)
- : steering strength (찾아야 할 값)
IDS는 바로 이 조건을 수학적으로 계산 가능한 제약 최적화 문제로 정식화합니다.
🧠 단계별 핵심 아이디어
IDS는 다음 3가지 아이디어로 구성됩니다:
① Activation distribution을 먼저 모델링한다 (PCA + Mahalanobis)
Positive class의 activation을 모아서 다음을 추정합니다:
- 평균 μ⁺
- 공분산 Σ⁺
- PCA embedding C
- Mahalanobis 거리 기반 threshold ε (95% percentile)
즉, IDS는 다음 공간을 구축합니다:
이 공간은 **“positive-behavior activation manifold”**라고 할 수 있습니다.
② Steering 후 activation이 distribution 안에 유지되도록 최대 α를 찾는다
목표:
“가능한 한 많이 steering하되, distribution을 절대 벗어나지 않도록 하라.”
이를 식으로 쓰면:
즉 Quadratic inequality constraint problem.
논문은 이를 **닫힌형(closed-form)**으로 해결:
이 식은 다음을 의미합니다:
- steering 방향이 positive distribution 내부로 향하면 → 가능한 가장 큰 α 적용
- 어떤 α에서도 distribution을 통과하지 못하면 → distribution에 가장 가까운 점까지 이동
결국 IDS는:
**“Activation collapse 를 절대 허용하지 않는 최대 steering”**을 수행합니다.
③ Behavior encoding이 강한 layer에서만 steering 적용
각 layer의 steering vector vₗ를 classifier로 삼아 F1-score를 봅니다.
- F1 ≥ 0.7 → 그 layer는 behavior 정보를 강하게 표현함
- F1 < 0.7 → steering 효과 없음 → 개입하지 않음
따라서 IDS는:
- 의미 있는 layer에만 개입
- 불필요한 layer steering으로 인한 noise 제거
- steering factor 누적 위험 감소
🎯 왜 이 아이디어가 강력한가? (문제 해결 관점)
문제 1 — Fixed α는 다양한 입력에 대응하지 못한다
예:
- 어떤 입력은 이미 긍정적 → 약한 steering 필요
- 어떤 입력은 부정적 → 강한 steering 필요
- 어떤 입력은 border-line → 미세 조절 필요
IDS는 입력 activation이 distribution에서 얼마나 떨어져 있는지 보고:
- 가까우면 α 작게
- 멀면 α 크게
- 단, 항상 distribution 내부까지로만 이동
→ 입력별 adaptive steering.
문제 2 — Open-ended generation에서 collapse 발생
기존 기법(MERA, 특히 CAA)은 token마다 steering이 누적됩니다.
여기서 α가 조금이라도 크면:
- layer depth 증가
- token step 증가
→ steering 효과가 누적되어 activation이 manifold 밖으로 튕겨나감 → collapse
IDS는 항상:
즉 절대로 distribution 밖으로 못 나가게 설정.
결과적으로:
- 반복, incoherence, 공격적 output 등이 사라짐
- 모델의 자연스러운 표현력 유지
- 안전한 steering
문제 3 — 어떤 layer에 steering을 넣어야 하는가?
기존 steering 연구의 오래된 문제:
- 어느 layer에 넣어야 제일 효과적인가?
- 모든 layer에 넣으면 collapse 위험 증가
IDS는 layer 자체를 classifier로 삼아 behavior encoding strength를 정량적으로 평가(F1).
이것은:
- Behavior-specific layer localization
- Efficient, effective steering
- Over-steering layer 제거
📌 핵심 아이디어를 한 문장으로 요약하면:
“Activation을 positive-behavior distribution 내부에 유지시키는 최대 steering”을 수행하는 adaptive, stable, distribution-aware activation steering 방법.
📌 연구자 관점 핵심 인사이트 3개
- Activation steering을 geometric constraint optimization 문제로 재정의했다.
(기존 방법은 scalar α 튜닝에 불과) - Distribution geometry(PCA + Mahalanobis)를 활용해 steering 안정성을 정량화했다.
→ open-ended generation collapse를 이론적으로 해결 - Layer selection을 자동화하여 steering을 behavior-relevant layer로 제한했다.
→ 효과 증가 + 안정성 증가
논문에 나온 IDS의 closed-form (\alpha)를 처음부터 끝까지 한 번 직접 유도해보겠습니다.
(구조는 논문 Appendix 8.3의 흐름을 따르되, 중간 단계를 더 촘촘히 채워서 설명합니다. )
0. 문제 설정 다시 쓰기
IDS의 목표는, layer , token 위치 에서의 activation 에 대해
로 steering할 때, **“가능한 한 큰 ”**를 쓰되, target(positive) 분포 안에 머물게 하는 것입니다.
즉, 최적화 문제:
여기서
- : Mahalanobis 거리 (혹은 그 변형)
- : target 분포에 대해 “in-distribution”이라고 보는 threshold (예: 95% 퍼센타일)
논문에서는 이걸 PCA 공간 + Mahalanobis distance로 쓰지만, 이해를 위해 먼저 Euclidean 거리에서 시작했다가, 이후 Mahalanobis/PCA 케이스로 확장합니다.
1. Euclidean 거리에서의 closed-form 유도
1.1. 제약식 정의
우선 target(positive) 분포의 평균을 라고 하고,
activation을 , steering vector를 라고 두겠습니다.
“분포 안”이라는 것은 다음 형태의 제약으로 표현할 수 있습니다:
최적화 문제는:
즉, 에 대해 2차 부등식 하나를 푸는 문제입니다.
1.2. 2차식 전개
우변의 2차식을 전개합니다.
우선
그러므로
내적을 이용해 전개하면:
따라서 제약식
는 다음과 같이 바뀝니다:
이를 표준적인 2차식 형태
로 쓰면,
가 됩니다.
1.3. 2차 부등식의 해석
에 대해
를 만족하는 구간을 찾아야 합니다.
여기서 (a = |v|^2 > 0)이므로, 포물선은 위로 열린 형태입니다.
- 판별식 를 계산합니다.
- 이면, 두 실근 존재.
- 이때, 부등식 의 해는
- 이면, 한 점 에서만 0; 그 점이 경계.
- 이면, 포물선이 전체에서 0보다 크거나 작음.
여기서는 (a > 0)이므로, 항상 (>0)인 경우이고, 엄밀한 의미의 “완전히 inside”해는 없음.
논문에서 원하는 것은 **“분포를 벗어나지 않는 최대 ”**이므로:
- 일 때:
feasible interval이 → 그 중 가장 큰 값 선택 - 일 때:
엄밀히 말하면 를 만족하는 가 없음 →
논문에서는 **“분포에 가장 가까운 점”**이 되도록, 포물선의 최소점 를 사용.
따라서 최종적으로:
이게 논문에서 말하는 Euclidean case의 closed-form입니다.
2. Mahalanobis + PCA 공간으로 확장
이제 실제 IDS는 단순 Euclidean가 아니라
- PCA로 차원 축소한 후
- 그 공간에서 Mahalanobis distance를 사용
합니다.
핵심은:
PCA + Mahalanobis 변환을 모두 합치면, 여전히 “적당한 선형 변환 후의 Euclidean 거리” 문제로 볼 수 있다.
그래서 위에서 했던 Euclidean derivation을 그대로 재사용할 수 있습니다.
2.1. Mahalanobis distance 복습
target distribution 의 평균 , 공분산 가 있을 때,
Mahalanobis distance는
(Cholesky 분해)로 두면,
즉, 선형 변환 후의 Euclidean 거리입니다.
2.2. PCA까지 포함한 경우의 선형 변환
논문에서는 먼저 PCA로 차원 축소를 합니다.
PCA 변환을 (principal components)라 하면,
target positive 분포의 평균도 PCA 공간에서
로 표현할 수 있습니다.
그리고 PCA 공간에서의 공분산 에 대해 Cholesky를 취하면:
Mahalanobis distance in PCA space는:
2.3. Steering 후의 Mahalanobis distance 표현
steering 후 activation: .
PCA 공간으로 보내면:
이를 다시 Mahalanobis distance에서 사용:
선형 변환을
라고 두면, (논문에 이 notation이 등장)
이고,
따라서,
이걸 다시 Euclidean distance 문제로 보면,
선형 변환을
라고 뒀을 때,
이제 완전히 1단계의 Euclidean case와 동일한 형태입니다.
2.4. 다시 2차식으로 쓰고 계수 정리
제약식은
이걸 전개하면:
따라서
형태에서,
가 됩니다. 논문에서 식 (5)에 대응하는 가 바로 이 부분입니다.
2.5. 최종 closed-form
이제 1단계와 완전히 동일한 논리로, 에 대한 2차 부등식을 풀면 됩니다.
판별식 에 따라:
이게 논문 본문 3.2 (그리고 Appendix 8.3)에서 제시한 IDS의 closed-form steering factor입니다.
정리하면:
PCA + Mahalanobis까지 포함된 IDS의 최적화 문제도,
“적당한 선형 변환 후 Euclidean 거리 제약을 가진 2차 부등식”으로 환원되고,
그 결과 표준적인 2차 방정식 해법으로 α closed-form이 나온다.
3. 직관적 요약
- 원래 목표:
“가 positive 분포의 타원(ellipsoid) 내부에 있도록 하는 최대 ” - 타원은 선형변환 후의 원과 같음 → Mahalanobis + PCA는 선형변환에 불과
- 따라서 “선형변환 후 중심에서의 유클리드 거리” 문제로 바꾸면,
문제는 단순히
이 되고, - 이는 **하나의 스칼라 변수 **에 대해
인 영역을 찾는 문제 → 표준 2차 부등식 - 최대한 크게 쓰려면, feasible interval의 가장 큰 (= 큰 root) 선택.
답글 남기기