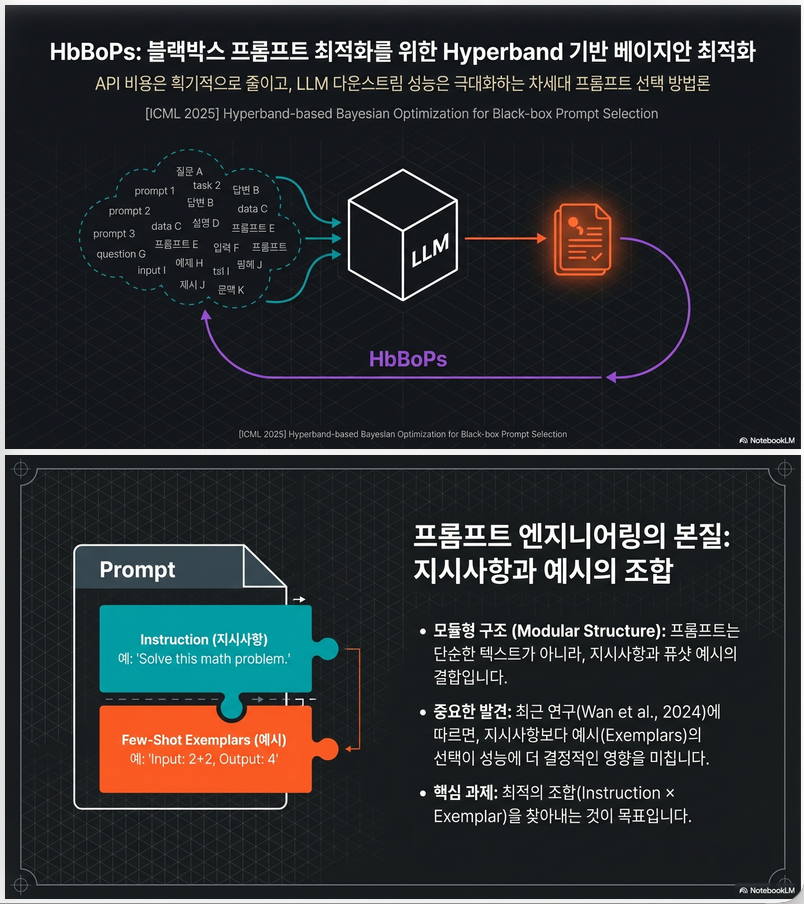


1. 문제 설정: Static Black-box Prompt Selection
목표
- LLM이 black-box API로만 접근 가능
- 미리 생성된 후보 prompt 집합
- I: instruction 집합
- E: few-shot exemplar 집합
- validation set에서 가장 낮은 error를 보이는 단일 prompt 하나를 찾는 문제
수식적으로는:
하지만 실제로는 validation set 평균으로 근사:
여기서 핵심 제약은:
- gradient 접근 불가
- LLM 내부 확률/로짓 접근 불가
- validation 전체 평가 비용이 매우 큼
즉,
샘플 효율(sample-efficient) + 쿼리 효율(query-efficient)
이 동시에 필요함.
2. 기존 방법들의 한계
논문에서 지적한 문제점:
| 방법 | 한계 |
|---|---|
| EASE | exemplar selection 위주, 구조 정보 활용 X |
| TRIPLE-SH/GSE | multi-fidelity지만 surrogate 기반 탐색 X |
| MIPROv2 | surrogate는 쓰지만 semantic 정보 활용 X |
| Vanilla BO | full-fidelity → validation 전체 사용 |
즉,
surrogate 기반 sample 효율
multi-fidelity 기반 query 효율
를 동시에 달성한 방법은 없었음.
3. HbBoPs 핵심 아이디어
HbBoPs =
4. Method 구성
4.1 Gaussian Process Surrogate
Prompt를 embedding 후 GP surrogate 학습:
Posterior:
Expected Improvement(EI)로 다음 prompt 선택:
4.2 문제: 고차원 embedding
BERT embedding = 768차원
→ GP는 고차원에서 불안정
PCA 같은 비지도 축소는
downstream performance와 정렬되지 않음
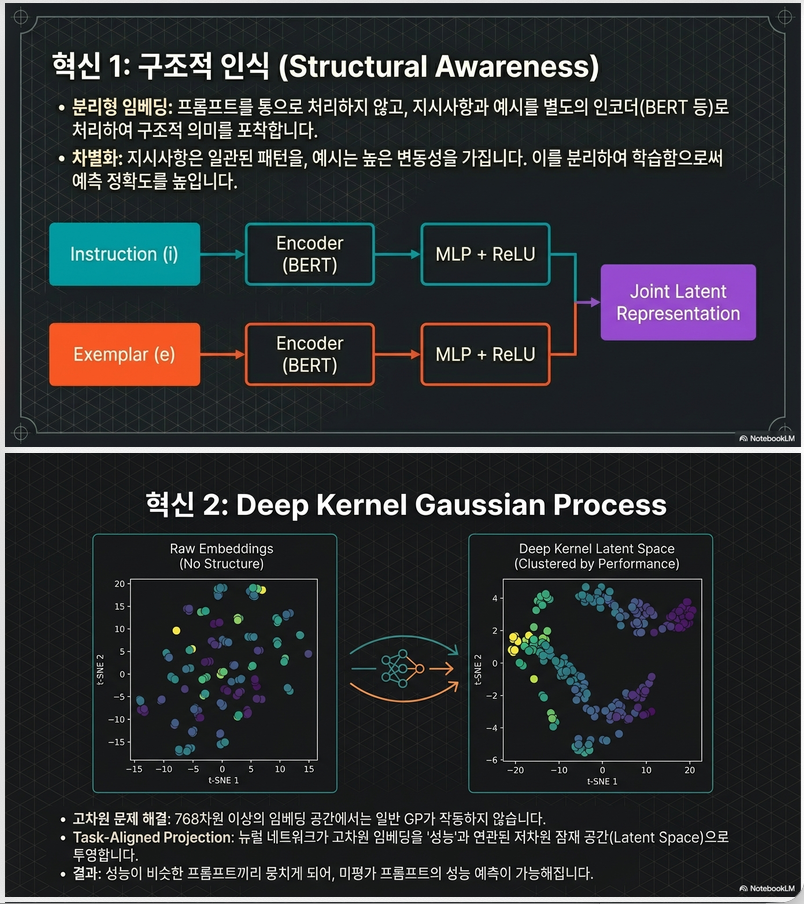
4.3 해결책: Structural-aware Deep Kernel GP
핵심 설계:
- instruction과 exemplar를 분리 embedding
- 각각 FFN 통과
- concat 후 joint latent space 학습
구조
Instruction:
Lin(d,64) → ReLU → Lin(64,32) → ReLUExemplar:
Lin(d,64) → ReLU → Lin(64,32) → ReLUConcat 후:
Lin(64,32) → ReLU → Lin(32,10)최종 10차원 latent space에서 GP 수행
장점
- 구조 정보 반영
- low-dimensional task-aligned representation 학습
- non-stationary modeling 가능
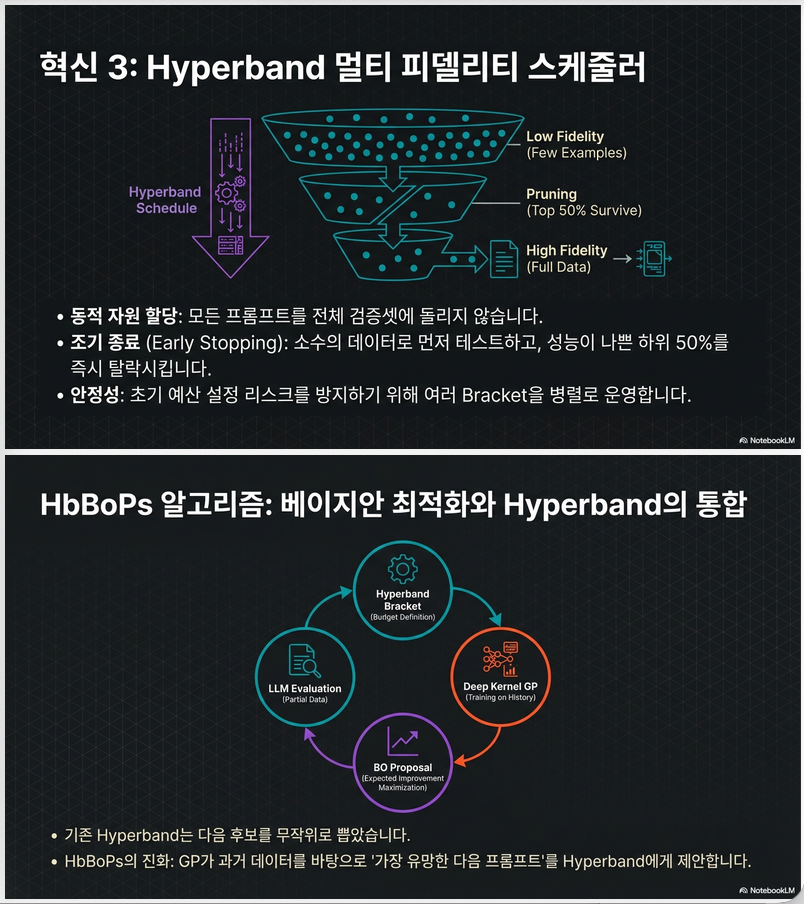
4.4 Query 효율: Hyperband
validation 전체 평가 대신:
- 처음엔 소수 validation instance로 평가
- 성능 나쁜 prompt early stop
- 점점 더 많은 instance로 확장
Successive Halving의 한계:
- 초기 예산 설정에 민감
→ Hyperband는 여러 bracket 실행하여 robust하게 탐색
4.5 HbBoPs 통합
기존 HB:
- prompt 랜덤 선택
HbBoPs:
- HB 내부 proposal을 BO 기반 EI로 교체
즉:
Hyperband scheduling
+
BO-based candidate selection→ sample 효율 + query 효율 동시 확보
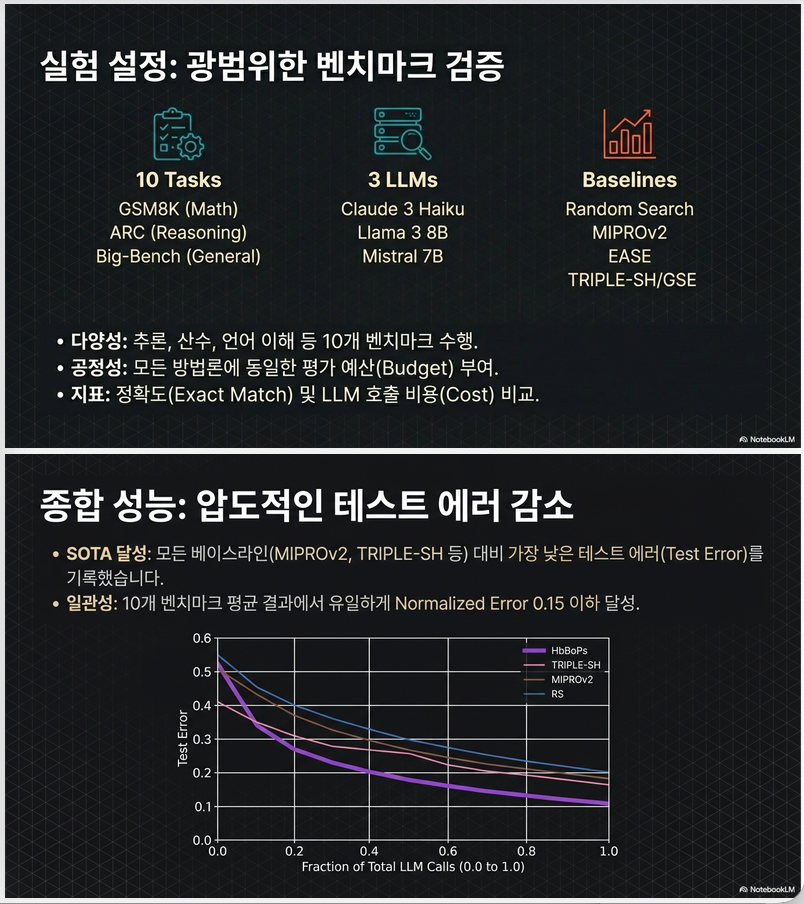
5. 실험 설정
Search space
- 5 instructions
- 50 exemplars (5-shot × permutation)
총 250 prompts
LLM
- Claude 3 Haiku
- LLAMA3 8B Instruct
- Mistral 7B Instruct
예산
- 25 full-fidelity 평가에 해당하는 LLM call budget
6. 결과 분석
Overall 성능
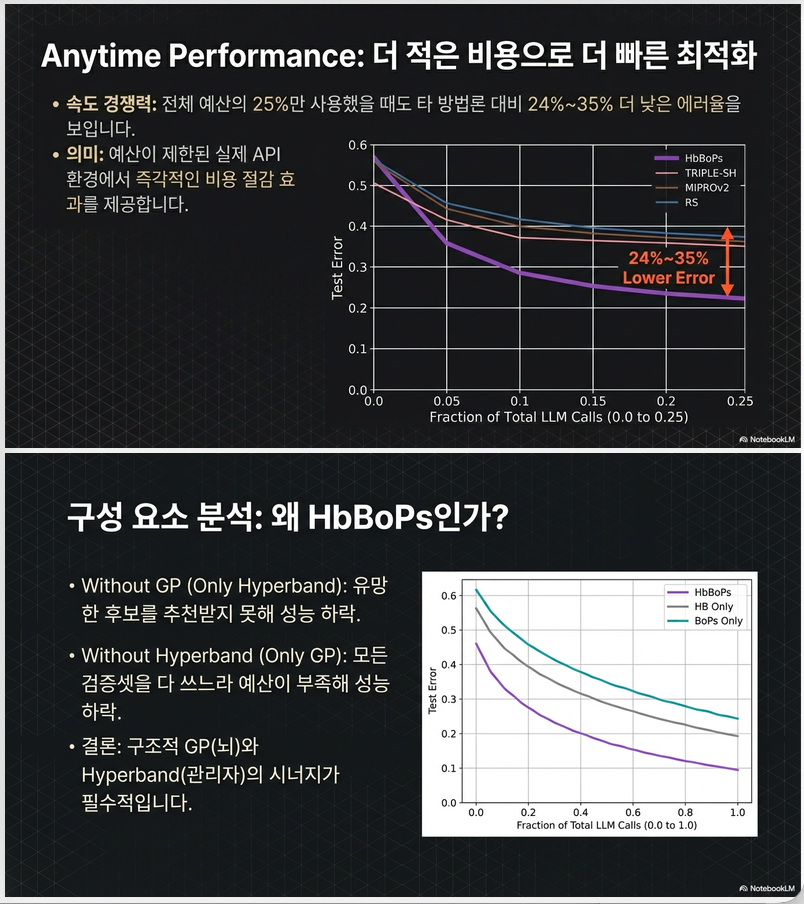
논문 Figure 1 (p.7)에서:
- validation/test normalized error 모두에서
- HbBoPs가 전체 구간에서 최저
특히 budget 0.25 시:
- HDBO 대비 ~35% 개선
- TRIPLE-SH 대비 ~24% 개선
Full Budget 결과
평균 normalized test error:
| 방법 | Error |
|---|---|
| RS | 0.214 |
| HDBO | 0.185 |
| TRIPLE-SH | 0.159 |
| HbBoPs | 0.150 |
Ablation 결과 (Figure 2, p.8)
기여도:
- DK-GP 사용 → vanilla BO 대비 큰 개선
- Structural-aware 추가 → 추가 개선
- Hyperband 추가 → orthogonal boost
- BO proposal + HB 결합 → 최종 최고 성능
Vanilla BO 대비:
- 0.5 budget에서 66% 개선
- full budget에서 67% 개선
Encoder Robustness
BERT / MPNet / DistillRoBERTa 모두 유사 성능
→ deep kernel이 semantic alignment 학습
7. 논문의 핵심 기여 요약
- Structural-aware deep kernel GP 설계
- BO + Hyperband 통합
- static black-box prompt selection에서 sample + query 효율 동시 달성
- 10 benchmark × 3 LLM에서 SOTA 달성
8. 한계
논문에서 언급:
- embedding 계산 비용 존재
- prompt 구조를 instruction/exemplar로 한정
- multi-objective 고려 안함
10. 한 줄 요약
HbBoPs는
구조 인식 Deep Kernel GP + Hyperband 기반 multi-fidelity scheduling을 결합하여
black-box LLM 환경에서 가장 효율적으로 prompt를 선택하는 방법이다.
다음은 논문의 **방법론(Method)**을 수식과 알고리즘 관점에서 정리한 내용입니다.
1. 문제 재정의
Prompt 집합:
- I: instruction 후보
- E: few-shot exemplar 후보
LLM은 black-box:
Validation 기반 목적함수:
관측은 noise 포함:
2. 전체 알고리즘 구조
HbBoPs =
핵심은
- sample efficiency → GP surrogate + EI
- query efficiency → Hyperband
3. Surrogate Model: Gaussian Process
3.1 Prompt embedding
각 prompt를 embedding:
하지만 vanilla GP는 high-dimensional 문제 발생
(예: BERT 768-dim)
4. Structural-aware Deep Kernel GP
4.1 Motivation
Prompt는 단일 text block이 아니라:
- instruction
- exemplar
두 구조적 구성요소를 가짐.
이를 분리 처리.
4.2 Architecture
Step 1: Separate embedding
Step 2: 각각 FFN 통과
instruction과 exemplar에 각각 적용.
Step 3: Concatenate
Step 4: Joint latent mapping
최종 latent dimension = 10
4.3 Deep Kernel
GP kernel:
ARD Matérn 5/2 kernel 사용.
4.4 Training
log marginal likelihood 최적화:
여기서:
- kernel parameter
- : neural feature extractor parameter
AdamW로 online 학습.
5. Bayesian Optimization Proposal
5.1 Posterior prediction
5.2 Expected Improvement
현재 best validation error 에 대해:
Closed form:
Finite candidate set이므로
모든 에 대해 EI 계산 후 argmax.
6. Query Efficiency: Hyperband
6.1 문제
Full fidelity = 모든 validation instance 사용
→ LLM call 비용 매우 큼
6.2 Multi-fidelity 정의
Fidelity = 사용한 validation instance 개수
- low fidelity → noisy하지만 저비용
- high fidelity → 정확하지만 고비용
6.3 Hyperband 구조
주요 변수:
- 최소 validation 개수
- : halving rate (2)
각 bracket에서:
- 여러 prompt 소수 instance로 평가
- 상위 1/η만 남김
- validation 개수 증가
- 반복
7. HbBoPs 통합 구조
기존 Hyperband:
p = random promptHbBoPs:
p = argmax EI(p | GP trained on current fidelity data)중요한 설계:
- GP는 highest fidelity 중 관측 충분한 level에서만 학습
- full validation 평가까지 간 prompt 중 best 반환
8. Algorithm Flow
Initialization
- empty design set D
For each bracket s:
- 반복:
- BO로 candidate 선택
- low fidelity로 평가
- D 업데이트
- Successive Halving
- 다음 fidelity level
Output
전체 validation set에서 lowest error prompt
9. 핵심 설계 포인트 요약
| 구성요소 | 역할 |
|---|---|
| Structural-aware DK-GP | sample-efficient exploration |
| EI acquisition | exploration-exploitation 균형 |
| Hyperband | query-efficient evaluation |
| BO proposal inside HB | random sampling 제거 |
10. 이 방법의 본질
HbBoPs는 사실상:
(BO + Hyperband, Falkner et al. 2018)의
prompt selection 특화 버전이라고 볼 수 있음.
하지만 중요한 차이점:
- 구조-aware representation 학습
- black-box LLM 환경에 맞춘 fidelity 정의
- joint instruction-exemplar modeling
11. 연구적 의미
이 방법론은 다음과 연결됩니다:
- Latent BO (GASP)
- Deep Kernel BO
- Surrogate-guided adversarial suffix search
- Multi-fidelity adversarial optimization
이제 **HbBoPs의 4.4 Training (Log Marginal Likelihood 최적화)**를
수식 수준에서 정확히 정리하겠습니다.
1. 학습 대상
Structural-aware Deep Kernel GP의 학습 파라미터는 두 종류입니다.
(1) Kernel parameter
- Matérn 5/2 ARD lengthscale
- output scale
- noise variance
(2) Deep feature extractor parameter
- instruction FFN
- exemplar FFN
- joint FFN
즉, 최적화 대상:
2. Deep Kernel GP 정의
Feature extractor:
Deep kernel:
3. GP Likelihood
관측값:
Covariance matrix:
where
4. Log Marginal Likelihood (LML)
Gaussian Process의 marginal likelihood는:
상수항 제외하면 논문 식 (6):
이를 최대화.
5. 각 항의 의미
(1) Data-fit term
- GP 예측이 실제 관측을 얼마나 잘 설명하는가
- quadratic form → smoothness 제약
(2) Complexity penalty
- 모델 complexity 제어
- Occam’s razor 역할
6. Gradient 계산 구조
LML의 gradient는 잘 알려진 closed-form:
따라서
Deep kernel이므로 chain rule 적용:
즉:
이게 Deep Kernel Learning의 핵심.
7. Matérn 5/2 Kernel 형태
ARD Matérn 5/2:
여기서
- = lengthscale (ARD)
- = output variance
8. 왜 Deep Kernel이 중요한가?
Vanilla GP:
k(enc(p), enc(p’))
→ 768차원 직접 사용
→ lengthscale 학습 불안정
→ curse of dimensionality
Deep kernel:
→ 10차원 latent
→ task-aligned representation
→ non-stationarity modeling 가능
9. Optimization 방식
논문 설정:
- Optimizer: AdamW
- lr = 0.01
- max epoch = 3000
- early stopping (patience 10)
중요:
- GP는 selection 과정 중 online 학습
- pre-trained surrogate 아님
10. Multi-Fidelity 상황에서 학습 전략
HbBoPs의 독특한 설계:
GP는
“현재 fidelity level 중 충분한 관측이 있는 최고 fidelity level”
데이터만 사용
이유:
- low-fidelity noise 큼
- high-fidelity estimate가 더 신뢰성 있음
이는 일종의 fidelity-aware surrogate filtering 전략.
11. 계산 복잡도
GP inversion:
하지만
- prompt 수 250
- high-fidelity observation은 적음
- manageable
또한 GPytorch 기반 GPU 가속 사용 가능.
12. 이 Training 단계의 핵심 의미
이 단계는 단순 regression이 아니라:
즉,
- 단순 similarity modeling이 아니라
- “validation error에 맞춰 embedding space를 비선형 재구성”
이는 거의 representation learning에 가깝습니다.
13. 요약
4.4 Training은:
을 통해
- kernel hyperparameter
- deep feature extractor
를 동시에 학습하여
prompt → validation error mapping을 probabilistic하게 모델링하는 단계
입니다.
이제 HbBoPs의 Query Efficiency 구성요소인 Hyperband를
이론 → 알고리즘 → HbBoPs 통합 관점까지 체계적으로 정리하겠습니다.
1. 왜 Query Efficiency가 필요한가?
Black-box prompt selection에서 비용은:
Full-fidelity 방식:
- 하나의 prompt 평가 시
- 모든 validation instance 사용
즉 비용이:
LLM API 호출 비용이 크기 때문에
이를 줄이는 것이 핵심.
2. Multi-Fidelity 아이디어
핵심 발상:
validation instance 수를 fidelity로 본다.
- low fidelity → 적은 validation instance
- high fidelity → 전체 validation instance
즉,
where
3. Successive Halving (SH)
Hyperband의 기본 구성요소.
3.1 SH 알고리즘
- 모든 candidate를 small budget b로 평가
- 상위 1/η만 유지
- budget을 η배 증가
- 반복
3.2 Budget Allocation
총 예산 B에서:
단점:
- 초기 budget 설정에 매우 민감
- 너무 작으면 좋은 prompt가 noise로 탈락
- 너무 크면 exploration 부족
4. Hyperband의 핵심 아이디어
Hyperband는:
여러 SH bracket을 실행하여
“budget vs. number of configurations” trade-off를 자동 조절
5. Hyperband 수식 구조
논문 Algorithm 1 기반.
5.1 정의
5.2 각 bracket s에서
초기 candidate 수:
초기 fidelity:
5.3 Stage i에서
즉:
- candidate 수 감소
- fidelity 증가
6. 직관적 해석
Hyperband는 다음을 동시에 시도:
| bracket | 특징 |
|---|---|
| s = 0 | 적은 candidate, 큰 budget |
| s = smax | 많은 candidate, 작은 budget |
즉,
- exploration-heavy bracket
- exploitation-heavy bracket
을 동시에 운영.
7. HbBoPs에서의 Hyperband 설계 특징
논문에서 두 가지 중요한 설계:
(1) Fidelity 확장 시 validation subset 포함 관계 유지
즉,
이는 noise 감소 및 안정성 증가 목적.
(2) 최종 반환
전체 validation set에서 평가된 prompt 중 최저 error 반환.
8. Query Efficiency 분석
Full-fidelity 방식:
Hyperband:
대략:
실제 실험에서는:
- 동일 full-budget 대비
- 훨씬 적은 LLM call로 최적 prompt 발견
9. Hyperband + BO 통합 전/후 차이
Vanilla HB:
p = random prompt→ sample inefficiency 존재
HbBoPs:
p = argmax EI(p | GP)→ evaluation 자체도 surrogate-guided
즉,
10. Noise 관점 분석
Low-fidelity 평가:
따라서:
- 초기 stage는 high variance
- 후반 stage는 low variance
Hyperband는 이를 점진적으로 조절.
11. 이 구조의 이론적 의미
HbBoPs는 사실상:
의 prompt selection 특화 구현.
하지만 차이점:
- fidelity 정의 = validation instance 수
- black-box LLM cost 구조 반영
12. 장점 요약
Hyperband가 제공하는 것:
- noisy early pruning
- adaptive resource allocation
- robust exploration/exploitation balance
- query cost 대폭 감소
14. 한 줄 요약
이고,
HbBoPs에서는 이를 BO proposal과 결합하여
sample + query 효율을 동시에 달성합니다.
답글 남기기