아래는 논문 “EXPERTSTEER: Intervening in LLMs through Expert Knowledge”(arXiv:2505.12313) 의 전체 구조, 핵심 아이디어, 방법론, 수식적 의미, 실험 내용 및 분석을 체계적으로 정리한 설명입니다.
⭐ 논문 핵심 기여 요약
EXPERTSTEER는 외부 Expert 모델이 가진 전문 지식을 임의의 Target LLM에 activation steering으로 전달하는 최초의 일반적 방법입니다.
기존 activation steering은 항상 자기 모델이 생성한 steering vector만 사용했기 때문에:
- 모델 자체의 한계 내에서만 steering 가능
- 더 큰 전문가 모델의 지식을 가져오는 것이 불가능
- cross-model steering이 되지 않음
이 논문은 Auto-encoder 기반 차원 정렬 → Mutual Information 기반 layer mapping → RFM(Recursive Feature Machine) 기반 steering vector 추출 → Inference-time activation intervention이라는 4단계 파이프라인을 제안하여 문제를 해결합니다.
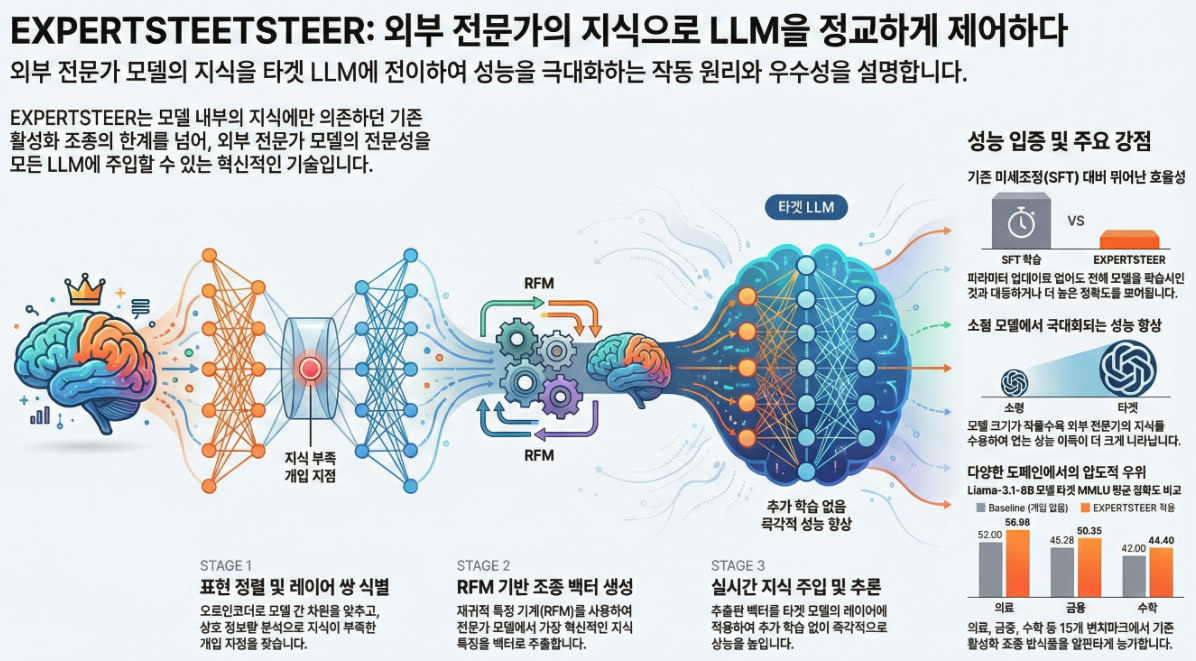
⭐ Figure 1 기반 전체 Pipeline 요약 (p.3)
논문은 EXPERTSTEER를 다음 4단계로 설명합니다.
1) Representation Alignment (Auto-Encoder)
- Expert 모델의 hidden size:
- Target 모델의 hidden size:
→ 서로 다른 차원을 encoder 로 변환
→ decoder 로 복원 - Loss:
기능: Expert 모델의 표현을 target LLM이 해석할 수 있는 공간으로 투영(projection).
2) Intervention Layer Pairing (Mutual Information 분석)
각 Expert layer , Target layer 에 대해 MI 계산:
MI가 낮을수록 두 layer의 표현 차이가 크므로
→ 지식 개입이 가장 필요한 지점
따라서 MI가 가장 낮은 P개의 (i,j) layer pair를 선택하여 intervention 수행.
OBS(Optimal Brain Surgeon) 원칙:
신경망 개입은 최소한의 위치에서 선택적으로 이뤄져야 한다(p.4).
3) Steering Vector Generation (RFMs: Recursive Feature Machines)
RFM은 다음 2개 구성요소로 이루어짐:
① Kernel Ridge Regression (KRR)
Expert hidden states (H_i) 를 medical/financial 등의 positive vs negative로 구분하는 binary classifier 학습.
② AGOP (Average Gradient Outer Product)
gradient outer product를 평균내어 feature importance matrix 형성:
여기서 는 iteration t의 KRR predictor.
Steering vector
가장 큰 eigenvalue에 대응하는 eigenvector 을 steering vector로 사용.
→ Expert 모델 representation이 가진 가장 강력한 domain-specific 방향(의학/수학/금융)을 추출.
4) Expertise Intervention (Inference-time Activation Addition)
선택된 (i,j) layer pair에서:
- Expert layer에서 구한 steering vector
- Auto-encoder encoder 로 Target 차원에 변환
- Target model activation 수정:
이 값이 다음 layer로 전파되며 Target model이 Expert model의 지식을 반영하도록 steering됨.
파라미터 업데이트 없음, 순수 inference-time 개입.
⭐ Why This Works? 핵심 논리
- Representation Alignment: 서로 다른 hidden size로 인해 발생하는 구조적 불일치 제거
- Low-MI layer pairing: Target이 Expert 지식을 충분히 갖고 있지 않은 layer에 집중 개입
- RFM 기반 Feature Extraction:
PCA/Mean Difference보다 훨씬 강력한 비선형 feature importance 학습
(논문 ablation에서도 RFM이 압도적으로 우수한 결과) - Inference-time Activation Steering:
비용이 거의 0에 수렴하며 파라미터 업데이트를 하지 않음 → catastrophic forgetting 없음
⭐ 실험 결과 요약 (p.6–7 Table 2)
세 domain(Medical, Financial, Math)에서 3개 target 모델(Llama-3.1 8B, Qwen2.5 7B, Gemma 2B)에 대해:
EXPERTSTEER의 특징적 성과:
- Llama-3.1-8B: 의료 분야에서 baseline 대비 +4.98 점 향상
- Qwen2.5-7B: 금융 분야에서 baseline 대비 +5.34 점 향상
- Gemma-2B: 매우 작은 모델에도 고정적 개선
특히 cross-family(예: Expert=Qwen → Target=Llama)에서도 잘 작동하는 것이 핵심.
→ 기존 activation steering은 동일 모델 내에서만 작동했음을 극복한 성과.
⭐ General-domain Transfer (Table 3, p.7)
Expert model = Qwen2.5-14B
Target = Llama-3.1 / Qwen2.5 / Gemma
- COPA / NLI / ARC-C / Humanities 등 다양한 NLU task 성능 개선
- Safety domain에서도 improvement
대형 Expert 모델의 능력을 소형 Target이 흡수하는 cross-model general knowledge transfer 성공.
⭐ Linguistic Expertise Transfer (Chinese, Table 4, p.7)
Expert: Llama3.1-8B-Chinese-Chat
Target: Llama-3.1-8B, Qwen2.5-7B
XCOPA-zh, XNLI-zh, StoryCloze-zh, Flores에 대해 성능 증가.
→ EXPERTSTEER는 언어적 지식도 전이 가능.
⭐ Ablation Study 핵심 요약 (p.8)
(1) Feature Extraction: RFM > PCA > MD
표 5에서 RFM이 다른 방법 대비 압도적.
(2) Expert Selection 중요
Figure 2에서
- Expert를 generic model로 바꾸면 성능 저하
- 진짜 전문 모델을 expert로 둘 때 가장 큰 gain
(3) RFMs → AE 순서(AE→RFMs 아님)
Figure 3:
RFMs-AE가 AE-RFMs 대비 훨씬 우수
→ feature extraction은 반드시 원본 hidden space에서 해야 함.
⭐ Efficiency (p.9)
- 2000개의 샘플로 충분(약 17분 학습)
- Inference는 단순한 벡터 더하기로 오버헤드 거의 없음
- 작은 모델일수록 gain이 더 큼(Figure 5)
⭐ 논문의 Overall Contribution (요약)
- Activation Steering을 Expert 모델 기반 Cross-model Steering으로 확장
- Auto-encoder 기반 Representation Alignment 제안
- MI 기반 Layer Pairing 제안
- RFM 기반 steering vector 추출 도입
- Medical / Finance / Math / General / Chinese 등 광범위 domain에서 강력한 성능 개선
아래는 논문 EXPERTSTEER의 방법론(Methods) 전체를 논문 구조 그대로, 하지만 훨씬 이해하기 쉽게, 수식·직관·절차 중심으로 재구성한 설명입니다.
🧩 EXPERTSTEER 방법론(Methodology) — 전체 구조 요약
논문은 EXPERTSTEER를 4단계 파이프라인으로 구성합니다:
- Representation Alignment
(Expert hidden → Target hidden 공간 정렬) - Intervention Layer Pairing
(어떤 Expert layer와 Target layer를 연결할지 MI로 계산) - Steering Vector Generation (RFMs)
(Expert hidden states에서 domain-specific vector 추출) - Expertise Intervention
(Target LLM의 forward pass 중 hidden activation에 steering vector 삽입)
그림 기준: Figure 1 (p.3).
1️⃣ Representation Alignment (표현 공간 정렬)
(p.3 Section 3.1)
🔍 문제
- Expert LLM과 Target LLM은 hidden dimension이 다름
- 예: Expert 4096-d, Target 3072-d
- 그대로는 Expert의 steering vector를 Target 모델에 넣을 수 없음.
🛠 해결책: Layer-wise Auto-Encoder
각 Expert layer (i) 에 대해 독립적인 Auto-encoder를 학습:
Encoder
Decoder
둘 다 Affine Linear (1-layer) 로 구성.
Training objective (Reconstruction loss)
✔ 역할: Expert hidden → Target hidden 크기로 투영(projection)
✔ 장점: Target 모델이 이해 가능한 feature space로 변환됨
✔ Autoencoder는 layer-wise로 따로 학습 (독립적)
→ 이후 단계에서 Expert steering vector 또는 Expert hidden states를 Target 공간으로 mapping할 수 있게 됨.
2️⃣ Intervention Layer Pairing
(p.4 Section 3.2)
🔍 목표
Expert layer 와 Target layer 중
지식을 개입하기 가장 적합한 layer pair (i, j)를 찾아야 함.
🔍 관찰
Target 모델이 이미 Expert와 비슷한 표현을 가진 layer는 굳이 개입할 필요 없음.
→ 따라서, Expert와 Target 표현이 가장 다른 layer를 찾아 개입해야 효율적.
이를 위해 Mutual Information (MI) 사용.
🔢 Mutual Information 계산
여기서 MI는
해석
- MI가 낮다
→ Target layer j의 표현이 Expert layer i의 정보를 거의 반영하지 못함
→ 여기에 개입하면 지식 전달 효과가 큼 - MI가 높다
→ Target layer j가 이미 비슷한 representation을 갖고 있음
→ 굳이 intervention 필요 없음
⭐ Layer Pair 선택
즉, 지식 부족 구간을 자동으로 탐지해 “개입 지점”으로 선택.
3️⃣ Steering Vector Generation (RFM 기반 비선형 특징 추출)
(p.4–5 Section 3.3)
이 단계는 논문 방법론 중 가장 핵심적입니다.
🔍 목표
Expert 모델의 특정 domain(예: 의학/수학/금융)의 **전문적 방향성(feature direction)**을 추출하여 steering vector로 만들기.
🚀 사용 알고리즘: RFM (Recursive Feature Machines)
RFM은 다음 두 요소로 구성됨:
① KRR (Kernel Ridge Regression)
Expert hidden states (H_i) 에 대해
positive domain vs negative domain으로 분류하는 binary classifier.
- Positive 예: 의료 관련 문장
- Negative 예: 일반적 문장 or 의료 관련 X
Classifier를 학습하면서 domain을 구분하는 중요한 feature가 어디인지 파악.
② AGOP (Average Gradient Outer Product)
모든 sample의 gradient outer product를 평균하여 feature importance matrix를 생성:
이 행렬은 feature-space 내에서
domain을 가장 잘 구분하는 방향을 강조한 정규화된 공분산 행렬이라고 볼 수 있음.
🔁 Recursive update
RFM은 kernel 를 feature importance에 따라 업데이트하며
feature 방향성을 iterative하게 refine함.
Kernel:
즉, feature importance가 높은 차원은 더 민감하게 반응하도록 kernel metric을 조정.
⭐ 최종 steering vector: Largest-eigenvector
완성된 feature importance matrix 에 대해:
그중 가장 큰 eigenvalue 에 대응하는 eigenvector 을 steering vector로 사용:
🎯 의미
- domain-specific 정보가 가장 많이 존재하는 공간 방향
- Expert 모델의 전문성을 가장 잘 대표하는 “지식 축(knowledge axis)”
4️⃣ Expertise Intervention (Target 모델에 개입)
(p.5 Section 3.4)
Intervention은 Target 모델의 forward pass 중 선택된 layer pair (i,j)에서 수행.
🧮 수정된 Activation
Case 1: hidden size가 다를 경우
Case 2: hidden size 동일
여기서
- : steering 강도 조절 hyperparameter
- : 앞서 학습한 encoder
수정된 hidden state는 남은 transformer layer로 propagation됨.
5️⃣ Implementation Details 요약
(p.5 Section 3.5)
- Hyperparameters:
- : intervention layer pair 개수 (1~10)
- : steering scale (1~16)
- Auto-encoder training: 2000 samples
- MI layer selection: 500 samples
- RFM training: positive 2000 / negative 2000
- 전체 training은 비교적 가볍고 inference-time cost는 거의 없음.
📌 EXPERTSTEER 방법론의 직관적 이해 요약
| 단계 | 역할 | 핵심 개념 |
|---|---|---|
| 1. Representation Alignment | Expert → Target 공간 변환 | Auto-encoder |
| 2. Layer Pairing | 개입할 위치 선택 | Mutual Information |
| 3. Steering Vector Generation | 전문성 축(axis) 추출 | RFM(KRR + AGOP), eigenvector |
| 4. Expertise Intervention | Target 모델 behavior 조정 | Activation addition |
Steering Vector Generation (RFM) 부분만 완전히 파고들어서 정리해볼게요.
(Algorithm 1 및 Section 3.3 기준 설명입니다. )
0. 목표 다시 정리
ExpertSteer에서 이 단계의 목표는 **“Expert 모델의 특정 전문 영역(의학, 수학, 금융 등)을 가장 잘 구분하는 한 방향 벡터”**를 찾는 것입니다.
입력: Expert 모델의 어떤 layer 의 hidden states
라벨:
- : expert가 잘 아는 domain(예: medical question)
- : 그 domain이 아닌 일반 example
출력: 그 layer에서 domain을 가장 잘 구분하는 방향
→ 이게 곧 steering vector
이걸 위해 사용하는 게 Recursive Feature Machines (RFM) 입니다.
1. 데이터와 초기화
데이터
- Hidden states:
- Label vector:
초기 feature importance 행렬
처음에는 모든 차원 중요도를 똑같이 보고
이 이 계속 업데이트되면서 “어느 차원이 domain 구분에 중요한지”를 학습합니다.
2. 단계 1: Mahalanobis Laplace Kernel 정의
iteration 에서 kernel:
- : bandwidth hyperparameter
- 가 들어가 있어서, 지금까지 학습된 feature importance를 반영한 Mahalanobis 거리를 사용
→ 중요하다고 판단된 방향은 거리 계산에서 더 크게 반영되고, 덜 중요한 방향은 무시되는 형태.
3. 단계 2: Kernel Ridge Regression (KRR)
Kernel 행렬
KRR 해
논문에서는 ridge 항을 명시하지 않았지만, 형태는 다음과 같습니다 (정규화 생략):
예측 함수
임의의 hidden state 에 대한 예측:
- 직관적으로
- 가 클수록 “이 벡터는 domain-positive(예: 의료 질문)일 가능성이 크다”
- “z를 어느 방향으로 바꿨을 때 domain score가 가장 많이 변하는가”를 의미:
4. 단계 3: AGOP (Average Gradient Outer Product)
각 sample마다 gradient를 계산:
그리고 다음을 평균:
- 는 rank-1 matrix로,
- “이 sample에서 예측 값이 민감하게 변하는 방향”을 반영
- 평균을 내면, 모든 sample에 공통적으로 중요한 방향을 강조하는 공분산 유사 행렬이 됩니다.
직관적으로
- 는 “예측 함수 에 대해 가장 민감한 방향의 분산”
- Fisher Information Matrix와 비슷한 역할:
형태
이 과정을 회 반복하는 이유:
- 가 kernel 안에 들어가 있고
- 새 kernel에서 다시 KRR을 돌린 뒤, gradient를 다시 계산해
- “중요하다고 판정된 방향을 점점 더 강화하는 metric” 으로 수렴시키기 위함.
즉, **feature importance 행렬 **가 자체적으로 metric을 바꿔가며 self-reinforcing feature learning을 수행하는 구조입니다.
5. 단계 4: Eigen-decomposition → Steering Vector
최종 iteration 에서의 행렬 :
여기서
을 steering vector로 사용합니다.
왜 이 steering vector인가?
- 는 “gradient가 자주/크게 등장한 방향”을 누적한 행렬
- 가장 큰 eigenvalue 방향은,
- “ (domain score)를 가장 크게 변화시키는 평균적 방향”
- 즉, domain-positive와 domain-negative를 가장 확실히 구분하는 축
따라서 는 그 layer에서 “이 방향으로 activation을 밀면 Expert가 잘 아는 domain 쪽으로 간다” 라는 의미를 갖는 domain steering 방향이 됩니다.
6. 왜 RFM이 비선형·비지도/지도 결합 측면에서 강력한가?
1) 비선형성
- PCA, mean-difference(MD)는 모두 선형 통계량 기반:
- MD:
- PCA: Covariance eigenvector
- RFM:
- Kernel 를 통해 비선형 decision boundary를 학습
- AGOP는 그 비선형 classifier의 gradient 구조를 반영
- 따라서, 복잡한 manifold 상의 domain 구분 방향도 잡아낼 수 있음
2) 지도 정보 활용
- PCA는 label-free
- RFM은 binary label을 직접 사용해 “positive/negative를 잘 나누는 방향”을 찾음
→ Domain-specific steering에 더 직접적
3) Recursive metric learning
- 가 kernel 안에 들어가 metric을 바꾸므로,
- 중요도가 높은 방향은 점점 더 민감하게,
- 중요도가 낮은 방향은 점점 더 둔감하게.
- Backprop 없이도 “gradient 기반 feature learning”을 구현하는 셈.
논문에서도 Table 5에서 RFMs > PCA > MD 순으로 성능이 나오는 것을 보여주며 이를 뒷받침합니다.
7. EXPERTSTEER 관점 Pseudo-code (RFM part만)
# H: (K, d_E) expert hidden states
# y: (K,) binary labels (1=domain, 0=other)
# tau: num_iterations
# sigma: bandwidth
M = I_dE # (d_E, d_E)
for t in range(tau):
# 1. Build kernel matrix using current M
K_mat = np.zeros((K, K))
for a in range(K):
for b in range(K):
diff = H[a] - H[b]
K_mat[a, b] = exp(-(diff @ M @ diff) / sigma)
# 2. Solve KRR
beta = np.linalg.solve(K_mat, y) # (K,)
# 3. Compute gradients wrt each H[k]
G = [] # list of gradient vectors g_k
for k in range(K):
# π_t(H[k]) = sum_a K(H[a], H[k]) * beta[a]
# ∇_{H[k]} π_t = sum_a beta[a] * ∇_{H[k]} K(H[a], H[k])
grad = np.zeros(d_E)
for a in range(K):
diff = H[a] - H[k]
# derivative of exp(-diff^T M diff / sigma) wrt H[k]
# = 2/sigma * M @ diff * kernel_value
kernel_val = K_mat[a, k]
grad += beta[a] * (2.0 / sigma) * (M @ diff) * kernel_val * (-1)
G.append(grad)
# 4. Update M by AGOP
M = np.zeros((d_E, d_E))
for g in G:
M += np.outer(g, g)
M /= K
# 5. Eigen decomposition
eigvals, eigvecs = np.linalg.eigh(M)
nu = eigvecs[:, np.argmax(eigvals)] # steering vector
(실제 구현에선 효율을 위해 kernel·gradient 계산을 벡터화하고, 정규화·정칙화(λI)도 추가할 수 있습니다.)
8. EXPERTSTEER 전체에서 RFM의 위치 요약
- Autoencoder와 MI로 **“어느 layer에 개입할지”**를 정하고
- RFM으로 **“그 layer에서 어떤 방향으로 밀어야 domain 전문성을 끌어낼지”**를 구한 뒤
- Target 모델의 해당 layer hidden state에 (또는 ) 를 더해서 steering
즉, **RFM은 ExpertSteer의 “지식 방향 추출 엔진”**입니다.
답글 남기기