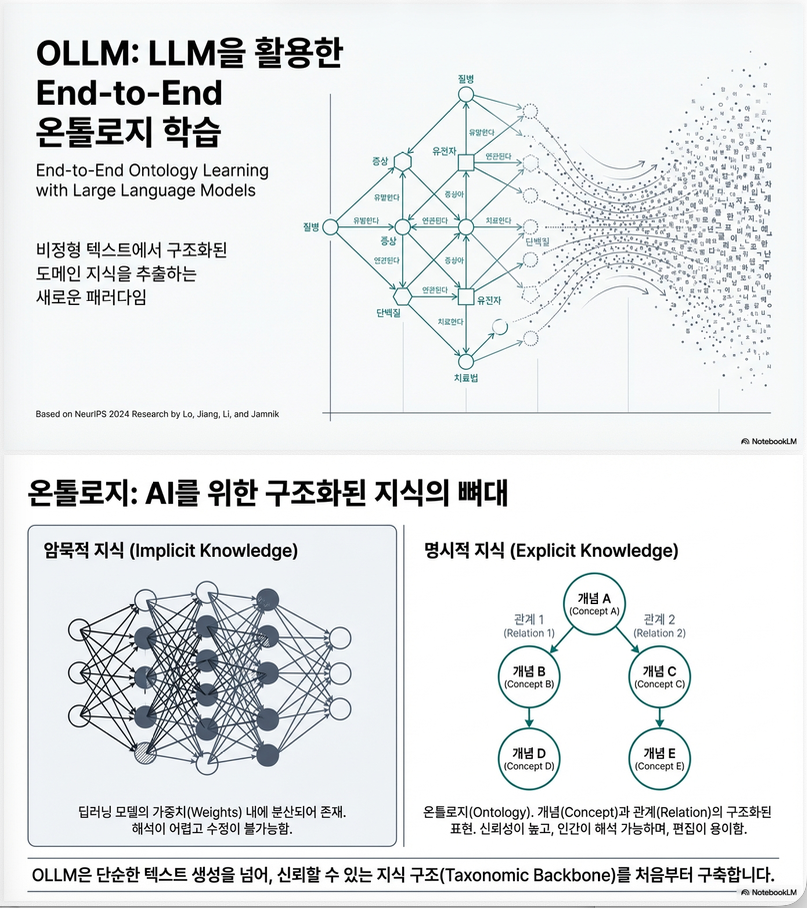

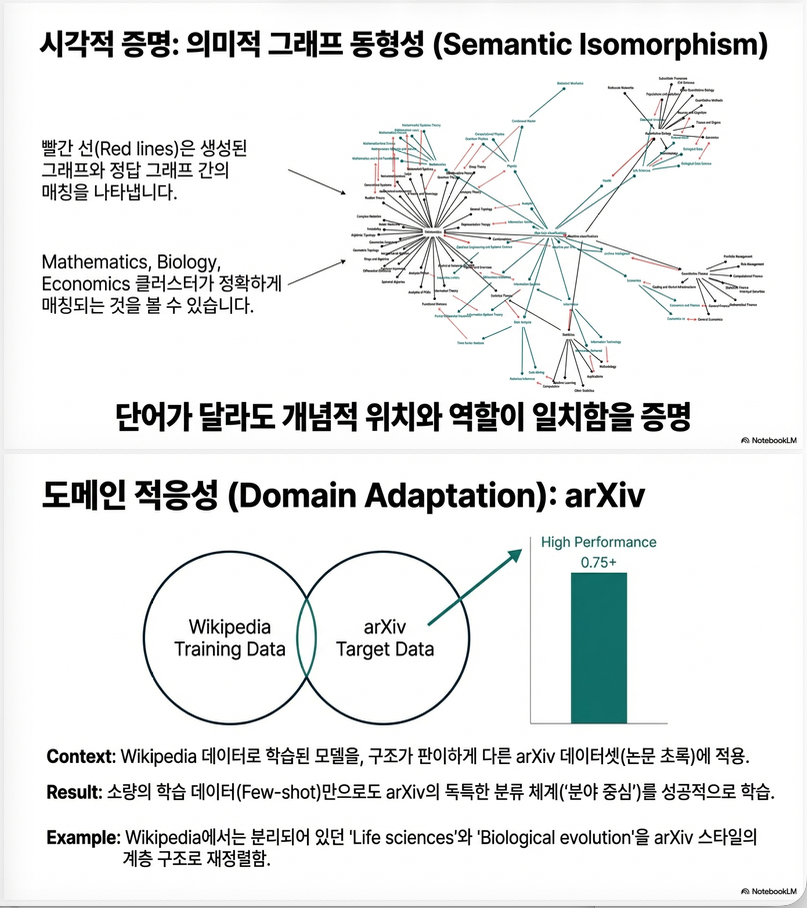
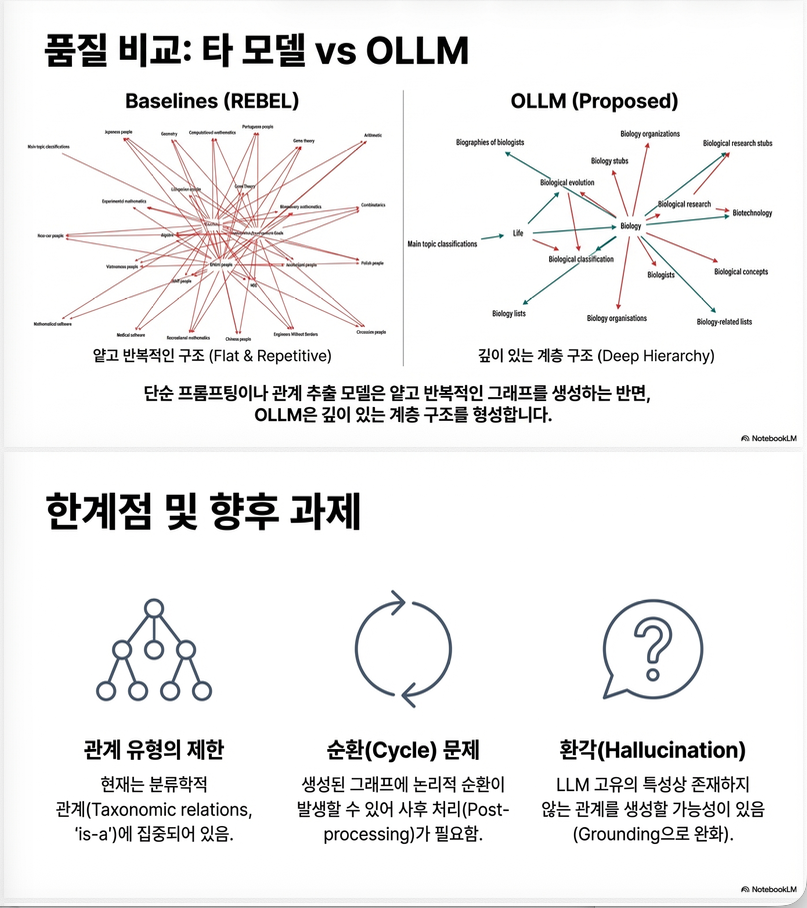
아래 논문은 **End-to-End Ontology Learning with Large Language Models (NeurIPS 2024)**로, LLM을 이용해 *온톨로지(특히 taxonomic backbone)*를 subtask 분해 없이 end-to-end로 학습하는 방법인 OLLM을 제안합니다
1. 문제 설정
Ontology Learning (OL)이란?
온톨로지는
- 노드: 개념 (concept)
- 엣지: is-a (taxonomic) 관계 로 구성된 루트가 있는 방향 그래프입니다.
예:
Programming language
→ Dynamically typed language
→ Python기존 OL 접근:
- Concept discovery
- Relation extraction
- Link prediction
즉, subtask 조합 방식.
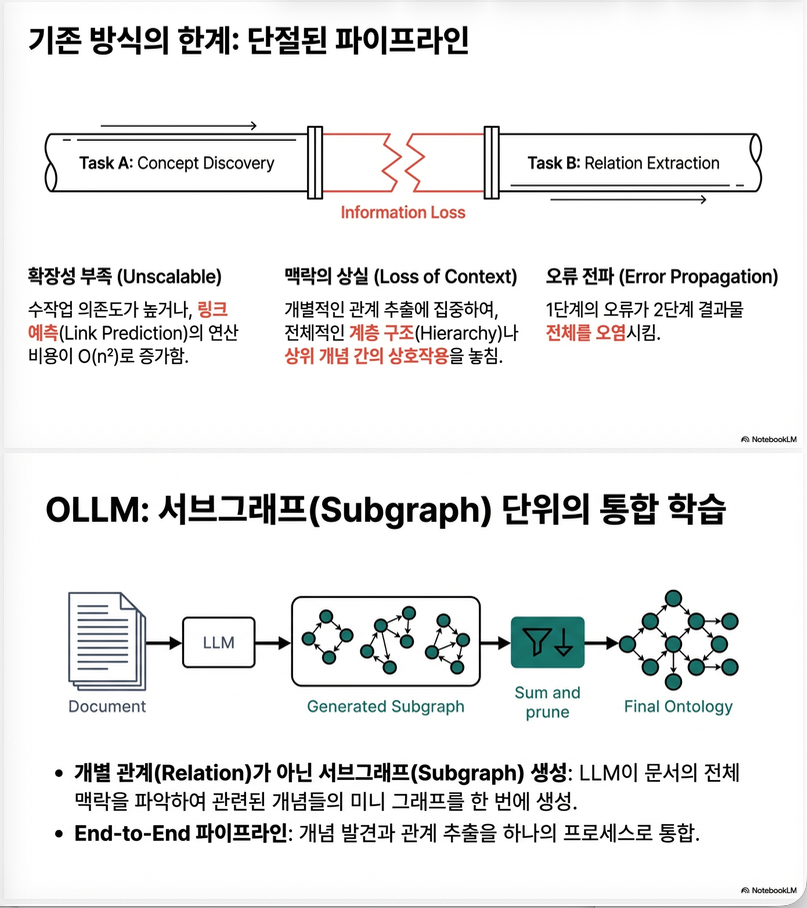
한계
- 각 subtask가 잘 되어도 전체 ontology 품질은 보장되지 않음
- link prediction은 O(n²) → 대규모 ontology에서 비효율적
- 구조적 일관성 유지 어려움
2. 핵심 아이디어: OLLM
핵심 전환
“엣지를 예측하지 말고, subgraph 전체를 생성하자.”
OLLM은 다음을 수행합니다:
- 문서 + 해당 문서의 ground-truth concept 집합 C
- root → concept 경로들 (길이 ≤ N)
- 이 경로들의 union = relevant subgraph
- subgraph를 문자열로 linearization
- LLM을 fine-tuning
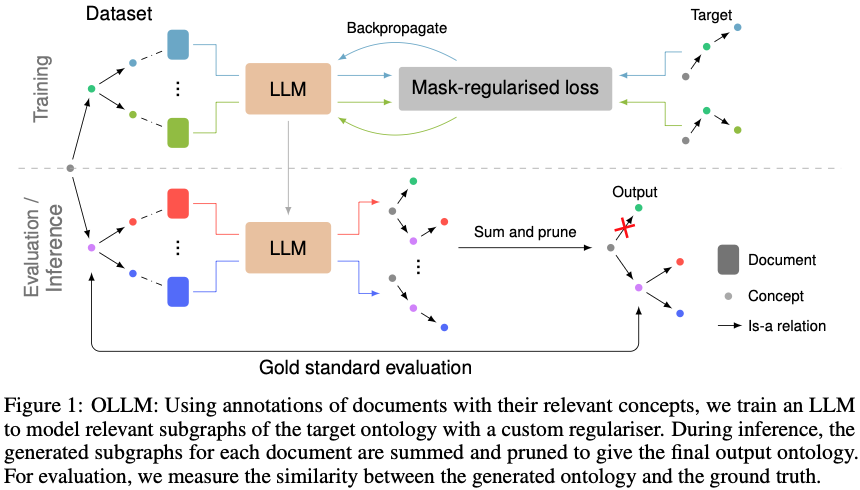
파이프라인은 Figure 1에 요약되어 있습니다
3. Subgraph Modeling
3.1 Relevant Subgraph 정의
문서 d에 대해:
- 해당 문서에 속한 concept 집합: C
- root에서 C까지 길이 ≤ N인 모든 경로
- 해당 경로들의 union을 subgraph로 사용
왜 subgraph 단위인가?
- 엣지 단위보다 고차 구조(higher-order structure) 학습 가능
- 계층적 inductive bias 제공
- BFS/DFS보다 “path-based linearization”이 자연스러움
Figure 2에 linearization 예시가 있습니다

4. Mask-Regularized Loss (핵심 기여)
문제점: Direct Finetuning의 Overfitting
고수준 개념 (예: “Culture”, “Humanities”)은 매우 자주 등장
→ 모델이 high-level relation을 암기
→ low-level relation 일반화 실패
Figure 4에서 이 현상이 시각화됨

해결책: Frequency-based Masking
관계 u → v가 학습 데이터에서 n번 등장하면
loss mask 확률:
즉,
- n ≫ M → 대부분 mask
- n ≤ M → 거의 mask 안 됨
의미:
자주 나오는 관계는 평균적으로 M번만 학습 타겟으로 보게 만듦
결과:
- high-level relation overfitting 감소
- low-level relation generalization 향상
5. Ontology 생성 방식
모든 문서에 대해 subgraph 생성 후:
엣지 weight:
= 등장 횟수
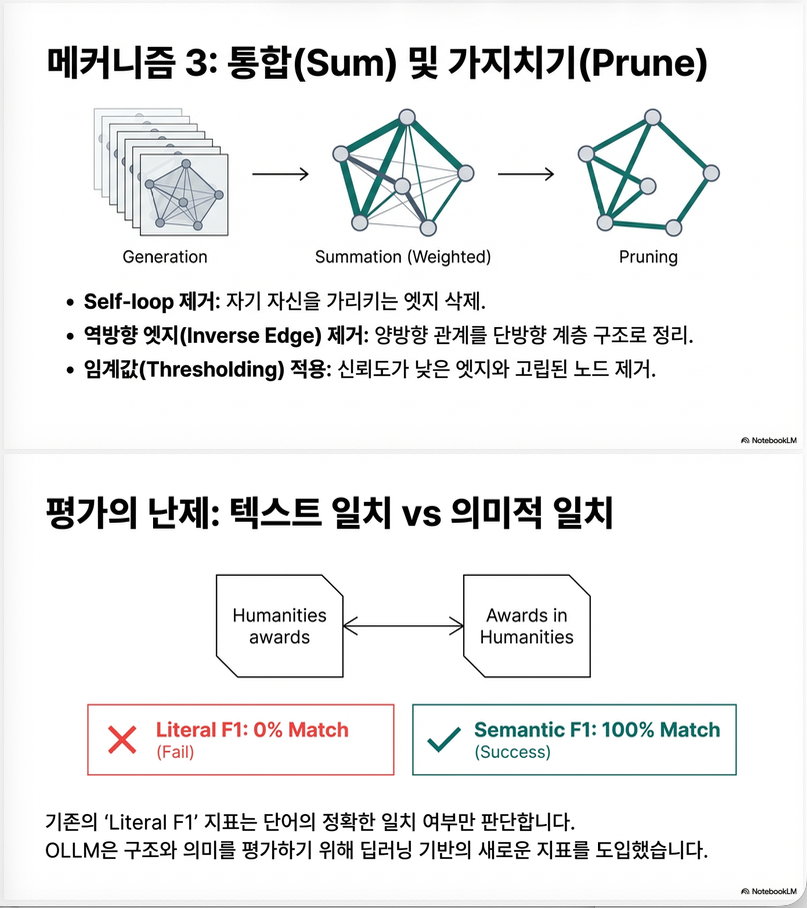
Post-processing
- self-loop 제거
- inverse edge 제거
- global threshold α
- local threshold β (top-p 스타일 pruning)
- isolated node 제거
6. 평가 지표 (중요 기여)
기존 ontology evaluation 문제:
- 문자열 exact match 위주
- semantic similarity 반영 못함
논문은 5개 metric 제안
6.1 Literal F1
정확한 문자열 일치
한계:
- casing, synonym에 취약
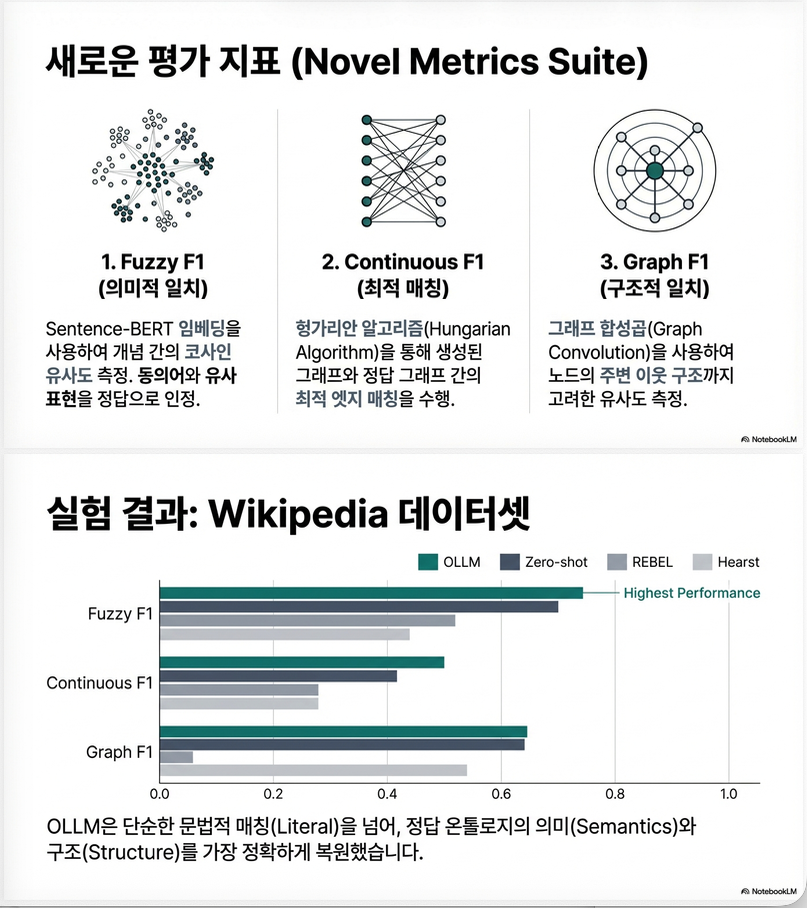
6.2 Fuzzy F1
Sentence-BERT embedding 사용
엣지 (u,v)와 (u’,v’)가:
이면 match
threshold t = WordNet synonym median (0.436)
6.3 Continuous F1
Hungarian algorithm으로 최적 edge matching 수행
보다 정밀한 fuzzy 매칭
6.4 Graph F1
- node embedding
- Graph Convolution (K=2)
- node matching
→ 구조 + 의미 동시 반영
6.5 Motif Distance
3-node motif 분포 비교
→ structural integrity 평가
7. 실험 결과
Wikipedia (대규모)
| Method | Fuzzy F1 | Cont F1 | Graph F1 |
|---|---|---|---|
| Zero-shot | 0.871 | 0.455 | 0.639 |
| Finetune | 0.884 | 0.470 | 0.588 |
| OLLM | 0.915 | 0.500 | 0.644 |
→ OLLM가 semantic metric에서 최고
arXiv (transfer)
OLLM은 Wikipedia → arXiv 소량 데이터 (2048 samples)로 transfer
Fuzzy F1:
- OLLM transfer: 0.570
- 다음 best: 0.460
→ strong domain adaptation
8. 중요한 관찰
Literal F1은 misleading
Memorization baseline이 Literal F1 최고
→ syntax ≠ semantic similarity
논문에서 meta-evaluation으로 비판
9. 기여 정리
논문 기여 3가지
- Wikipedia / arXiv end-to-end OL dataset 구축
- OLLM (subgraph generative framework)
- 새로운 semantic-aware graph evaluation metric
10. 방법론적 의의
이 논문은 단순히 “LLM으로 ontology 만들었다”가 아니라:
① Task Reframing
- edge prediction → subgraph generation
② Regularization Innovation
- frequency-aware masked loss
③ Evaluation Innovation
- semantic graph isomorphism 근사
11. 한 줄 요약
OLLM은 LLM을 이용해 ontology를 “edge prediction의 집합”이 아니라 “subgraph generation 문제”로 재정의하고, frequency-aware regularization과 semantic graph matching metric을 통해 대규모 end-to-end ontology learning을 가능하게 한 첫 실질적 프레임워크이다.
아래는 논문의 **방법론(Methodology)**을 수식·알고리즘 관점에서 정리한 것입니다
1. 문제 정식화
- 입력: 문서 집합
- 보조 정보(학습 시): 각 문서 d에 대응하는 개념 집합
- 목표: 루트가 있는 유향 그래프 G=(V,E)의 taxonomic backbone(is-a 관계) 복원
온톨로지는 (개념=노드, is-a=엣지)로 구성된 라벨 그래프.
2. Subgraph Modeling (핵심 전환)
2.1 Relevant Subgraph 정의
문서 d와 그 개념 집합 C(d)가 주어지면:
- 루트 r에서 까지 길이 인 모든 경로들의 집합:
- Relevant subgraph:
엣지 단위가 아니라 **경로들의 합집합(=subgraph)**을 예측 단위로 설정.
왜 subgraph인가?
- 엣지 간 상호작용(고차 구조) 학습
- 계층적 inductive bias 제공
- 대규모 link prediction(O(n²)) 회피
2.2 Linearization (경로 기반)
각 경로 를 문자열로 직렬화:
Main topic classifications -> ... -> c- BFS/DFS 대신 path-based linearization 채택
- 자연어 프롬프트와의 정합성↑
- 계층 구조를 직접 노출
3. 학습 목표: Mask-Regularized Autoregressive LM
3.1 기본 목적함수
LLM 파라미터 에 대해, 각 문서-서브그래프 쌍 의 선형화 시퀀스 y:
문제: 상위 개념(high-level relation) 과적합.
3.2 Frequency-aware Masked Loss (핵심 기여)
관계 가 학습 데이터에서 n번 등장한다고 하자.
하이퍼파라미터 M (평균 노출 목표 횟수) 정의.
관계 토큰(특히 child v)의 loss를 다음 확률로 마스킹:
- : 자주 등장 → 대부분 마스킹
- : 드물게 등장 → 마스킹 거의 없음
직관
- 모든 관계가 평균적으로 회만 타겟으로 학습
- 고빈도 상위 개념 암기 ↓
- 저빈도 하위 개념 일반화 ↑
입력 컨텍스트에서는 해당 토큰을 유지(teacher forcing 유지), 타겟 손실만 제거.
4. Inference & Graph Aggregation
4.1 문서별 Subgraph 생성
각 문서 d에 대해 생성된 서브그래프 .
4.2 합집합 및 가중치
엣지 가중치:
4.3 Post-processing (Pruning)
- Self-loop 제거
- Inverse edge 중 가중치 낮은 방향 제거
- Global threshold : 하위 제거
- Relative threshold : 각 노드별 top-p 유사 누적 비율 컷
- 고립 노드 제거
는 validation에서 Continuous F1 최대화로 선택
5. 평가 지표 설계 (Semantic Graph Matching)
기존 literal match 한계 극복.
5.1 NodeSim
사전학습 sentence transformer로 노드 임베딩 :
5.2 Continuous F1 (Edge-level Optimal Matching)
엣지 간 유사도:
Hungarian algorithm으로 최대 가중치 매칭:
5.3 Graph F1 (Node-level Structural Matching)
- 초기 노드 임베딩
- Graph Convolution (K=2):
- 노드 매칭 최적화
→ 구조 + 의미 동시 반영
6. 전체 알고리즘 (요약)
Training
for each document d:
construct relevant subgraph G_d (path length ≤ N)
linearize G_d
compute masked CE loss
update θInference
for each document d:
generate subgraph Ĝ_d
aggregate all Ĝ_d
apply pruning (α, β)
return final ontology7. 복잡도 관점
- Subtask link prediction: O(|V|²)
- OLLM: O(|D|) 문서 단위 생성
Hungarian matching은 평가 시 O(|E|³)이나
실제 inference에는 영향 없음
8. 방법론적 본질
OLLM은 다음 3가지 전환을 수행:
- Edge prediction → Subgraph generation
- Uniform CE → Frequency-balanced masked CE
- Literal graph match → Semantic optimal graph matching
9. 수식적으로 보면
본질적으로 OLLM은 다음을 근사:
즉,
global graph posterior를 document-level local graph generation의 합으로 근사.
다음은 논문의 실험 결과를 정량·정성·메타평가 관점에서 정리한 것입니다
1. 실험 설정 요약
- In-domain: Wikipedia categories
- Out-of-domain (transfer): arXiv taxonomy
- Baselines:
- Memorisation
- Hearst patterns
- REBEL
- Zero/One/Three-shot prompting
- Finetune (마스킹 없음)
- OLLM (마스킹 있음)
평가 지표:
- Literal F1
- Fuzzy F1 (semantic edge match)
- Continuous F1 (optimal matching)
- Graph F1 (GCN 기반 구조+의미)
- Motif Distance (구조 보존)
2. Wikipedia (대규모 실험)
주요 수치 (Table 1)
| Method | Literal | Fuzzy | Cont | Graph | Motif ↓ |
|---|---|---|---|---|---|
| Memorisation | 0.134 | 0.837 | 0.314 | 0.419 | 0.063 |
| Hearst | 0.003 | 0.538 | 0.350 | 0.544 | 0.163 |
| REBEL | 0.004 | 0.624 | 0.356 | 0.072 | 0.132 |
| Zero-shot | 0.007 | 0.871 | 0.455 | 0.639 | 0.341 |
| Finetune | 0.124 | 0.884 | 0.470 | 0.588 | 0.050 |
| OLLM | 0.093 | 0.915 | 0.500 | 0.644 | 0.080 |
해석
1. Semantic Metric에서 OLLM 최고
- Fuzzy F1: 0.915
- Continuous F1: 0.500
- Graph F1: 0.644
→ LLM + subgraph modeling이 의미적 일관성에서 가장 우수
2. Literal F1은 misleading
Memorisation이 최고 (0.134)
→ train/test 구조 overlap 때문에
→ 단순 암기가 syntax metric에서 유리
논문은 이를 명시적으로 비판
3. 구조적 안정성
- Prompting은 Motif Distance 0.314–0.354 → 구조 붕괴
- Finetune/OLLM은 0.05~0.08 → 구조 보존
→ fine-tuning이 구조 일관성 회복에 결정적
3. arXiv (Transfer 실험)
Wikipedia로 학습 → arXiv 2048 샘플로 적은 데이터 fine-tune
결과
| Method | Fuzzy | Cont | Graph |
|---|---|---|---|
| Memorisation | 0.207 | 0.257 | 0.525 |
| Hearst | 0.000 | 0.151 | 0.553 |
| REBEL | 0.060 | 0.281 | 0.546 |
| Zero-shot | 0.450 | 0.237 | 0.414 |
| Finetune (transfer) | 0.440 | 0.225 | 0.441 |
| OLLM (transfer) | 0.570 | 0.357 | 0.633 |
해석
1. Transfer 능력
- OLLM이 모든 semantic metric에서 최고
- 특히 Graph F1 0.633 → 구조 재구성 성공
2. 재구성 능력
논문에서 qualitative 분석:
- Wikipedia에서 배운 개념을 arXiv 구조에 맞게 재배치
- 예: “Life sciences”를 top-level로 승격
→ 단순 복사가 아닌 구조 재조합
4. Ablation 결과
4.1 Masked Loss 효과
Figure 4에서 확인
- Direct finetune: high-level relation 과적합
- Masked loss: unseen high-level generalization 개선
→ Continuous/Graph F1 향상
4.2 Chain-of-Thought Prompting
Zero-shot vs Zero-shot CoT 비교:
| Method | Cont F1 |
|---|---|
| Zero-shot | 0.455 |
| Zero-shot CoT | 0.449 |
→ 거의 차이 없음
해석:
- OL은 multi-step reasoning보다 semantic representation이 중요
4.3 LLMs4OL 방식 비교
Subtask 조합 vs End-to-end
| Method | Cont F1 |
|---|---|
| Zero-shot (end-to-end) | 0.455 |
| LLMs4OL | 0.428 |
→ end-to-end subgraph modeling이 구조적으로 우월
5. 계산 비용
Wikipedia:
- Training: 12 A100-hours
- Inference: 7 A100-hours
→ 대규모 ontology(13K concepts)에도 practical
6. Meta-Evaluation 분석
논문이 흥미로운 점은 metric 자체 분석을 수행한 것
발견:
- Literal F1 → syntax bias
- Motif distance → train/test structural symmetry bias
- Continuous F1 & Graph F1 → semantic graph isomorphism 근사
특히 Graph F1 node matching 시각화에서
Physics ↔ Mathematics cluster 매칭이 semantic하게 의미 있음
7. 전체 결론
Wikipedia
- OLLM이 semantic/structural metric에서 최고
arXiv
- 적은 데이터로 strong transfer
Prompting
- 구조 붕괴 발생
Subtask 방식
- 성능 낮고 확장성 문제
8. 핵심 메시지
- LLM 단독 prompting은 구조적으로 불안정
- Direct finetune은 high-level overfitting
- Frequency-masked subgraph modeling이 가장 안정적
- End-to-end modeling이 subtask 조합보다 우수
아래는 OLLM에서 말하는 subgraph generation을 “데이터 구성 → 시퀀스화(linearization) → LLM 생성 → 그래프 복원/집계”까지 구체적으로 풀어쓴 설명입니다. (논문 기준으로는 Section 3.1–3.2, Figure 2, Appendix Figure 5 템플릿)
1) Subgraph generation이란 무엇인가?
기존 OL은 보통
- (A) concept set을 찾고
- (B) concept 쌍 (u,v)에 대해 is-a인지 edge/link prediction을 합니다.
OLLM은 이를 뒤집어서,
문서 1개를 넣으면, 그 문서와 관련된 온톨로지의 “조각(subgraph)” 전체를 LLM이 한 번에 텍스트로 출력하게 합니다.
이 subgraph는 “임의 그래프”가 아니라, **루트에서 관련 개념까지의 경로들(paths)**을 모아 만든 작고 계층적인 그래프입니다.
2) 학습용 subgraph는 어떻게 만든다? (Ground-truth에서 “relevant subgraph” 추출)
각 문서 d에는 라벨처럼 관련 concept 집합 C(d) 가 있습니다. (Wikipedia에서는 문서가 속한 category들)
2.1 Relevant paths
루트 r에서 까지 가는 경로들 중 길이 인 것만 모읍니다.
- 여기서 N은 hyperparameter
- Wikipedia는 N=4 (전체 엣지의 99% 이상이 어떤 relevant subgraph 안에 들어오게 하는 최소 N)
2.2 Relevant subgraph
이 경로들의 union이 문서 d의 정답 subgraph:
즉,
- 노드: relevant paths에 등장하는 모든 concept
- 엣지: 그 경로에 포함된 is-a 관계
Figure 2 예시 직관
문서가 “Hybridity”이고, 관련 concept이 이면
루트(“Main topic classifications”)에서 이 둘로 가는 경로들을 모아 작은 subgraph를 만듭니다.
3) 그 subgraph를 LLM이 생성할 수 있게 “텍스트 시퀀스”로 바꾸기 (Linearization)
LLM은 그래프를 직접 출력하기 어렵기 때문에, OLLM은 subgraph를 **“경로 리스트”**로 표현합니다.
각 경로는
Main topic classifications -> ... -> leaf형식의 한 줄로 출력되고, 여러 경로를 줄바꿈으로 나열합니다.
논문이 BFS/DFS가 아니라 path-based를 택한 이유는:
- subgraph 정의 자체가 paths에서 나오므로 가장 자연스럽고
- 계층적 inductive bias를 “문장 형태”로 강하게 주며
- prompting baseline에서도 형식을 맞추기 쉬움
4) LLM이 실제로 “subgraph를 생성”하는 과정 (Generation task)
4.1 입력 (context)
문서의 title + abstract(또는 summary) + 지시문(Instruction)을 넣습니다.
Appendix의 템플릿은 이런 형태입니다 :
- 입력: Title: … Abstract: …
- 출력: 여러 줄의 root -> … -> leaf 경로들
4.2 출력 (what LLM produces)
LLM이 생성하는 텍스트는 사실상 “경로들의 집합”이고, 이것을 파싱하면 곧바로 엣지 집합을 얻습니다:
- 각 경로에서 인접한 노드쌍을 엣지로 추가 예: A -> B -> C ⇒ 엣지 (A,B), (B,C)
결국 LLM이 하는 일은
을 학습한 뒤, 문서별로 paths를 샘플링해내는 것과 같습니다.
5) 문서별 subgraph들을 “큰 ontology”로 합치는 방법 (Sum & Prune)
문서마다 생성된 가 있고, 이를 합쳐 최종 ontology를 만듭니다.
5.1 Union + edge counting
- 많이 반복 생성된 엣지는 weight가 커짐 → 더 신뢰
5.2 Post-processing (pruning)
논문은 다음을 수행합니다 :
- self-loop 제거
- inverse edge가 둘 다 있으면 weight 큰 방향만 유지
- global quantile threshold 로 약한 엣지 제거
- 각 노드 outgoing edge들에 대해 top-p 유사한 cumulative pruning
- 고립 노드 제거
즉, “여러 문서의 투표로 얻은 noisy graph”를 정제해서 backbone으로 만드는 단계입니다.
6) 왜 subgraph generation이 유리한가? (핵심 장점 3가지)
(1) 확장성
edge/link prediction은 개념 수가 n이면 질문/판정이 필요합니다.
반면 OLLM은 문서 수 |D| 만큼만 생성하면 됩니다. (문서당 1회 generation)
(2) 구조 학습
엣지 단위는 “국소 판단”이고, 삼각형/계층의 모양 같은 higher-order 구조를 직접 학습하기 어렵습니다.
경로 리스트는 계층 구조를 강하게 강제합니다.
(3) LLM 친화적 표현
LLM은 텍스트 생성이 강점이므로, “그래프→텍스트” 변환을 경로 나열로 두면 형식 강제가 쉽고, zero/one-shot도 꽤 작동합니다(다만 구조는 무너질 수 있음).
7) 논문에서의 흔한 failure mode (subgraph generation 관점)
- Prompting만 할 때: 의미는 맞는데 구조가 깨져서 motif distance가 나쁨
- Direct finetune: 상위 레벨 관계를 암기(“Main topic classifications → Culture” 같은 것) → unseen top-level generalization 실패 → 그래서 frequency-aware masked loss가 필요
답글 남기기