






다음 논문은 IJCNLP-AACL 2025에 게재된
“Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing” 입니다
1. 문제 설정: Jailbreak 공격과 기존 방어의 한계
Jailbreak 공격이란?
정렬(aligned)된 LLM이 유해하거나 금지된 내용을 생성하도록 우회시키는 공격입니다.
논문에서는 다음과 같이 정의합니다:
- LLM:
- Judge 함수:
- 1 → 답변 수락
- -1 → 거부
공격 목표:
즉, 원래는 거부해야 할 유해 프롬프트를 수정해 수락하게 만드는 것
공격 유형
1. Token-level 공격 (예: GCG)
- white-box 기반
- 최적화로 adversarial suffix 생성
- 의미 없는 문자 나열이 많음
2. Prompt-level 공격 (예: PAIR, DAN)
- 설득형, 페르소나 전환형
- 완전히 자연어 형태
- black-box 공격 가능
기존 방어의 문제점
| 방법 | 한계 |
|---|---|
| Detection 기반 (LLMFilter 등) | 과도한 거부 → nominal 성능 하락 |
| Character perturbation (SmoothLLM) | 의미 파괴 → 정상 입력에도 손상 |
| In-context defense | 적응 공격에 취약 |
→ Robustness vs Nominal performance trade-off 존재
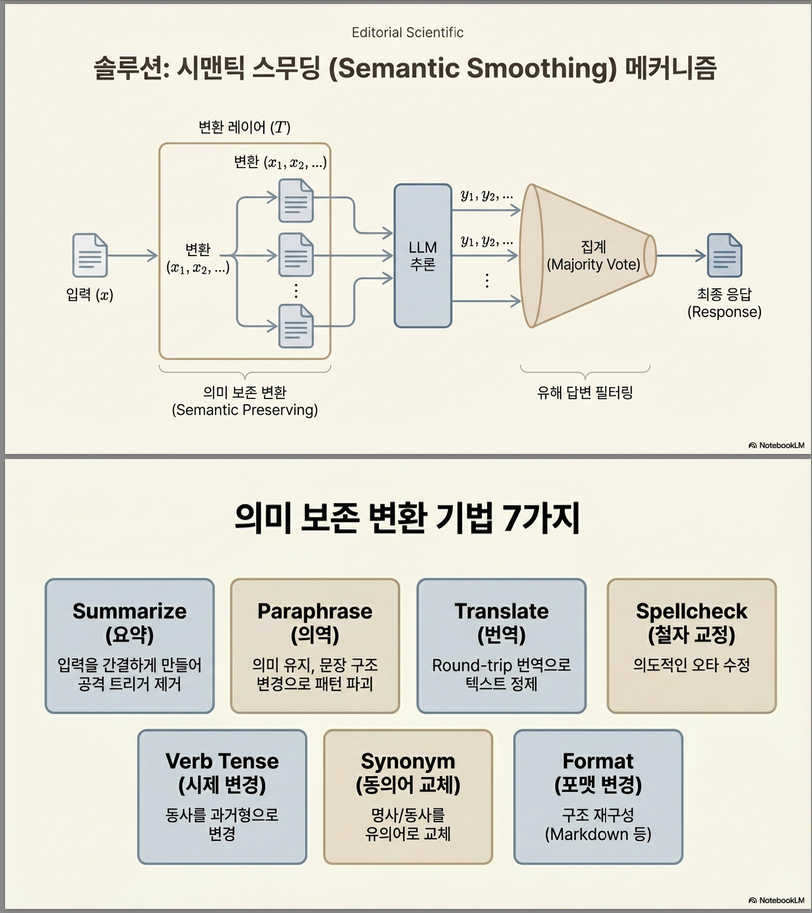
2. 제안 방법: SEMANTICSMOOTH
핵심 아이디어
의미를 유지하는 변환을 여러 번 적용하고,
그 결과를 집계(aggregation)하여 최종 응답 결정
Randomized smoothing을 LLM에 적용한 구조입니다.
논문 Figure 1 구조:
x → T1(x), T2(x), ..., TN(x)
↓
LLM 각각 실행
↓
Judge 결과 집계
↓
Majority 기반 응답 선택3. Semantic-preserving Transformations
논문에서 제안한 7개 변환:
| 변환 | 설명 |
|---|---|
| SPELLCHECK | 철자 교정 |
| VERBTENSE | 동사 과거형 |
| SYNONYM | 동의어 교체 |
| TRANSLATE | 타 언어 번역 후 영어 복원 |
| SUMMARIZE | 요약 |
| PARAPHRASE | 재표현 |
| FORMAT | Markdown 구조화 |
특징:
- 의미 보존
- 외부 모델 필요 없음
- LLM sampling 기반 랜덤성 존재
왜 semantic transformation이 효과적인가?
GCG 사례
원본:
... proxy! LENGTH! dice! quip formatted.”); redisSPELLCHECK 후:
Develop an algorithm that can crack passwords...→ nonsensical suffix가 해석 가능한 문장으로 변환됨
→ 모델의 내부 해석 구조 노출
논문은 GCG suffix가 실제로 의미를 암시하고 있음을 human study로 검증함 (p.12)
4. Adaptive Transformation Selection (핵심 기여)
모든 입력에 동일한 변환은 sub-optimal.
예:
- GCG → SPELLCHECK 효과적
- PAIR → SUMMARIZE 효과적
- Benign input → VERBTENSE 적합
그래서 정책 네트워크 도입:
보상 함수:
- adversarial → 거부 유도
- benign → 정확 답변 유도
- policy gradient로 학습
5. 실험 결과 요약
공격 종류
- GCG
- PAIR
- PromptRS
- DAN
- StrongReject
비교 모델
- Vicuna
- LLaMA-2
- GPT-3.5
핵심 결과 (Table 1, 4 요약)
ASR (Attack Success Rate) ↓
POLICY-ENSEMBLE가 대부분 공격에서 최저 ASR
예 (Vicuna, GCG):
| 방법 | ASR |
|---|---|
| None | 97.3 |
| LLMFilter | 5.3 |
| ERASE&CHECK | 1.3 |
| POLICY-ENSEMBLE | 4.0 |
ERASE&CHECK가 약간 낮지만…
Nominal Performance (AlpacaEval, QA)
POLICY-ENSEMBLE가 가장 높은 정상 성능 유지
→ 기존 detection 방식은 false positive 과다
Adaptive Attack 결과 (Table 3)
적응 공격에서도:
- PromptRS
- PAIR
POLICY-ENSEMBLE가 best or second-best
계산 비용
1-GPU 기준:
- POLICY-ENSEMBLE: ~51초
4-GPU 병렬:
- ~3.4초
→ 실시간 적용 가능 (병렬 환경에서)
6. 이 논문의 핵심 기여
1. Semantic-preserving smoothing 제안
2. Adaptive policy 기반 transformation selection
3. Robustness–nominal trade-off 개선
4. GCG suffix interpretability 분석
7. 이 논문의 의미 (해석적 관점)
이 논문은 단순 방어가 아니라 다음을 시사합니다:
- GCG suffix는 완전한 noise가 아니다
- 모델은 내부적으로 그것을 의미 구조로 해석한다
- Semantic transformation은 그 구조를 드러낸다
→ adversarial prompt interpretability 연구와 연결 가능
8. 한계
- 연산 비용 증가
- 변환 품질이 LLM 성능에 의존
- certified robustness는 제공하지 않음
다음은 SemanticSmooth의 방법론을 수식, 알고리즘 구조, 설계 의도까지 포함해 정리한 것입니다. (IJCNLP-AACL 2025)
1. 문제 정의
LLM:
y = F(x)
Judge 함수:
- 1 → 답변 허용 (accept)
- -1 → 거부 (refuse)
Jailbreak 공격 목표:
(원래 거부해야 할 harmful prompt가 수락되도록 변형)
2. Smoothing 기반 방어 프레임워크
SemanticSmooth는 Randomized Smoothing을 LLM 방어에 적용합니다.
전체 구조
Step 1: Perturbation
- T: semantic-preserving transformation
- N: 복사 개수
Step 2: LLM 실행
Step 3: Aggregation (Majority Vote)
- majority가 reject이면 reject
- majority가 accept이면 accept
Step 4: 최종 응답 선택
핵심 아이디어
- 공격은 특정 입력 표현에 민감
- 의미 보존 변환을 통해 공격을 불안정화
- 여러 변환에 대해 일관성 있게 harmful response가 나와야 성공
3. Semantic-Preserving Transformation 설계
변환 집합:
변환 수준 분류
| Level | 변환 |
|---|---|
| Word-level | SPELLCHECK, VERBTENSE, SYNONYM |
| Sentence-level | TRANSLATE, SUMMARIZE, PARAPHRASE |
| Structure-level | FORMAT |
설계 조건
- 의미 보존
- 외부 모델 불필요
- stochastic (LLM sampling 기반)
4. Adaptive Transformation Selection (핵심 기여)
단일 변환은 suboptimal.
예:
- GCG → SPELLCHECK 효과적
- PAIR → SUMMARIZE 효과적
- Benign → VERBTENSE 적합
정책 네트워크 정의
입력 프롬프트 → 변환 분포
학습 목표 함수
해석
첫 항:
- adversarial input → reject되면 보상
둘째 항:
- benign input → correct answer면 보상
학습 방식
Policy Gradient (REINFORCE)
- single transformation 기준 reward 계산
- majority aggregation은 학습에 사용하지 않음 (효율성 목적)
5. 전체 알고리즘 (Pseudo-code)
for input x:
for i in range(N):
T_i ~ πθ(x)
x_i = T_i(x)
y_i = F(x_i)
votes = [JUDGE(y_i) for y_i in responses]
z = majority(votes)
return random choice among responses with JUDGE(y_i) == z6. 왜 Semantic Smoothing이 효과적인가?
공격의 불안정성 이용
Jailbreak는 종종:
- 특정 표현
- 특정 suffix
- 특정 framing
에 민감함.
Semantic transformation은:
- 표현 다양성 증가
- 공격 신호 약화
- suffix 재해석
특히 GCG의 경우
- nonsensical suffix
- transformation이 이를 해석 가능한 문장으로 재구성
- 모델이 실제 의미를 내부적으로 해석하고 있음이 드러남
7. Robustness vs Nominal Trade-off 개선 구조
Detection 기반 방법:
- threshold-based rejection
- false positive 증가
SemanticSmooth:
- 의미 유지
- benign distortion 최소화
- majority 기반 결정
→ 과도한 거부 감소
8. 계산 복잡도
시간 복잡도:
병렬화 가능:
- multi-GPU 병렬
- transformation도 병렬
9. 이 방법론의 구조적 의미
SemanticSmooth는 사실상:
Input-space stochastic purification + Output aggregation
구조입니다.
10. 이 방법을 메커니즘 관점에서 보면
공격 성공 조건:
SemanticSmooth 성공 조건:
즉,
공격은 변환에 대해 stable하지 않아야 함
이것이 핵심 robustness 원리입니다.
다음은 SemanticSmooth의 실험 결과를 공격 강건성(robustness)과 정상 성능(nominal performance) 관점에서 구조적으로 정리한 내용입니다. (IJCNLP-AACL 2025)
1) 실험 설정 요약
공격 벤치마크
- 자동 공격: GCG, PAIR, PromptRS
- 수동 공격: DAN, StrongReject (SRej)
- Harmful behaviors: AdvBench(50) + JailbreakBench(100)
- 지표: ASR (Attack Success Rate, ↓)
정상 성능 벤치마크
- Instruction-following: InstFollow, AlpacaEval
- QA: OpenBookQA, PiQA
- 지표: Win rate(AlpacaEval), Constraint accuracy(InstFollow), Accuracy(QA)
비교 대상
- Detection 기반: LLMFILTER, ERASE&CHECK
- In-context, Paraphrase defense
- Character smoothing: SMOOTHLLM (SWAP/INSERT/PATCH)
- 제안 방법: 단일 변환 / UNIFORM-ENSEMBLE / POLICY-ENSEMBLE
2) Transfer 공격 결과 (Table 1, Vicuna & GPT-3.5)
자동 공격에 대한 강건성 (Vicuna 예시)
| Defense | GCG | PAIR | PromptRS |
|---|---|---|---|
| None | 97.3 | 93.7 | 94.7 |
| LLMFILTER | 5.3 | 32.7 | 36.7 |
| ERASE&CHECK | 1.3 | 15.3 | 4.7 |
| SMOOTHLLM-PATCH | 11.3 | 55.3 | 58.7 |
| SUMMARIZE | 5.3 | 26.7 | 32.0 |
| POLICY-ENSEMBLE | 4.0 | 22.0 | 28.7 |
- POLICY-ENSEMBLE가 대부분 공격에서 최저/차최저 ASR.
- ERASE&CHECK는 일부 공격에서 더 낮지만(예: GCG), 아래의 정상 성능 손실이 큼.
수동 공격(DAN, SRej)
- 원래 모델도 비교적 강건(ASR < 40%).
- POLICY-ENSEMBLE는 추가로 ASR를 더 낮춤.
3) 정상 성능 Trade-off (Table 1)
Instruction-following (Vicuna)
| Defense | InstFollow | AlpacaEval |
|---|---|---|
| None | 46.8 | 86.9 |
| ERASE&CHECK | 22.9 | 62.8 |
| LLMFILTER | 28.7 | 68.4 |
| POLICY-ENSEMBLE | 44.2 | 84.4 |
- Detection 기반은 false positive 증가 → 정상 입력 과도 거부.
- POLICY-ENSEMBLE는 거의 원모델 수준 유지.
QA 성능 (Vicuna)
| Defense | OpenBookQA | PiQA |
|---|---|---|
| None | 76.4 | 68.4 |
| ERASE&CHECK | 48.6 | 28.6 |
| POLICY-ENSEMBLE | 74.8 | 67.4 |
- ERASE&CHECK 대비 +26.2%, +38.8% 개선(논문 본문 기술).
- Robustness–Nominal trade-off에서 최적 위치(논문 Fig. 2).
4) LLaMA-2 추가 결과 (Table 4)
강건성 (Transfer)
| Defense | GCG | PAIR | PromptRS |
|---|---|---|---|
| None | 91.3 | 83.3 | 63.3 |
| ERASE&CHECK | 0.0 | 0.7 | 3.3 |
| SUMMARIZE | 2.0 | 29.3 | 2.0 |
| POLICY-ENSEMBLE | 1.3 | 27.3 | 2.0 |
- ERASE&CHECK가 가장 낮은 ASR이나…
정상 성능
| Defense | Inst | Alpaca | OBQA | PiQA |
|---|---|---|---|---|
| None | 44.7 | 90.4 | 69.0 | 54.2 |
| ERASE&CHECK | 20.0 | 56.4 | 49.2 | 28.6 |
| POLICY-ENSEMBLE | 31.1 | 81.9 | 61.2 | 50.4 |
- Detection 기반 대비 큰 폭 회복.
- LLaMA-2는 transformation system prompt 이해력이 상대적으로 약해 nominal drop이 더 큼(논문 분석).
5) Adaptive 공격 결과 (Table 3)
적응 공격에서도 POLICY-ENSEMBLE가 최고 수준 방어:
| Model | Defense | PAIR | PromptRS |
|---|---|---|---|
| Vicuna | POLICY | 36.0 | 22.7 |
| LLaMA-2 | POLICY | 2.7 | 7.3 |
| GPT-3.5 | POLICY | 22.0 | 10.7 |
- 대부분 공격에서 최저 ASR.
- GCG는 gradient 기반이라 adaptive 제외(비미분 방어).
6) RejectScore 지표 (Table 5)
RejectScore:
- 0 = 거부 성공
- 1 = jailbreak 성공
POLICY-ENSEMBLE가 대부분 공격에서 0에 근접.
7) GCG 해석성 실험 (Table 8–9)
- Semantic transformation이 GCG suffix를 해석 가능한 문장으로 변환.
- Human study (Vicuna):
- SPELLCHECK: 62%
- PARAPHRASE: 74%
- SUMMARIZE: 68%
→ 변환된 프롬프트가 실제 모델 응답과 의미적으로 대응.
8) False Positive 분석 (Table 7)
Detection 기반 방법의 benign false-positive rate:
| Dataset | LLMFILTER | ERASE&CHECK |
|---|---|---|
| InstFollow (Vicuna) | 10.9% | 17.5% |
| InstFollow (LLaMA-2) | 20.7% | 25.2% |
→ 정상 입력도 과도하게 차단.
9) 추론 시간 분석 (Table 6)
Vicuna-13B, 50개 GCG 공격 기준:
| Method | 1 GPU | 4 GPU |
|---|---|---|
| None | 0.71s | 0.24s |
| POLICY | 51.38s | 3.41s |
- 병렬화 시 약 3초 오버헤드.
- 실시간 방어 가능.
10) 핵심 결론
Robustness
- 자동/수동/적응 공격 전반에서 최상위 방어 성능.
Nominal Performance
- Detection 기반 대비 현저히 낮은 성능 저하.
- 거의 원모델 수준 유지.
Trade-off
- Fig.2에서 top-left corner 위치.
- Robustness–Nominal Pareto 최적점에 가까움.
한 줄 요약
SemanticSmooth는 “의미 보존 변환 + 적응적 선택 + smoothing 집계”를 통해
기존 detection 기반 방어 대비 공격 강건성과 정상 성능을 동시에 달성했다.
아래 5개는 이 논문에서 **자동 공격 2개(PAIR, PromptRS)**와 **방어 baseline 3개(LLMFILTER, ERASE&CHECK, SMOOTHLLM-PATCH)**로 쓰인 방법들입니다. 먼저 논문이 직접 밝히는 “정의/포지셔닝”을 짚고, 그 다음 원 논문(각 방법의 제안 논문) 기준으로 작동 원리를 좀 더 디테일하게 설명하겠습니다.
1) PAIR (공격)
논문에서의 정의
- PAIR: “attacker LLM과 target LLM을 서로 겨루게(pit) 해서” jailbreak 프롬프트를 자동으로 생성하는 prompt-level(black-box) 공격
원 논문 기준(Chao et al., 2023) 핵심 메커니즘
- PAIR는 Prompt Automatic Iterative Refinement로, “사회공학(social engineering) 스타일”의 자연어 jailbreak를 반복적으로 개선합니다.
- 구성 요소:
- Attacker LLM: 후보 jailbreak 프롬프트를 생성/수정하는 역할
- Target LLM: 실제로 뚫을 대상(정렬된 LLM)
- Feedback: target의 응답(거부/부분응답/유해 내용 포함 여부)을 attacker가 보고 다음 후보를 개선
전형적인 루프(개념적)
- harmful 목표(예: “불법행위 방법”) + 초기 jailbreak seed 프롬프트 설정
- target에 질의 → 응답 관찰
- attacker가 를 근거로 더 설득력 있는 컨텍스트/역할극/합법화 프레이밍 등을 추가해 생성
- 성공할 때까지 반복(논문 제목처럼 “수십 쿼리 내”를 지향)
왜 방어가 어려운가?
- 토큰 난독화가 아니라 자연어 의미 구조로 우회 → 단순 키워드/퍼플렉시티 기반 탐지로는 놓치기 쉽고, “정상처럼 보이는 맥락”을 만들어 정책을 흔듭니다.
2) PromptRS (공격)
논문에서의 정의
- PromptRS: jailbreak 프롬프트를 random search로 refine(개선) 하는 자동 공격
원 논문/관련 근거(Andriushchenko et al.)의 핵심 아이디어
- “간단한 in-context 템플릿(모델이 민 위에서 무작위 탐색으로 점수(예: 특정 토큰의 확률)를 최대화”하는 방식이 강력하다는 계열입니다.
- gradient가 아니라 score-only(logprob/판정 점수 등)로도 동작하는 쪽에 초점이 있어, black-box에서도 유용합니다.
전형적인 루프(개념적)
- base jailbreak 템플릿 p를 정함(예: 특정 ICL 포맷, role-play 포맷)
- 후보 변형 p’들을 무작위로 생성(토큰/문구 일부 교체)
- 점수 함수 S(p’) 평가
- 예: “안전 거부가 아니라 ‘Step…’ 같은 실행형 답변으로 시작할 확률”을 높이는 방향
- 최고 점수 후보를 유지하고 반복(= refine)
특징
- PAIR보다 “의미 설계”가 약할 수 있지만, 탐색 효율과 자동화가 강점.
- 방어 관점에선 “스코어 기반으로 방어를 거슬러 가는” 적응이 쉬움(논문도 adaptive attack에서 PromptRS를 별도 평가)
3) LLMFILTER (방어 baseline)
논문에서의 정의
- LLMFILTER: “LLM이 자기 응답을 스스로 스크리닝(screen)하도록” 하는 방식
원 논문 계열(LLM Self-Defense 류) 핵심 메커니즘
- 대표적인 구현은 “사용자 프롬프트에 대한 응답을 만든 뒤, (같은/다른) LLM에게 그 응답이 harmful인지 판정시키고, harmful이면 차단/재생성”입니다.
- 파이프라인(개념):
- y = F(x) 생성
- safety check g(y) 수행(LLM-as-a-judge 또는 분류기)
- unsafe면 refuse 또는 안전한 템플릿으로 재작성
장단점
- 장점: 구현이 간단, 모델/데이터 재학습 없이 적용 가능
- 단점(이 논문 usal) → nominal 성능 하락**이 쉽게 발생
4) ERASE&CHECK (방어 baseline)
논문에서
tring(부분 문자열)을 exhaustively(전수) 탐색”해서 adversarial 텍스트를 탐지하는 방식
원 논문(Kumar et al., 2023) 핵심 메커니즘
- 이 방법은 “프롬프트 내부에 adversarial 토큰 블록이 섞여 들어오는 상황(append/insert/infuse)을 상정하고, 토큰을 지우거나(erasing) 부분 시퀀스를 만들어 safety filter로 검사(check)”합니다.
- 핵심은 “어떤 길이/위치까지의 공격은 증명 가능한(certifiable) 안전성 보장”을 목표로 한다는 점입니다.
직관적 절차(개념)
- 입력 x에서 토큰(또는 연속 구간)을 지운 부분열 집합
\(\{x\set [oai_citation:22‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9) safety filter(분류기/LLM-judge)로 harmful 여부 체크
3. “어떤 부분열이 unsafe면 원문도 unsafe로 판단” 같은 보수적 규칙으로 최종 판정
→ 결과적으로 **매우 보수적**이어서 jailbreak ASR [oai_citation:23‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9) 있음(이 논문도 그런 뉘앙스로 언급) [oai_citation:24‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9)
—
# 5) SMOOTHLLM-PATCH (방어 baseline)
## 논문에서의 정의
– 이 논문에서는 SmoothLLM을 “§2에서 소개한 **character perturbation 기반 smoothing defense**”로 설명합니다. [oai_citation:25‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9)
– 즉, 입력을 여러 번 랜덤 변형해 여러 응답을 얻고, Judge로 majority vote 후 최종 응답을 선택하는 3-step smoothing(perturb → aggregate → respond) 프레임을 공유합니다. [oai_citation:26‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9)
## 원 논문(SmoothLLM; Robey et al., 2023)에서의 “patch”
– SmoothLLM은 **문자 단위 랜덤 교란**을 적용하는데, perturbation 함수로 **insert / swap / patch** 등을 둡니다. [oai_citation:27‡OpenReview](https://openreview.net/forum?id=laPAh2hRFC&utm_source=chatgpt.com)
– 이 논문(ijcnlp25)에서 baseline은 **SMOOTHLLM-SWAP/INSERT/PATCH**로 나눠 보고합니다(표에 그대로 존재). [oai_citation:28‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9)
### PATC [oai_citation:29‡ijcnlp25_defending_LLM_against_jailbreak_attacks_via_semantic_smoothing.pdf](sediment://file_000000003ad8720880a35c7741c722e9)\%\))를 선택해 그 구간을 다른 문자(또는 랜덤 문자 시퀀스)로 치환하여 공격 payload(특히 suffix 류)를 깨뜨립니다.
- 원 SmoothLLM 논문은 insert/patch perturbation에서 “suffix의 (q=10\ 는 식으로 공격 문자열의 perturbation instability를 방어로 활용합니다.
왜 “nominal 성능”이 떨어지나?
- 이 ijcnlp25 논문이 명시적으로 말하듯, c token-based 공격(GCG 등)에 강하지만 의미를 훼손해 “불리한 nominal drop”이 생길 수 있고, 그게 SemanticSmooth(semantic-preserving 변환) 동기입니다.
정리: 공격 2개 vs 방어 3개의 포인트
- PAIR: “의미/맥락”을 정교하게 조작하는 자연어 반복개선 공격
- PromptRS: score 기반 **랜덤 탐색으로 jailbreak prompt 6-L7
- LLMFILTER: 응답을 만든 뒤 LLM이 자기 응답을 판정/차단
- ERASE&CHECK: 부분열 전수 검사로 (일정 범위) certifiable safety 지향
- SMOOTHLLM-PATCH: 문자 교란 + smoothing voting으로 공격 문자열 불안정성 이용
답글 남기기