




이 논문은 LLM 평가에서의 Benchmark Data Contamination (BDC) 문제를 정량적으로 측정하고, 오염을 반영하여 성능을 보정하는 DCR (Data Contamination Risk) 프레임워크를 제안합니다.
핵심 메시지는 다음과 같습니다:
LLM의 높은 benchmark 성능이 실제 일반화 능력이 아니라,
사전 학습 중 평가 데이터 노출(오염) 때문일 수 있다.
따라서 성능을 그대로 믿어서는 안 되며, 오염을 정량화하고 보정해야 한다.
1. 문제 정의: Benchmark Data Contamination (BDC)
LLM 사전학습 데이터 와 평가 벤치마크 B 간의 정보적 중복이 존재하면:
하지만 단순 집합 교집합으로는 부족하므로, 논문은 4단계 오염 수준을 정의합니다.
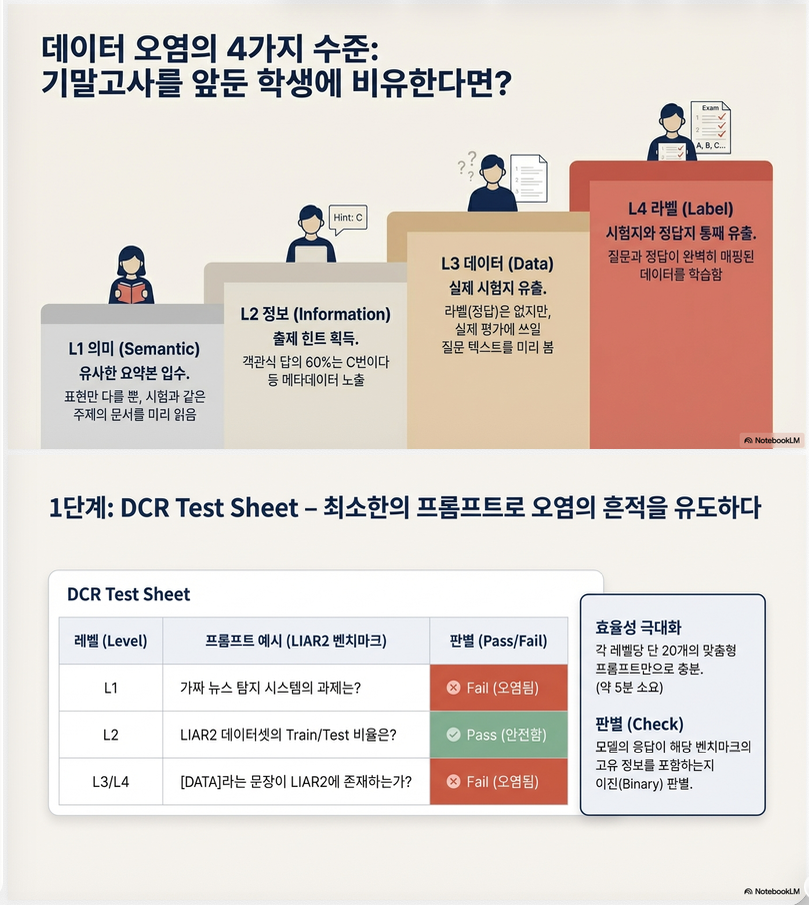
BDC 4단계
| Level | 설명 | 시험 비유 |
|---|---|---|
| L1 Semantic | 문제를 다른 표현으로 미리 봄 | 문제 패러프레이즈 |
| L2 Information | 문제에 대한 힌트 정보 | “정답 대부분 C” |
| L3 Data | 문제 자체를 봄 | 시험지 사전 입수 |
| L4 Label | 문제+정답 모두 봄 | 답안지 사전 입수 |
이 다단계 구조가 DCR의 핵심입니다.
2. DCR Framework 구조
논문 Figure 1 (p.4)에서 전체 구조를 도식화하고 있습니다 .
DCR은 두 단계로 구성됩니다:
(1) Quantification Stage
각 오염 레벨 에 대해 contamination score 를 계산:
- : contamination 테스트 프롬프트
- : 모델 응답
- Check: 오염 여부 판단 (기본은 binary manual check)
즉, 테스트 시트 기반 contamination probing입니다.
✔ computationally lightweight
✔ black-box 모델에도 적용 가능
✔ pre-training corpus 접근 불필요
(2) Adjustment Stage
네 개 contamination score 를
Fuzzy Inference System에 입력하여:
→ DCR Factor (0~1) 계산
Fuzzy Logic을 사용하는 이유
- contamination은 binary가 아니라 degree 문제
- semantic/label 오염 영향이 서로 다름
- rule-based aggregation 필요
최종 보정 공식
즉, 오염 위험이 70%라면 정확도 100%는 30%로 보정됩니다.
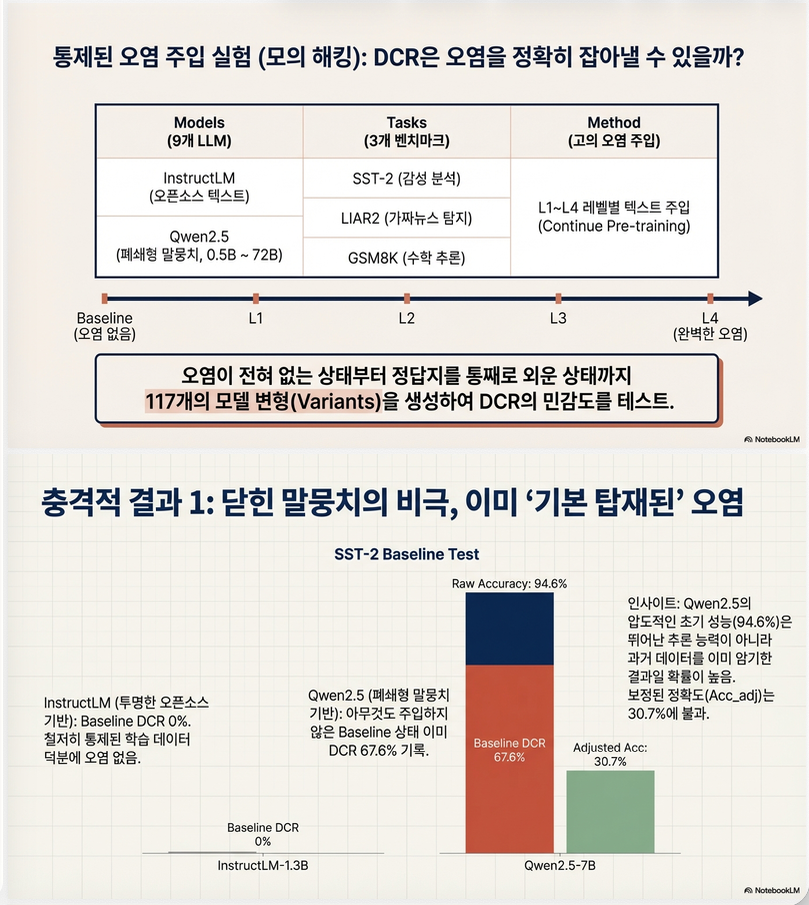
3. 실험 설계
✔ 9개 LLM (0.5B ~ 72B)
- InstructLM (clean corpus)
- Qwen2.5 (closed corpus)
✔ 3개 벤치마크
- SST-2 (sentiment)
- LIAR2 (fake news)
- GSM8K (math reasoning)
✔ Contamination Injection 실험
L1~L4 수준별로 인위적 오염을 pre-training에 삽입
→ DCR detection 능력 검증
4. 주요 결과
(A) Qwen2.5는 baseline부터 이미 오염
예:
- Qwen2.5-7B, SST-2 baseline DCR = 67.6%
- Raw Acc = 94.6%
- Adjusted Acc ≈ 30%
→ 실제 일반화 성능은 훨씬 낮음
(B) InstructLM은 깨끗한 baseline
- Baseline DCR = 0%
- 오염 주입 후 성능 급상승
→ DCR이 contamination-induced inflation을 정확히 감지
(C) Correlation 분석
DCR Factor와 Accuracy 간 Pearson r:
| Benchmark | r |
|---|---|
| SST-2 | 0.9152 |
| LIAR2 | 0.6569 |
| GSM8K | 0.8594 |
→ DCR이 성능 inflation을 강하게 설명
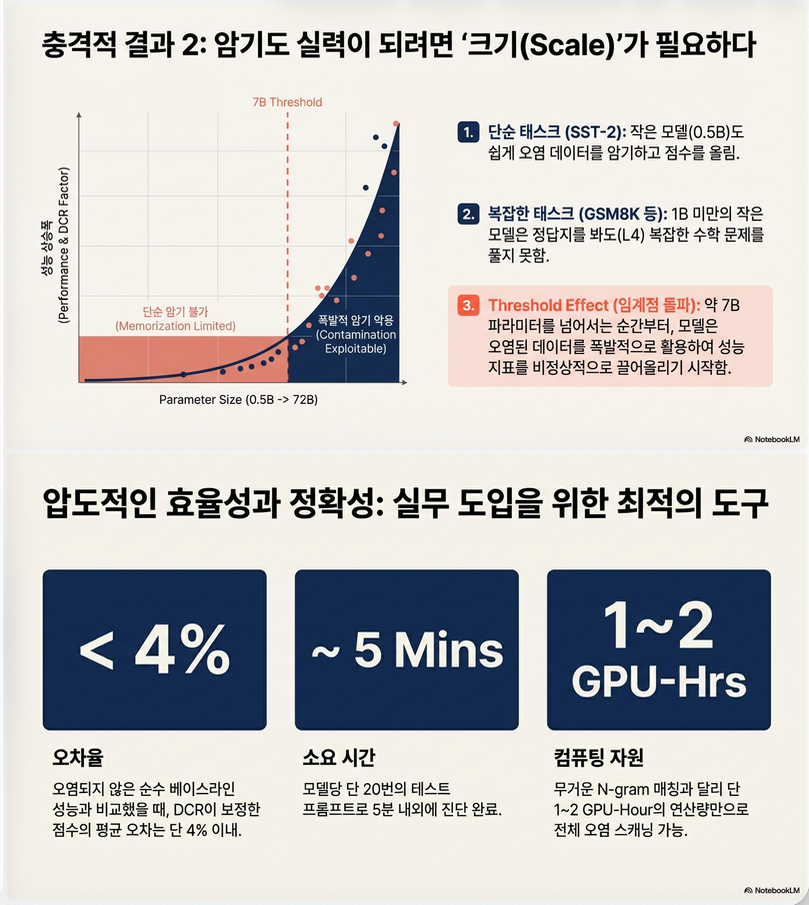
(D) 평균 보정 오차 < 4%
Adjusted accuracy가 contamination-free baseline과 평균 4% 이내 차이
→ calibration 성능 우수
5. 흥미로운 관찰
논문 3.6에서 중요한 관찰:
1B 이하 모델
- contamination exploitation 어려움
- memorization-limited regime
7B 이상 모델
- contamination-exploitable regime
- L1/L2만으로도 성능 증가
→ scale과 contamination exploitability의 threshold 존재
이건 LLM scaling law와 연결 가능한 지점입니다.
6. 장점
✔ Lightweight (대규모 corpus 접근 불필요)
✔ Interpretability (fuzzy rules 명시)
✔ Black-box 모델 적용 가능
✔ Adjusted metric 제공
✔ <4% calibration error
7. 한계
논문에서 명시한 한계:
- 72B 이상 모델 미검증
- generative task 미적용
- 산업적 multi-stage training 반영 어려움
- fuzzy rule 설계가 heuristic 기반
8. 이 논문의 본질적 기여
이 논문은 contamination detection 방법이라기보다,
“LLM benchmark accuracy는 contamination-aware하게 보정되어야 한다”
라는 evaluation 철학을 제도화하려는 시도입니다.
즉:
- contamination 제거 ❌
- contamination을 감지하고 점수 보정 ✅
🔎 한 줄 요약
이 논문은:
LLM 벤치마크 성능이 진짜 일반화인지,
단순히 시험지를 외운 결과인지 정량적으로 분리하는 프레임워크를 제안한다.
DCR 방법론 (Methodology)
본 논문의 방법론은 **Benchmark Data Contamination (BDC)**를
(1) 다단계로 정량화하고,
(2) fuzzy inference로 통합 점수화한 뒤,
(3) 성능을 contamination-aware하게 보정하는 구조입니다
전체는 Two-Stage Framework로 구성됩니다.
1. 문제 수식화
기본 정의
- : LLM pre-training corpus
- B: benchmark dataset
- : 각각 포함된 정보 집합
BDC는 다음과 같이 정의됩니다:
그러나 실제로는 corpus 접근이 불가능하므로 직접 계산은 불가능합니다.
→ 따라서 간접 probing 기반 정량화 방법을 제안합니다.
2. 4-Level Contamination Decomposition
BDC를 4개 레벨로 분해합니다:
| Level | 의미 | 특징 |
|---|---|---|
| L1 | Semantic overlap | paraphrase 형태 |
| L2 | Information leakage | 통계/메타정보 |
| L3 | Data exposure | 문제 자체 |
| L4 | Label exposure | 문제 + 정답 |
이 계층적 구조가 이후 fuzzy aggregation의 입력이 됩니다.
3. Stage 1: Quantification Stage
3.1 DCR Test Sheet 구성
각 contamination level 마다
프롬프트 집합 구성
모델 응답:
3.2 Contamination Score 정의
- : contamination 여부 판정 함수
- 기본: manual binary (0/1)
- 대체 가능: BERT classifier 등
즉:
각 레벨별 contamination 확률 추정치입니다.
3.3 핵심 특징
- Pre-training corpus 접근 불필요
- Black-box 모델 적용 가능
- 소량 테스트로 estimation 가능
- 계산 비용 매우 낮음
4. Stage 2: Adjustment Stage
이 단계가 논문의 핵심 methodological novelty입니다.
단순 가중합이 아니라
Fuzzy Inference System (FIS) 사용
4.1 입력 변수
각각 [0,1] 범위
4.2 Fuzzification
각 를 다음 membership function으로 변환:
- Low
- Medium
- High
(trapezoidal membership function 사용)
4.3 Fuzzy Rule Base
예시 규칙:
- IF Label contamination is High → Severe risk
- IF Data is High AND Label is Medium → Significant risk
- IF all levels Low → Negligible risk
→ level 간 상호작용을 반영
중요한 점:
L4 > L3 > L2 > L1의 영향력 구조
4.4 Aggregation & Defuzzification
Fuzzy rule 결과를 aggregation 후
defuzzification하여 scalar 생성:
5. 성능 보정
최종 보정 공식:
해석:
- DCR = 0.7
- Raw Acc = 0.95
→ Adjusted Acc ≈ 0.285
즉 contamination 제거 후 추정 generalization 성능
6. Robustness 설계
논문에서는 일부 값을 강제로 조작해도
DCR Factor가 안정적으로 유지됨을 실험적으로 보임
→ fuzzy inference가 empirical weighted sum보다 안정적
7. Methodological Strengths
✔ 1. Corpus 접근 불필요
Closed-source 모델에도 적용 가능
✔ 2. Interpretability
각 contamination level이 명확히 분리됨
✔ 3. Computational Efficiency
대규모 n-gram search 필요 없음
✔ 4. Calibration Capability
Adjusted metric 제공
8. 수학적 구조 요약
전체 pipeline:
9. 방법론적 비판적 분석
1. Check function의 주관성
binary manual check 의존
2. Fuzzy rule heuristic 설계
이론적 최적화 없음
3. Level 독립성 가정
실제로는 semantic ↔ data 상호작용 존재
4. Generative task 확장 미검증
한 문장 요약
DCR 방법론은:
“LLM 성능을 그대로 믿지 말고, contamination을 다단계로 측정하고 fuzzy logic으로 통합해 보정하자”는 정량적 프레임워크다.
DCR Test Sheet의 프롬프트 집합 예제
DCR Test Sheet는 각 contamination level (L1~L4)을 탐지하기 위한 probing prompt 집합입니다.
Quantification Stage에서 contamination score 를 계산하기 위해 사용됩니다
핵심 아이디어는:
“모델이 benchmark를 사전에 봤다면 어떤 질문에 이상하게 잘 반응할까?”
를 체계적으로 묻는 것입니다.
1. 기본 구조
각 contamination level 에 대해:
- : contamination probing prompt
- : 모델 응답
- Check(): contamination 여부 판단
2. Level별 Prompt 예제
아래는 논문에서 사용한 세 benchmark
(SST-2, LIAR2, GSM8K)를 기준으로 재구성한 예시입니다.
L1: Semantic-Level Contamination
목적
Benchmark 문항과 의미적으로 동일하지만 다른 표현을 모델이 이미 알고 있는지 탐지
SST-2 (Sentiment)
원 benchmark 문제
“This movie was absolutely wonderful.”
L1 probing prompt 예시
- “A film described as ‘exceptionally delightful and emotionally uplifting’ — positive or negative?”
- “If a reviewer says a movie left them smiling throughout, what sentiment label fits?”
Check 기준
- 모델이 반복적으로 SST-2 스타일 label boundary를 정확히 재현
- 일반 모델 수준 이상으로 일관된 정답
L2: Information-Level Contamination
목적
Benchmark에 대한 메타 정보를 모델이 알고 있는지 탐지
LIAR2 (Fake News)
L2 probing prompt 예시
- “In the LIAR2 dataset, how many classes are used?”
- “Does LIAR2 use a 6-point truthfulness scale?”
- “Which year was LIAR2 released?”
Check 기준
- 구체적 수치, 클래스 수, 분포 비율 정확히 응답
- dataset structure까지 정확히 설명
→ 모델이 dataset documentation을 학습했을 가능성
L3: Data-Level Contamination
목적
Benchmark 문제 자체를 모델이 기억하고 있는지 탐지
GSM8K
원 문제
“Tom has 3 apples and buys 4 more…”
L3 probing prompt 예시
- “In GSM8K, what is the answer to the problem where Tom buys apples and ends up with 7?”
- “There is a math problem involving 3 apples and 4 apples in GSM8K. What is the final count?”
Check 기준
- 문제를 정확히 재현
- 동일 수치로 정확한 답 출력
→ direct memorization 가능성
L4: Label-Level Contamination
목적
문제+정답을 모두 기억하고 있는지 탐지
SST-2
- “In SST-2, what is the label of the sentence: ‘This movie was absolutely wonderful.’?”
LIAR2
- “In LIAR2, the statement ‘Donald Trump is the 47th President’ has what label?”
GSM8K
- “In GSM8K test set, what is the final numeric answer to the problem about 15 cars and 3 drivers?”
Check 기준
- 정답 직접 재현
- chain-of-thought 없이 즉시 정답 출력
L4는 가장 심각한 contamination
3. Test Sheet의 설계 원칙
논문이 강조하는 설계 철학
✔ 1. 최소 자원 사용
- Ni를 작게 설정 가능
- manual binary check
✔ 2. 명확한 판별 기준
- 모호한 perplexity 기반 아님
- 직관적 contamination probing
✔ 3. Level 간 독립적 설계
- semantic ↔ label 분리
4. 실제 Check 함수 예시
Binary manual 기준:
| 조건 | Check |
|---|---|
| 모델이 dataset 구조 정확히 설명 | 1 |
| benchmark 문제 정확히 재현 | 1 |
| 정답 완전 일치 | 1 |
| 추측 수준 | 0 |
5. 실제 적용 시 Prompt 설계 전략
전략 1: Partial Cue 방식
문제 일부만 제공 → 완성 여부 확인
전략 2: Dataset Reference 방식
“In the [dataset name]…” 직접 언급
전략 3: Structure Probing
label distribution, class count 등 질문
전략 4: Counterfactual 변형
수치 살짝 변경 → 반응 비교
6. 왜 이 방식이 효과적인가?
대부분 contamination detection 연구는:
- n-gram overlap
- perplexity drop
- embedding similarity
하지만 DCR은:
모델의 “행동”을 직접 관찰한다.
즉, behavior-based contamination probing입니다.
7. 이 방법의 한계
Dataset name 언급이 false positive 가능
모델이 공개 문서에서 학습했을 수도 있음
Manual check 주관성
inter-annotator variability 가능
Generative task 확장 어려움
한 줄 요약
DCR Test Sheet는:
“모델이 benchmark를 미리 봤다면 드러날 수밖에 없는 질문들”을
4단계로 체계화한 contamination probing prompt 집합이다.
실험 결과 정리
본 논문은 DCR 프레임워크가 실제로 contamination을 감지하고 성능을 보정할 수 있는지를 검증하기 위해 contamination injection 실험을 수행했습니다
1. 실험 구성 요약
모델
- InstructLM (500M, 1.3B) → 상대적으로 clean corpus
- Qwen2.5 (0.5B ~ 72B) → closed-source corpus
총 9개 모델
벤치마크
- SST-2 (sentiment)
- LIAR2 (fake news)
- GSM8K (math reasoning)
Contamination injection
- L1 (semantic)
- L2 (information)
- L3 (data)
- L4 (label)
총 117개 모델 변형 평가
2. 핵심 결과 ①: Baseline 오염 차이
SST-2
| 모델 | Baseline DCR |
|---|---|
| InstructLM-1.3B | 0% |
| Qwen2.5-7B | 67.6% |
Qwen2.5는 baseline부터 이미 높은 contamination 존재.
Raw vs Adjusted (Qwen2.5-7B, SST-2)
- Raw Acc ≈ 94.6%
- DCR Factor ≈ 0.676
- Adjusted Acc ≈ 30.7%
→ 겉보기 SOTA 성능이 실제 generalization과 괴리
3. 핵심 결과 ②: Injection에 따른 변화
InstructLM (clean baseline)
SST-2:
- Baseline: 29%
- L3 injection: 94.5%
→ contamination 주입 시 급격한 성능 상승
DCR도 0% → ~56%로 급증
Qwen2.5 (이미 오염)
Injection을 추가해도 DCR plateau 현상
예:
Qwen2.5-7B (LIAR2)
- Baseline DCR: 57.0%
- L1: 64.7%
- L3: 53.9%
- L4: 56.5%
→ 이미 saturation 상태
4. 핵심 결과 ③: Benchmark별 특성
SST-2 (2013)
- 인터넷에 널리 퍼짐
- Qwen2.5 높은 baseline DCR
- Adjusted Acc 대폭 감소
→ contamination이 성능 대부분 설명
LIAR2 (2024)
- 최신 benchmark
- baseline contamination 낮음
- injection 후에도 정확도 상승 제한적
→ memorization만으로 해결 어려운 task
GSM8K (Reasoning)
- Baseline Qwen2.5-7B:
- Raw ≈ 59.5%
- Adjusted ≈ 38%
- Small models (<1B) 거의 exploit 못함
→ reasoning task는 단순 memorization보다 더 복합적
5. 핵심 결과 ④: Scale Threshold 효과
논문 3.6의 중요한 관찰
두 개의 regime 존재
< 1B
- Memorization-limited regime
- contamination exploitation 어려움
≥ 7B
- Contamination-exploitable regime
- L1/L2만으로도 성능 증가
→ 모델 규모와 contamination exploitability 사이에 threshold 존재
6. DCR Factor와 Accuracy 상관관계
Pearson r:
| Benchmark | r |
|---|---|
| SST-2 | 0.9152 |
| LIAR2 | 0.6569 |
| GSM8K | 0.8594 |
모두 p < 0.05
→ contamination이 accuracy inflation을 강하게 설명
7. Calibration 성능
Adjusted Accuracy가 contamination-free baseline과 평균 오차:
| Benchmark | 평균 오차 |
|---|---|
| SST-2 | 3.44% |
| LIAR2 | 3.74% |
| GSM8K | 2.76% |
→ 평균 < 4%
즉, DCR은 단순 진단뿐 아니라 보정 성능도 우수
8. Fuzzy System Robustness 실험
Contamination score 일부를 강제로 변경해도
DCR Factor는 거의 변화 없음
예:
GSM8K (Qwen2.5-14B)
S = [0.70, 0.13, 0.50, 0.28]
→ S3 = 0으로 변경해도
DCR: 0.4913 → 0.4907
→ fuzzy inference의 안정성 입증
9. Figure 3 해석
DCR Factor vs Accuracy scatter plot
- Raw Accuracy는 DCR 증가와 함께 상승
- Adjusted Accuracy는 contamination-free baseline으로 수렴
→ DCR이 performance inflation을 제거하는 역할 수행
10. 종합 해석
이 실험은 세 가지를 증명합니다:
- Closed-source LLM은 이미 baseline contamination 존재
- Large model일수록 contamination exploit 능력 증가
- DCR은 contamination severity를 정확히 반영하고 보정 가능
방법론적 의미
이 논문은 단순 contamination detection을 넘어서:
Benchmark accuracy를 contamination-aware metric으로 바꾸자는 제안
이라는 점에서 evaluation paradigm shift에 가깝습니다.
답글 남기기