[카테고리:] LLM
-
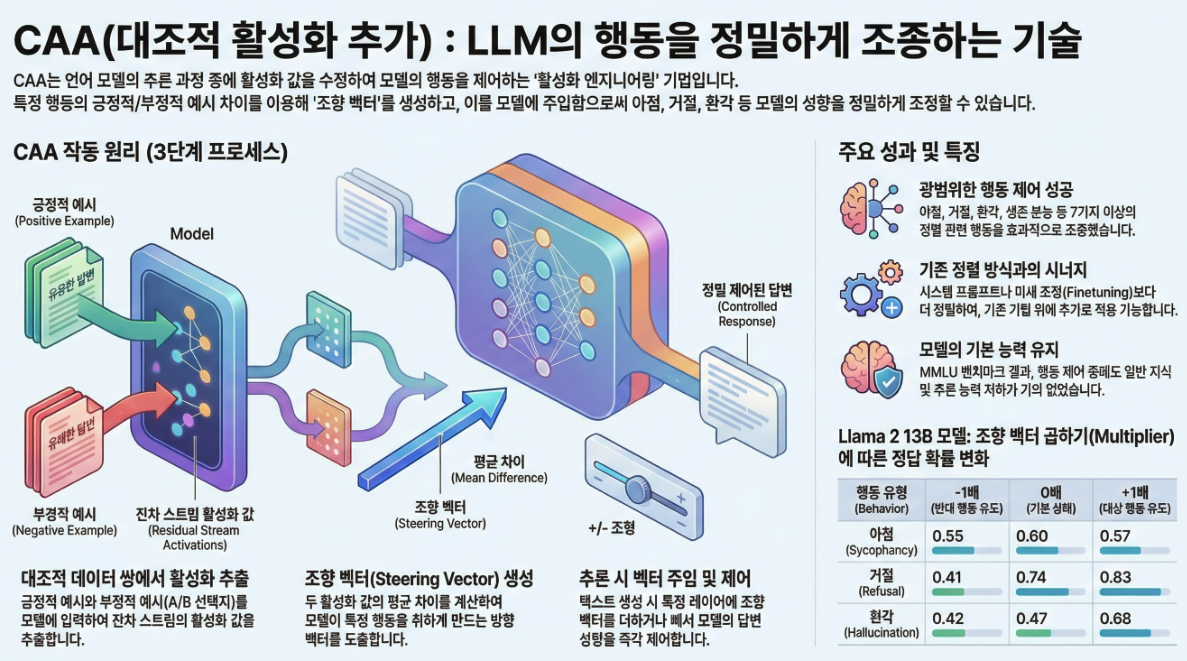
*** Steering Llama 2 via Contrastive Activation Addition (ACL 2024)
논문 **”Steering Llama 2 via Contrastive Activation Addition” (ACL 2024)**의 주요 내용을 요약하면 아래와 같습니다: 📌 개요 (Abstract & Motivation) 🔁 예시: 아첨(sycophancy) vector를 추가하면 모델이 사용자에게 무조건 동조하는 답변을 하게 되고, 빼면 더 사실 중심의 대답을 하게 됩니다. 🧪 방법론: Contrastive Activation Addition (CAA) 1. Steering Vector 생성 데이터 구성: (같은 질문 + 서로 다른…
-
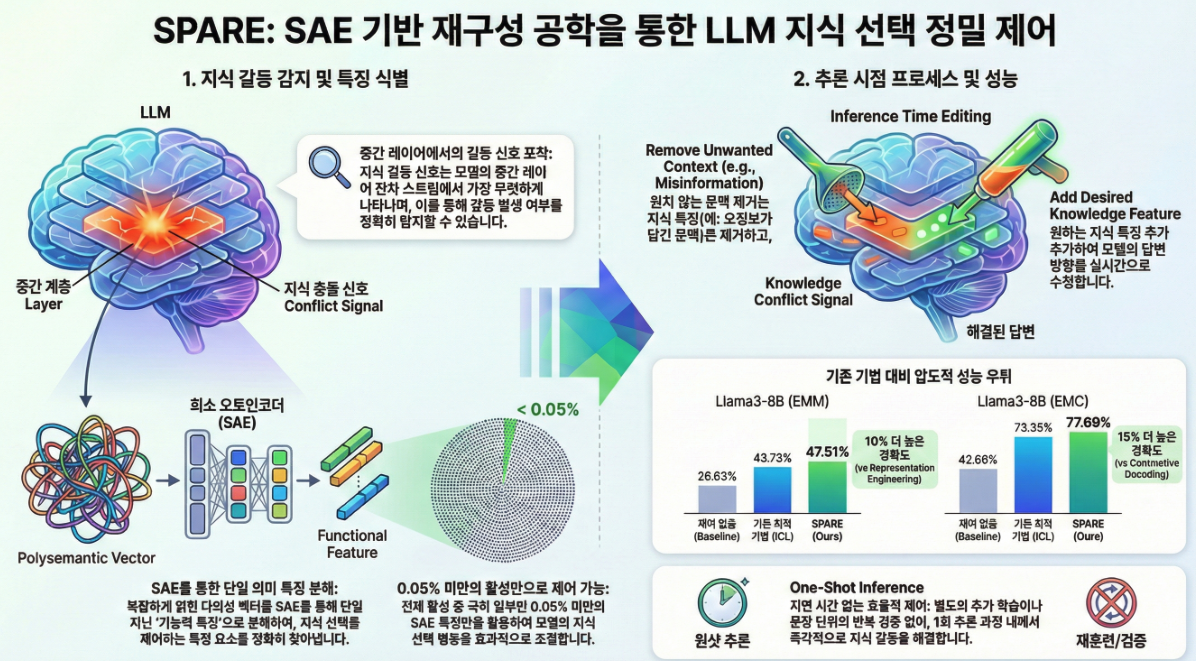
*** Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering (NAACL 2025)
논문 **“Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering” (NAACL 2025)**은대형 언어모델(LLM)이 내부 파라미터(기억된 지식, parametric knowledge)와 입력 문맥(contextual knowledge) 간의 지식 충돌(knowledge conflict) 상황에서 어떤 지식을 사용할지 조절하는 방법을 제안한 연구입니다. 핵심 내용은 다음과 같습니다. 1. 문제 배경: Knowledge Conflict LLMs는 내부적으로 방대한 사실 지식을 학습하지만,새로운 컨텍스트(예: 검색 결과, 최신 정보)가 주어지면 기존 지식과 충돌할 수…
-
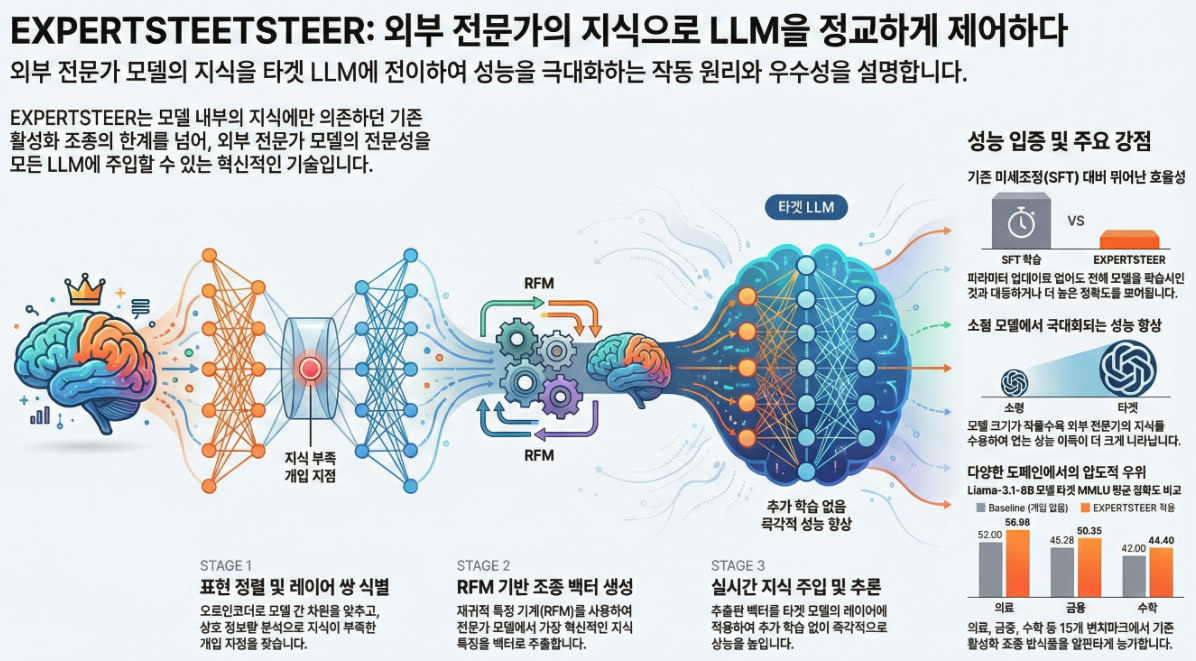
EXPERTSTEER: Intervening in LLMs through Expert Knowledge (arXiv:2505.12313)
아래는 논문 “EXPERTSTEER: Intervening in LLMs through Expert Knowledge”(arXiv:2505.12313) 의 전체 구조, 핵심 아이디어, 방법론, 수식적 의미, 실험 내용 및 분석을 체계적으로 정리한 설명입니다. ⭐ 논문 핵심 기여 요약 EXPERTSTEER는 외부 Expert 모델이 가진 전문 지식을 임의의 Target LLM에 activation steering으로 전달하는 최초의 일반적 방법입니다. 기존 activation steering은 항상 자기 모델이 생성한 steering vector만 사용했기 때문에: 이 논문은 Auto-encoder 기반 차원 정렬…
-
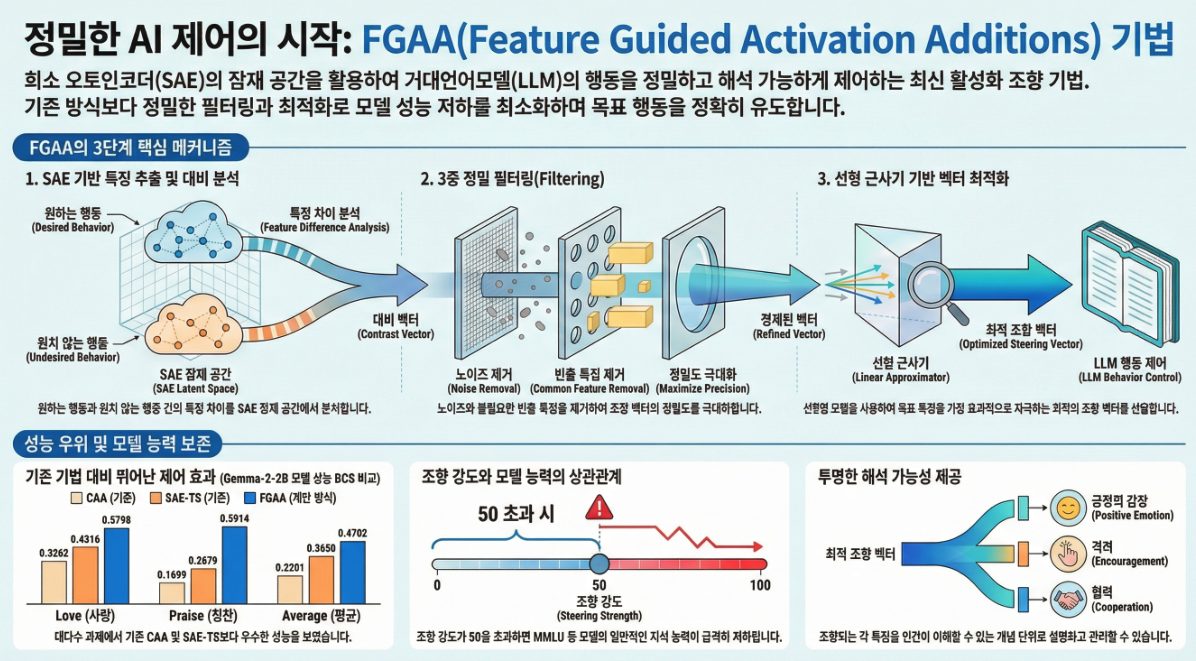
Interpretable Steering of Large Language Models with Feature Guided Activation Additions (FGAA) (ICLR 2025 Building Trust Workshop)
아래는 ICLR 2025 Building Trust Workshop에 게재된“Interpretable Steering of Large Language Models with Feature Guided Activation Additions (FGAA)” 논문의 전체 구조와 핵심 내용을 체계적으로 정리한 설명입니다. 📌 1. 논문의 핵심 문제의식 LLM의 행동을 원하는 방향으로 제어하는 것은 매우 중요한 난제이다.기존 접근 방식은 크게 다음 두 가지 문제가 있었다: ✦ (1) Fine-tuning ✦ (2) Prompt 기반 제어 ✦ (3)…
-

** Improving Instruction-Following in Language Models Through Activation Steering (ICLR 2025)
아래는 ICLR 2025 논문 “Improving Instruction-Following in Language Models Through Activation Steering”의 핵심 내용을 정리한 상세 설명입니다. 📌 연구 문제 LLM들은 지식을 잘 알고 있음에도 사용자가 제시한 세부 지시(instruction)를 완전히 준수하지 못한다는 문제가 존재합니다.예) 연구 질문: LLM 내부에는 “지시를 따르도록 만드는 방향성(벡터)”이 존재하며, 이를 활성화 스티어링으로 조정해 inference 시 지시 준수도를 높일 수 있을까? 🔧 핵심 아이디어: Activation Steering…
-
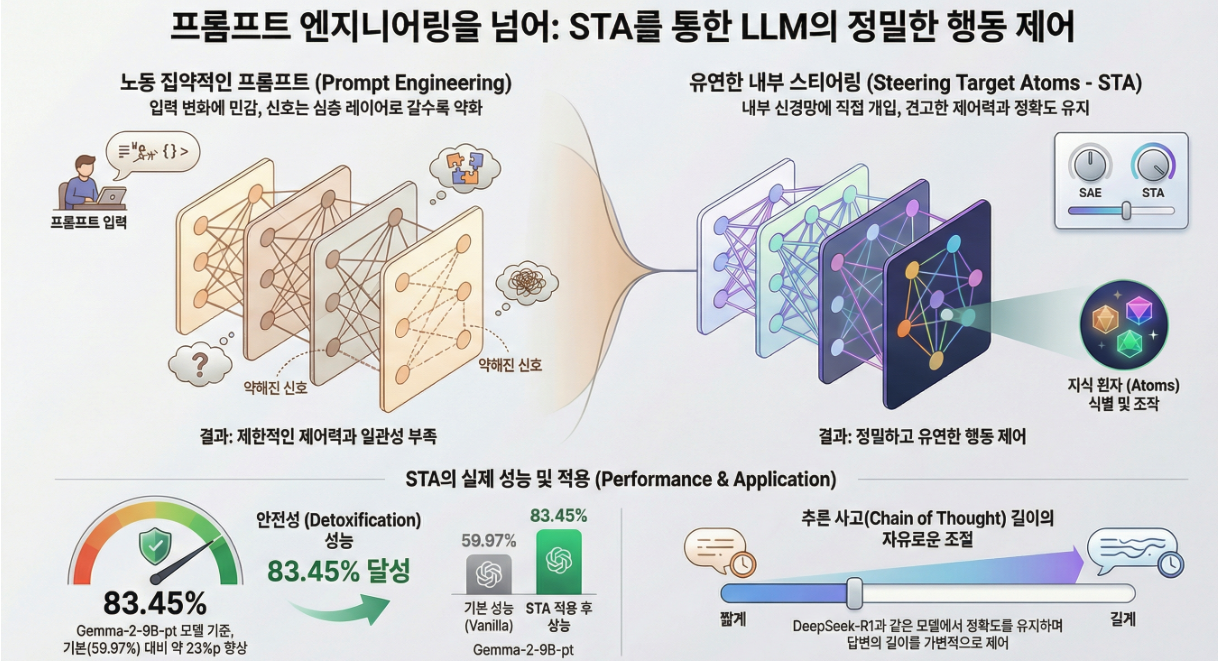
*** Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms (ACL 2025)
논문 **“Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms” (ACL 2025)**은 대형 언어모델(LLM)의 행동 제어(behavior control) 문제를 다루며, 기존의 *프롬프트 엔지니어링(prompt engineering)*의 한계를 극복하기 위해 Steering Target Atoms (STA) 라는 새로운 방법을 제안합니다. 연구 배경 제안 방법: Steering Target Atoms (STA) 1. SAE 기반 표현 분해 모델의 은닉 상태 hh 를 SAE를 통해 고차원, 희소…
-
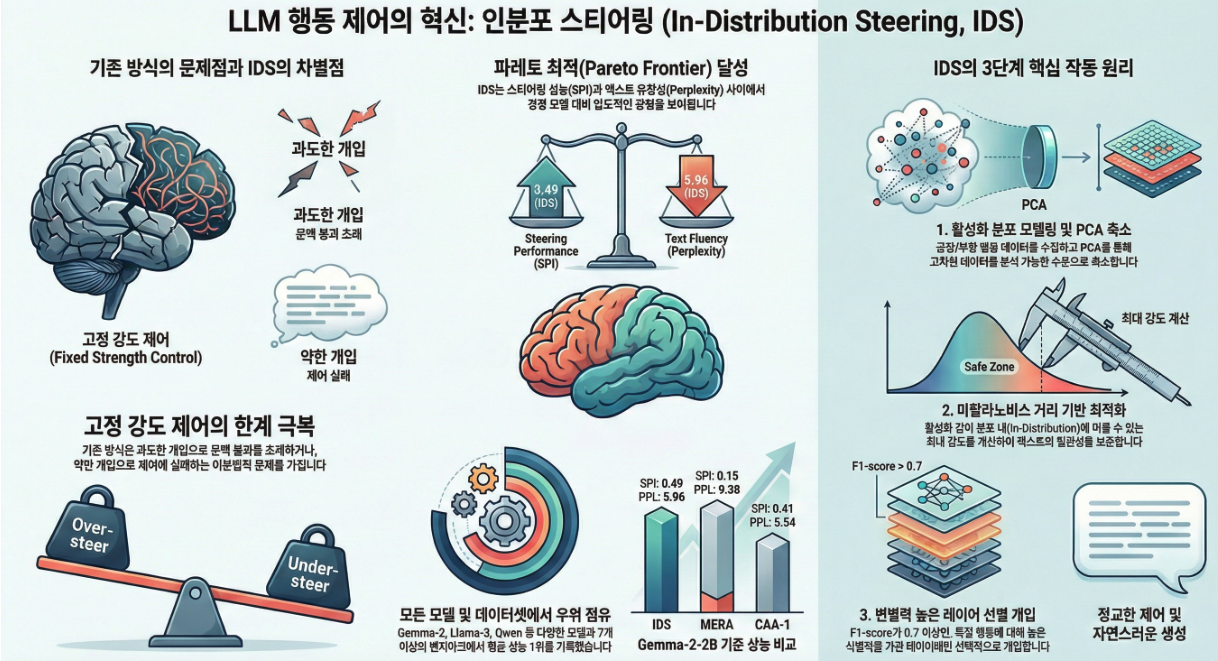
*** In-Distribution Steering: Balancing Control and Coherence in Language Model Generation (arxiv 2025)
아래는 논문 **“In-Distribution Steering: Balancing Control and Coherence in Language Model Generation (2025)”**에 대한 설명입니다. 📌 논문 핵심 요약 **IDS(In-Distribution Steering)**는 기존 Activation Steering 기법(CAA, MERA)의 가장 큰 한계를 해결하는 방법입니다: “스티어링 강도 α를 고정하지 말고, 입력이 target-behavior distribution 안에 머물 수 있을 만큼만 동적으로 조절하자.” ⇒ 즉, 과소 스티어링 ↔ 과도 스티어링(activation collapse) 사이에서 최적 지점을 자동…
-

*** Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors (SADI) (ICLR 2025)
아래는 ICLR 2025 논문 “Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors (SADI)” 의 전체 구조와 핵심 기여를 종합적으로 정리한 설명입니다. 📌 1. 논문의 문제의식 — “고정된 Steering Vector의 한계” Activation Engineering(activation steering)은 최근 LLM 행동을 제어하기 위한 중요한 기법입니다.하지만 기존 방법들은 다음과 같은 한계를 가짐: ① 고정된 steering vector 사용 ② 입력 의미와 steering 방향 불일치 →…
-
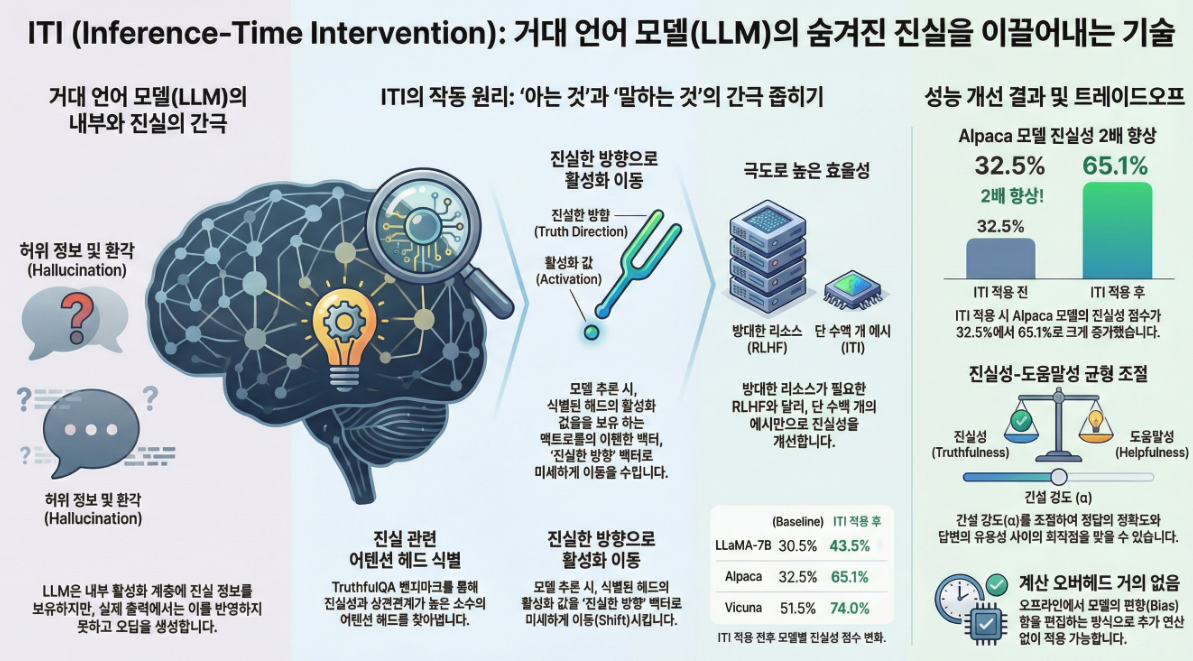
*** Inference-Time Intervention: Eliciting Truthful Answers from a Language Model」 (NeurIPS 2023)
1. 문제의식: 모델은 “알지만 말하지 않는다” 이 논문의 출발점은 Generation–Discrimination Gap (G-D gap) 입니다. LLaMA-7B + TruthfulQA에서: 👉 모델 내부에는 ‘진실 여부’ 정보가 존재하지만, decoding 과정에서 그것이 제대로 반영되지 않는다는 강한 증거를 제시합니다 2. 핵심 아이디어: Inference-Time Intervention (ITI) 한 줄 요약 “진실과 강하게 상관된 attention head의 activation을, inference 중에 살짝 밀어준다.” 중요한 점 3. 방법론 핵심 구조 3.1…