[카테고리:] Circuit Discovery
-
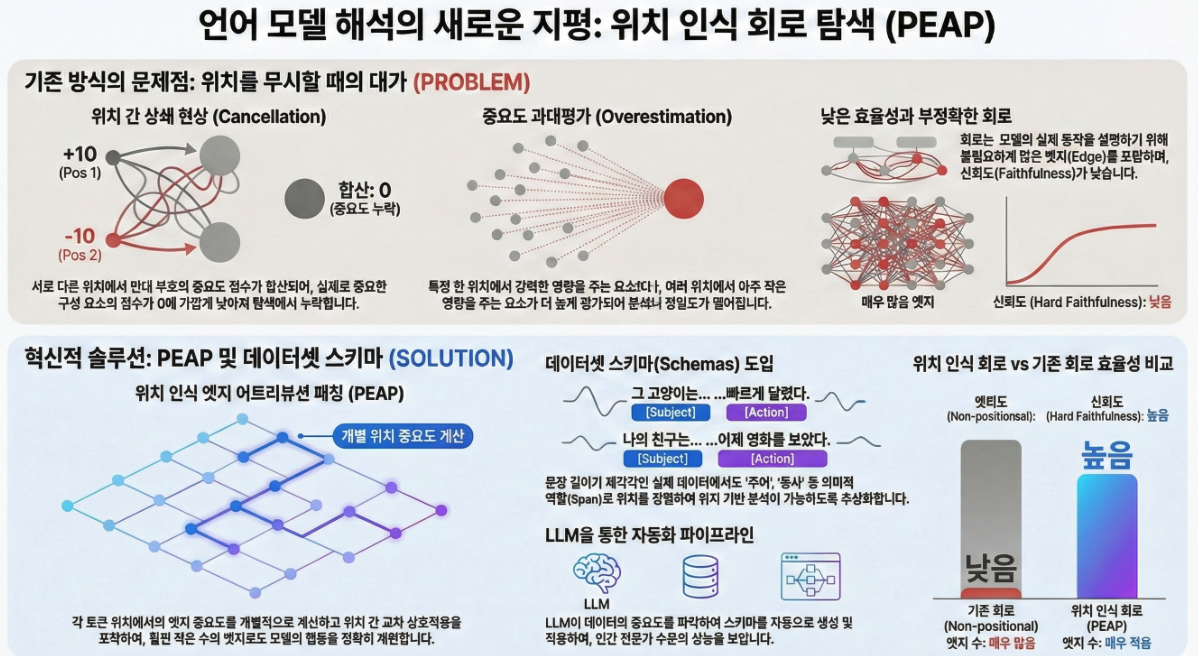
*** Position-aware Automatic Circuit Discovery (ACL 2025)
아래는 ACL 2025 논문 “Position-aware Automatic Circuit Discovery (PEAP)” 전체 내용을 기반으로 한 논문 설명입니다. 📌 Position-aware Automatic Circuit Discovery — 논문 전체 설명 1. 논문 문제의식 (Why?) 기존 자동 circuit discovery 기법(EAP, direct patching 등)은 “position-invariant” 가정을 한다. 즉, 이로 인해 이 문제를 해결하기 위해 저자들은 **“Position-aware Edge Attribution Patching (PEAP)”**을 제안한다. 2. 제안…
-
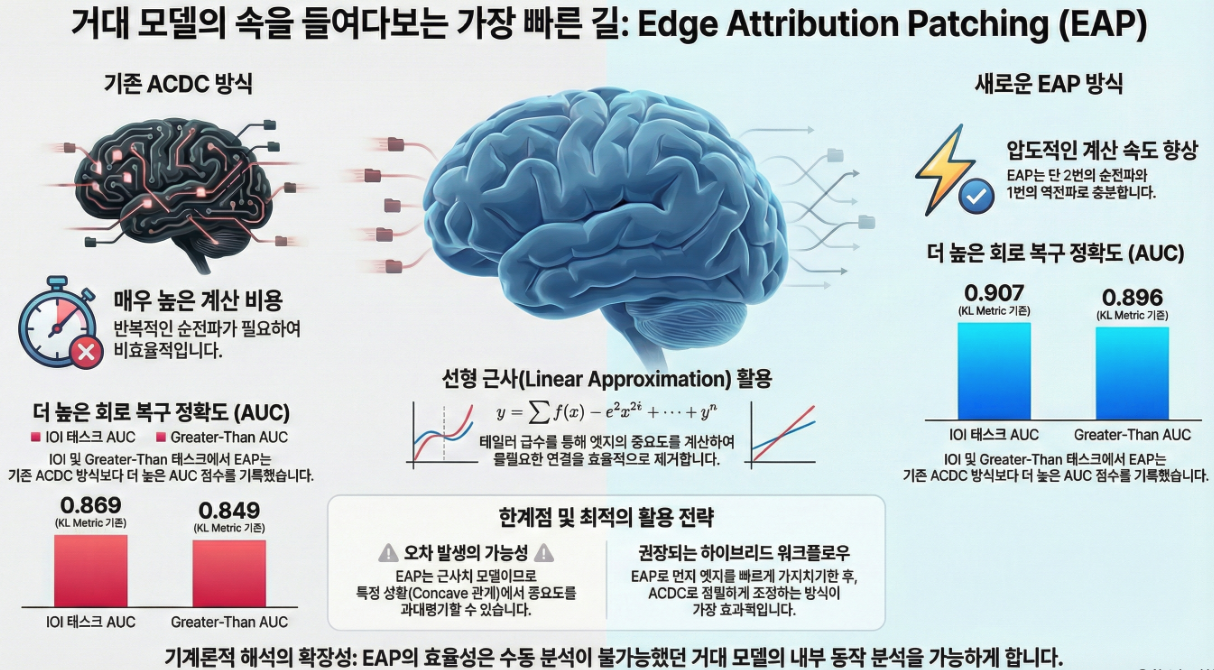
*** Attribution Patching Outperforms Automated Circuit Discovery (BlackboxNLP 2024)
아래는 **BlackboxNLP 2024 논문 〈Attribution Patching Outperforms Automated Circuit Discovery〉**의 핵심 내용을 구조적으로 정리한 상세 설명입니다. 1. 논문의 문제의식 (Introduction) 메커니스틱 인터프리터빌리티의 핵심 목표는 LLM 내부에서 특정 작업(Task)을 수행하는 서브네트워크(circuit)를 자동으로 찾아내는 것이다. 기존 자동화된 방법의 대표는 **ACDC (Automated Circuit Discovery)**로, 각 *edge(노드 간의 activation flow)*가 해당 작업에 얼마나 기여하는지 activation patching을 반복적으로 수행해 측정한다.…
-
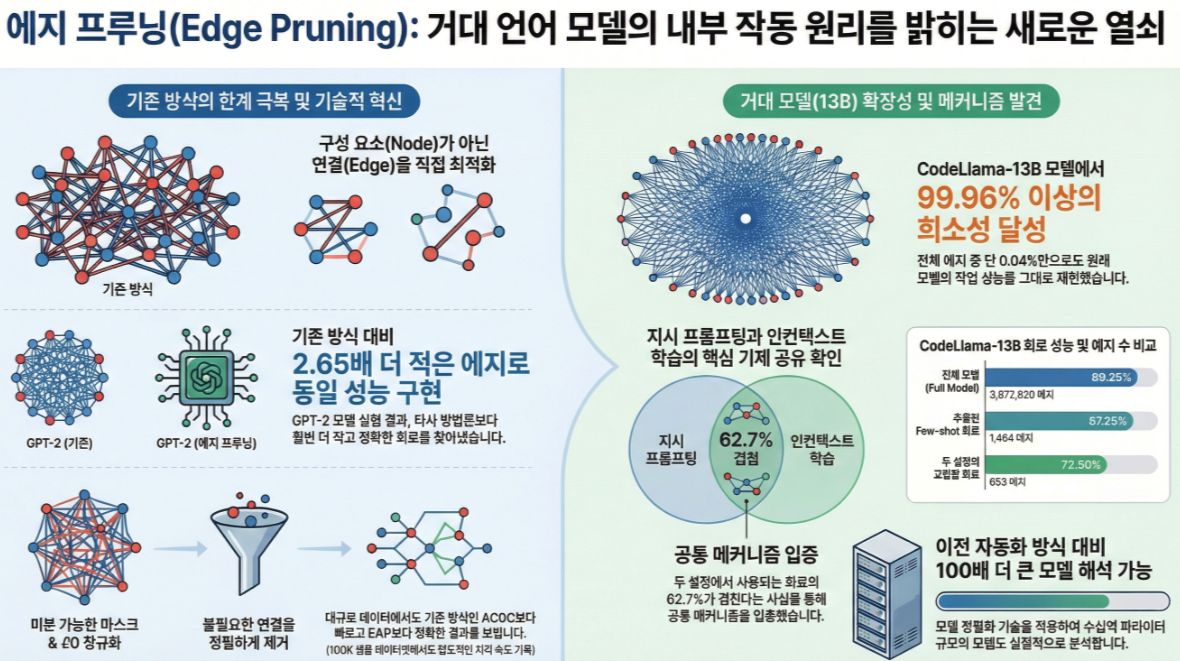
* Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)
아래는 논문 **“Finding Transformer Circuits with Edge Pruning (NeurIPS 2024)”**의 핵심 내용을 직관적으로, 기존 ACDC/EAP과의 차이를 중심으로, 수식·개념까지 포함해 정리한 설명입니다. 🔍 1. 연구 배경: 왜 Edge Pruning인가? Transformer의 동작을 해석하려면 모델 내부에서 특정 기능을 수행하는 회로(circuit) 를 찾아야 한다. 기존 자동 회로 추출 방식에는 두 가지 대표적 접근이 있다: (1) ACDC (2023) (2) EAP…
-
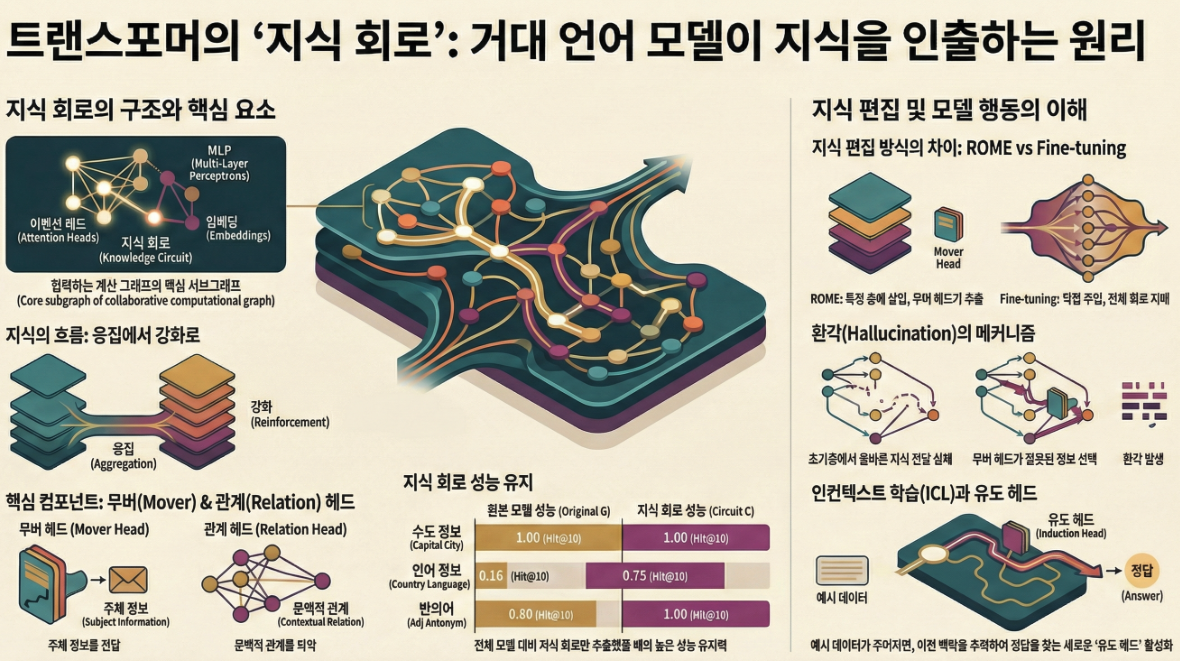
* Knowledge Circuits in Pretrained Transformers (NeurIPS 2024)
다음은 NeurIPS 2024에 발표된 “Knowledge Circuits in Pretrained Transformers” 논문의 주요 내용 요약입니다. 이 논문은 LLM 내부의 지식 저장 메커니즘을 **회로(circuit)**의 관점에서 새롭게 분석한 연구입니다. 1. 연구 배경 2. Knowledge Circuit의 정의 3. 연구 방법론 (1) Knowledge Circuit 탐색 (2) 모델 및 데이터 4. 주요 실험 결과 (1) Knowledge Circuit의 성능 Knowledge Type Original (Hit@10)…
-
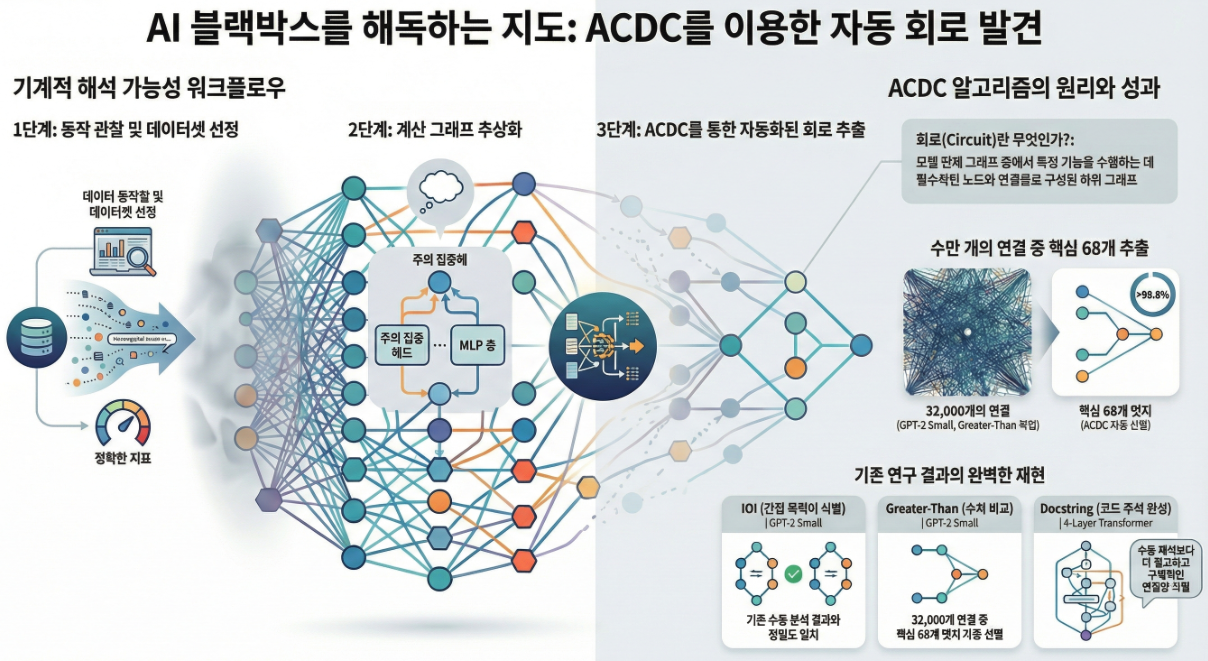
*** Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)
아래는 **“Towards Automated Circuit Discovery for Mechanistic Interpretability (NeurIPS 2023)”**의 핵심 내용을 정리한 설명입니다. 📌 논문의 목적 Transformer 기반 LLM은 뛰어난 성능에도 불구하고 내부 동작이 블랙박스처럼 보입니다. 메커니스틱 인터프리터빌리티 연구는 내부 컴포넌트(Attention Head, MLP 등)가 구체적으로 어떤 알고리즘을 수행하는지 밝히려고 하지만, 현재는 사람이 일일이 수작업으로 분석하는 방식이라 확장성이 떨어집니다. 이 논문은 그 과정을 체계화하고 특히…