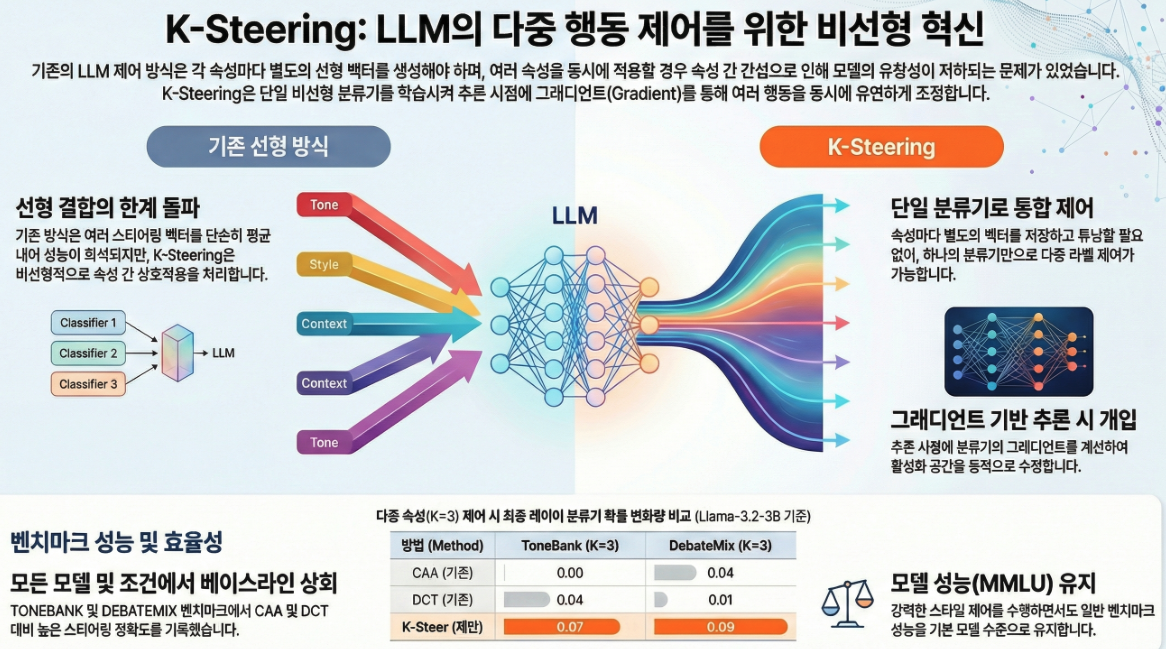
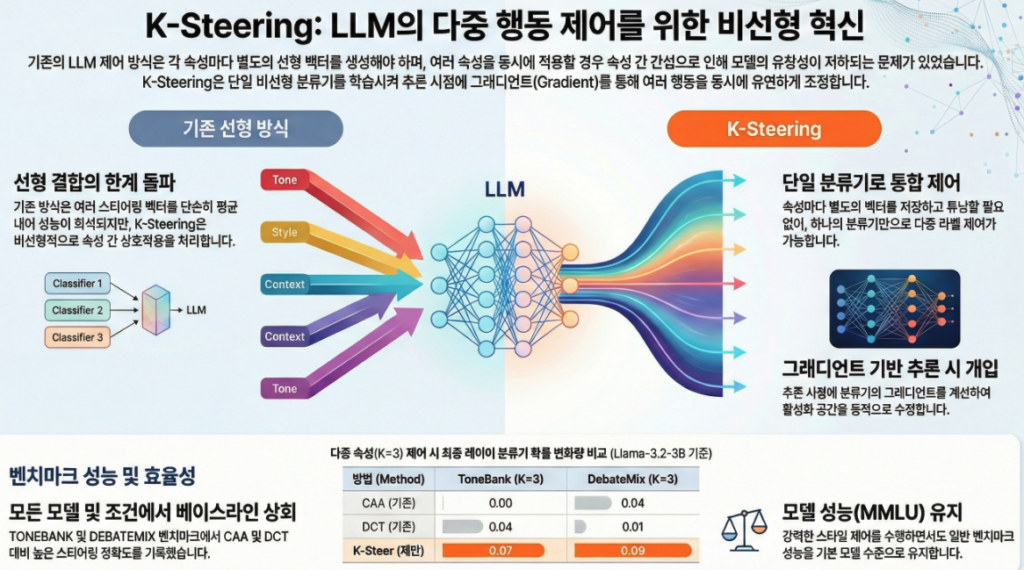
논문 “Beyond Linear Steering: Unified Multi-Attribute Control for Language Models” (EMNLP 2025 Findings) 은 LLM의 복수 속성(behavioral attribute) 제어를 위한 새로운 비선형 스티어링 방법인 K-Steering 을 제안한 연구입니다. 아래에 주요 내용을 정리했습니다.
1. 연구 배경
기존의 Activation Steering (예: CAA, ITI, RepE 등)은 LLM의 은닉 표현(activation)을 선형 벡터로 조작하여 특정 속성(예: 공격성, 공손함, 진실성 등)을 제어하지만,
- 대부분 단일 속성(single attribute) 제어에 국한되고,
- 선형성 가정(linearity assumption) 때문에 다중 속성 조합 시 간섭(interference) 문제가 발생합니다.
예: “공손하면서 유머러스한 톤”처럼 복합적인 조합은 단순 벡터 합으로는 제대로 표현되지 않음.
2. 제안 방법: K-Steering
(1) 기본 아이디어
- 모델의 은닉 활성값 에 대해
비선형 MLP 분류기 를 학습하여 K개의 속성(톤, 스타일 등)을 예측. - 추론 시, 이 분류기의 gradient 를 이용해 활성값을 수정함으로써
모델 출력을 특정 속성으로 유도함.
- : 타깃 속성의 logit을 높이고 회피 속성의 logit을 낮추는 손실
- : 스케일 팩터 (스티어링 강도 조절)
(2) 알고리즘 요약
Algorithm 1: Iterative Gradient-based Steering
- 여러 단계로 gradient를 반복 적용 (decay 포함)
- 타깃 속성 ↑, 회피 속성 ↓
- 시퀀스 전체 평균을 통해 문맥 수준의 속성 제어 수행
Algorithm 2: Projection Removal
- 회피 속성 제거 전용 (directional ablation 대체)
- gradient 방향을 이용해 해당 속성 방향 성분을 제거 (Householder reflection 사용)
→ 비선형 공간에서 속성 경계로부터 “멀어지게” 만듦.
3. 데이터셋
두 개의 새로운 다중 속성 제어 벤치마크를 제작:
- TONEBANK — 6가지 대화 톤 (예: expert, empathetic, casual, cautious, concise 등)
- DEBATEMIX — 10가지 논쟁 스타일 (예: reductio, analogy, moral framing 등)
GPT-4o-Mini를 사용해 자동 생성, 각 문장은 여러 톤/스타일로 응답 가능하도록 설계.
4. 실험 설정
- 모델: Llama-3.2-3B-Instruct, Mistral-7B-Instruct-v0.3, OLMo-2-7B-Instruct
- 비교대상:
- CAA (Contrastive Activation Addition)
- DCT (Deep Causal Transcoding)
모든 방법에서 스티어링 강도 는 GPT-4o-Mini 기반 이진 탐색(binary search) 로 최적화.
5. 주요 결과
| Dataset | Method | 평균 속성 제어 향상 (Δprob) |
|---|---|---|
| TONEBANK | CAA | 0.11~0.13 |
| DCT | 0.13~0.18 | |
| K-Steer | 0.17~0.37 | |
| DEBATEMIX | CAA | 0.02~0.24 |
| DCT | 0.16~0.32 | |
| K-Steer | 0.25~0.56 |
- K-Steering은 대부분의 모델 및 속성 조합에서 CAA/DCT 대비 향상된 제어력을 보임.
- MMLU 성능에서도 원래 모델 성능을 유지(≈ base 0.57).
6. 세부 분석
(1) Multi-layer Steering
- 하나의 층에서 학습된 분류기로 모든 레이어에 적용 가능
- 중간층(layer 14)이 가장 효과적 (score 0.86)
(2) Multi-step Steering
- 작은 α에서는 여러 단계의 gradient 적용이 부드럽게 성능 향상
- 큰 α에서는 coherence 급락 → 최적 단계 수 2~8회
(3) Projection Removal 결과
- 논쟁 스타일 제거 태스크에서 K-Steer > CAA (6/10 스타일)
- 톤 제거에서도 유사하거나 근소한 우세
7. 결론 및 의의
- K-Steering은 다중 속성 제어를 위한 비선형, 통합형( unified ) 접근법:
- 별도의 속성 벡터 저장/튜닝 불필요
- 속성 간 간섭(interference) 완화
- 동적 조합(dynamic composition) 가능
- 학습 비용: MLP 학습은 가볍지만, 추론 시 gradient 계산으로 인해 CAA보다 계산량 ↑
- 활용 가능성: 안전성, 표현 다양성, 페르소나 제어 등 다양한 영역에 적용 가능
8. 한계 및 향후 연구
- 데이터셋(TONEBANK, DEBATEMIX)은 합성(synthetic) → 실제 데이터 일반화 미지수
- 속성 수 증가 시 조합 폭발적 증가
- Multi-step 방식은 계산비용 큼
- ITI, RepE 등 더 많은 baseline과의 비교 필요
요약하자면, 이 논문은 기존 “선형 벡터 합 기반” 스티어링을 비선형 gradient 기반으로 확장하여
다중 속성 조합을 자연스럽게 제어할 수 있게 만든 최초의 통합적 방법론입니다.
즉, “K-Steering = multi-label classifier 기반 gradient steering for compositional behavioral control”이라 정리할 수 있습니다.
아래는 논문 Beyond Linear Steering: Unified Multi-Attribute Control for Language Models의 방법론(Methodology) 을 핵심 수식·알고리즘 중심으로 정리한 설명입니다.
1. 핵심 아이디어 요약
K-Steering은
“선형 스티어링 벡터를 합산하지 말고, 비선형 분류기(probe) 가 학습한 결정경계의 gradient 로 활성값을 직접 이동시키자”
는 접근입니다.
- 단일 속성 → 다중 속성(K개) 동시 제어
- 선형성 가정 제거
- 속성 간 상호작용을 하나의 모델에서 학습
2. 전체 파이프라인 개요
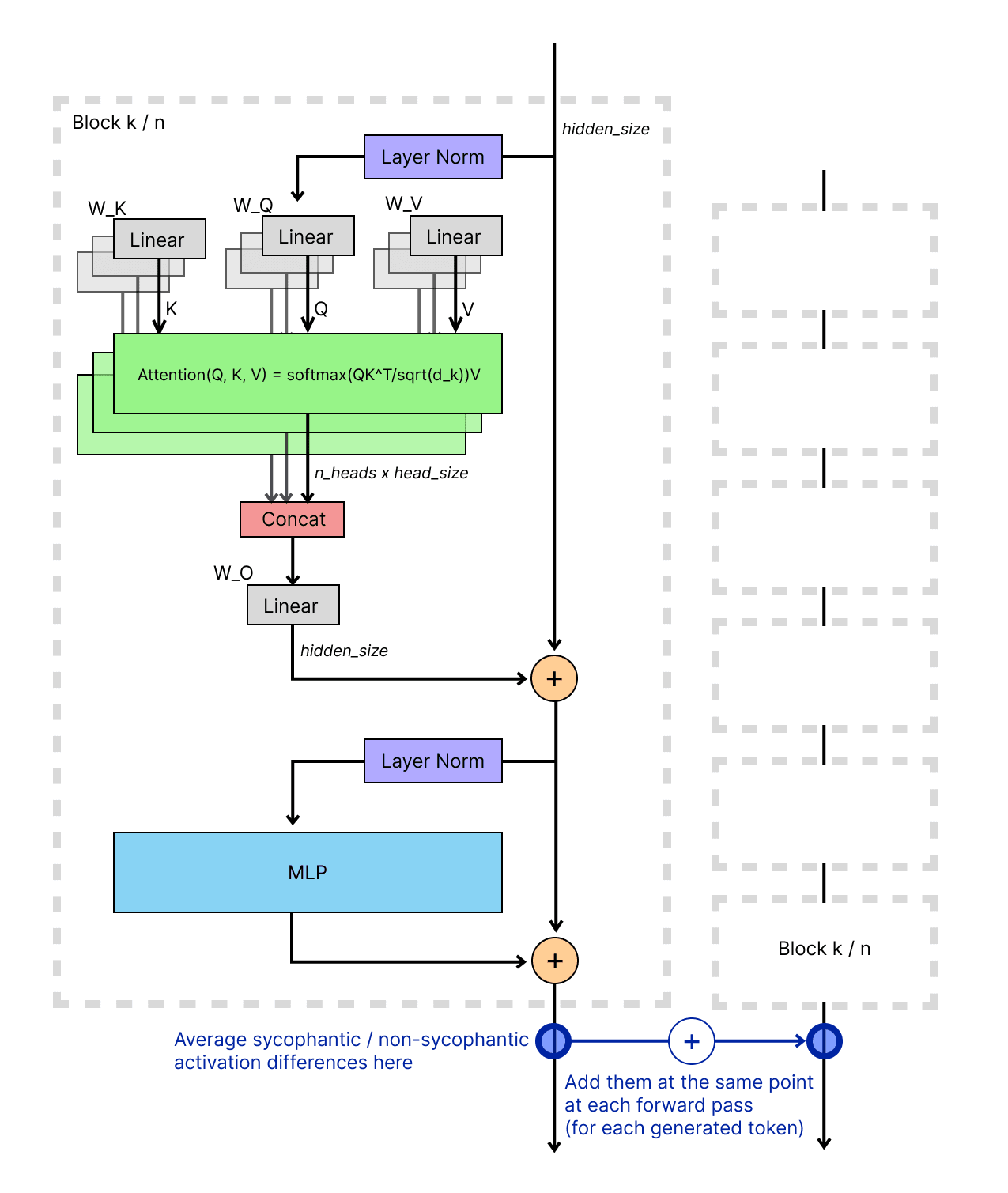
단계 개요
- Activation 수집
- Multi-label 비선형 분류기(MLP) 학습
- Inference 시 gradient 기반 activation 수정
- (선택) 다단계 / 다층 / 속성 제거(Projection Removal)
3. Activation 수집 & 분류기 학습
(1) Activation 정의
- LLM 의 특정 layer에서 은닉 표현:
- 학습 시에는 마지막 토큰의 activation만 사용
- 추론 시에는 시퀀스 전체 토큰에 적용
(2) Multi-Label Non-Linear Classifier
- 분류기
- 구조:
- MLP (2 hidden layers, 256 units, ReLU)
- 출력: K개 속성 logit (tone / debate style)
- Loss:
중요 포인트
- 속성별 분리 학습 ❌
- 모든 속성을 하나의 분류기에서 joint 학습
→ 속성 간 상관관계를 내부적으로 모델링
4. K-Steering: Gradient 기반 Activation Intervention
(1) 기본 수식
추론 시 activation을 다음과 같이 수정:
- : steering loss
- : steering strength
(2) Steering Loss 정의
- Target 속성 집합
- Avoid 속성 집합
✔️ target logit ↑
✔️ avoid logit ↓
5. Algorithm 1 — Iterative Gradient-Based K-Steering
for step k = 1 … K:
α_k = α · γ^k
compute L from target / avoid logits
a ← a − α_k ∇_a L
특징
- 다단계(non-linear trajectory) 이동
- 작은 α + 여러 step → 안정적 steering
- 큰 α + 여러 step → coherence 붕괴 위험
시퀀스 전체 평균 loss
→ 톤·스타일처럼 문맥적 속성에 적합
6. Algorithm 2 — Projection Removal (속성 제거 전용)
목적
“이 속성을 없애고 싶다” (e.g., strawman 제거)
(1) Loss
(2) Gradient 방향
(3) Householder Reflection
차별점
- 단순 projection 제거 ❌
- gradient 방향 기준 반사(reflection)
→ 비선형 decision boundary에서 멀어짐
✔️ 1-step
✔️ 반복 없음
✔️ CAA ablation보다 강력 (특히 debate style)
7. Multi-Layer & Multi-Step 확장
(1) Multi-Layer Steering
- 하나의 classifier를 학습한 후
- 모든 residual stream layer에 동시에 적용
✔️ Hydra effect(자기 복구) 대응
✔️ 깊은 스타일/논증 구조 변화에 효과적
(2) Multi-Step Steering
- activation을 loss manifold 상에서 점진적 이동
- 실험적 최적:
- α ≈ 0.6 ~ 3.0
- steps ≈ 2 ~ 8
8. 기존 방법과의 구조적 차이
| 항목 | CAA / ITI | K-Steering |
|---|---|---|
| 속성 수 | 단일 | 다중(K) |
| 가정 | 선형 | 비선형 |
| 벡터 | 고정 | 입력별 동적 |
| 조합 | 벡터 합 | joint gradient |
| 제거 | 평균 차 벡터 | gradient reflection |
9. 계산 비용 관점
- CAA:
- K-Steering (N step):
정리
- 성능 ↑
- 계산량 ↑
→ inference-time controllability trade-off
핵심 한 문장 요약
K-Steering은 “속성 벡터를 더하는 방법”이 아니라,
“비선형 속성 분류기의 gradient를 따라 activation을 이동시키는 방법”이다.
아래는 논문 **Beyond Linear Steering: Unified Multi-Attribute Control for Language Models (EMNLP 2025 Findings)**의 실험 결과(Experiments & Results) 를 평가 설계 → 핵심 테이블/그림 → 해석 순서로 정리한 내용입니다.
1. 실험 목표 정리
논문에서 실험은 다음 질문들에 답하려는 구조로 설계되어 있습니다.
- K-Steering이 다중 속성 조합(K=1,2,3)에서 기존 방법(CAA, DCT)보다 잘 작동하는가?
- Activation classifier 기반 평가가 실제 generation 품질과 일치하는가?
- Multi-layer / multi-step steering이 추가적인 이점을 주는가?
- 속성 제거(removal)에서도 효과적인가?
- 일반 성능(MMLU 등)을 훼손하지 않는가?
2. 실험 설정 요약
모델
- Llama-3.2-3B-Instruct
- Mistral-7B-Instruct-v0.3
- OLMo-2-7B-Instruct
데이터셋
- TONEBANK: 6개 톤 (expert, empathetic, cautious, casual, concise, helpful)
- DEBATEMIX: 10개 논증 스타일
비교 방법
- CAA (Contrastive Activation Addition)
- DCT (Deep Causal Transcoding)
- K-Steering (제안 방법)
3. 평가 방법 (중요)

(1) α (steering strength) 보정
- 각 속성 조합마다 α를 따로 탐색
- GPT-4o-Mini coherence judge 기반 binary search
- “최대한 세게, but OOD는 아닌” α 선택
(2) Layer 선택
- final-layer activation classifier 점수를 최대화하는 layer 선택
(3) 주 평가 지표
- Final-layer activation classifier 확률 증가량 (Δprob)
- 보조: LLM judge 평가 (0–10)
중요한 점
→ 출력 텍스트만 보지 않고, activation space에서의 속성 존재 정도를 정량화
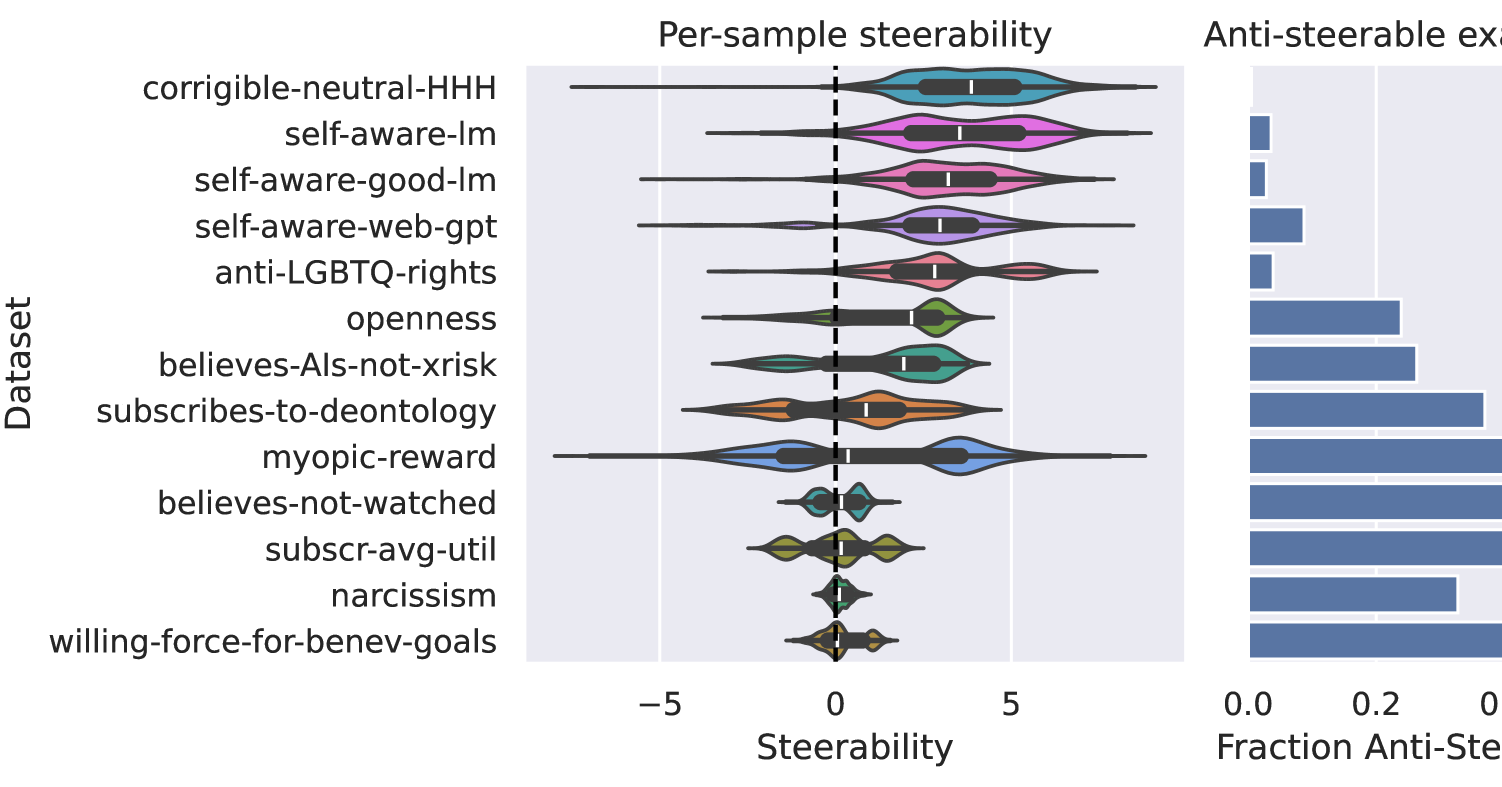
4. 메인 결과 ①
Single-layer, Single-step K-Steering (Table 1)
평균 activation classifier 확률 증가 (Δprob)
| Dataset | K | CAA | DCT | K-Steer |
|---|---|---|---|---|
| TONEBANK (OLMo) | 1 | 0.11 | 0.18 | 0.37 |
| 2 | 0.13 | 0.15 | 0.21 | |
| 3 | 0.04 | 0.01 | 0.09 | |
| TONEBANK (LLaMA) | 1 | 0.12 | 0.13 | 0.17 |
| DEBATEMIX (OLMo) | 1 | 0.43 | 0.32 | 0.56 |
| 2 | 0.24 | 0.16 | 0.25 | |
| 3 | 0.04 | 0.01 | 0.09 |
해석
- K-Steering은 모든 모델·데이터셋에서 평균적으로 최고 성능
- 특히 **K=2,3 (다중 속성)**에서 CAA의 급격한 성능 붕괴를 완화
- CAA는 벡터 평균 시 dilution effect 발생
5. 메인 결과 ②
Activation Classifier vs LLM Judge 일치성 (Table 2)
| Dataset | Model | K | Agree? |
|---|---|---|---|
| TONEBANK | OLMo | 1,2,3 | ✅ |
| TONEBANK | LLaMA | 3 | ❌ |
| DEBATEMIX | OLMo | 1,2,3 | ✅ |
- 15개 중 10개 케이스에서 일치
- 불일치 사례는 대부분:
- K=3
- Δprob < 10% (generation에서 미세함)
결론
→ activation-level 평가는 “민감”, generation 평가는 “보수적”
6. 메인 결과 ③
일반 성능 유지 (MMLU, Table 3)
| Model | K | Unsteered | CAA | K-Steer |
|---|---|---|---|---|
| OLMo-2-7B | 1 | 0.579 | 0.579 | 0.579 |
| 2 | 0.579 | 0.575 | 0.579 | |
| LLaMA-3.2-3B | 3 | 0.573 | 0.555 | 0.573 |
해석
- K-Steering은 base model 성능 유지
- CAA는 K 증가 시 성능 하락
→ “조종은 되는데, 모델을 망치지 않는다”
7. 메인 결과 ④
Multi-Layer Steering (Table 4, 7)

- Layer 14 (중간층)에서 최고 점수: 0.86
- Early layer → 작은 α 필요
- Late layer → 큰 α 필요
해석
- 스타일/논증 구조는 중간층 representation에 강하게 존재
- 단일 layer intervention은 Hydra effect로 상쇄 가능
8. 메인 결과 ⑤
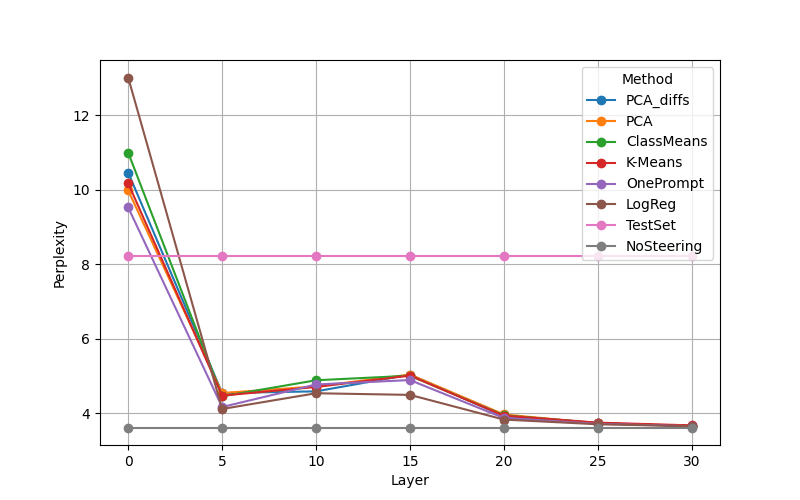
Multi-Step Steering (Figure 3, Table 5)

- 작은 α:
- step 증가 → 성능 점진적 상승
- 중간 α:
- 2~3 step에서 peak
- 큰 α:
- step 증가 → coherence 붕괴
결론
- Non-linear loss manifold을 따라 이동하는 효과
- 하지만 계산비용 ↑
9. 메인 결과 ⑥
Projection Removal (속성 제거, Table 6)
| Task | CAA Ablation | K-Steer Projection |
|---|---|---|
| Debate styles | 4 / 10 승 | 6 / 10 승 |
| Tones | 근소 우세 | 거의 동등 |
특히:
- burden
- empirical
- refutation
에서 큰 차이
이유
→ gradient는 현재 context에서 활성화된 속성 방향을 정확히 반영
10. 실험 결과 핵심 요약
정량 요약
- 다중 속성(K≥2)에서 일관되게 최고 성능
- CAA/DCT 대비 dilution 문제 완화
- 일반 QA 성능 유지
- 제거(ablation)에서도 효과적
개념적 메시지
“다중 행동 제어는 선형 벡터 합 문제가 아니라,
비선형 결정경계 추적 문제다.”
답글 남기기