


1. 문제 정의 및 연구 배경
Data Contamination이란?
테스트셋의 일부 샘플이 LLM의 pre-training 데이터에 이미 포함되어 있는 현상을 의미합니다.
이 경우 모델은 **일반화(generalization)**가 아니라 **암기(memorization)**로 정답을 맞출 수 있습니다.
논문에서는 contamination을 두 유형으로 구분합니다:
- Input-only contamination
- 질문만 training 데이터에 존재
- 정답(label)은 없음
- Input-and-label contamination
- 질문 + 정답이 함께 존재
- 가장 위험한 유형
(p.2 정의 부분 참고 )
2. 기존 연구의 한계
기존 contamination 분석은:
- GPT-4, Llama 등 모델 개발사 내부 분석
- 전체 benchmark를 포괄하지 않음
- 코드 및 측정 방식 공개 부족
- training data 접근 불가
즉, 투명성 부족 문제가 존재합니다.
3. 제안 방법 (핵심 기여)
핵심 아이디어
Training data에 접근하지 않고 contamination을 추정할 수 있는 공개 파이프라인 구축
사용 자원
- Bing Search API
- Common Crawl index
이 두 자원은 대부분의 LLM pretraining 데이터에 포함될 가능성이 높음
(GPT-3, LLaMA training data의 80% 이상이 Common Crawl 기반 — p.4 )
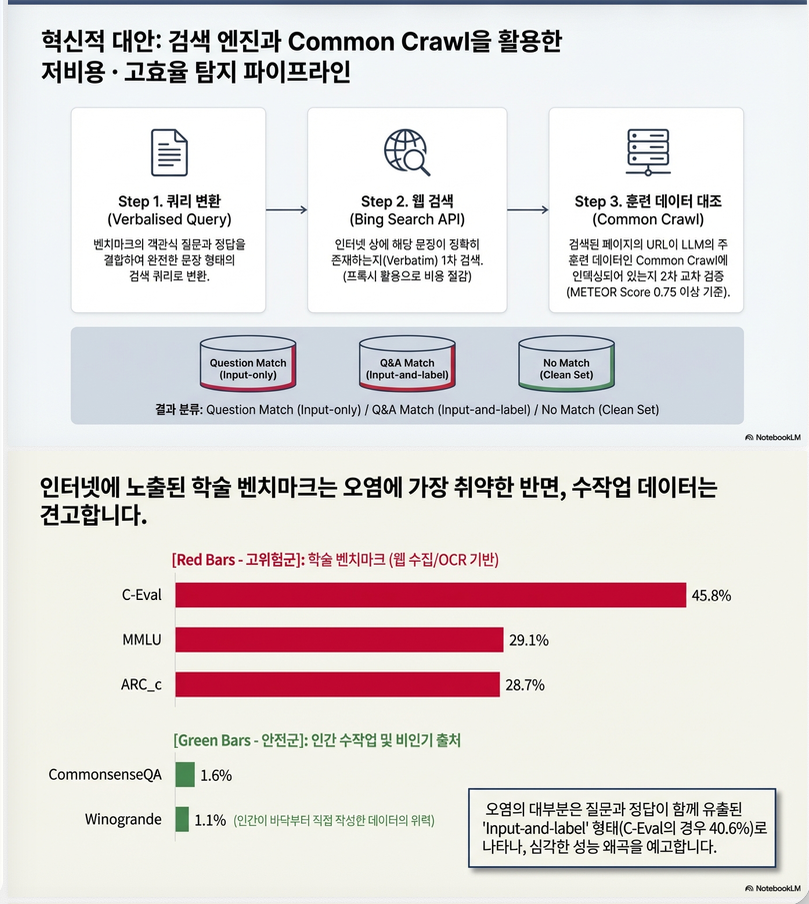
Contamination Detection Pipeline
Step 1: Query 구성
- MCQ 문제를 정답을 채운 문장으로 verbalize
- 예:
The flaw in Anderson’s ACT theory was that some considered it untestable...Step 2: Bing 검색
- 해당 문장이 웹에 존재하는지 확인
Step 3: Common Crawl index 확인
- 그 URL이 Common Crawl에 수집되었는지 확인
Step 4: METEOR 유사도 계산
- strict exact match 대신
- METEOR recall > 0.75 → contamination으로 판정
- 순서 penalty(γ=0.8), 2× query length window 제한 적용
(p.4–5 설명 )
4. 분석 대상
6개 Multi-choice Benchmark
| Benchmark | 특성 |
|---|---|
| MMLU | 학술 시험 기반 |
| C-Eval | 중국어 시험 기반 |
| ARC | 과학 시험 |
| HellaSwag | WikiHow 기반 |
| CommonsenseQA | ConceptNet 기반 |
| Winogrande | 인간 제작 |
총 15개 이상 LLM 평가
5. Contamination 통계 (Table 1, p.5)
| Benchmark | Total Contam |
|---|---|
| C-Eval | 45.8% |
| MMLU | 29.1% |
| ARC | 28.7% |
| HellaSwag | 12.4% |
| CommonsenseQA | 1.6% |
| Winogrande | 1.1% |
(p.5 표 )
🔍 주요 발견
- 학술 시험 기반 benchmark가 contamination 가장 심함
- Winogrande (human authored) 거의 contamination 없음
- 대부분 contamination은 input-and-label
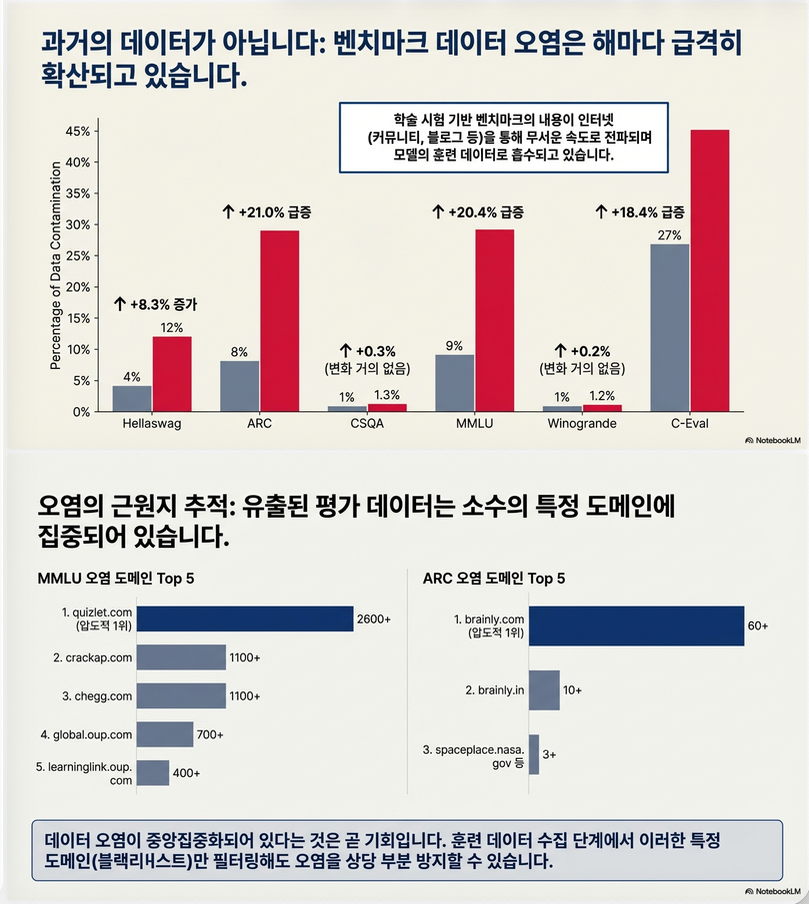
- 2020 → 2023 사이 contamination 급증 (p.6 Figure 2)
6. Contamination이 성능에 미치는 영향
성능 inflation
HellaSwag
- 최대 +7% accuracy inflation
C-Eval
- 최대 +14% inflation
MMLU
- 영향은 상대적으로 작음
(Table 2, 3 — p.7 )
중요한 발견
Input-only contamination
- 성능 향상 거의 없음
- 오히려 더 어려운 문제일 가능성 있음
Input-and-label contamination
- 명확한 성능 상승
- METEOR score가 높을수록 accuracy 상승 (Figure 4, p.8)
모델 규모 영향
- 70B > 13B > 7B
- 큰 모델이 contamination을 더 잘 exploit
(메모리 capacity 가설 — Carlini et al. 인용)
7. Domain 집중 현상
Figure 3 (p.6)
- contamination이 특정 도메인에 집중
- 예: HellaSwag → wikihow.com 집중
→ 특정 도메인 blocklist 전략 가능
8. 기존 방법과 비교 (Table 4, p.9)
| Method | Contam % | Inflation |
|---|---|---|
| Ground truth (Llama-2) | 8.4% | 7.42% |
| Ours | 8.3% | 7.29% |
| minK-20% | N/A | 14.29% |
→ 제안 방법이 ground truth와 거의 일치
9. 한계
- Bing API 비용 (~$110 for MMLU 전체)
- 긴 passage benchmark (SQuAD 등) 분석 어려움
- 비공개 user data contamination은 탐지 불가
(p.9 Limitation )
10. 핵심 메시지
Data contamination은 실제로 심각하다
- 최대 45% contamination
- accuracy inflation 최대 14%
시간이 지날수록 악화
- 학술 시험 benchmark 특히 위험
큰 모델일수록 더 취약
- memorization capacity 때문
공개 contamination 분석 필요
- 개발사 내부 보고만으로는 불충분
다음은 논문의 **방법론(Methodology)**을 정리한 것입니다
1. 문제 설정
목표는 다음 두 단계입니다:
- Test sample을 clean vs contaminated로 분류
- 각 subset에서 모델 성능을 비교하여 contamination 영향 측정
중요 제약:
- 대부분 LLM의 training data 접근 불가
- 수 PB 규모 corpus 로컬 인덱싱 불가능
따라서 논문은 training data를 직접 보지 않고 contamination을 추정하는 간접 접근을 제안합니다.
2. 핵심 아이디어
Proxy-based Contamination Detection
“Web presence + Common Crawl indexing”을 training data의 proxy로 사용
근거:
- GPT-3, LLaMA pretraining 데이터의 80% 이상이 Common Crawl 기반
- 나머지도 대부분 온라인 자료 기반
즉:
Test example이
(1) 웹에 존재하고
(2) Common Crawl에 index되어 있다면
→ LLM training data에 포함되었을 가능성 높음3. 전체 파이프라인
Step 1: Query Verbalization
Multi-choice 문제를 정답을 채운 문장 형태로 변환
예시:
Original:
The flaw in Anderson’s ACT theory was that some considered it ____.
Answer: BVerbalized:
The flaw in Anderson’s ACT theory was that some considered it untestable and thus...중요 설계:
- 다른 선택지는 포함하지 않음
- 질문 + 정답이 contamination 핵심 요소
Step 2: Bing Search API 탐색
- 해당 문장이 verbatim으로 웹에 존재하는지 검색
- Freshness parameter로 기간 제한
- 검색 window: 2017 ~ 모델 knowledge cutoff
Step 3: Common Crawl Index 검증
- Bing에서 찾은 URL이
- Common Crawl index에 존재하는지 확인
중요 포인트:
- Common Crawl 전체 문자열 검색하지 않음
- URL 존재 여부만 확인 → 비용 절감
4. Overlap 판정 방식
기존 방법 문제:
- Exact match → false negative 많음
- n-gram match → 변형 문장 탐지 어려움
제안 방법: METEOR 기반 유사도
- METEOR recall > 0.75 → contaminated
- Order penalty γ = 0.8
- Matching window ≤ 2× query length
이 설계는:
- 삽입어 허용
- 어형 변화 허용
- 문장 순서 보존
을 동시에 달성
5. Contamination 유형 분류
논문은 두 유형을 명확히 구분:
Input-only contamination
- 질문만 존재
- 정답 없음
Input-and-label contamination
- 질문 + 정답 존재
- 가장 위험
이 분리는 후속 성능 분석에서 매우 중요합니다.
6. 시간적 분석 설계
Contamination 증가 추적:
- 2017–2020
- 2020–2023
동일 pipeline으로 시계열 비교
결과:
- Academic benchmark contamination 급증
7. 모델 성능 분석 방법
Benchmark를 4개 subset으로 분리:
- Clean
- Not clean
- Input-only
- Input-and-label
모델 평가 설정:
- HellaSwag, ARC → zero-shot
- MMLU, C-Eval → 5-shot
- Perplexity 기반 선택 (lowest ppl 선택)
OpenCompass 사용
8. METEOR score vs Accuracy 분석
Test sample을 METEOR score 구간별로 그룹화:
Higher METEOR → Higher accuracy→ overlap 강도가 클수록 memorization 가능성 증가
9. Ground Truth 비교
Llama-2 contamination report와 비교:
- <1% contamination 오차
- <2% inflation 오차
minK-20% 대비 더 정확
10. 방법론의 기술적 강점
Training data 불필요
비용 효율적
공개 재현 가능
모델 독립적
11. 방법론 한계
- 긴 passage benchmark 적용 어려움
- Bing API 비용 존재
- 비웹 training data 탐지 불가
- paraphrased contamination 탐지 한계
12. 방법론 구조 요약 (알고리즘 관점)
For each test sample x:
q = verbalize(x, answer)
urls = BingSearch(q, time_window)
For each url in urls:
if url ∈ CommonCrawlIndex:
similarity = METEOR(q, page_text)
if similarity > 0.75:
if answer in page_text:
label = input-and-label
else:
label = input-only13. 연구적으로 중요한 설계 선택
- Exact match 대신 METEOR
- Web + CC 이중 검증
- Answer 포함 query 설계
- Temporal window 제한
- 유형별 contamination 분리
답글 남기기