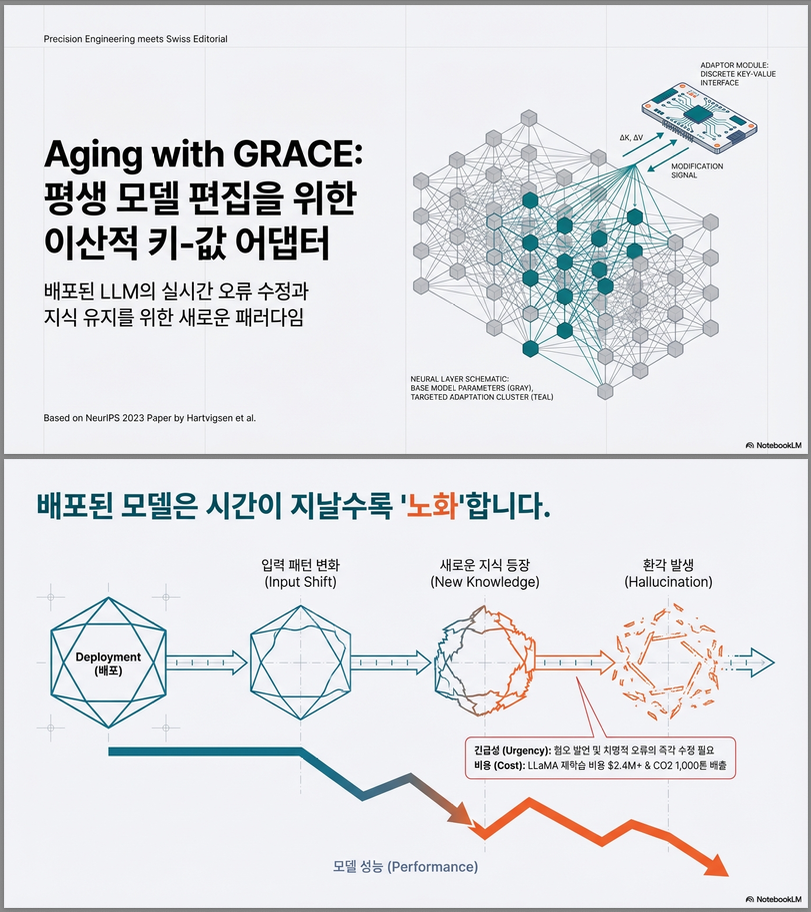

본 논문은 대규모 사전학습 모델을 재학습 없이, 수천 번 순차적으로(edit sequentially) 수정하는 방법을 제안합니다. 핵심은 모델 가중치를 건드리지 않고, 특정 레이어에 discrete key-value adaptor (codebook) 를 추가하여 “국소적 수정(spot-fix)”을 수행하는 것입니다 .
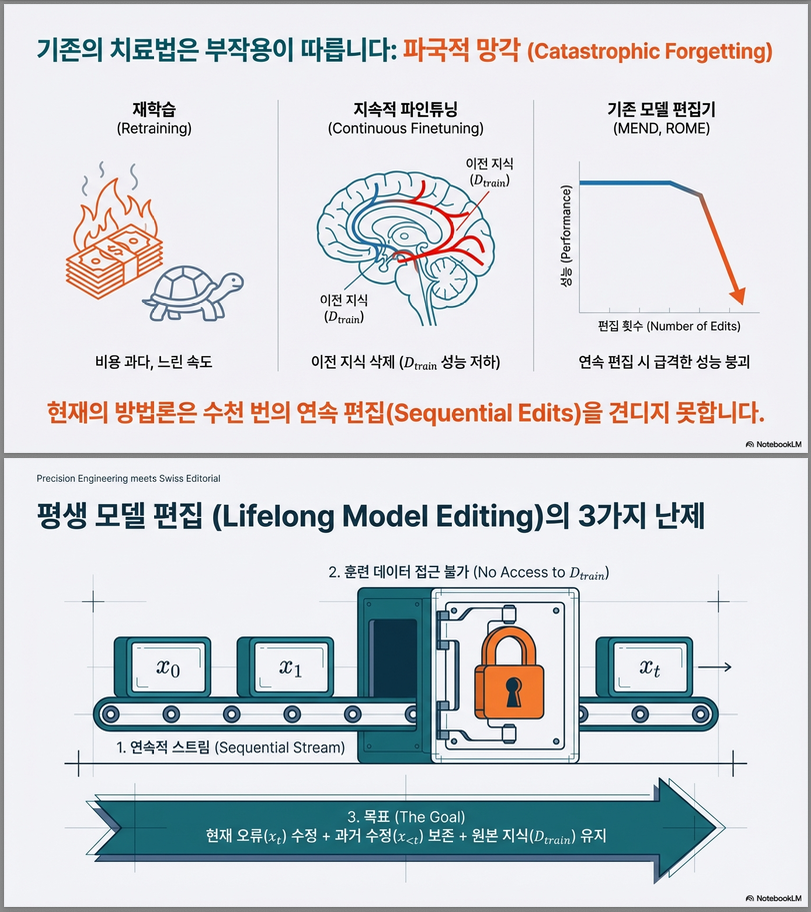
1. 문제 배경: 왜 Lifelong Model Editing이 필요한가?
배포된 LLM은 시간이 지나면서:
- 지식이 낡음 (factual decay)
- hallucination 발생
- 사회적 규범/라벨 기준 변화
- 사용자 요구 변화
와 같은 문제가 발생합니다 .
그러나:
- 재학습(retraining)은 매우 비쌈 (수백~수천 GPU-day)
- 기존 model editing 기법은 연속 편집(sequential editing) 시 성능이 급격히 붕괴
→ 따라서 문제는:
수백~수천 번 순차적으로 edit하면서도 기존 성능을 유지할 수 있는가?
이를 Lifelong Model Editing 문제로 정식화합니다 .
2. 문제 정의 (Problem Formulation)
기본 모델:
배포 중 입력 스트림:
각 시점에서 오류 발생:
편집 후 요구 조건:
- Edit Success (ES):
- Edit Retention (ERR): 과거 edit 유지
- Test Retention (TRR): 기존 학습 데이터 성능 유지
제약 조건:
- pretraining 데이터 접근 불가
- semantically equivalent input 없음
- 단일 edit 입력만 사용 가능
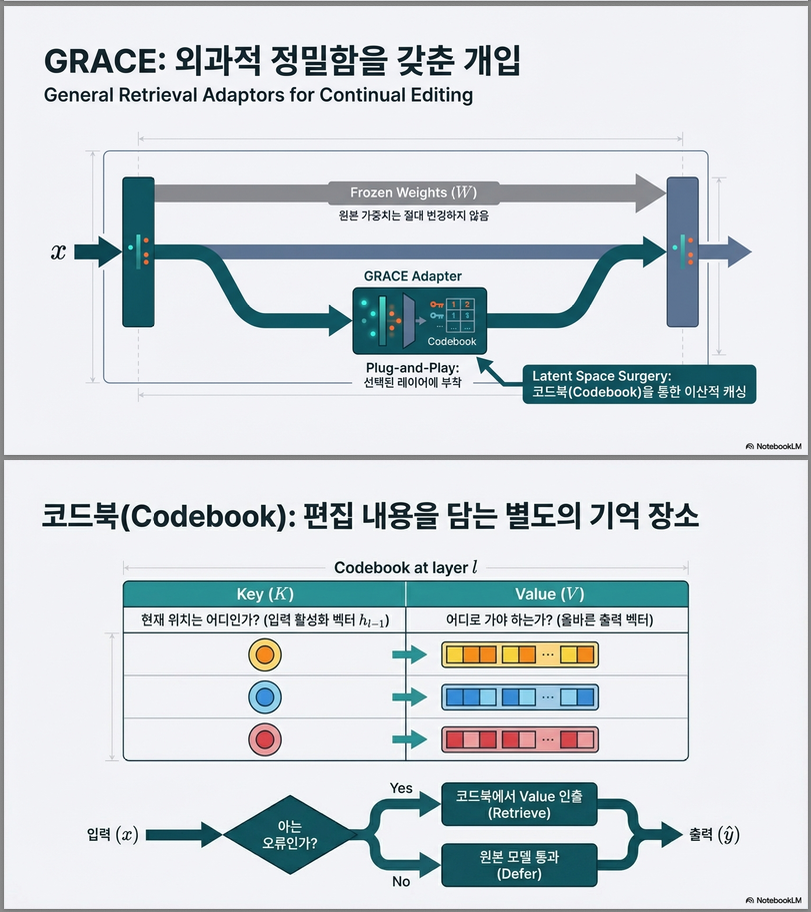
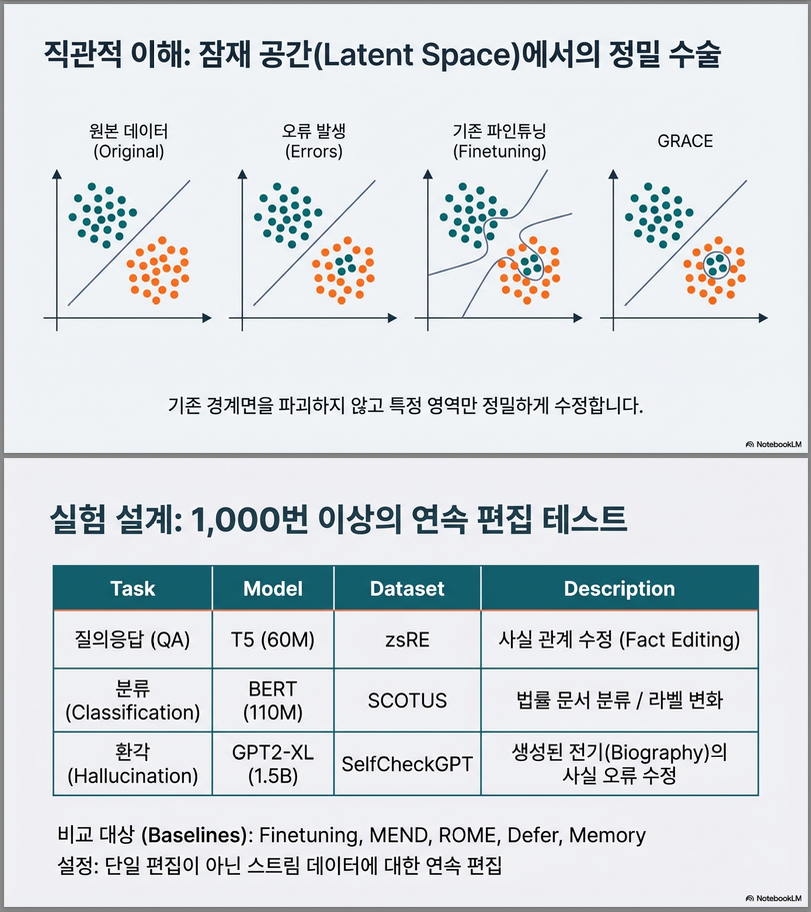
3. 핵심 제안: GRACE
GRACE = General Retrieval Adaptors for Continual Editing
핵심 아이디어
모델 가중치는 절대 수정하지 않고,
특정 레이어 l 에:
Key-Value Codebook Adaptor 추가
3.1 GRACE 구조
각 레이어 adaptor는 다음을 포함:
| 구성요소 | 설명 |
|---|---|
| Keys (K) | layer l-1 activation |
| Values (V) | 수정된 representation |
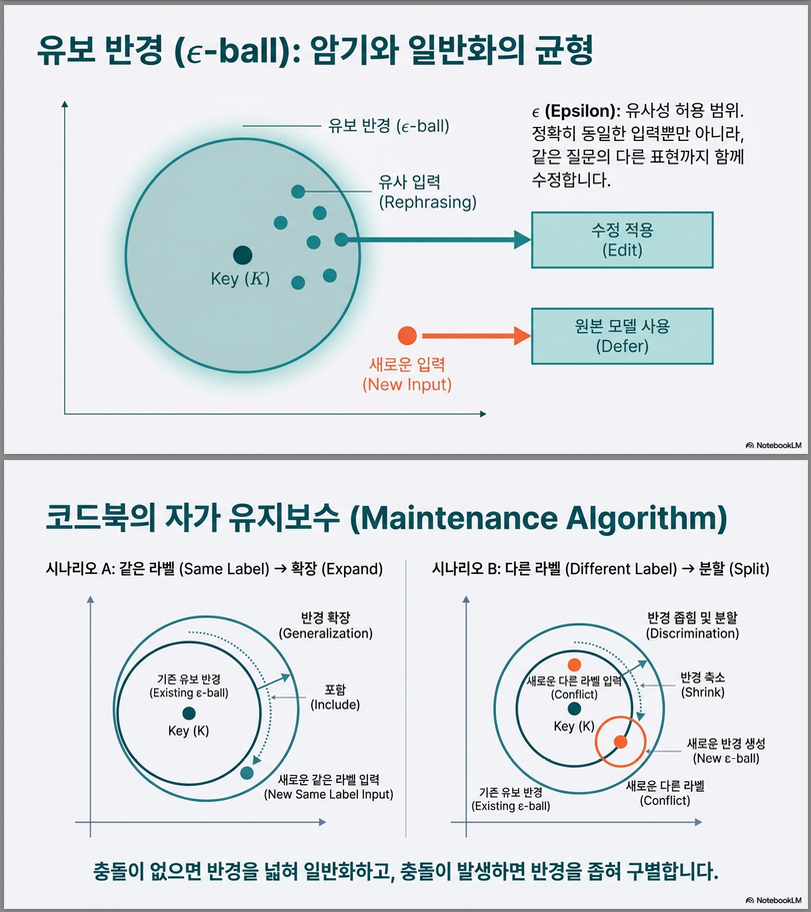
| ϵ (radius) | 유사도 허용 범위 |
수식적으로:
즉:
- latent space에서 가장 가까운 key 검색
- ϵ-ball 안이면 value로 교체
- 아니면 원래 모델 그대로 통과
3.2 Codebook Update 전략
새로운 edit 발생 시:
Case 1: 기존 key와 멀다
→ 새 key-value 추가
Case 2: 가까운데 label 동일
→ ϵ 확장 (generalization 강화)
Case 3: 가까운데 label 다름
→ 기존 ϵ 줄이고 split
Algorithm 1에 정리되어 있음 .
4. 실험 설정
3가지 시나리오
| Task | Model | Dataset |
|---|---|---|
| QA Editing | T5-small | zsRE |
| Label Shift | BERT | SCOTUS |
| Hallucination | GPT2-XL | SelfCheckGPT |
상세 구성은 Appendix에 기술 .
5. 주요 결과
5.1 기존 방법 대비 성능
GRACE는:
- 7개 baseline 대비 최고 TRR-ERR 균형
- 수천 번 edit 후에도 성능 유지
- hallucination 수정에서도 SOTA
예:
- T5에서 1000 edits → 단 137 keys 사용
- GPT hallucination → 1392 edits 수행
5.2 Generalization vs Memorization
ϵ_init 조절 실험 결과:
- 큰 ϵ → 더 일반화
- 작은 ϵ → 더 안전하지만 key 증가
중간 layer (block 2,4)가 가장 잘 작동 .
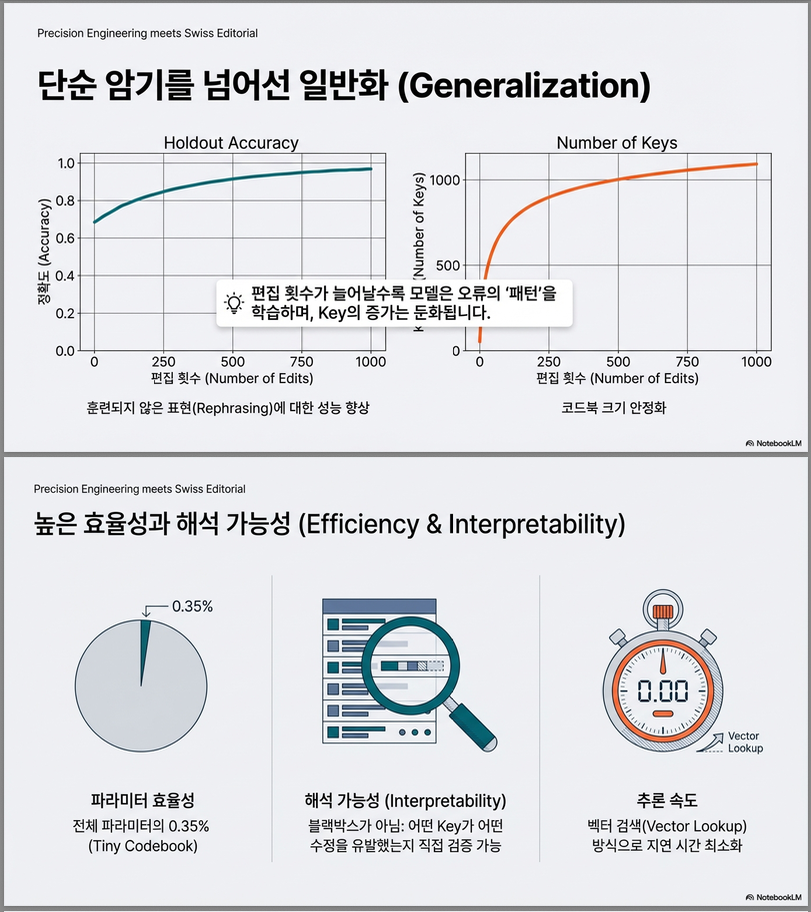
5.3 Parameter Efficiency
각 edit 당 필요한 파라미터:
- key는 학습하지 않음
- 매우 적은 learnable parameter 사용
5.4 Inference Cost
- 약 1.3× slowdown
- codebook 커져도 큰 증가 없음
6. 기존 모델 편집 방법과 비교
| 방법 | 한계 |
|---|---|
| Finetuning | catastrophic forgetting |
| EWC | long-term retention 약함 |
| MEND | pretraining data 필요 |
| ROME | multiple edits 취약 |
| SERAC | large auxiliary data 필요 |
GRACE는:
✔ weight untouched
✔ no external data
✔ sequential editing 가능
✔ plug-and-play adaptor
7. 한계
논문에서 언급한 제한점 :
- inference 느려짐
- multi-layer editing 미연구
- edit implication propagation 없음
- 악용 가능성 존재
8. 이 논문의 핵심 기여
- Lifelong Model Editing 문제 정의
- Discrete key-value adaptor 기반 editing
- 수천 번 sequential edit 최초 달성
- 실제 hallucination / label shift 시나리오 실험
9. 연구적 관점에서의 의미
이 논문은:
“Editing = weight update” 패러다임에서
“Editing = latent-space memory insertion” 패러다임으로 전환
입니다.
이는:
- Retrieval-Augmented Editing
- Memory-augmented LLM
- Latent Space Partitioning
연구와 직접 연결됩니다.
Methodology
본 논문의 방법론은 가중치를 수정하지 않고, 특정 레이어의 latent representation을 국소적으로 재정의하여 순차적(edit-after-edit) 수정을 가능하게 하는 것입니다. 핵심은 Discrete Key-Value Codebook Adaptor입니다 .
1. 문제 설정 (Formal Setup)
사전학습된 모델:
- 파라미터는 고정(frozen)
배포 중 입력 스트림:
오류 발생 시:
목표:
- Edit Success:
- Edit Retention (ERR): 이전 edit 유지
- Test Retention (TRR): 기존 데이터 성능 유지
제약:
- pretraining 데이터 없음
- semantically-equivalent 데이터 없음
- 단일 edit 입력만 사용
2. GRACE의 핵심 구조
기본 아이디어
특정 레이어 l에 Adaptor를 삽입:
을 다음으로 대체:
즉,
- latent space에서 비슷한 과거 edit를 찾으면
- 그에 대응하는 수정 representation으로 교체
3. Codebook 구성
각 GRACE Adaptor는 다음 3요소로 구성됩니다 :
| 구성 | 의미 |
|---|---|
| Keys | layer l-1 activation 저장 |
| Values | 수정된 representation (학습됨) |
| (radius) | influence 범위 |
4. Retrieval & Deferral Mechanism
거리 함수:
최근접 key:
Activation 조건:
조건 만족 시:
아니면:
→ 이를 Deferral mechanism이라 부름 .
5. Edit 발생 시 Codebook 업데이트
새로운 edit 도착:
Step 1: query 계산
Step 2: 최근접 key 탐색
Case A️: 멀리 있음
→ 새 entry 추가:
Case B️: 가까움 & 같은 label
→ 기존 ϵ 확장:
Case C️: 가까움 & 다른 label
→ split:
Algorithm 1에 정식화 .
6. Value 학습 방식
새 value v는 다음 loss로 학습:
- 100 step gradient descent
- 모델 가중치는 고정
- 오직 v만 학습
즉,
Editing = representation replacement learning
7. Transformer에서의 적용 세부
Classification 모델 (BERT, T5)
- value를 모든 토큰에 broadcast
- representation을 강하게 제어
Autoregressive 모델 (GPT)
- 마지막 token만 교체
- 이후 생성에 영향
8. 중요한 설계 선택
ϵ_init
- 클수록 generalization ↑
- interference ↑
- codebook 작아짐
Layer 선택
Appendix에서 특정 layer 선택이 중요함을 실험적으로 확인 .
9. 이 방법의 본질
기존 편집:
weight update 기반
GRACE:
latent-space partition 기반
즉,
- 모델 파라미터는 global
- GRACE는 local memory patch
10. 계산 비용
각 edit 당 필요한 파라미터:
- key는 frozen
- value만 학습
방법론 요약
GRACE는:
- 특정 layer 선택
- latent activation을 key로 저장
- 수정 representation을 value로 학습
- ϵ-ball 기반 retrieval 적용
- weight 수정 없이 sequential edit 가능
실험 결과 (Experimental Results)
본 논문의 실험은 **“수백~수천 번의 순차적 편집 이후에도 성능이 유지되는가?”**라는 질문에 정면으로 답합니다. 결론부터 말하면, GRACE는 기존 모든 편집/continual learning 방법 대비 가장 안정적인 TRR–ERR 균형을 달성합니다 .
1. 실험 설정 요약
평가 모델 & 태스크
| Task | Model | 목적 |
|---|---|---|
| QA Editing | T5-small (60M) | factual error 수정 |
| Label Shift | BERT-base (110M) | 시간에 따른 라벨 변화 |
| Hallucination | GPT2-XL (1.5B) | 문장 단위 hallucination 수정 |
각 실험은 hundreds–thousands of sequential edits로 구성됨 .
비교 방법 (Baselines)
- Finetuning (FT)
- FT + EWC
- FT + Periodic Retraining
- MEND
- Defer (SERAC-style)
- ROME (GPT only)
- Memory Network (soft attention)
평가 지표
| 지표 | 의미 |
|---|---|
| ES (Edit Success) | 현재 edit 성공 여부 |
| ERR (Edit Retention Rate) | 과거 edit 유지 |
| TRR (Test Retention Rate) | 원래 성능 유지 |
| ARR | (Hallucination) 이미 정확했던 문장 유지 |
| Runtime | edit 1회당 시간 |
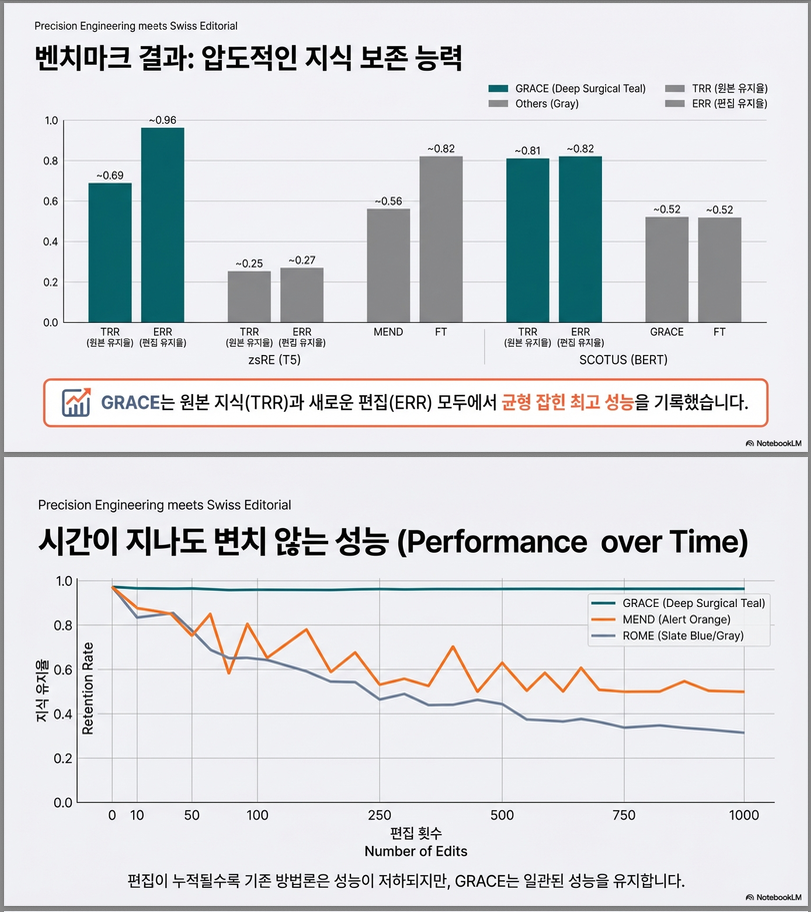
메인 결과 (Table 2 핵심 요약)
전체적인 결론
GRACE는 모든 태스크에서 TRR과 ERR을 동시에 가장 잘 유지하는 유일한 방법이다.
(1) zsRE – T5 QA Editing (1000 edits)
| Method | TRR ↑ | ERR ↑ | Avg |
|---|---|---|---|
| FT | 0.56 | 0.82 | 0.69 |
| FT+EWC | 0.51 | 0.82 | 0.66 |
| FT+Retrain | 0.27 | 0.99 | 0.63 |
| MEND | 0.25 | 0.27 | 0.26 |
| Defer | 0.72 | 0.31 | 0.52 |
| Memory | 0.25 | 0.27 | 0.26 |
| GRACE | 0.69 | 0.96 | 0.82 |
–> 최고 평균 성능, catastrophic forgetting 없음 .
(2) SCOTUS – BERT Label Shift (≈400 edits)
| Method | TRR ↑ | ERR ↑ | Avg |
|---|---|---|---|
| FT | 0.52 | 0.52 | 0.52 |
| FT+EWC | 0.67 | 0.50 | 0.58 |
| FT+Retrain | 0.67 | 0.83 | 0.75 |
| MEND | 0.19 | 0.27 | 0.23 |
| Defer | 0.33 | 0.41 | 0.37 |
| Memory | 0.21 | 0.20 | 0.21 |
| GRACE | 0.81 | 0.82 | 0.82 |
–> 라벨 시프트 상황에서도 안정적인 유지 .
(3) Hallucination – GPT2-XL (1392 edits)
| Method | TRR (PPL↓) | ERR (PPL↓) | ARR (PPL↓) |
|---|---|---|---|
| FT | 28.14 | 107.8 | ❌ |
| FT+Retrain | 35.3 | 195.8 | ❌ |
| Defer | 133.3 | 10.04 | ❌ |
| ROME | 30.28 | 103.8 | 14.02 |
| Memory | 25.47 | 79.30 | 10.07 |
| GRACE | 15.84 | 7.14 | 10.00 |
–> hallucination은 고치면서, 원래 잘하던 문장은 유지 .
3. 시간에 따른 성능 변화 (Figure 3)
관찰 결과
- Finetuning 계열
- 초반 ES ↑
- 빠르게 TRR 붕괴
- ROME / Memory
- 초반에는 괜찮음
- edit 수 증가 시 성능 하락
- GRACE
- ES, ERR, TRR 모두 안정적으로 유지
- 1000+ edit 이후에도 성능 유지 .
4. Generalization vs Memorization 분석 (Figure 4)
설정
- zsRE에서 3000 sequential edits
- unseen paraphrase holdout 평가
핵심 관찰
- 중간 layer (Block 2, 4)
- 높은 TRR & ERR
- Holdout generalization 우수
- ϵ_init 효과
- 작은 ϵ → memorization ↑, key 폭증
- 큰 ϵ → generalization ↑, codebook 감소
- Codebook size 안정화
- 초반 증가 후 plateau 형성 .
5. Codebook 효율성
| Task | #Edits | #Keys | Edits / Key |
|---|---|---|---|
| zsRE | 1000 | 137 | 7.3 |
| SCOTUS | 381 | 252 | 1.5 |
| Hallucination | 1392 | 1341 | ~1 |
–> edit label 다양성에 따라 자동으로 적응 .
6. Inference Time (Figure 6)
- GRACE 적용 후 inference ≈ 1.32× 느림
- codebook 커져도 추가 증가 없음
- 벡터화된 nearest-neighbor search 덕분 .
7. 실험 결과 핵심 요약
GRACE는
- 수천 번 edit 이후에도
- 기존 지식(TRR)과 수정 지식(ERR)을
- 동시에 유지하는 유일한 방법이다.
기존 방법들의 실패 원인
- weight update → global interference
- soft memory → 누적 drift
- retraining → catastrophic forgetting
GRACE의 성공 요인
- latent-space local intervention
- discrete retrieval
- ϵ-ball 기반 영향 제어
답글 남기기