


다음 논문은 LLM이 생성하는 자연어 설명(NLE)의 “faithfulness(충실성)”을 어떻게 개선할 것인가를 다룬 매우 중요한 연구입니다. 핵심은 모델이 스스로 자신의 설명을 비판하고 수정할 수 있는가입니다.
1. 문제 정의 (Why this paper?)
핵심 문제: NLE의 “비충실성 (Unfaithfulness)”
- LLM은 설명을 잘 “만들어내지만”
- 그 설명이 실제 모델의 내부 reasoning을 반영하지 않는 경우가 많음
예:
- 모델은 “playing guitar → performing”으로 판단했지만
- 설명은 “셔츠 입었다” 같은 irrelevant 이유를 제시
즉, plausible explanation ≠ faithful explanation
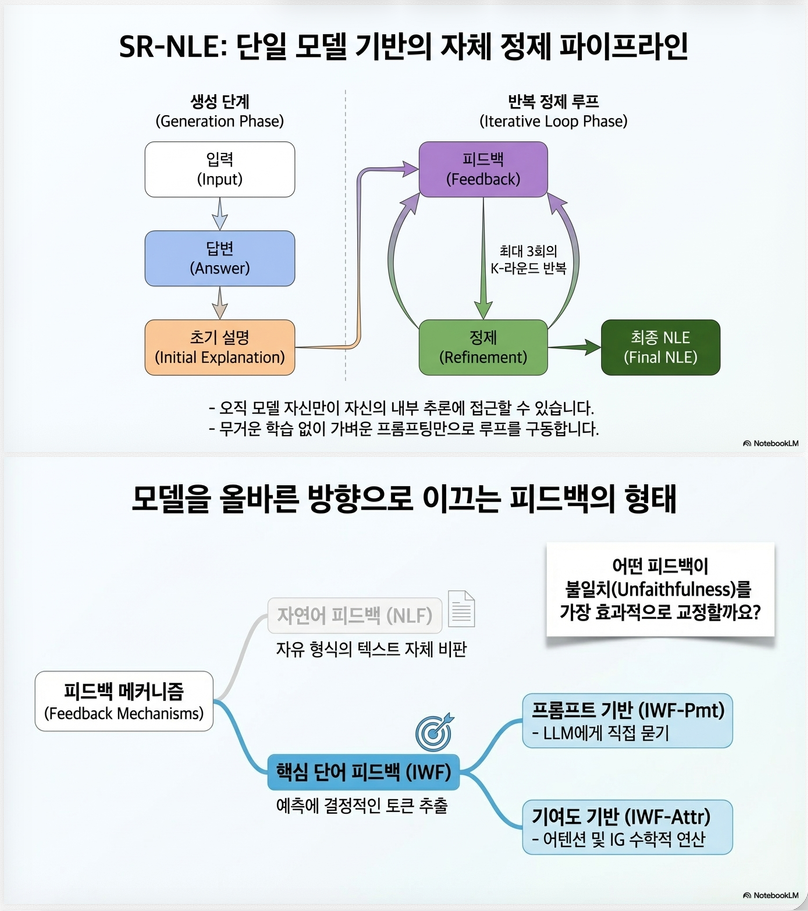
2. 핵심 아이디어: SR-NLE
Self-Critique + Refinement
논문에서 제안한 프레임워크:
SR-NLE (Self-critique and Refinement for NLE)
핵심 특징:
- 외부 supervision 없음
- 추가 학습 없음
- 모델 하나만 사용
- iterative refinement
전체 구조 (2단계)
(1) Answer + Initial Explanation
(2) Iterative Refinement (핵심)
각 iteration r에서:
- Feedback 생성
- Explanation 수정
–> 반복 → (최종 설명)
3. 핵심 설계: Feedback 방식
논문의 핵심 contribution은 feedback 설계입니다.
(1) Natural Language Feedback (NLF)
- 모델이 직접 설명을 비판
예:
“설명이 부족하다, 더 구체적으로 써라”
장점: 직관적
단점: vague, 비효율적
(2) Important Word Feedback (IWF): 핵심
“모델이 실제로 중요하게 사용한 입력 단어”를 feedback으로 제공
예:
- 중요한 단어: playing, performing
- → explanation 수정 유도
IWF 생성 방식 2가지
(a) Prompt-based
- LLM에게 직접 중요 단어를 물어봄
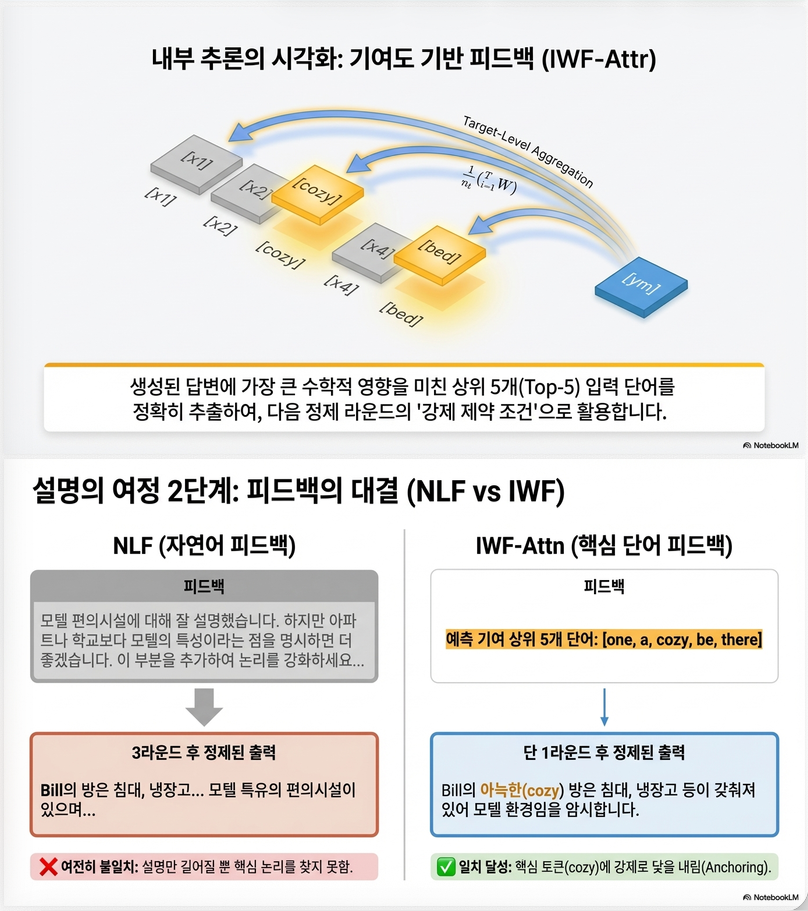
(b) Attribution-based (핵심 기여)
- gradient / attention 기반 importance 계산
Attribution 공식 (핵심 수식)
토큰 단위 attribution:
→ output token별 영향
집계:
→ input token 중요도
word-level:
–> top-N 단어 → feedback
4. 실험 설정
- Dataset:
- ComVE (commonsense)
- ECQA (QA)
- e-SNLI (NLI)
- 모델:
- LLaMA, Mistral, Qwen, Falcon (≤10B)
평가 metric (중요)
Counterfactual Test
- 입력 단어 수정
- prediction 바뀌는지 확인
- 설명이 그 단어를 포함하는지 확인
Unfaithfulness 정의
–> 낮을수록 좋음
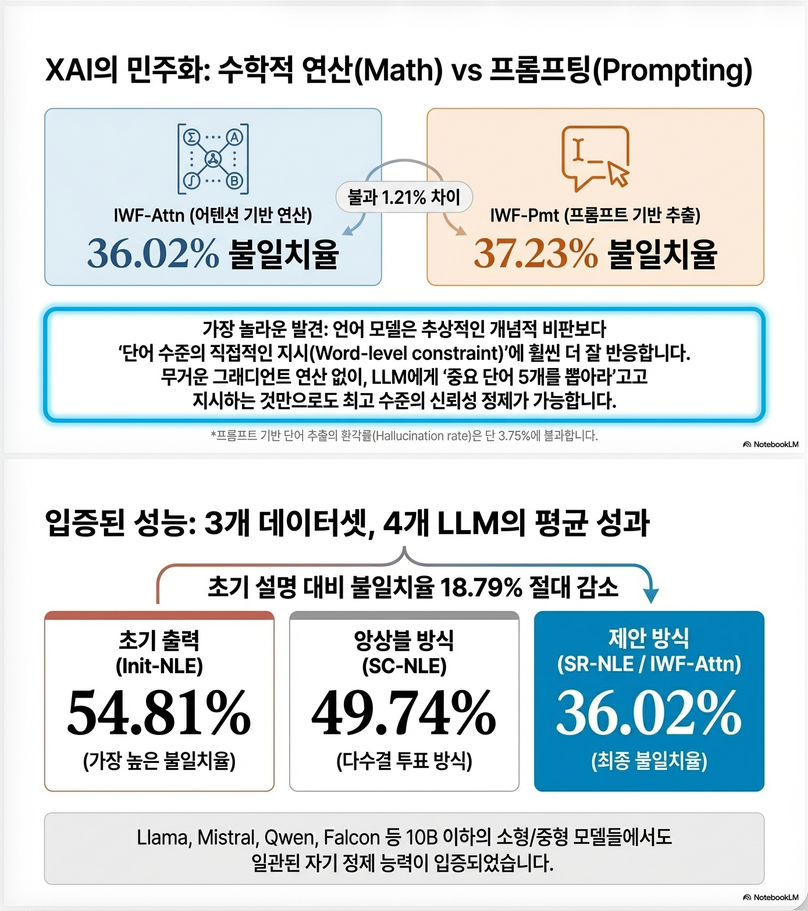
5. 주요 결과
핵심 결과
| 방법 | Unfaithfulness |
|---|---|
| Init-NLE | 54.81% |
| SC-NLE | 49.74% |
| SR-NLE (best) | 36.02% |
–> 약 18.8% 감소
중요한 관찰
1. IWF >> NLF
- 중요 단어 기반 피드백이 훨씬 효과적
2. Prompt-based ≈ Attribution-based
- surprising result
- → LLM 자체도 중요한 단어 잘 찾음
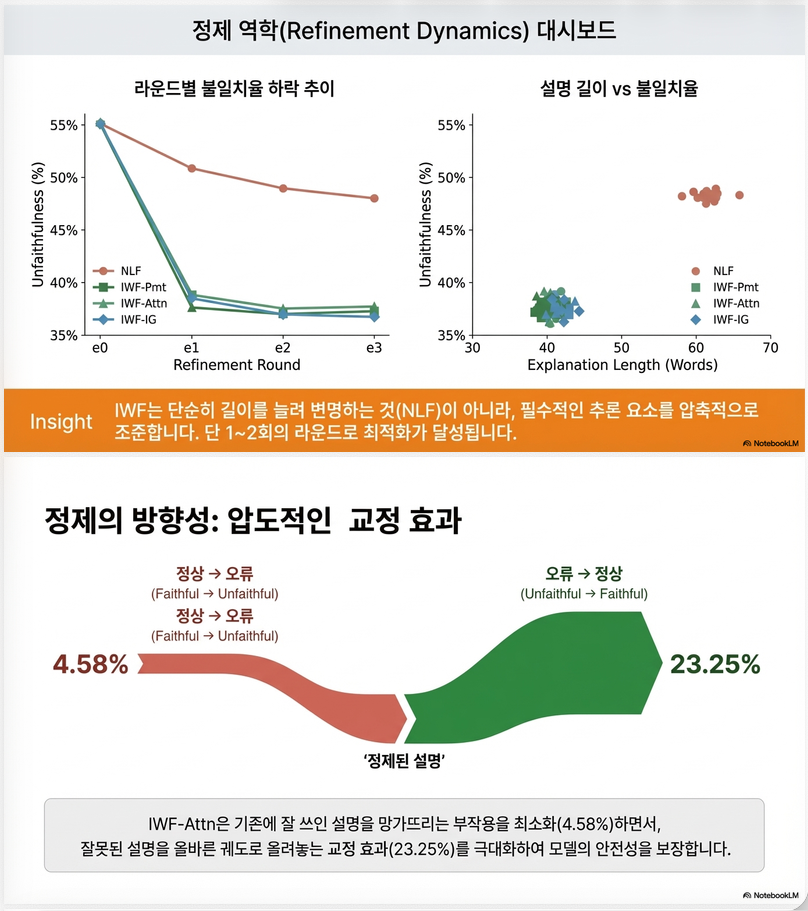
Iteration 효과
- 1st round에서 가장 큰 개선
- 이후 diminishing return
–> optimal: 2~3 rounds
Faithfulness transition (page 8 그림)
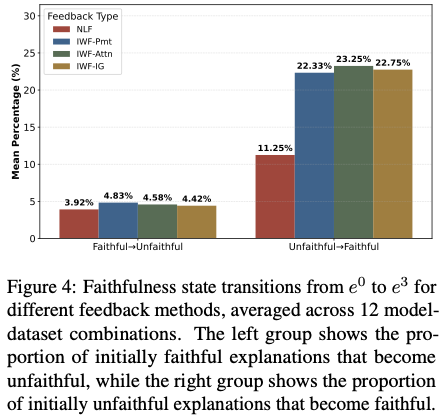
- Unfaithful → Faithful 전환이 훨씬 많음
- Faithful → Unfaithful는 거의 없음
–> refinement가 안정적
6. 핵심 인사이트
Insight 1: LLM은 “자기 설명을 고칠 수 있다”
- 단, 적절한 feedback이 필요
Insight 2: “어떤 token이 중요한가”가 핵심
–> explanation quality 문제 ≠ language 문제
–> 실제로는 feature attribution 문제
Insight 3: Explanation length ≠ quality
- 길어지면 좋아지긴 하지만
- 중요한 것은 relevant word 포함 여부
7. 기존 연구와 차별점
| 방식 | 특징 |
|---|---|
| 기존 | fine-tuning / architecture 변경 |
| G-TEX | graph 기반 모델 수정 |
| Cross-Refine | 다른 모델 사용 |
| SR-NLE | self-contained, training-free |
–> lightweight + scalable
8. 한계
- post-hoc NLE만 대상
- counterfactual metric 하나만 사용
- attribution 품질 의존
- small model만 실험
핵심 한 줄 요약
LLM은 자신의 설명이 틀렸다는 것을 알 수 있으며,
“중요 단어 기반 feedback”을 주면 더 faithful한 설명으로 스스로 개선할 수 있다.
다음은 이 논문의 **방법론(Method)**을 핵심 구성 요소와 수식 중심으로 정리한 것입니다.
Method: SR-NLE (Self-Critique and Refinement for NLE)
1. Problem Formulation
입력 x, 모델 M:
- 예측:
- 초기 설명:
이후 iterative refinement 수행:
2. Iterative Refinement Loop
각 step :
(A) Feedback 생성
(1) Natural Language Feedback (NLF)
- 자유 텍스트 형태 critique
(2) Important Word Feedback (IWF)
핵심 구조:
- S: input word importance score
- I: top-N 중요한 단어 집합
(B) Refinement
- feedback을 conditioning으로 explanation 업데이트
3. IWF: Attribution-Based Scoring (핵심 기술)
(1) Token-level attribution
출력 token 기준:
- 절댓값 사용:
- sign cancel 방지
- magnitude 중심 중요도 측정
(2) Target-level aggregation
- 전체 answer span에 대한 영향 누적
(3) Word-level aggregation
- subword → word 매핑
4. SCORE 함수 구현
(A) Prompt-based
- LLM이 직접 중요 단어 예측
(B) Attribution-based
두 가지 구현:
- Integrated Gradients (IG)
- Attention weights
5. Full Algorithm (요약)
Input: x
1. y ← M(x)
2. e0 ← M(x, y)
for r = 1 ... K:
fr ← Feedback(x, y, e_{r-1})
er ← M(x, y, e_{r-1}, fr)
return eK6. Design 특징 (Method 관점 핵심)
✔ Single-model closed loop
- feedback + refinement 모두 동일 모델
✔ Training-free
- fine-tuning 없음
- purely in-context
✔ Feedback modularity
- NLF ↔ IWF 교체 가능
✔ Attribution → language bridging
- feature importance → textual feedback 변환
Method 핵심 요약
SR-NLE는
(1) explanation 생성 → (2) 중요 정보 기반 feedback → (3) iterative refinement
의 closed-loop 구조이며,
특히 input attribution을 feedback으로 변환하는 것이 핵심 메커니즘이다.
답글 남기기