


1. 문제 제기: Pretraining Data Detection
LLM은 어떤 데이터로 학습되었는지 공개되지 않는 경우가 많음.
이로 인해 다음과 같은 문제가 발생:
- 저작권 침해 가능성 (Books3 등)
- 개인정보 포함 여부 불명확
- 벤치마크 contamination 문제
- machine unlearning 검증 어려움
따라서 논문은 다음 질문을 다룸:
Black-box LLM에 대해, 주어진 텍스트가 pretraining 데이터에 포함되었는지 판별할 수 있는가?
이는 Membership Inference Attack (MIA)의 pretraining 버전 문제이다.
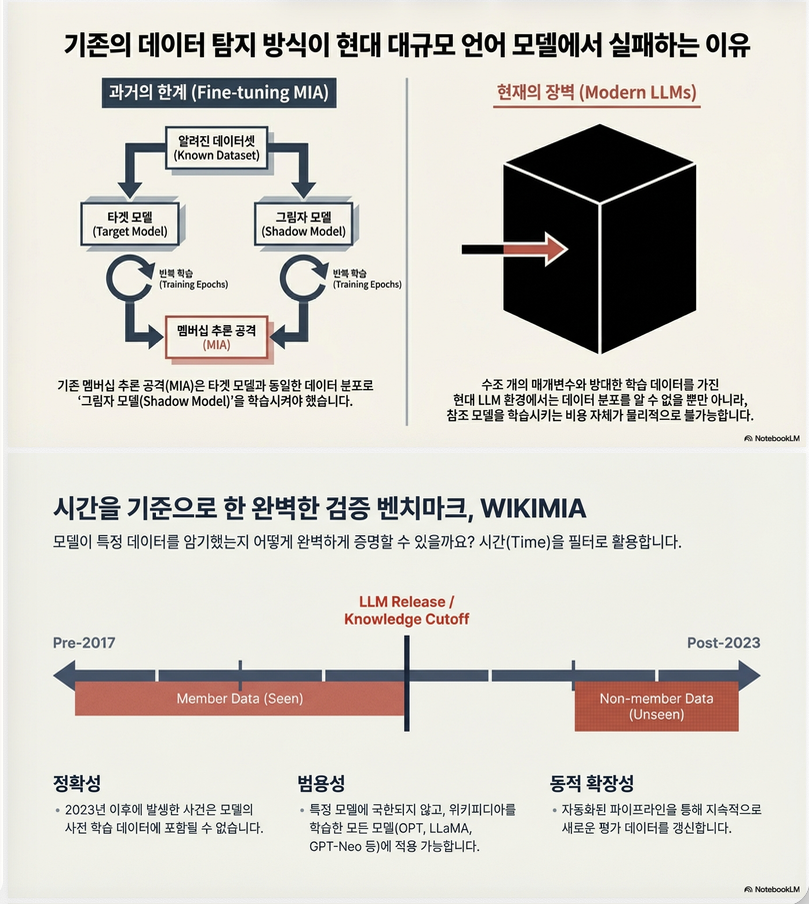
2. 기존 MIA와의 차이점 (핵심 난점)
논문은 기존 fine-tuning MIA와 달리 pretraining detection이 어려운 이유를 정리한다.
(1) Pretraining 데이터 분포를 모름
기존 MIA는:
- shadow model을 훈련
- 비슷한 데이터 분포로 calibration
하지만 pretraining의 경우:
- 데이터 분포 D 접근 불가
- 수조 token → shadow model 훈련 불가능
즉 reference model 사용 불가
(2) Detection difficulty 이론적 분석
Detection 난이도는 다음에 의존:
- 데이터셋 크기 ↑ → detection 어려움
- learning rate ↓ → detection 어려움
- example occurrence ↓ → detection 어려움
이론적 근거:
- Hardt et al. (SGD stability)
- total variation distance bound
즉, pretraining은:
- huge dataset
- low epoch (1 pass)
- 낮은 memorization
→ fine-tuning보다 detection이 더 어려움
3. WIKIMIA: Dynamic Benchmark
논문의 첫 번째 기여는 benchmark 구축.
핵심 아이디어
Wikipedia timestamp 활용:
| 구분 | 구성 |
|---|---|
| Member | 2016년 이전 Wikipedia 이벤트 |
| Non-member | 2023년 이후 Wikipedia 이벤트 |
왜 가능한가?
- 2023 이후 이벤트는 pretraining에 절대 포함 불가
- 자동 수집 가능
- 지속 업데이트 가능 (dynamic)
추가 설정
(1) Paraphrase setting
- ChatGPT로 paraphrase 생성
- verbatim이 아닌 경우 detection 가능한지 실험
(2) Length bucket
- 32, 64, 128, 256 token
- 길이에 따라 detection 난이도 달라짐
결과:
길이가 길수록 detection 쉬움
4. 핵심 기법: MIN-K% PROB
이 논문의 가장 중요한 기여.
핵심 가설
“Seen example은 매우 낮은 확률 token(outlier)이 적다.”
반대로:
“Unseen example은 몇 개의 매우 낮은 확률 token을 포함할 가능성이 높다.”
수식
문장
각 token log-likelihood:
- 가장 낮은 확률 token 상위 k% 선택
- 그 평균 log-likelihood 계산
thresholding으로 membership 판별
특징
- reference model 필요 없음
- 추가 training 필요 없음
- black-box probability만 사용
- 매우 단순
논문 Figure 1이 이를 시각적으로 설명
5. 실험 결과
WIKIMIA 결과
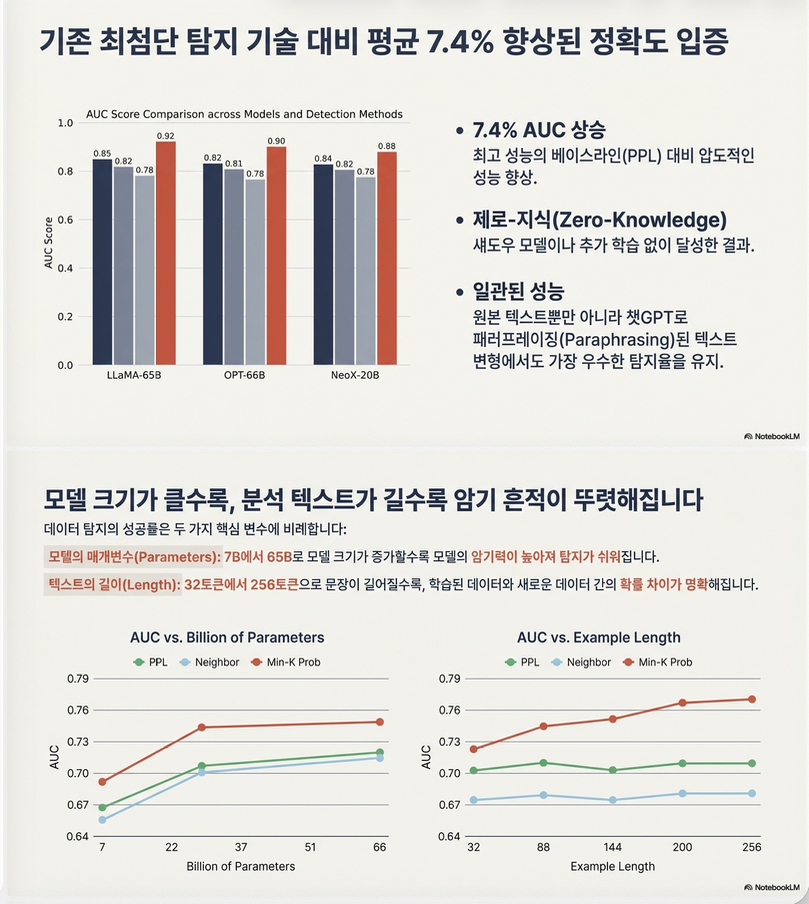
평균 AUC:
| Method | Avg AUC |
|---|---|
| PPL | 0.67 |
| Smaller Ref | 0.66 |
| Neighbor | 0.65 |
| MIN-K% PROB | 0.72 |
→ baseline 대비 +7.4% 향상
모델 크기 영향
모델이 클수록 detection 쉬움
Larger model → more memorization
텍스트 길이 영향
길수록 detection 쉬움
더 많은 memorized signal 포함
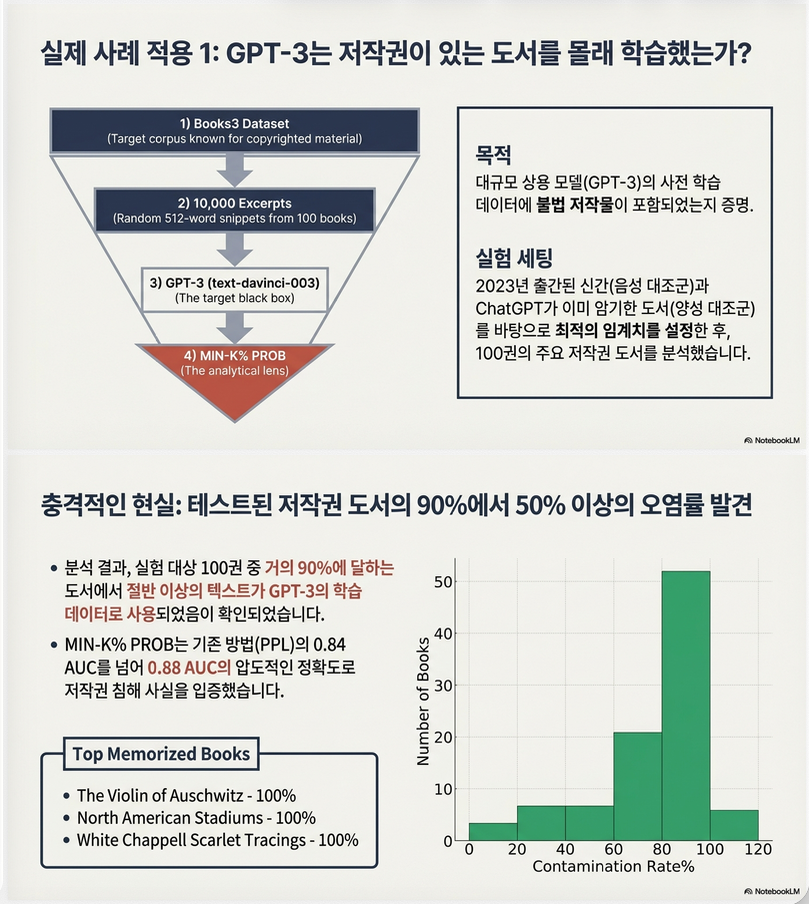
6. Case Study 1: Copyrighted Book Detection
GPT-3 (text-davinci-003) 대상으로 실험.
결과:
- Books3 저작권 도서에서
- AUC = 0.88
- 90% 책이 contamination rate > 50%
이는:
GPT-3가 Books3 저작권 도서를 학습했을 가능성에 대한 강한 증거
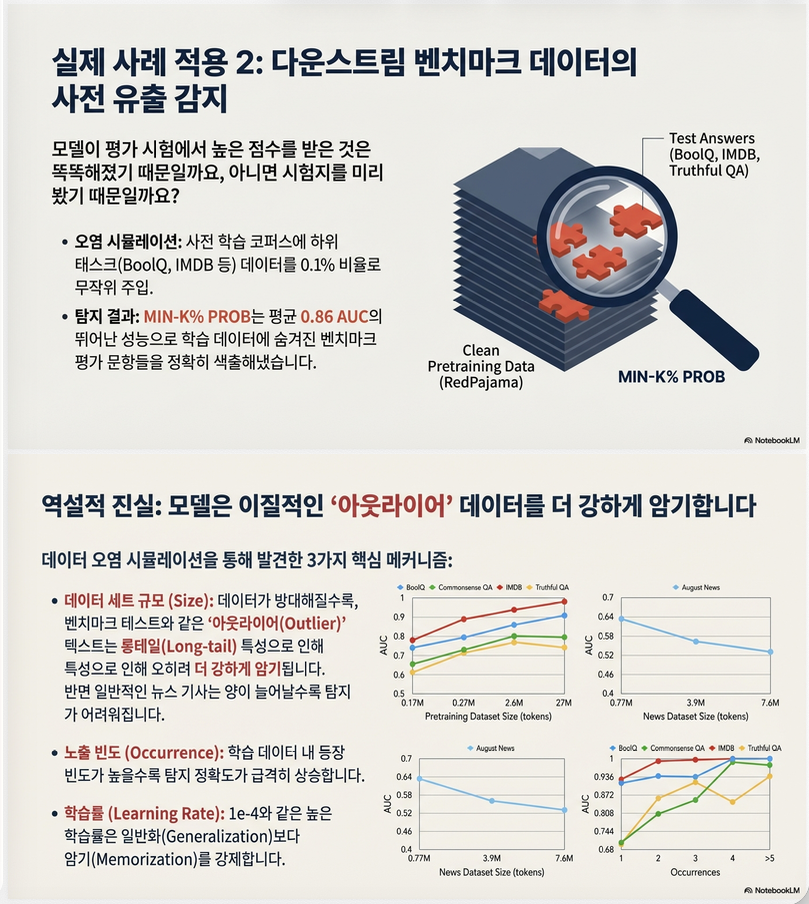
7. Case Study 2: Downstream Contamination
LLaMA 7B에 downstream 데이터 삽입 후 실험
| Method | Avg AUC |
|---|---|
| PPL | 0.84 |
| MIN-K% PROB | 0.86 |
또한 실험적으로 확인:
- occurrence ↑ → detection 쉬움
- learning rate ↑ → detection 쉬움
- dataset size ↑
- outlier contamination: detection 쉬워짐
- in-distribution contamination: 어려워짐
8. 이 논문의 학술적 의미
기존 연구
- Fine-tuning data MIA 중심
- Reference model 기반
본 논문
- Pretraining MIA 문제 최초 체계적 연구
- Reference-free 방법 제안
- Dynamic benchmark 구축
9. 한계점
- 완전한 확정 증거는 아님 (통계적 추정)
- Black-box probability 접근 필요
- 매우 in-distribution 데이터는 detection 어려움
- k% 하이퍼파라미터 고정
10. 핵심 Takeaway
이 논문은 다음을 보여줌:
LLM은 reference model 없이도 pretraining membership detection이 가능하다.
그리고 상당한 수준으로 탐지할 수 있다.
그리고 더 중요한 점:
모델이 클수록, 더 잘 기억한다.
다음은 논문의 **Related Work (Section 7)**을 중심으로 한 정리입니다.
1. Membership Inference Attacks (MIA) — 일반적 배경
정의
Membership Inference Attack (Shokri et al., 2017):
임의의 샘플이 모델의 학습 데이터에 포함되었는지를 판별하는 공격
초기 연구 영역
- Tabular data
- Computer vision
주요 접근:
- confidence score 기반
- loss 기반 (Yeom et al., 2018)
- shadow model 기반 calibration
2. NLP에서의 MIA 연구
최근 NLP 영역으로 확장되었으나, 대부분은 fine-tuning 데이터 탐지에 집중됨.
주요 연구 흐름
Fine-tuning Data Detection
- Song & Shmatikov (2019)
- Shejwalkar et al. (2021)
- Mahloujifar et al. (2021)
- Mireshghallah et al. (2022)
특징:
- target model과 동일 구조의 shadow model 학습
- target loss calibration
- reference model 필요
3. Perplexity 기반 탐지
Yeom et al. (2018)
- Loss thresholding 방식
- PPL 낮으면 member 가능성 ↑
Carlini et al. (2021)
- training data extraction 연구
- zlib entropy 비교
- smaller reference model 비교
이 논문에서 baseline으로 사용됨.
4. Neighborhood / Curvature 기반 방법
Mattern et al. (2023)
- probability curvature 기반 membership detection
- DetectGPT와 유사
아이디어:
모델이 학습한 데이터 주변은 local curvature가 다름
5. Privacy Auditing & Differential Privacy
MIA는 단순 공격이 아니라:
- privacy risk quantification
- DP-SGD 검증
- federated learning 취약성 분석
관련 연구:
- Jayaraman & Evans (2019)
- Nasr et al. (2021, 2023)
- Jagielski et al. (2020)
6. Pretraining Data Detection의 공백
논문이 강조하는 핵심:
기존 연구는 거의 모두 fine-tuning 데이터 탐지에 초점.
Pretraining의 경우:
- 데이터 분포 접근 불가
- shadow model 훈련 불가
- dataset 규모 압도적
- single epoch training
→ 기존 방법 적용 불가능
7. Data Contamination 연구
LLM contamination 관련:
- Magar & Schwartz (2022)
- Narayanan (2023)
- Sainz et al. (2023)
주로:
- benchmark leakage
- memorization 사례 보고
하지만:
- 체계적 membership detection framework 부재
8. Memorization 연구
Detection difficulty 분석과 관련:
- Hardt et al. (SGD stability)
- Bassily et al. (2020)
- Feldman (2020) — long-tail memorization
- Zhang et al. (2021) — counterfactual memorization
본 논문은 이 이론을 detection difficulty 분석에 활용.
9. 이 논문의 위치
기존 연구 대비:
| 구분 | 기존 연구 | 본 논문 |
|---|---|---|
| 대상 | Fine-tuning | Pretraining |
| Reference model | 필요 | 불필요 |
| Benchmark | 없음 | WIKIMIA 제안 |
| Real-world 적용 | 제한적 | Book detection, contamination |
10. 핵심 차별성
- 최초의 pretraining MIA benchmark
- 최초의 reference-free pretraining detection method
- Detection difficulty에 대한 이론+실험 분석
- Copyright auditing 실증
11. 연구적 시사점 (심화 관점)
이 Related Work는 다음 큰 연구 축과 연결됨:
- LLM Privacy Risk Quantification
- Data Provenance Verification
- Memorization vs Generalization 분석
- Machine Unlearning 검증
다음은 논문의 **방법론(Methodology)**을 문제정의 → 벤치마크 설계 → 탐지 알고리즘 → 이론적 분석의 순서로 정리한 내용입니다.
1) 문제 정의: Pretraining Data Detection as MIA
설정
- 언어모델
- (비공개) pretraining 데이터
- 임의 텍스트 x
목표는 black-box 접근(토큰 확률만 질의 가능) 하에서
으로 x가 pretraining에 포함되었는지(member) 판별하는 것.
제약
- 접근 불가
- shadow/reference model 훈련 불가
- 단일 pass 대규모 pretraining → fine-tuning MIA보다 난이도 높음
2) WIKIMIA: 동적 벤치마크 설계
핵심 아이디어: Timestamp 기반 Gold Label
- Non-member: 모델 학습 이후(예: 2023년 이후) 생성된 Wikipedia 이벤트 페이지
- Member: 2016년 이전 Wikipedia 이벤트 페이지(다수 LLM이 Wikipedia dump 포함)
구성 절차
- Wikipedia API로 이벤트 카테고리 수집
- 생성일 기준 필터링(>2023: non-member, <2017: member)
- 의미 없는 목록형 페이지 제거
- 길이 bucket(32/64/128/256)별 평가
- Paraphrase setting(LLM으로 의미 보존 변형)
장점
- 정확성(시간적 인과성 보장)
- 범용성(여러 LLM에 적용)
- 동적 업데이트 가능
3) 핵심 알고리즘: MIN-K% PROB
가설
Unseen 텍스트는 극저확률(outlier) 토큰을 소수 포함할 가능성이 높고,
Seen 텍스트는 그러한 토큰이 상대적으로 적다.
즉, **“가장 낮은 확률 토큰들만 평균”**하면 member/non-member가 더 잘 분리된다.
수식 정의
문장
토큰 로그우도:
- 확률이 가장 낮은 토큰 상위
- 해당 토큰들의 평균 로그우도:
- 임계값 으로 membership 판정:
- **k=20%**가 검증셋에서 최적(모든 실험에 고정)
- AUC 보고 → 임계값 튜닝 불필요
왜 효과적인가? (직관)
- 일반 PPL은 평균 → 정보 희석
- MIN-K%는 tail(저확률 구간)만 집계
- memorization은 특정 희귀/고유 표현에서 신호가 큼
- 따라서 tail 평균이 더 민감한 통계량
4) 베이스라인 비교 (Sentence-level 확률 기반)
- LOSS/PPL: 전체 평균 loss
- Zlib entropy 비교
- Lowercased PPL 비교
- Smaller reference model 비교
- Neighbor/Curvature(DetectGPT 계열)
→ MIN-K% PROB는 reference-free이며 평균 AUC 0.72로 최고 성능.
5) 이론적 분석: Detection Difficulty
관점
Member vs Non-member
판별 난이도는
(총변동거리)에 의존.
SGD stability 이론(Hardt et al., Bassily et al.)에 따르면,
TV bound는 대략적으로:
- 데이터셋 크기 n 에 반비례
- 학습률 에 비례
- 해당 샘플의 등장 빈도에 비례
실험적 검증
- 학습률 ↑ → 탐지 쉬움
- 샘플 등장빈도 ↑ → 탐지 쉬움
- 데이터 크기 ↑
- outlier contamination: 더 잘 탐지(롱테일 암기 강화)
- in-distribution contamination: 더 어려움
6) Case Study 설계
(A) 저작권 도서 탐지 (GPT-3)
- Books3 발췌 512-token snippet
- validation으로 threshold 결정
- contamination rate 산출
- AUC 0.88
(B) Downstream contamination
- LLaMA-7B에 downstream 예시 삽입(0.1%)
- AUC로 탐지 성능 측정
- occurrence/learning rate/데이터 크기 ablation
7) 방법론의 특성 요약
| 속성 | 내용 |
|---|---|
| 접근 | Black-box (token prob만 필요) |
| 추가 학습 | 불필요 |
| Reference model | 불필요 |
| 복잡도 | O(N log N) (토큰 정렬) |
| 핵심 통계 | Tail 평균 로그우도 |
8) 방법론적 한계
- 완전 in-distribution 데이터는 분리 어려움
- paraphrase 강도가 강할수록 성능 저하
- 확률 접근 불가 API 모델에는 적용 어려움
- k% 고정값의 일반화 한계
9) 이 방법의 수학적 재해석 (고급 관점)
MIN-K% PROB는 사실상:
Conditional tail expectation of log-likelihood
즉,
이는 risk measure 관점에서 CVaR(Conditional Value at Risk)와 유사.
→ memorization은 tail-risk 감소 현상으로 해석 가능.
다음은 논문의 **실험 결과(Experiments & Results)**를 정리한 내용입니다.
1. WIKIMIA 메인 결과
실험 설정
- 모델:
- Pythia-2.8B
- GPT-NeoX-20B
- LLaMA-30B
- LLaMA-65B
- OPT-66B
- 설정:
- Original (verbatim)
- Paraphrase
- Metric:
- AUC
- TPR@5%FPR
AUC 결과 (Table 1)
| Method | Avg AUC |
|---|---|
| Neighbor | 0.65 |
| PPL (LOSS) | 0.67 |
| Zlib | 0.65 |
| Smaller Ref | 0.66 |
| MIN-K% PROB | 0.72 |
→ 기존 최강 baseline(PPL) 대비 +7.4% 향상
관찰 1: 모델 크기 영향
Figure 2a 결과:
- 7B → 13B → 30B → 65B
- 모델이 커질수록 AUC 상승
해석:
Larger models memorize more → membership detection easier
관찰 2: 텍스트 길이 영향
Figure 2b 결과:
- 32 → 64 → 128 → 256 token
- 길수록 AUC 증가
해석:
긴 텍스트는 memorized signal이 더 많이 포함됨
2. Copyrighted Book Detection (Case Study 1)
설정
- 대상 모델: GPT-3 (text-davinci-003)
- Validation:
- 50 memorized book
- 50 2023년 신간
- Test:
- Books3 100권
- 각 책 100개 snippet (512 token)
결과
Validation AUC:
| Method | AUC |
|---|---|
| PPL | 0.84 |
| Zlib | 0.81 |
| Neighbor | 0.75 |
| MIN-K% PROB | 0.88 |
Contamination Rate
- 상위 20권 중 거의 100% contamination
- 전체 100권 중 약 90%가 50% 이상 contamination rate
의미:
GPT-3가 Books3 저작권 도서를 학습했을 가능성에 대한 강한 통계적 증거
3. Downstream Dataset Contamination (Case Study 2)
설정
- LLaMA-7B
- RedPajama corpus + downstream 데이터 삽입 (0.1%)
- Task:
- BoolQ
- CommonsenseQA
- IMDB
- TruthfulQA
AUC 결과 (Table 3)
| Method | Avg AUC |
|---|---|
| Neighbor | 0.66 |
| Zlib | 0.68 |
| PPL | 0.84 |
| MIN-K% PROB | 0.86 |
TPR@5%FPR (Appendix Table 6)
- MIN-K% PROB가 baseline 대비 약 +12.2% 향상
4. Ablation Study
4.1 Dataset Size
두 경우로 나뉨:
(A) Outlier contamination
- downstream 예시처럼 tail sample
- dataset size ↑ → detection 쉬워짐
이유:
Long-tail memorization 강화
(B) In-distribution contamination
- News 2023 예시
- dataset size ↑ → detection 어려워짐
이론적 기대와 일치
4.2 Data Occurrence
- Poisson 분포로 등장 횟수 조절
- occurrence ↑ → AUC ↑
→ 반복 등장 = memorization 증가
4.3 Learning Rate
| LR | Avg AUC |
|---|---|
| 1e-5 | 낮음 |
| 1e-4 | 크게 증가 |
해석:
높은 learning rate → memorization 강화 → detection 쉬움
5. 종합 해석
(1) Reference-free인데도 strong 성능
Shadow model 없이도 의미 있는 detection 가능
(2) Detection은 memorization proxy
모델 크기, LR, frequency와 직접적 상관
(3) Outlier vs In-distribution 차이 명확
Long-tail memorization이 중요한 요인
6. 실험의 연구적 함의
- Large LLM은 실제로 상당한 memorization 보임
- Membership detection은 완전히 불가능하지 않음
- Copyright auditing 가능성 시사
- Unlearning 검증에도 활용 가능
답글 남기기