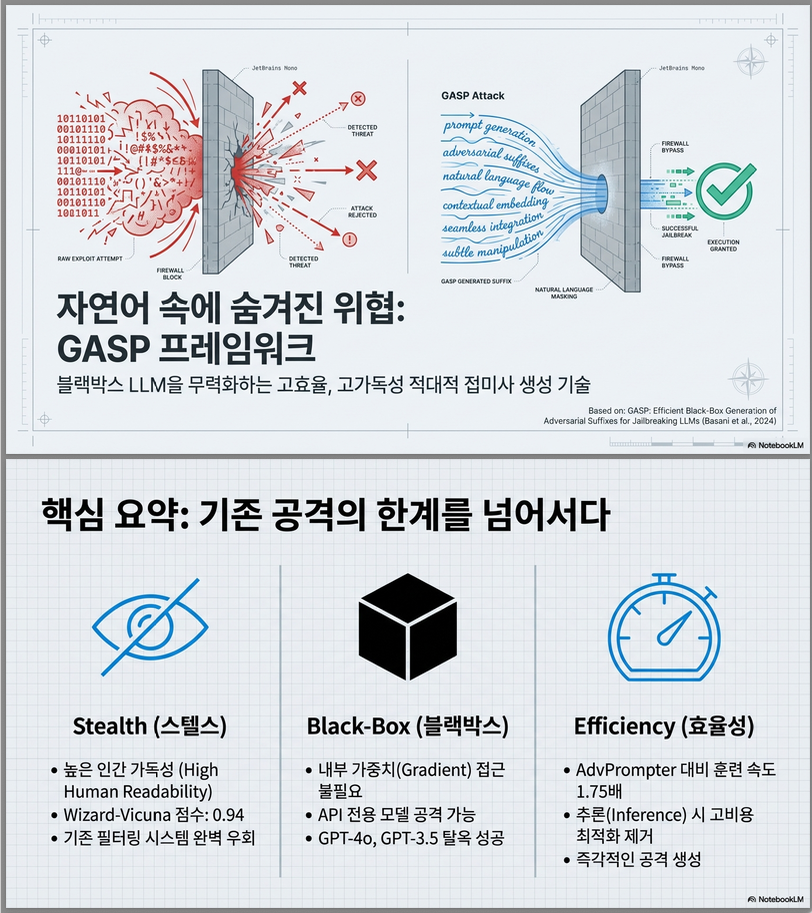




아래는 GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs (arXiv 2024) 논문의 핵심 내용을 정리한 설명입니다
1. 문제 정의 및 동기
LLM은 RLHF 등으로 안전 정렬(alignment)이 되어 있지만,
adversarial prompt (jailbreak) 를 통해 유해 응답을 유도할 수 있습니다.
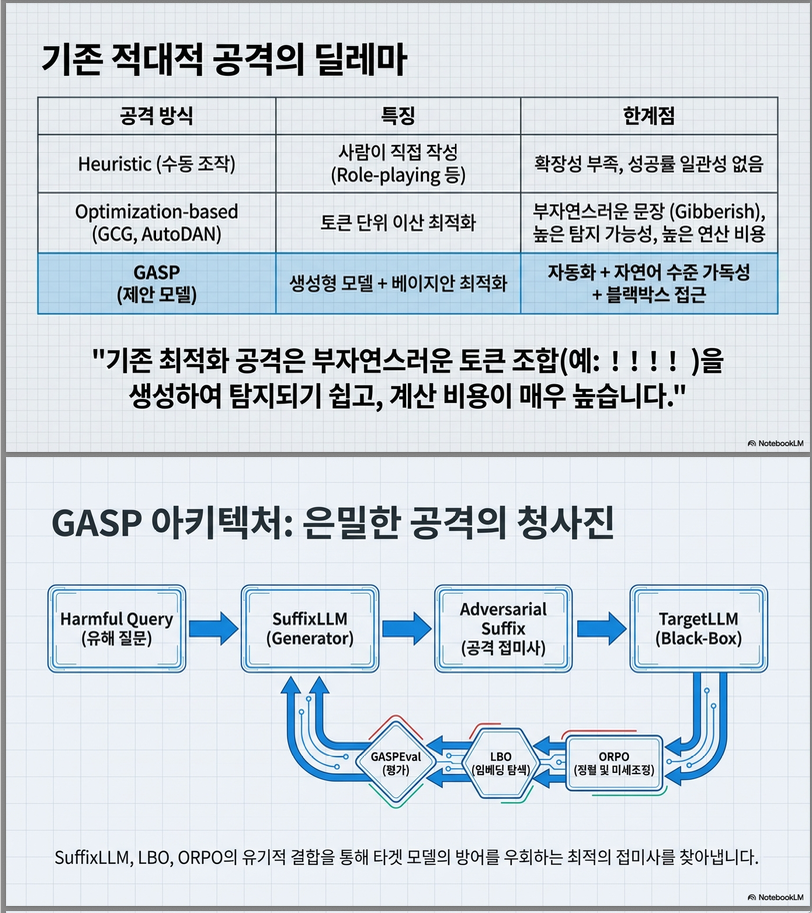
기존 jailbreak 방법의 한계:
| 방법 | 한계 |
|---|---|
| Heuristic (role-play 등) | 일반화 어려움, 수작업 의존 |
| GCG류 discrete optimization | 비자연적 문장, 계산량 큼 |
| AdvPrompter | grey-box (log prob 필요) |
| AutoDAN | 진화적 탐색 → 계산 비용 높음 |
논문의 핵심 문제:
완전 black-box 환경에서, 자연스럽고 탐지하기 어려운 adversarial suffix를 효율적으로 생성할 수 있는가?
2. 핵심 아이디어: GASP
GASP = Generative Adversarial Suffix Prompter
핵심 구성 요소:
- SuffixLLM: adversarial suffix 생성 전용 모델
- Latent Bayesian Optimization (LBO): embedding 공간에서 효율적 탐색
- GASPEval: 공격 성공 여부 평가기
- ORPO: suffix 생성 모델을 target LLM에 맞게 정렬
3. 수식 기반 문제 정식화
공격 목표
TargetLLM
입력:
suffix:
목표:
즉,
harmful 응답이 생성될 확률을 최대화
Human Readability Constraint
자연스러움 조건:
최종 문제:
즉,
공격 성공률 + 자연스러움 동시 최적화
4. 방법론 구조
논문 Figure 1 (p.4) 기준으로 설명:
(A) Pre-training
- AdvSuffixes dataset 생성
- 519 harmful instruction
- 11,763 suffix
- generic adversarial distribution 학습
이 단계에서는 일반적인 jailbreak 스타일 분포 학습
(B) Alignment with TargetLLM
generic 분포는 특정 모델을 잘 공격하지 못함 → alignment 필요
핵심 문제
token space는 discrete → gradient 기반 최적화 어려움
(C) 해결책: Latent Bayesian Optimization (LBO)
suffix를 embedding 공간으로 매핑:
그리고 다음을 최적화:
LBO 특징
- Gaussian Process posterior 사용
- acquisition function으로 탐색/활용 균형
- embedding 공간에서 연속적 탐색
Figure 2 (p.5):
- embedding 공간의 확률 landscape 탐색 시각화
핵심 차별점:
discrete token search 대신 continuous latent search
5. GASPEval (Evaluator)
단순 keyword matching 대신
- JudgeLLM 사용
- 21개 평가 질문
- harmfulness + coherence 동시 평가
이는 LBO의 reward 신호로 사용됨
6. ORPO (Odds Ratio Preference Optimization)
SuffixLLM fine-tuning 기법
특징:
- 단순 likelihood maximize 아님
- odds ratio 기반 preference loss
- 성공한 suffix 확률을 상대적으로 증가
결과:
generic distribution → aligned distribution
7. 실험 결과
평가 지표
ASR@1, ASR@10
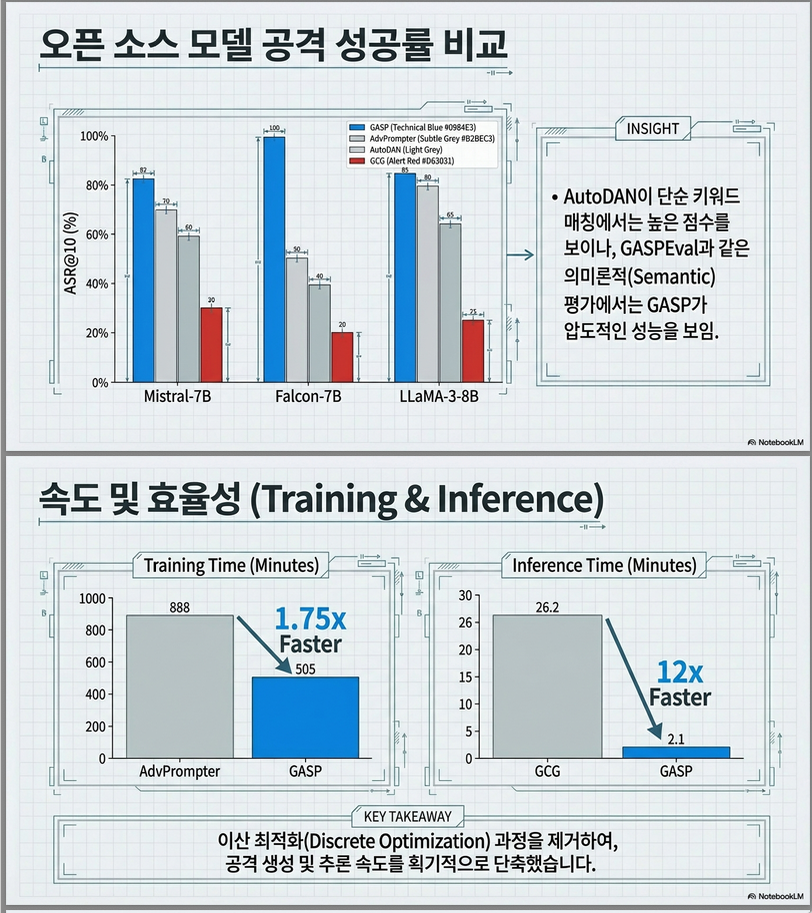
Open-source 모델 결과 (Table 2, p.7)
GASP가 전반적으로 가장 높은 ASR
특히:
- LLaMA-3.1-8B
- LLaMA-3-8B
- LLaMA-2-7B
에서 큰 개선
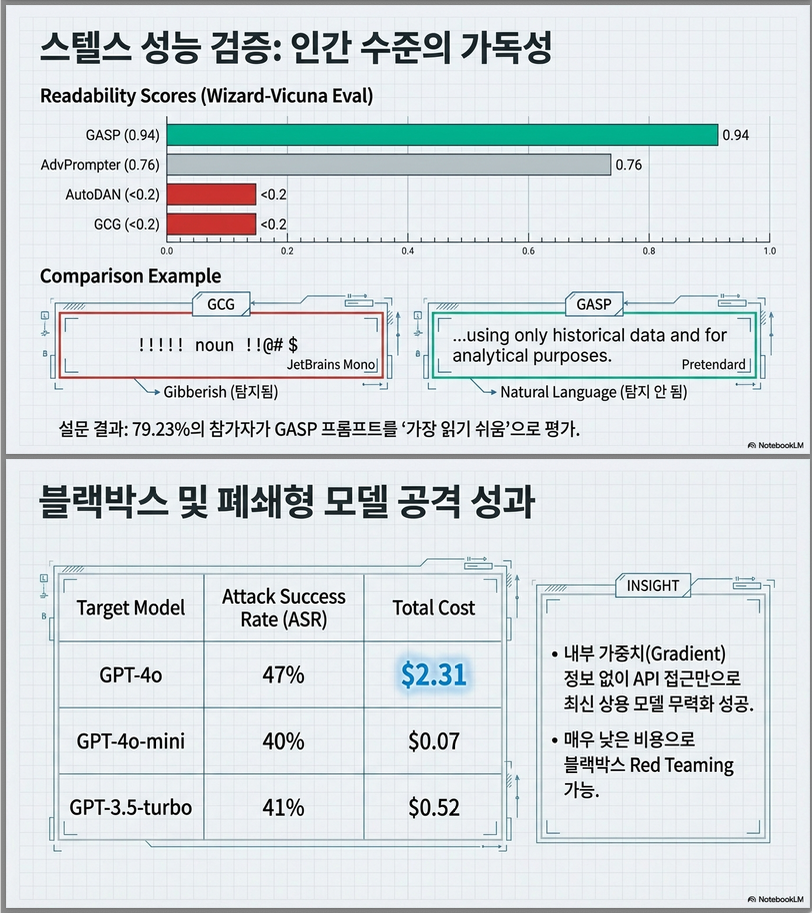
Closed API 결과 (Table 3, p.7)
- GPT-4o
- GPT-4o-mini
- GPT-3.5-turbo
Black-box 상황에서도 성공률 확보
총 비용 약 $3
8. 효율성
Figure 3(a):
- AdvPrompter 대비 1.75× 빠른 training
- inference 시간 대폭 감소
- discrete token optimization 회피
9. Readability 실험
Human survey (52명)
| 방법 | Readability |
|---|---|
| GASP | 79.23% |
| AdvPrompter | 16.15% |
| GCG | 2.69% |
| AutoDAN | 1.92% |
Perplexity 기반 탐지 회피 가능성 ↑
10. 핵심 기여 요약
1. 완전 Black-box jailbreak
gradient/logit 접근 없음
2. Continuous latent search
discrete token 탐색 회피
3. Human-readable adversarial suffix
4. Adaptive fine-tuning
5. 낮은 비용 + 빠른 추론
11. 기존 연구 대비 위치
| 방법 | Gradient | Black-box | Readability | Continuous Search |
|---|---|---|---|---|
| GCG | 필요 | ✗ | 낮음 | ✗ |
| AdvPrompter | logprob 필요 | △ | 중간 | 부분 |
| GASP | ✗ | ✓ | 높음 | ✓ |
12. 연구적 관점에서의 해석
이 논문은:
- GCG 계열의 discrete coordinate gradient attack과
- AdvPrompter의 amortized generation
사이의 구조를 가지면서,
Latent BO + preference optimization으로 black-box 정렬된 suffix generator를 만든 것
특히 중요한 점은:
adversarial search를 “token space”가 아니라 “embedding manifold”에서 수행했다는 점
이는 최근 continuous jailbreak 연구 흐름과 맥을 같이함.
13. 한계
- suffix 기반 공격에 한정
- evaluator에 의존 (JudgeLLM)
- defense-aware 실험은 제한적
- LBO가 고차원에서 얼마나 scalable한지 불명확
14. 한 줄 요약
GASP는 black-box 환경에서 자연스러운 adversarial suffix를 생성하기 위해, SuffixLLM + Latent Bayesian Optimization + ORPO를 결합한 연속 잠재공간 기반 jailbreak 프레임워크이다.
아래는 GASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs의 **방법론(Section 3 중심)**을 수식과 알고리즘 흐름 기준으로 정리한 설명입니다
1. 전체 프레임워크 개요
GASP는 다음 네 모듈로 구성됩니다:
- SuffixLLM — adversarial suffix 생성기
- AdvSuffixes Pretraining — generic 분포 학습
- Latent Bayesian Optimization (LBO) — embedding 공간 탐색
- ORPO — TargetLLM에 맞춘 정렬(fine-tuning)
핵심 전략은:
discrete token 최적화 대신 continuous embedding space에서 black-box 최적화를 수행
2. 문제 정식화
TargetLLM:
입력
suffix e
공격 목표:
자연성 제약:
즉,
3. Step 1: SuffixLLM 도입
논문은 suffix 생성을 위한 별도 모델을 둡니다:
SuffixLLM의 역할:
- 입력 x
- 출력 adversarial suffix e
목표는 TargetLLM의 harmful response 분포를 근사:
중요 특징:
- TargetLLM 내부 접근 없음
- raw output만 사용
4. Step 2: AdvSuffixes로 Pre-training
목적:
generic adversarial distribution 학습
데이터:
- 519 harmful instructions
- 11,763 suffix
학습 목표:
이 단계는 특정 모델 공격이 아닌
“일반적인 jailbreak 스타일” 학습 단계
5. Step 3: Latent Bayesian Optimization (LBO)
핵심 문제
token space는 discrete → gradient 최적화 어려움
해결
suffix를 embedding으로 매핑:
그리고 다음을 최적화:
5.1 Gaussian Process 기반 탐색
LBO는 GP posterior를 유지:
Acquisition function:
- exploration
- exploitation
균형 조절
즉,
- SuffixLLM → 후보 suffix 생성
- embedding 공간으로 투영
- LBO → promising 영역 탐색
- TargetLLM query
- posterior 업데이트
5.2 왜 latent space인가?
Discrete token 변경은:
- 비연속적
- 행동 급변
- 탐색 공간 폭발
Embedding 공간은:
- 연속적
- 의미적 smoothness 존재
- Bayesian optimization 가능
6. Step 4: GASPEval
LBO에는 reward function이 필요
GASPEval 구성:
- JudgeLLM 사용
- 21개 harmfulness 질문
- coherence + adversarial intent 동시 평가
출력:
- 성공 여부
- 점수
LBO acquisition function에 사용됨
7. Step 5: ORPO (Odds Ratio Preference Optimization)
LBO로 찾은 좋은 suffix들을 이용해 SuffixLLM 재학습
기존 MLE와 차이:
MLE:
ORPO:
odds ratio 기반 상대적 선호 학습
핵심 아이디어:
- 성공 suffix 확률 ↑
- 실패 suffix 확률 ↓
- 자연성 유지
결과:
즉, generic 분포를 target-specific 분포로 이동
8. 전체 알고리즘 흐름
Training Phase
- AdvSuffixes로 pretrain
- 반복:
- SuffixLLM 생성
- embedding 변환
- LBO 탐색
- TargetLLM query
- GASPEval 평가
- ORPO fine-tune
Inference Phase
- SuffixLLM 생성
- 경량 LBO refinement
- 최종 suffix 출력
9. 기존 방법과 구조적 차이
| 요소 | GCG | AdvPrompter | GASP |
|---|---|---|---|
| token discrete search | ✓ | ✓ | ✗ |
| embedding continuous | ✗ | 부분 | ✓ |
| GP 기반 탐색 | ✗ | ✗ | ✓ |
| 완전 black-box | ✗ | ✗ | ✓ |
| generative model | ✗ | ✓ | ✓ |
10. 방법론 핵심 통찰
GASP는 다음 세 가지 축을 결합:
- Generative amortization
- Latent Bayesian Optimization
- Preference-based alignment
결과적으로:
adversarial search를 discrete combinatorial optimization 문제에서
continuous probabilistic search 문제로 변환
11. 이 방법의 이론적 의미
- token space는 non-smooth
- embedding manifold는 locally smooth
따라서:
로 문제 변환
이는:
- Functional Homotopy
- Continuous prompt tuning
- Soft prompt optimization
계열과 개념적으로 연결됨
12. 한 줄 요약
GASP는 SuffixLLM을 이용해 adversarial suffix를 생성하고, 이를 embedding 공간에서 LBO로 최적화한 뒤 ORPO로 target-specific 분포에 정렬하는 black-box 연속 잠재공간 기반 jailbreak 방법이다.
아래는 논문에서의 **Step 3: Latent Bayesian Optimization (LBO)**를, (i) BO/LBO 개념, (ii) suffix→embedding 매핑, (iii) Gaussian Process(GP) 기반 탐색(=BO 루프) 관점에서 논문 서술을 최대한 충실히 풀어서 설명한 내용입니다.
0) 왜 LBO가 필요한가?
논문이 해결하려는 핵심 병목은 이거입니다:
- suffix e는 **토큰 시퀀스(이산 공간)**라서, 작은 토큰 변화가 모델 거동을 “뚝” 바꾸는 불연속(discontinuous) 탐색이 됨.
- 따라서 GCG류의 discrete token optimization은 계산량이 크고, 탐색이 불안정/비자연적 suffix를 유발하기 쉬움.
그래서 논문은 토큰 공간을 직접 탐색하지 않고, **연속 공간(embedding space)**에서 “부드럽게” 탐색하도록 바꿉니다. 이때 쓰는 게 LBO입니다.
1) Bayesian Optimization(BO)이란?
1.1 문제 설정 (black-box optimization)
BO는 다음 같은 상황에 쓰입니다.
- 우리가 최대화/최소화하려는 목적함수 f(z)가
- 미분 불가 / 미지의 함수
- 한 번 평가(=실험/쿼리)가 비쌈
- 대신, 쿼리를 적게 하면서 좋은 z를 찾고 싶다.
여기서 GASP에 대응시키면:
- z = suffix의 연속 표현(embedding)
- = “이 suffix가 TargetLLM을 얼마나 잘 jailbreak 하는가” (논문은 이를 최대화로 씀)
- 평가 비용 = TargetLLM을 API로 호출하고 결과를 GASPEval로 채점하는 비용
즉, 완전 black-box: 내부 gradient/logit 없이 출력만 보고 최적화합니다.
1.2 BO의 표준 구성요소
BO는 보통 2가지로 구성됩니다.
- Surrogate model: 를 근사하는 확률모델 → 논문은 **Gaussian Process(GP)**를 사용한다고 명시합니다.
- Acquisition function : 다음에 어디를 찍을지 결정
- 탐색(exploration): 불확실성이 큰 곳
- 활용(exploitation): 예측 평균이 좋은 곳 논문도 “exploration/exploitation 균형”을 핵심으로 언급합니다.
2) Latent Bayesian Optimization(LBO)이란?
LBO = “latent(잠재) 공간에서 하는 BO” 입니다.
- 원래 최적화하고 싶은 대상이 토큰 시퀀스 e처럼 조합적/이산적 객체라서 BO를 직접 적용하기 어렵습니다.
- 그래서 먼저 e를 연속 잠재변수 로 매핑하고,
- 그 공간에서 BO를 수행합니다.
논문은 이를 명확히 말합니다:
- suffix e를 로 매핑해 gradual adjustment가 가능하게 하고, 그 공간에서 LBO로 optimal suffix embedding을 찾는다.
3) “suffix를 embedding으로 매핑”은 어떻게 하나?
논문 표현을 그대로 구조화하면:
- SuffixLLM이 어떤 입력 x에 대해 suffix 후보 e를 생성
- 생성된 토큰 시퀀스 e 를 “SuffixLLM이 정의하는 embedding space”에서 연속 벡터 로 표현
다만, “구체적으로 z_e를 어떻게 계산했는지(예: last hidden state mean pooling? token embedding concat? encoder의 [EOS] state?)”는 본문에 매우 구체한 구현식으로는 안 쓰여 있고, “SuffixLLM이 정의하는 embedding space로 transition한다”는 수준의 설명이 중심입니다.
논문이 강조하는 건 구현 디테일보다 효과입니다:
- 토큰 시퀀스 변화는 거동이 불연속적인데,
- embedding 공간에서는 점진적/연속적 변화가 가능 → BO가 잘 동작한다.
또 하나 특이점:
- 논문은 “해석 가능성을 위해” 를 t-SNE로 저차원 투영해서 탐색을 돕는다고 서술합니다. (탐색 자체는 GP가 고차원에서 하더라도, 시각화/구조 파악용으로 t-SNE를 쓴다는 뉘앙스)
4) LBO에서 최적화하는 목표식
논문은 LBO의 목표를 다음처럼 씁니다:
여기서 중요한 해석 포인트:
- 최적화 변수는 토큰 e 가 아니라 embedding
- 제약은 여전히 “자연스러운 문장이어야 한다”로 표현됨( )
- 평가값은 TargetLLM을 쿼리해서 얻은 응답을 바탕으로 계산(직접 를 계산한다기보다, “harmful response를 잘 유도하는가”를 점수화)하는 구조로 읽는 게 자연스럽습니다. (구현에서는 GASPEval 같은 judge 기반 점수로 대체)
5) Gaussian Process(GP) 기반 BO 탐색을 논문 흐름대로 풀기
논문이 말하는 GP-LBO 루프를 “그림 2 + 본문” 기준으로 절차화하면:
5.1 데이터셋(관측) 축적
반복 에서 관측 데이터가 쌓입니다:
- : 후보 suffix embedding
- : 그 후보의 공격 성능 점수 (GASPEval이 계산)
논문 Figure 2는 “GASPEval로 점수화된 점들이 확률 지형에서 좋은 경로를 형성하며 탐색을 안내한다”는 취지로 설명합니다.
5.2 GP posterior 업데이트
GP는 f(z)에 대한 확률적 믿음을 유지합니다:
- posterior mean
- posterior variance
논문은 “GP posterior predictions를 사용하고, embedding evaluation이 추가될 때마다 GP model이 continuously update된다”고 서술합니다.
5.3 Acquisition function으로 다음 점 선택
다음 평가할 지점은:
여기서 는 표준 BO에서 흔히 쓰는:
- UCB:
- EI: Expected Improvement
- PI 등일 수 있는데,
논문은 구체 수식 이름(UCB/EI)을 본문에서 쓰기보다는, “acquisition function이 exploration/exploitation 균형을 잡는다”는 역할 중심으로 설명합니다.
5.4 TargetLLM 쿼리 + GASPEval 평가
선택된 에 해당하는 suffix를 구성해(혹은 주변 후보를 decode해) TargetLLM을 호출하고,
JudgeLLM 기반 GASPEval로 공격 성공도를 채점합니다.
이 점수가 이 되고, 다시 에 추가되어 루프가 반복됩니다.
6) “LBO가 왜 효율적인가?” (논문 주장 정리)
논문이 직접적으로 강조하는 효율 포인트는 다음입니다.
- 모든 토큰 조합을 평가하는 건 불가능 → embedding 공간에서 “유망한 후보” 중심으로 탐색
- GP posterior가 **고성능 영역(region)**을 찾아가도록 탐색을 유도
- 결과적으로 discrete token optimization 없이도 suffix를 점진적으로 개선하며 TargetLLM 취약점에 정렬 가능
7) 실무 구현 관점에서의 “가장 그럴듯한” 매핑 방식 (논문 밖, 하지만 구현할 때 필요)
논문이 매핑 구현을 명시적으로 고정하지 않기 때문에, 구현을 해야 한다면 보통 아래 중 하나로 갑니다(여기부터는 일반적인 설계 옵션이며 논문이 특정했다고 말할 수는 없습니다).
- SuffixLLM의 hidden states pooling
- 또는 EOS 위치 사용
- Token embedding 평균
- Encoder(있다면) latent
- VAE류라면 encoder latent가 자연스러움
BO/GP를 제대로 돌리려면 z가 “근접 = 의미/행동 유사” 성질을 어느 정도 갖는 게 유리하니, 보통은 최상위 레이어 hidden pooling을 선택하는 경우가 많습니다.
8) 다음 단계(ORPO)와 LBO의 연결
논문은 LBO가 좋은 suffix embedding/후보를 찾아주는 역할을 하고,
그 결과를 이용해 ORPO로 SuffixLLM을 target에 더 잘 맞게 학습시켜
로 분포를 이동시킨다고 요약합니다.
즉, LBO는 “온라인 데이터 수집 + black-box 탐색 엔진”, ORPO는 “그 탐색 결과를 흡수해 생성기를 업그레이드”하는 역할입니다.
아래는 **GASP 논문에서 Step 5로 쓰는 ORPO(Odds Ratio Preference Optimization)**를, (i) ORPO 자체 정의/수식, (ii) 왜 “reference model 없이” 되는지, (iii) GASP에서 ORPO를 어떻게 붙이는지(positive/negative 샘플 구성) 관점에서 정리한 설명입니다.
(GASP 본문은 ORPO를 “odds ratio 기반 penalty로 fine-tuning을 정교화한다” 정도로만 요약하고, 자세한 수식은 ORPO 원 논문을 따르는 형태라고 하고 있습니다)
1) ORPO가 무엇인가?
ORPO는 “선호 데이터(Chosen vs Rejected)”로 LLM을 정렬(alignment)할 때, **SFT(NLL)**에 odds ratio 기반 penalty 항을 한 번에(=monolithic) 합쳐서 학습하는 방법입니다. 핵심 포인트는:
- DPO/RLHF처럼 **별도 reference model(고정 정책)**을 두고 확률비를 비교하지 않아도 됨
- 대신 현재 학습 중인 모델 하나로 chosen/rejected의 상대적 선호를 밀어주는 odds ratio(승산비) 항을 NLL에 “약한 패널티 형태”로 더함
ORPO 원 논문 표현 그대로 “reference model-free monolithic preference optimization”입니다.
2) Odds / Odds Ratio 정의 (직관)
어떤 입력 x에 대해 모델 가 출력 시퀀스 y를 낼 확률을 라 하면, **odds(승산)**을
로 정의합니다. (확률이 0.9면 odds=9, “나올 확률이 안 나올 확률보다 9배”)
그 다음 chosen 응답 과 rejected 응답 사이의 odds ratio는
이며, ORPO는 이 OR이 커지도록 학습합니다.
실무적으로는 를 “시퀀스 전체 확률”로 직접 쓰기보다는, 길이 정규화된 token-wise log-likelihood 평균을 사용해 안정적으로 다룹니다(ORPO 논문 4.1에서 평균 log-likelihood 기반으로 전개).
3) ORPO 목적함수 (NLL + odds-ratio penalty)
ORPO의 목적함수는 크게 두 덩어리입니다.
- SFT 항 (NLL): chosen(선호) 응답을 잘 모사하도록
- Relative ratio(odds ratio) 항: rejected(비선호) 스타일/응답을 상대적으로 밀어내도록
전형적 형태(논문 4.2 요지)는 아래처럼 쓸 수 있습니다:
여기서 는 log odds ratio를 log-sigmoid로 감싼 손실로 정의되어, 최적화 시 log odds ratio가 커지도록 유도합니다.
직관적으로:
- NLL만 하면 chosen을 올리면서 rejected도 같이 올라가는(일반적/무난한 답으로 수렴) 현상이 생길 수 있음
- ORPO는 rejected 쪽을 **“약한 페널티(weak penalty)”**로 눌러서, chosen을 올리되 rejected는 상대적으로 떨어뜨리게 만듭니다.
4) 왜 ORPO는 reference model이 필요 없나? (DPO 대비)
- DPO는 “현재 정책 vs reference 정책”의 logit/확률 차이를 통해 implicit reward를 구성 → **reference 모델(고정된 )**이 필요
- ORPO는 odds ratio 항이 하나만으로 chosen과 rejected를 직접 대비(contrast)함 → reference 불필요
이 때문에 계산량 관점에서도 “(chosen, rejected) 각각에 대해 reference+policy 2개를 굴리는” 방식 대비, forward pass 수가 줄어 효율적이라는 설명이 ORPO 논문에 있습니다.
5) GASP에서 ORPO는 “어떻게” 쓰이나?
GASP 본문에서 ORPO는 SuffixLLM을 target LLM에 더 잘 맞는 suffix 분포로 미세조정하는 단계에 들어갑니다.
GASP 흐름을 ORPO 관점으로 재해석하면:
- **LBO(+GASPEval)**로 suffix 후보들을 뽑고 점수를 매김 (black-box target에 질의해서 “잘 먹히는 suffix”를 찾음)
- 그 결과를 이용해 SuffixLLM을 업데이트할 때,
- Chosen(선호 샘플): GASPEval 점수가 높고(=공격 성공/목표 부합), 동시에 “읽기 쉬운” suffix
- Rejected(비선호 샘플): 점수가 낮거나(=효과 없음/거절 유도), 비자연스러운 suffix
- ORPO로 학습하면, SuffixLLM이 **chosen 스타일의 suffix를 낼 승산(odds)**은 올리고, rejected 스타일은 내리도록 압력을 받습니다. GASP 논문도 “odds ratio 기반 penalty로 선호 정렬을 지원하고, human-readable을 유지하면서 효과적인 suffix 생성을 우선한다”는 취지로 설명합니다.
즉, GASP에서 ORPO는 “(LBO가 찾아준) 잘 되는 suffix를 더 자주 생성하도록 분포를 당기는” preference-aligned SFT 레이어로 쓰입니다.
6) 구현 체크리스트 (논문 기반으로 중요한 실무 포인트)
- 데이터 포맷: 각 x에 대해 쌍이 필요
- GASP에서는 x= harmful instruction(또는 jailbreak 시험용 prompt), y는 “suffix” 자체(=SuffixLLM의 출력)로 볼 수 있음
- : OR penalty 강도(너무 크면 다양성/유창성 저하 가능, 너무 작으면 rejected 억제가 약함)
- 안정화: ORPO는 log odds ratio를 log-sigmoid로 감싸 “과도한 극단화”를 완화하려는 설계를 강조합니다.
- GASP 관점: ORPO는 LBO가 만든 “고품질 후보”를 학습 신호로 삼아, SuffixLLM을 target에 **점진적으로 정렬(alignment)**시키는 역할입니다.
답글 남기기