아래는 ICLR 2025 Building Trust Workshop에 게재된
“Interpretable Steering of Large Language Models with Feature Guided Activation Additions (FGAA)” 논문의 전체 구조와 핵심 내용을 체계적으로 정리한 설명입니다.
1. 논문의 핵심 문제의식
LLM의 행동을 원하는 방향으로 제어하는 것은 매우 중요한 난제이다.
기존 접근 방식은 크게 다음 두 가지 문제가 있었다:
(1) Fine-tuning
- 효과적이지만 비용이 매우 높고
- 안전성·로버스트니스 확보가 어렵다.
(2) Prompt 기반 제어
- 비교적 쉽지만 일관성이 부족하며
- 특정 상황에서 쉽게 무력화된다.
(3) Activation Steering(활성화 조작)
Transformer 내부의 residual stream에 벡터를 더해 행동을 바꾸는 방식.
그러나 기존 CAA(Contrastive Activation Addition), SAE-TS(SAE Targeted Steering) 등은
정확성 부족, 해석 가능성 제한, 출력 품질 저하라는 문제가 있었다.
2. FGAA(Feature Guided Activation Additions)의 핵심 기여
FGAA는 CAA + SAE-TS의 장점을 결합하여
SAE의 latent feature 공간에서 정확하고 해석 가능한 방식으로 steering 벡터를 구성하는 기법이다.
FGAA가 제공하는 핵심 개선점:
✔ SAE latent 공간에서 contrastive 분석
→ 더 구조화된 semantically meaningful feature 차이를 추출한다.
✔ Feature filtering (밀도 필터링, BOS feature 제거, 상위 top-k feature 선택)
→ steering vector에서 불필요하거나 해롭고 일반적인 feature 제거.
✔ Linear Effect Approximator를 이용한 최적화
→ LLM이 실제로 해당 latent feature를 어떻게 변화시킬지 추정하여
최적의 steering 벡터를 계산.
✔ 최종적으로 모델 activation에 α·v_opt 형태로 주입
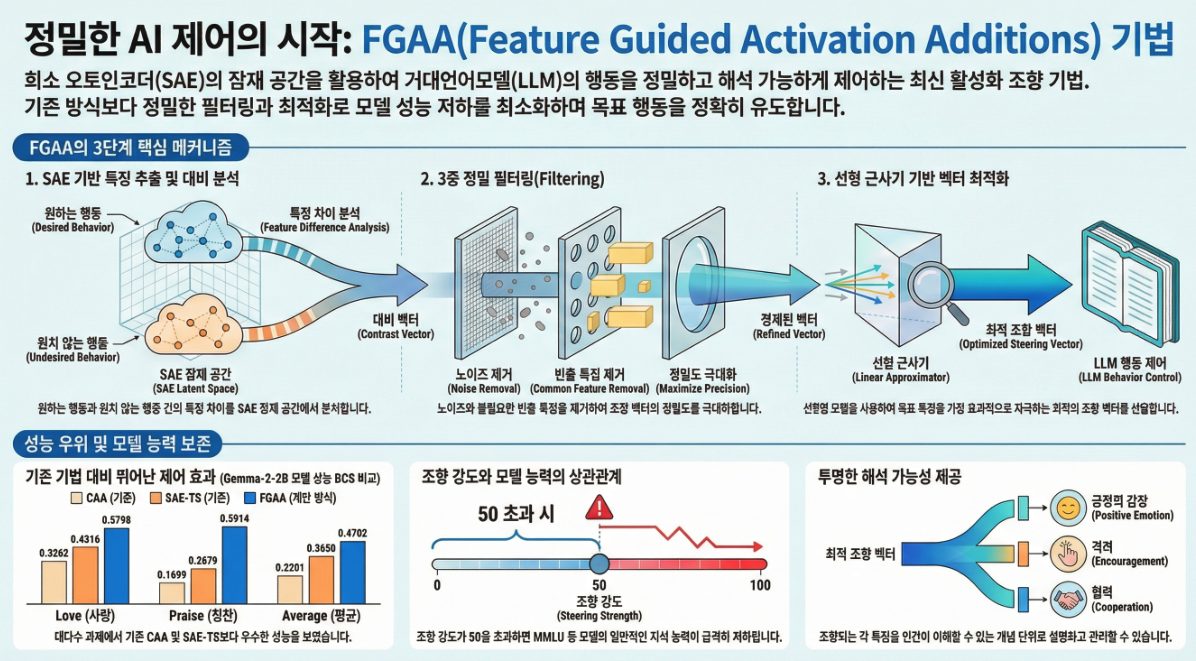
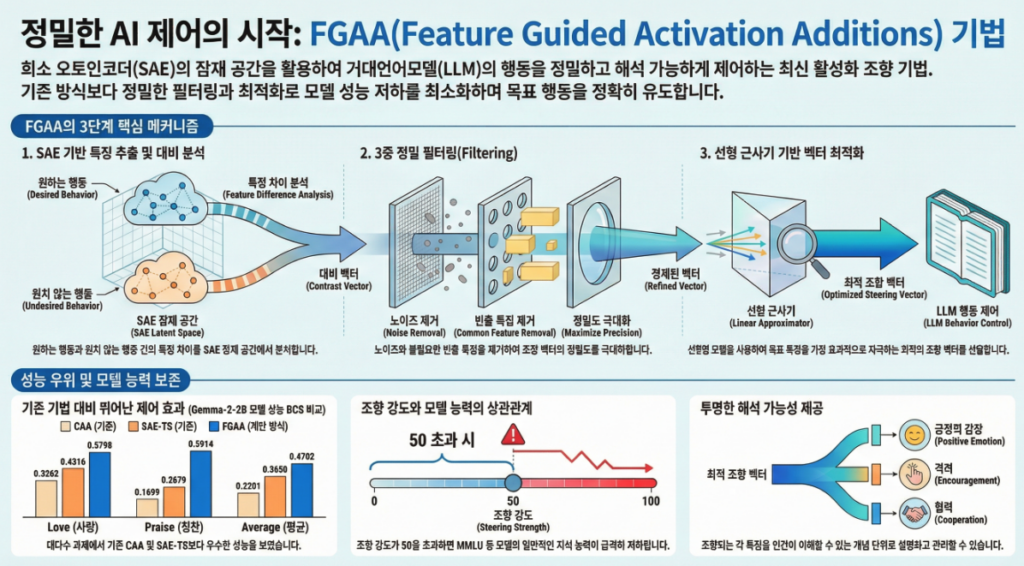
3. 방법론 전체 구조
논문의 Figure 1(페이지 3)은 FGAA의 핵심 파이프라인을 요약한다.
아래는 주요 단계별 정리.
3.1 SAE 기반 Contrastive Analysis (식 (1))
두 개의 예시 집합을 준비한다:
- X⁺: 원하는 행동이 담긴 텍스트
- X⁻: 원하지 않는 행동이 담긴 텍스트
각 입력 x의 특정 layer l에서 hidden state 를 SAE encoder 에 넣어
feature activation을 평균낸 후 차이를 계산:
→ 기존 CAA는 raw residual activation으로 계산하지만
FGAA는 SAE latent feature 공간에서 계산한다는 점이 결정적.
3.2 Feature Filtering 단계 (식 (2)(3)(4))
(1) Density Filtering
특정 SAE feature가 너무 자주 활성화되면(ρ > 0.01),
이는 일반적 언어 패턴일 가능성이 높다 → 제거.
(2) BOS Feature 제거
페이지 22의 Table G.1에 따르면, BOS token에 강하게 반응하는 feature들이 다수 존재.
이들은 generation 아티팩트를 유발하므로 제거.
(3) Top-k Feature 선택
양수 방향 feature n1개, 음수 방향 feature n2개를 선택하여 target vector 구성.
논문 실험 결과:
n2(negative feature)는 steering 성능을 오히려 악화시키므로 대부분 n2=0이 최적.
(Appendix A.3)
3.3 Linear Effect Approximator 기반 최적화 (식 (5))
Effect approximator M, b는
steering 벡터가 SAE feature에 어떤 영향을 줄지 선형적으로 예측하는 모델.
목표: target feature 변화를 가장 잘 유도하는 steering vector v_opt 계산:
여기서 v_target은 L1 normalization을 사용.
논문에서 L1이 L2보다 성능이 좋다는 실증 결과가 있다 (Appendix F).
3.4 최종 적용
Residual stream의 layer l에 다음을 적용:
Steering scale α로 steering intensity를 조절.
4. 실험 결과 요약
FGAA는 Gemma-2-2B와 Gemma-2-9B에서 여러 steering task(Anger, Praise, Love 등)를 평가했다.
평가는 다음 두 가지 점수를 곱해 BCS(Behavior × Coherence)로 계산.
✔ 주요 결과(표 1, 페이지 5)
Gemma-2-2B 평균 BCS
- CAA: 0.2201
- SAE: 0.1404
- SAE-TS: 0.3650
- FGAA: 0.4702 (최고)
9개 task 중 8개에서 FGAA가 최고 성능
Gemma-2-9B
- FGAA가 평균에서는 1위지만
- 일부 task에서는 CAA, SAE-TS가 더 잘됨 → model scaling 효과
✔ 왜 FGAA가 더 잘 동작하는가?
논문 분석(페이지 6):
- SAE feature는 polysemanticity를 완화한 interpretable unit이므로
steering vector의 품질이 향상됨. - FGAA는 단일 feature 조작이 아닌 feature 공간 전체의 스펙트럼을 반영함.
- Feature filtering이 artifacts 및 off-target 조작을 제거함.
- Effect approximator가 실제 영향력을 고려하여 feature-weight를 최적화함.
5. Steering이 모델 능력에 미치는 영향 (Section 4.2)
Perplexity, MMLU, MMLU-Pro로 평가.
✔ Steering scale α가 커지면 모델 능력이 급격히 저하
- Figure 4에서 40 이상의 scale에서 perplexity 폭증
- Figure 5에서 MMLU 성능 감소
→ FGAA는 작은 scale에서는 안정적
→ CAA/SAE-TS는 초·저 규모에서 noise 효과가 오히려 MMLU를 약간 향상시키기도 함(NEFTune과 유사)
6. 논문의 한계(Section 5)
- SAE latent feature 품질에 의존
- n1, n2 최적값이 task-dependent
- Feature filtering의 정량적 지표 부족
7. 향후 연구 방향 (Section 6)
- SAE width가 steering 성능에 미치는 영향 조사
- 더 높은 steering scale에서도 능력 저하를 줄이는 방법
- FGAA를 안전성 분야에 적용(환각, 편향, 시카팬시 등 제어)
8. 요약: FGAA가 기존 방식 대비 가진 강점
| 방법 | 문제점 | FGAA의 개선 |
|---|---|---|
| CAA | raw activation → 비해석적 | SAE latent → interpretable |
| SAE steering | 단일 feature | 여러 feature를 선택하여 더 정밀 |
| SAE-TS | feature 선택이 manual | FGAA는 자동 feature filtering |
| 공통 문제 | coherence 저하 | filtering + optimization으로 개선 |
FGAA는
“해석 가능성 + 조작 정밀도 + coherence 유지”
세 가지를 모두 만족하는 새로운 activation steering 방법이다.
아래에서는 논문의 3.2 Feature Filtering 단계와 3.3 Linear Effect Approximator 기반 최적화를
수식·직관·예시·논문에서의 근거까지 포함해 매우 명확하고 깊이 있게 설명해드립니다.
3.2 Feature Filtering 단계: “원하는 feature만 남기고 나머지는 제거하는 정제 과정”
FGAA는 CAA와 달리 *SAE latent feature 공간에서 contrastive vector(v_diff)*를 만들지만,
이 v_diff는 불필요하거나 해로운 feature들을 많이 포함하고 있다.
그러므로 **v_diff → v_target로 정제(refinement)**하는 과정이 필요하며,
이 정제 절차가 바로 Feature Filtering(식 (2)~(4))이다.
Feature Filtering은 총 3단계:
✔ (1) Density Filtering — 너무 자주 활성화되는 feature 제거
식 (2):
여기서
- ρ(i): feature i의 activation density = 전체 토큰 중 활성화된 비율
- θ = 0.01 (논문 기본값)
왜 density filtering을 하는가?
논문 설명(페이지 4):
- density가 높은 feature는 너무 일반적이고 task-specific하지 않음.
예:- 문장구조, 접속사, punctuation
- 광범위한 언어 패턴
- 이런 feature는 v_diff에서 값이 크게 나와 steering 방향을 왜곡한다.
따라서 특정 행동(anger, praise 등)을 설명하는 핵심 feature만 남기기 위해
자주 등장하는 feature들을 0으로 만든다.
✔ (2) BOS Feature Removal — BOS token에 강하게 반응하는 feature 제거
식 (3):
논문 부록 Appendix G(Table G.1)에서 발견한 BOS 토큰 전용 feature들 예시:
- “the first token of a text”
- “BOS token”
- “newline or BOS combination”
문제점
BOS feature를 포함하면 steering이 모든 문장 시작(bring-up)에 영향을 주어
❌ coherence 문제가 발생하거나
❌ 원치 않은 정형화된 서두를 강제하는 문제가 발생한다.
따라서 이런 feature들을 제거해 steering vector의 품질을 향상시킨다.
✔ (3) Top-k Feature Selection — 가장 중요한 feature만 남김
식 (4):
- top n1 positive features: desired behavior를 가장 많이 나타내는 feature
- top n2 negative features: undesired behavior와의 차이가 큰 feature
하지만 Appendix A의 실험에 따르면:
n2(negative features)는 steering 성능을 오히려 저하시킴
(Appendix A.3의 heatmap 및 분석)
왜냐하면:
- 긍정 feature는 보통 semantic cluster를 이루지만
- 부정 feature는 매우 다양한 의미를 포함 (weather, sarcasm, crime 등 혼합)
- 이러한 분산된 feature를 negative steering에 포함시키면 coherence 손상
그래서 실제 FGAA 구현에서는 대부분:
Feature Filtering의 직관적 요약
| 단계 | 목적 |
|---|---|
| Density Filtering | 너무 일반적인 feature 제거 |
| BOS Feature Removal | generation artifact 방지 |
| Top-k Selection | 중요 feature만 남겨서 정확한 steering |
결과적으로, v_diff → v_target은
raw 차이 벡터 → 정제된 의미적 feature set
으로 변화한다.
3.3 Linear Effect Approximator 기반 최적화
FGAA의 핵심 혁신 중 하나.
Filtering으로 v_target이 만들어졌다고 해서 그대로 steering 벡터로 사용할 수는 없다.
왜냐하면:
⚠ 문제:
Residual activation 공간과 SAE latent feature 공간은 직접적 매핑이 없다.
따라서
“이 feature들을 증가시키고 싶다”
→ residual stream에서 어떤 벡터를 더해야 하는가?
를 계산해야 한다.
이 역할이 Linear Effect Approximator다.
✔ Effect Approximator란?
Chalnev et al. (2024)에서 도입한 개념.
구조는 매우 단순한 선형 모델:
여기서:
- x: steering vector (residual stream dimension d_model)
- M: d_model × d_sae 행렬
(“x가 SAE feature를 얼마나 바꾸는가”를 의미하는 영향 행렬) - b: bias
- : 예측된 SAE feature 변화량
즉, x를 더했을 때 어떤 SAE feature가 얼마나 변하는지 선형적으로 예측하는 모델이다.
✔ FGAA의 목표
“v_target에 해당하는 feature 변화량을 만들어내도록 x를 설계”
즉, 다음을 만족하는 x를 찾아야 한다:
FGAA는 해를 직접 구하기보다 다음 형태로 설계된 최적화된 방향을 사용한다.
✔ 최종 steering vector 계산식 (식 (5))
여기서 W = Mᵀ 로 볼 수 있음.
해석:
- : “이 feature 변화를 만들기 위해 residual stream에서 취해야 할 방향”
- :
bias로 인한 unwanted shift를 제거
→ baseline 변화량을 보정(recification) - 각각 L2 normalize
→ 방향성 유지 + 크기는 steering scale α로 조절
✔ 왜 L1 normalization을 v_target에 사용하는가?
Appendix F에서 설명:
- L2는 큰 값의 feature만 과도하게 강조
- L1은 중간 정도의 feature 기여도도 유지
→ 실제 steering에서 더 자연스럽고 높은 성능
Linear Effect Approximator 최적화의 핵심 요약
- SAE feature → model activation 공간 간의 매핑 문제 해결
- v_target feature 변화를 residual stream 벡터 방향으로 변환
- baseline을 제거해 unwanted drift 감소
- normalize로 안정적·일관된 steering 보장
전체 직관 요약
★ Feature Filtering(3.2)
v_diff에서
→ “정확한 semantic feature만 살아 있는” v_target 추출
★ Effect Approximator Optimization(3.3)
v_target을
→ “모델 residual stream에서 실제로 적용 가능한 방향” v_opt로 변환
즉,
“무엇을 바꾸고 싶은가?” (FGAA feature filtering)
→ “어떻게 바꿀 수 있는가?” (effect approximator optimization)
의 2단계를 완성한다.
여기서는 실제로 Gemma-Scope SAE + Gemma-2-xB를 쓴다고 가정하고, M, b를 어떻게 학습하면 되는지 데이터 수집 → 회귀 학습 → 검증까지 한 번에 정리해볼게요.
0. 목표 다시 정리
우리가 만들고 싶은 것은 layer 에 대해:
steering vector (residual stream 공간):
SAE feature 변화량 의 예측값:
즉,
“이 steering vector를 넣었을 때, SAE feature들이 얼마나 변하는지”를
선형적으로 예측하는 모델을 회귀로 학습
하는 문제입니다.
1. 전제 조건
- LLM (예: Gemma-2-2B / 9B) – freeze
- SAE:
- 특정 layer 의 residual stream에 대해 학습된 SAE encoder
- Steering 적용 위치:
- 예: layer 12 residual
h_l에h_l ← h_l + α·v를 토큰별로 적용
- 예: layer 12 residual
- Effect approximator는 layer별로 따로 학습 (보통 layer 12만).
2. 학습 데이터 수집 파이프라인
핵심 아이디어는 간단합니다:
여러 steering vector 를 실제로 모델에 넣어보고,
그때 SAE feature가 얼마나 변했는지 를 측정해서
쌍을 회귀 데이터로 만든다.
2.1 코퍼스 준비
- 예: OpenWebText, Wikipedia, 뉴스 등에서
prompt(또는 prefix) 를 많이 샘플링합니다. - N_prompt = 수천~수만 문장 정도면 충분.
2.2 Steering vector 샘플링
가능한 옵션:
- 무작위 방향:
- 후 L2 normalize
- SAE decoder 기반 방향:
- SAE decoder의 특정 feature vector (혹은 그 선형 결합)
- CAA 벡터:
- 실제 task에서 나오는 CAA vector들
실제로는 일반적인 효과를 학습하려면
1 + 2를 섞어서 쓰는 게 좋습니다.
- M개 steering vector 샘플:
- 각 는 L2 정규화 해서
2.3 Forward pass: base vs steered
각 (prompt p, steering vector v)에 대해:
- Base pass
- 모델에 p를 넣고 forward
- layer 의 residual activations: (t는 토큰 index)
SAE encoder로 통과:
토큰 평균을 쓰는 게 일반적:
- Steered pass
같은 입력 p에 대해, layer 에서
SAE encoder 통과:
토큰 평균:
- 변화량 계산
이렇게 해서 한 쌍의 샘플:
- 입력
- 타겟
을 얻습니다.
2.4 스케일 α 선택
- Approximator는 선형 근사이므로,
너무 큰 α는 비선형 구간을 강하게 건드려서 회귀가 나빠질 수 있음. - 보통:
- 학습 시 작은 α (예: 10~30 정도)로 데이터 수집
- 나중에 α가 바뀌면 단순히 결과에 곱해지는 형태라 잘 generalize 함
- (FGAA도 steering scale은 나중 단계에서 α로 조정)
2.5 데이터 크기
- d_model = 2048, d_sae = 16384 (Gemma-2 기준) 정도라고 하면,
- 샘플 수:
- N ≈ (수천 prompts) × (몇 개 steering vector) → 몇만 샘플
- 회귀 모델이므로 수만 샘플이면 충분하고,
더 많으면 regularization을 덜 써도 됨.
3. 회귀 문제로서의 학습
이제 가 있다고 하면,
우리가 푸는 것은 ridge regression입니다:
- : weight decay 역할
실제 구현은:
- PyTorch에서 단순한
nn.Linear(d_model, d_sae, bias=True) - Optimizer로 AdamW / SGD
- MSE loss + weight decay
으로 충분합니다.
4. PyTorch 스타일 의사 코드
아주 거친 pseudo-code를 적어보면:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
d_model = 2048 # 예: residual dim
d_sae = 16384 # 예: SAE feature dim
# 1. 회귀 모델 정의 (effect approximator)
class EffectApproximator(nn.Module):
def __init__(self, d_model, d_sae):
super().__init__()
self.linear = nn.Linear(d_model, d_sae, bias=True)
def forward(self, x):
return self.linear(x)
model = EffectApproximator(d_model, d_sae).cuda()
# 2. (v_i, Δz_i) 데이터가 이미 만들어져 있다고 가정
# v_data: [N, d_model], dz_data: [N, d_sae]
dataset = TensorDataset(v_data, dz_data)
loader = DataLoader(dataset, batch_size=256, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
for epoch in range(epochs):
for v_batch, dz_batch in loader:
v_batch = v_batch.cuda() # [B, d_model]
dz_batch = dz_batch.cuda() # [B, d_sae]
# 예: v는 이미 L2-normalized 되어 있다고 가정
pred = model(v_batch) # [B, d_sae]
loss = F.mse_loss(pred, dz_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
학습 시 팁
- 입력 v를 사전에 L2 정규화 (
v / v.norm(dim=-1, keepdim=True)) 하면
scale에 대한 sensitivity가 줄어듭니다. - 출력 Δz는 로그 스케일/표준화 할 수도 있지만,
보통 raw 값으로도 충분히 잘 동작합니다. - d_sae가 크므로:
- 필요하면 feature-wise PCA, top-k feature만 학습,
- 또는 여러 개의 small head로 나누어 학습하는 것도 가능.
5. 학습된 Approximator 사용법
학습 후에는 논문 식 (5)와 같이 사용:
- Feature-space target v_target (FGAA의 filtering 결과)을 만들고
L1-normalize:
- Approximator의 weight/bias를 꺼내서:
W = model.linear.weight.T # [d_model, d_sae]
b = model.linear.bias # [d_sae]
- 논문식:
PyTorch로 치면:
with torch.no_grad():
v_target = v_target_l1_normalized # [d_sae]
v1 = W @ v_target # [d_model]
v2 = W @ b # [d_model]
v1 = v1 / v1.norm()
v2 = v2 / v2.norm()
v_opt = v1 - v2 # [d_model]
- 최종 steering은:
6. 검증과 튜닝
6.1 Approximator 평가
- 별도의 validation set (새 prompts, 새 steering vectors)에 대해
- 실제 Δz와
- 예측 의 cosine similarity / R²를 측정합니다.
- feature 단위로 “중요한 feature들”에 대해서만 성능을 보는 것도 좋습니다
(예: activation density가 너무 높거나 낮은 feature는 제외).
6.2 Practical Tips
- linear assumption이 잘 성립하려면:
- 학습 시 steering scale을 너무 크게 잡지 말 것
- (예: 10~30 정도에서 데이터 수집)
- 특정 layer 전용이므로 layer마다 따로 학습해야 함.
- FGAA처럼 top-k feature만 사용할 경우,
- approximator가 모든 16k feature를 완벽히 예측할 필요는 없고
- 중요한 feature subset에서만 잘 맞으면 됨.
7. 요약
- SAE가 이미 학습된 상태에서,
- 다양한 steering vector (v)를 골라
- LLM을 base vs steered로 돌려서 SAE feature 변화 Δz를 측정하고,
- (v, Δz)를 가지고 단순한 Linear Regression(=nn.Linear) 을 학습하면
→ 그것이 곧 Effect Approximator.
FGAA는 이 approximator를 통해
“이 feature들을 키우고 싶다(v_target)”
→ “그럼 residual stream에서 이 방향(v_opt)으로 더해라”
라는 mapping을 얻는 셈입니다.
답글 남기기